[记录]GAN学习之路[持续更新]
目录
一、原始GAN
二、WGAN(GP)
三、pix2pix
四、CycleGAN
一、原始GAN
通俗解释:
GAN由生成器(Generator)和判别器(Discriminator)组成,生成器负责生成假的图片来骗过判别器,而判别器需要不断从真实图片上学习特征来提高自己的判别能力。
GAN本质是一个博弈的过程,首先生成器G将输入的随机噪声通过神经网络生成一张图,判别网络D会对G生成的假图进行打分(分值越接近0表示图片越假,越接近1表示图片越真),从而引导G生成更真的图(既然判别器D要引导生成器G变得更好,那么D的判别能力起到至关重要的作用,因此判别器D也在不断学习真实图片的特征,从而提高自己的判别能力)
理论解释:
实际上,我们的真实样本是服从某种分布的(分布很复杂,无法用具体表达式写出),这里记为![]() ,我们输入的噪声z通过G之后生成的图片也是服从某种分布的,这里记为
,我们输入的噪声z通过G之后生成的图片也是服从某种分布的,这里记为![]() ,我们的目的是让
,我们的目的是让![]() 不断逼近
不断逼近 ![]() ,如下图所示。而如何才能知道这两种分布的相似程度(fGAN总结了各种衡量分布差异的方式),通过JS散度来衡量两种概率分布的差异divergence(后面简记为div)。因此目的就很明确,要让
,如下图所示。而如何才能知道这两种分布的相似程度(fGAN总结了各种衡量分布差异的方式),通过JS散度来衡量两种概率分布的差异divergence(后面简记为div)。因此目的就很明确,要让![]() 和
和![]() 的div最小(原始GAN是用JS散度来作为两种分布的div)。
的div最小(原始GAN是用JS散度来作为两种分布的div)。
![[记录]GAN学习之路[持续更新]_第1张图片](http://img.e-com-net.com/image/info8/21c4a77acfcd47d1b46dfad2f16e9a0f.jpg)
实际逼近过程中,我们不可能在全部样本上做处理,而是通过采样,在真实样本中采集m个样本,同时生成m个输入噪声z(这些噪声服从同一种分布),然后去使两个分布逼近,因此优化目标如下图G*所示。
![[记录]GAN学习之路[持续更新]_第2张图片](http://img.e-com-net.com/image/info8/a0f562cd645e438eac12d09ca4c45a9e.jpg)
通过一系列验证,将优化目标G*变成
![]()
![[记录]GAN学习之路[持续更新]_第3张图片](http://img.e-com-net.com/image/info8/6995afa530184cc3a631971f281b519c.jpg)
![[记录]GAN学习之路[持续更新]_第4张图片](http://img.e-com-net.com/image/info8/6ed748b79dfc42a2b942cfea8a0e7850.jpg)
之后,GAN的一系列操作均是为了寻找上述方程的最优解。关于训练过程中先训练k次D再训练G,这里给出很直观的答案,我们希望找到V(G0,D)的最大值(这里G0是固定的),这个最大值才是表征两个分布的div。
存在的问题:
由于 ![]() 和
和 ![]() 最初开始训练时候可能是完全不重合的,而这种情况下JS散度来衡量两者的差异 div是一个定值log2,也就是此时即便
最初开始训练时候可能是完全不重合的,而这种情况下JS散度来衡量两者的差异 div是一个定值log2,也就是此时即便 ![]() 已经有在逼近
已经有在逼近![]() ,但实际梯度是无法进行更新的(因为网络在这种情况认定两种状态是一致的),因此GAN很难达到收敛。
,但实际梯度是无法进行更新的(因为网络在这种情况认定两种状态是一致的),因此GAN很难达到收敛。
![[记录]GAN学习之路[持续更新]_第5张图片](http://img.e-com-net.com/image/info8/04eb5e42cd6b4001a53400e4815ee551.jpg)
二、WGAN(GP)
解决的问题:
为了解决原始GAN使用JS散度衡量两种分布差异时带来收敛慢的问题,WGAN引入了一种新的度量差异的方式。
通俗解释:
已知![]() 和
和 ![]() 的分布,如何衡量两者之间的div。可以用一个土堆转移来形象说明该问题,要使分布P变成分布Q,如下图所示有很多种方案,WGAN将这种转移需要的最小平均距离定义为wasserstein distance。因此现在目标就是从多种方案中找到距离最小的一种。
的分布,如何衡量两者之间的div。可以用一个土堆转移来形象说明该问题,要使分布P变成分布Q,如下图所示有很多种方案,WGAN将这种转移需要的最小平均距离定义为wasserstein distance。因此现在目标就是从多种方案中找到距离最小的一种。
![[记录]GAN学习之路[持续更新]_第6张图片](http://img.e-com-net.com/image/info8/3a3cee7d340e48419cf197c1a23d7ab9.jpg)
理论解释:
上述问题可以用公式W(P,Q)来表示,B( )表示任意一种方案 对应的平均距离,W(P,Q)的目的就是从各种方案中找到最优方案(即平均距离最短)。
)表示任意一种方案 对应的平均距离,W(P,Q)的目的就是从各种方案中找到最优方案(即平均距离最短)。
![[记录]GAN学习之路[持续更新]_第7张图片](http://img.e-com-net.com/image/info8/53b2ab9ac3064dc7b7476d05db238934.jpg)
将其转换到GAN的优化目标上,等同于给D增加一个一阶lipschitz条件(![]() ),目的是使得当输入变化较小的时候,D给出的分差不会太大,即变化更加平缓。
),目的是使得当输入变化较小的时候,D给出的分差不会太大,即变化更加平缓。
给D增加限制后如何进行更新的,最初的WGAN通过Weight Clipping(即将参数w限制在某个区域内,实际是存在一些问题的),因此又引入了WGAN-GP,这种方法对D的限制条件进行了转换,变成![]() ,其中x是任意的,而实验表明只需要将x限制在
,其中x是任意的,而实验表明只需要将x限制在 ![]() 和
和 ![]() 之间即可,因为目的是要让
之间即可,因为目的是要让 ![]() 去逼近
去逼近![]() ,只有介于该部分之间的x才会影响结果,实验同时说明其实当D(x)梯度越接近1收敛越快。
,只有介于该部分之间的x才会影响结果,实验同时说明其实当D(x)梯度越接近1收敛越快。
![[记录]GAN学习之路[持续更新]_第8张图片](http://img.e-com-net.com/image/info8/f98af73d0fe94986840f1b3fcbb85cda.jpg)
实际实现:
WGAN相对于原始GAN主要有以下变动:
1、将损失中log全部去掉了,拿 ~来说,
~来说,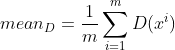 这部分相当于判别器D输出的均值,我们希望
这部分相当于判别器D输出的均值,我们希望![]() 越大越好,也就是meanD越大越好,由于采用的是梯度下降法,我们希望其负数越小越好(因此在代码中这部分loss应该等于-D(x).mean()),而后面那部分我们希望其越小越好(因此在代码中这部分loss应该等于D(x~).mean());在更新G时候,我们希望
越大越好,也就是meanD越大越好,由于采用的是梯度下降法,我们希望其负数越小越好(因此在代码中这部分loss应该等于-D(x).mean()),而后面那部分我们希望其越小越好(因此在代码中这部分loss应该等于D(x~).mean());在更新G时候,我们希望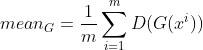 越大越好,也就是其负数越小越好(因此在代码中这部分loss应该等于-D(G(z)).mean()),因此总loss=-mean_D-mean_G+mean_D~
越大越好,也就是其负数越小越好(因此在代码中这部分loss应该等于-D(G(z)).mean()),因此总loss=-mean_D-mean_G+mean_D~
2、V~部分增加了weight clipping 或Gradient Penalty;
3、去除了判别器D最后的sigmod;
![[记录]GAN学习之路[持续更新]_第9张图片](http://img.e-com-net.com/image/info8/c6da228f03804ab198fc6dd17adf50ec.jpg)
三、pix2pix
实现的功能:
pix2pix实现图片到图片的转变,可以用来做画风迁移、图像上色、图像修复等等。
![[记录]GAN学习之路[持续更新]_第10张图片](http://img.e-com-net.com/image/info8/01ddf4c8ddfd4aeea747cfc5b44455ee.jpg)
代码实现细节:
首先,在数据集方面,训练样本必须是成对的(其实这种样本获取是很不方便的,需要一一匹配,后续Cycle GAN中貌似解决了这个问题)。
其次,对于生成网络G来说,采用了经典的U-net网络,本质就是一个编解码的过程。G的输入不再是噪声,而是fecade 图片,噪声通过dropout层体现,G生成的图片一方面要尽可能骗过D,另一方面要尽可能逼近fecade图片对应的真实图片(通过L1 loss体现) 。另一方面,对于判别器D来说,采用的Patch GAN,即D要对最终输出的N*N个Patch进行打分,D的训练损失与原始GAN相同。
具体可参考我另一篇博文:PyTorch 实现Image to Image (pix2pix)
四、CycleGAN
解决的问题:
由于pix2pix对数据集的要求较高,需要成对的样本,而这种样本的获取往往需要很大的成本,CycleGAN可以实现两种风格的数据进行风格转变,只需要准备两种风格的样本(Domain X、Domain Y),两个domain之间并不需要一一对应。
![[记录]GAN学习之路[持续更新]_第11张图片](http://img.e-com-net.com/image/info8/0fb3deabace149a3a3d9980af3330539.jpg)
代码实现细节:
在网络结构上,生成器G采用了ResNet结构,网络的padding方式(ReflectionPad)与原始GAN不同,判别器D与pix2pix类似,最终同样是对每个Patch进行打分;损失函数方面,判别器D的目的是尽可能区分真假图片,生成器G的损失包括三部分:GAN_loss、Cycle_loss、id_loss。其中,GAN_loss就是传统GAN的loss,目的是使G生成的图片尽可能真,Cycle_loss是重建的图片与原始图片之间的L1损失,id_loss是为了保证G不去随意改变图片的色调(即便判别器告诉你另外一种色调也服从Domain Y的分布,但为了仅仅改变风格不改变别的因素,因此引入了该损失)。
具体可参考我另一篇博文:PyTorch 实现CycleGAN 风格迁移