Pytorch学习--导数,激活函数,反向传播
文章目录
- 激活函数及其梯度
-
- Sigmoid / Logistic
- Tanh
- Rectified Linear Unit
- Leaky ReLU
- SELU
- softplus
- LOSS及其梯度
-
- Mean Squared Error
- softmax()函数
- Cross Entropy Lose
- 多输出感知机求导样例
- 测试案例
激活函数及其梯度
Sigmoid / Logistic
f ( x ) = 1 / ( 1 + e − x ) f(x) = 1/(1+e^{-x}) f(x)=1/(1+e−x)
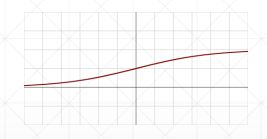
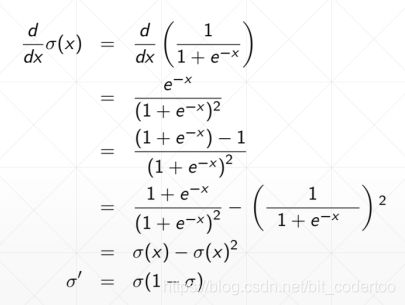
torch.sigmoid(a) 调用sigmoid函数
Tanh
f ( x ) = t a n h ( x ) = ( e x − e − x ) / ( e x + e − x ) f(x) = tanh(x) = (e^x - e^{-x})/(e^x + e^{-x}) f(x)=tanh(x)=(ex−e−x)/(ex+e−x)
= 2 s i g m o i d ( 2 x ) − 1 = 2sigmoid(2x) -1 =2sigmoid(2x)−1
在sigmoid上,x轴压缩2倍,y轴拉伸两倍,并下移1
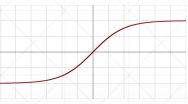
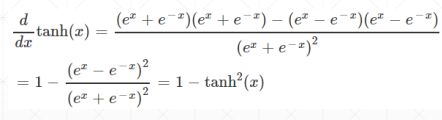
torch.tanh(a)
Rectified Linear Unit

torch.relu(a) 或 F.relu(a)
Leaky ReLU

nn.LeakyReLU() 其中倾角可以设置
SELU

softplus

LOSS及其梯度
Mean Squared Error
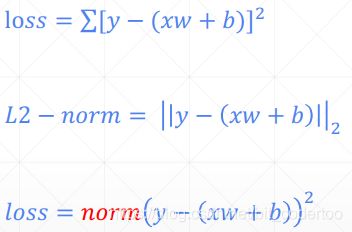
均方差与2范数相差一个**.pow(2)** 的关系
>w = torch.full([1],2) #一个2
>w.require_grad_() #需要导数
>mse = F.mse_loss(torch.ones(1), x*w) #设置mse_loss
>torch.autograd.grad(mse,[w])
或者使用backward
>w = torch.full([1],2) #一个2
>w.require_grad_() #需要导数
>mse = F.mse_loss(torch.ones(1), x*w) #设置mse_loss
>mse.backward()
>w.grad()
torch.autograd.grad(loss, [w1, w2,…])
或者
loss.backward()
softmax()函数
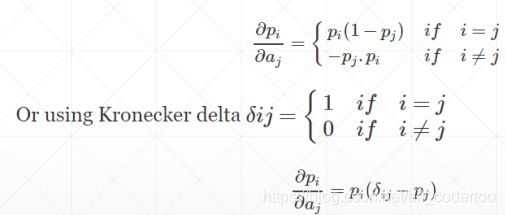
其中ai为原值,pi为概率值
>a = torch.rand(3)
>a.require_grad_()
>p = F.softmax(a, dim = 0)
>torch.autograd.grad(p[1], [a], return_graph = True)
需要设置 return_graph = True 才可进行下次调用
Cross Entropy Lose
higher entropy = less info
Entropy = - (a * torch.log2(a)).sum()

D K L : D i v e r g e n c e , 表 重 合 量 , 分 布 越 重 合 , 其 值 越 小 D_{KL} : Divergence,表重合量,分布越重合,其值越小 DKL:Divergence,表重合量,分布越重合,其值越小
x = torch.randn(1,784)
w = torch.randn(10,784)
logits = x@w.t() #[1,10]
F.cross_entropy(logits,torch.tensor([3])) #自动包含softmax操作
#或者
pred = F.softmax(logits,dim = 1)
pred_log = torch.log(pred)
F.nll_loss(pred_log,torch.tensor([3]))
F.cross_entropy() = F.softmax() + torch.log() + F.nll_loss()
多输出感知机求导样例
x = torch.randn(1,10)
w = torch.randn(2,10,require_grad = True)`
o = torch.sigmoid(x@w.t()) #[1,2]`
loss = F.mse_loss(torch.ones(1,2),o)`
loss.backward()
w.grad #输出w的梯度
测试案例
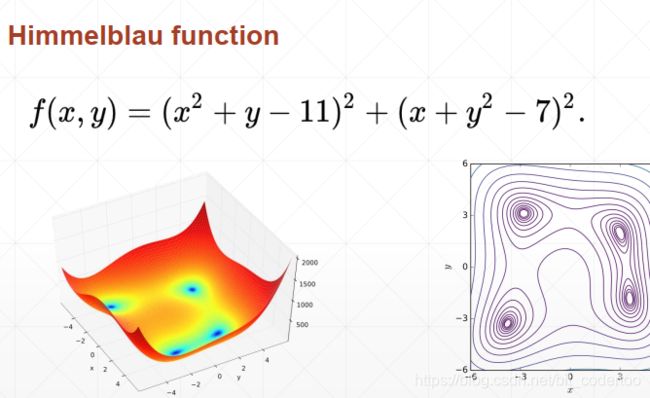
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import pyplot as plt
import torch
def himmelblau(x):
return (x[0] ** 2 + x[1] - 11) ** 2 + (x[0] + x[1] ** 2 - 7) ** 2
#绘制三维图像
x = np.arange(-6, 6, 0.1)
y = np.arange(-6, 6, 0.1)
print('x,y range:', x.shape, y.shape)
X, Y = np.meshgrid(x, y)
print('X,Y maps:', X.shape, Y.shape)
Z = himmelblau([X, Y])
fig = plt.figure('himmelblau')
ax = fig.gca(projection='3d')
ax.plot_surface(X, Y, Z)
ax.view_init(60, -30)
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
# [1., 0.], [-4, 0.], [4, 0.]
x = torch.tensor([-4., 0.], requires_grad=True)
optimizer = torch.optim.Adam([x], lr=1e-3) #设置优化器,目标为[x],以及学习率,自动完成x'=x-lr*dx
for step in range(20000):
pred = himmelblau(x)
optimizer.zero_grad() #梯度清零
pred.backward() #对预测值直接求导
optimizer.step() #对x,y更新
if step % 2000 == 0:
print ('step {}: x = {}, f(x) = {}'
.format(step, x.tolist(), pred.item()))