论文研读-AI4VIS-可视化推荐-VizML: 一种基于机器学习的可视化推荐方法
VizML: 一种基于机器学习的可视化推荐方法
- 1 论文概述
-
- 1.1 摘要
- 1.2 引言
- 2 问题陈述
- 3 相关工作
-
- 3.1 基于规则的可视化推荐系统
- 3.2 基于机器学习的可视化推荐系统
- 4 数据
-
- 4.1 Plotly介绍
- 4.2 数据描述和分析,收集和清理
- 4.2 数据特征提取
- 4.3 设计选择提取
- 5 方法
-
- 5.1 特征处理
- 5.2 预测任务
- 5.3 神经网络和基线模型
- 6 评估性能
-
- 解释特征重要性
- 7 基准与众包的有效性
-
- 7.1 建模和测量有效性
- 7.2 基准测试过程与数据准备
- 7.2 基准测试程序
- 7.3 基准测试结果
- 8 讨论
1 论文概述
本文发表于CHI 2019。 作者来自MIT Media Lab和MIT CSAIL。
1.1 摘要
可视化推荐系统的目标是通过自动生成结果让分析师进行搜索和选择,而不是手动指定,从而降低探索基本可视化的障碍。
在这里,我们演示了一种基于机器学习的可视化推荐新方法,该方法从大量的数据集和相关的可视化中学习可视化设计选择。首先,我们确定分析师在创建可视化时所做的五个关键设计选择,例如选择可视化类型和选择沿着X或y轴对列进行编码。我们使用从一个流行的在线可视化平台收集的100万个数据集可视化对来训练模型来预测这些设计选择。与基线模型相比,神经网络预测这些设计选择具有较高的准确性。我们从这些基线模型中报告并解释特性的重要性。
为了评估该方法的通用性和不确定性,我们使用一个众包测试集进行基准测试,结果表明,我们的模型在预测共识可视化类型时的性能与人类的性能相当,并超过了其他可视化推荐系统。

1.2 引言
背景:
跨领域的知识工作者——从商业到新闻到科学研究——越来越多地使用数据可视化来产生见解、交流发现和做出决策[9,26,58]。然而,许多可视化工具由于依赖于代码[7,68]或点击[2,62]的手动说明,学习曲线陡峭。因此,越来越多缺乏时间或背景来学习复杂工具的领域专家往往无法访问数据可视化。
虽然需要创建定制的可视化,但是对于许多常见的用例(如初步的数据探索和基本可视化的创建)来说,手工规范是不必要的。在这些用例中,搜索的速度和广度比可定制性更重要[63],为了支持这些用例,系统可以利用数据集的属性对可视化的影响。例如,先前的研究表明,视觉通道(如位置和颜色)编码数据的准确性取决于数据值的类型[5,15,67]和[28]分布.
前人方案:
基于规则的方法:
大多数推荐系统将这些可视化指南编码为“if-then”语句的集合,或规则[21],以自动生成可视化,供分析人员搜索和选择,而不是手动指定[64]。例如,APT[35]、BOZ[13]和SAGE[52]使用感知原则的规则生成可视化并排序。最近的系统如Voyager[72,73]、Show Me[34]和DIVE[23]扩展了这些方法,支持列选择。虽然对于某些用例[72]是有效的,但是这些基于规则的方法面临着限制,例如昂贵的规则创建和可能结果[1]的组合爆炸。
基于机器学习的方法:
相比之下,基于机器学习(ML)的系统通过对分析师交互的训练模型直接学习数据和可视化之间的关系。虽然最近的系统如DeepEye[33]、Data2Vis[17]和Draco-Learn[37]都很令人兴奋,但它们并没有像分析师那样学会如何选择可视化设计,这将影响到可解释性和集成到现有系统的方便性。此外,由于这些系统在受控设置中使用规则生成的可视化注释进行训练,它们受到数据数量和质量的限制。
本文方案:
我们引入了VizML,这是一种基于ml的方法,使用大量的数据集和相关的可视化来实现可视化推荐。首先,我们将可视化描述为一个做出设计选择的过程,使效率最大化,这取决于数据集、任务和上下文。然后,我们制定可视化建议作为一个开发模型的问题,学习做出设计选择。
我们使用来自Plotly Community Feed[46]的100万个独特的数据集可视化对来训练和测试机器学习模型。我们描述了收集和清理这个语料库的过程,从每个数据集提取特征,并从相应的可视化中提取五个关键的设计选择。我们的学习任务是优化模型,利用数据集的特征来预测这些选择。
结果与评估:
在60%的语料库上训练的神经网络在一个单独的20%测试集中预测设计选择的准确率达到了70 - 95%。这一性能超过了四个更简单的基线模型,它们本身的性能优于随机概率。我们从这些基线模型之一报告特征的重要性,解释特征对给定任务的贡献,并将它们与现有的研究联系起来。
我们通过对众包测试集进行基准测试来评估我们模型的可泛化性和不确定性。我们通过从Plotly中随机选择数据集来构建这个测试集,将每个数据集可视化为一个条形、直线和散点图,并测量机械土耳其工人的共识。使用一个根据共识程度调整的评分指标,我们发现VizML的表现与Plotly用户和Mechanical Turkers相当,并且优于两个基于规则和两个基于ml的可视化推荐系统。
最后,我们讨论了初始机器学习方法在可视化推荐中的解释、应用和局限性。我们还提出了未来研究的方向,例如聚合公共训练和基准语料,将单独的推荐模型集成到端到端系统中,以及细化可视化有效性的定义。
2 问题陈述
数据可视化通过用可视化元素表示数据来传递信息。这些表示是用从数据映射到实体属性的编码指定的:图形标记(例如点、线或矩形)的位置、长度或颜色[5,12]。
具体地说,考虑一个描述406辆汽车(行)的数据集,它有8个属性(列),比如每加仑行驶里程(MPG)、马力(Hp)和磅重(Wgt)[50]。为了创建显示mpg和hp之间关系的散点图,分析人员将每对数据点与二维平面上圆的位置进行编码,同时还指定其他属性,如大小和颜色:
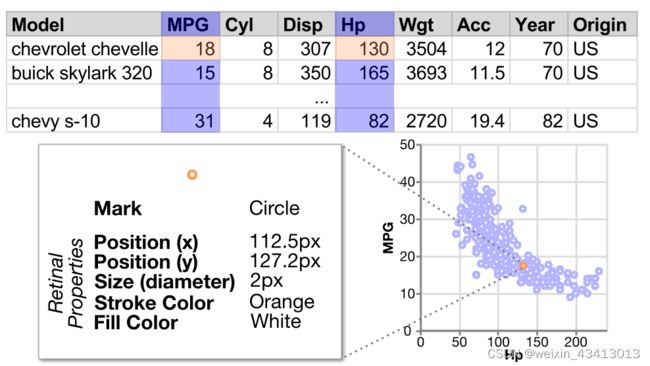
我们将数据集d的基本可视化表述为一组相互联系的设计选择 C ={c}。然而,并不是所有的设计选择都会产生有效的可视化效果——有些选择彼此不兼容。例如,使用线标记的Y轴位置编码分类列是无效的。因此,产生有效可视化结果的选择集是所有可能选择的空间的子集。

可视化的有效性可以通过信息度量,如效率、准确性和可记忆性(efficiency, accuracy, and memorability)[6,74],或情感度量,如参与度(engagement)[19,27]来定义。先前的研究还表明,除了任务[3,28,53]、美学[14]、领域[24]、受众[60]和媒介[36,57]等上下文因素外,有效性还受到低级感知原则[15,22,31,51]和数据集属性[28,54]的影响。
换句话说,在给定 数据集d 和 上下文因素T 的情况下,分析师做出的 设计选择C 可以使 可视化有效性EFF 最大化,此时的设计选择C_max定义为:

但是,做出设计选择可能是昂贵的。可视化推荐的一个目标是,通过自动建议一个子集的设计选择(C_rec⊆C)来降低创建可视化的成本,从而最大化效率。使用由数据集{d}和相应的设计选择{C}组成的语料库训练的基于ml的推荐系统,将推荐视为一个优化问题,如预测C_rec ~ C_max。
设计选择推荐建模:
给定 C’(除了设计选择c以外的其他选择)、数据集d 和 上下文因素T ,理想的设计决策推荐函数F_c输出最大化可视化有效性的设计选择c_max。
![]()
我们的目标是用函数G_c来近似F_c。现在假设一组数据集D={d}和相应的可视化V={V_d},每个可视化都可以用设计选项C_d={c_d}来描述。基于机器学习的推荐系统考虑G_C作为带有一组参数Θ_c的模型,可以通过最大化目标函数Obj的学习算法对该语料库进行训练:
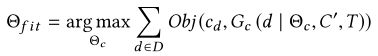
在不丧失一般性的情况下,假设目标函数使训练输出{C_d}的可能性最大化。即使分析师做出次优设计选择,集体优化所有观察到的设计选择的可能性仍然是最优的。这正是我们观察到的设计选择c_d=F_c(d|C′,T)+噪声+偏差的情况。因此,给定一个看不见的数据集d∗, 最大化这个目标函数可以合理地给出一个使可视化的效果最大化的推荐。
![]()
在本文中,我们的模型G_c是一个神经网络,Θ_c是连接权重。我们通过独立地优化每个G_c来简化推荐问题,并且没有上下文因素:G_c(d|Θ)=G_c(d|Θ,C′,T)。我们注意到,独立的推荐建议可能不兼容,也不一定能最大限度地提高整体效率。生成完整的可视化输出需要为每个c的G_c之间的依赖关系建模。
3 相关工作
我们将我们的工作与现有的基于规则的可视化推荐系统和基于ML的可视化推荐系统进行了关联和比较 。
3.1 基于规则的可视化推荐系统
可视化推荐系统可以建议数据查询(选择要可视化的数据)或可视化编码(如何可视化所选数据)。数据查询推荐的方法各不相同[59,69],最近的系统优化了统计“效用”函数[18,65]。尽管指定数据查询对可视化至关重要,但它与设计选择建议是截然不同的任务。
大多数视觉编码推荐实施的指导方针都是贝尔廷[5]和克利夫兰与麦吉尔[15]的开创性工作。麦金莱(Mackinlay)的APT[35]——ur推荐系统——就是这种方法的一个例子。该系统使用表达能力和感知有效性标准对可视化进行枚举、过滤和评分。密切相关的SAGE[52]、BOZ[13]和Show Me[34]支持更多数据、编码和任务类型。最近,Voyager[71–73]、Explore in Google Sheets[20,66]、VizDeck[43]和DIVE[23]等混合系统将视觉编码规则与包含非选择列的可视化建议结合起来。
尽管对许多用例有效,但这些系统有三个主要限制。首先,可视化是一个复杂的过程,可能需要对难以用简单规则捕捉的非线性关系进行建模。其次,制定规则集是一个昂贵的过程,需要依靠专家的判断。最后,随着输入数据维数的增加,规则的组合性质会导致大量可能的建议。
3.2 基于机器学习的可视化推荐系统
由基于规则的系统编码的指南通常来自实验结果和专家经验。因此,启发法以一种间接的方式,从另一位分析师创造和消费可视化的经验中提炼出最佳实践。基于ML的系统没有将从数据中学习到的最佳实践聚合起来,并用规则将它们表示在一个系统中,而是建议训练直接从数据中学习并可以按原样嵌入系统的模型。
表S1显示了基于ml的可视化推荐系统VizML(本工作)、DeepEye[33]、Data2Vis[17]和Draco-Learn[37]的列表比较。

VizML在三个主要方面与这些系统不同。在学习任务方面,DeepEye学习对可视化进行分类和排序,Data2Vis学习端到端生成模型,Draco学习学习软约束权重。通过学习预测设计选择,VizML模型更容易进行定量验证,提供特征重要性的可解释度量,并且可以更容易地集成到可视化系统中。
在数据量方面,VizML训练语料库比DeepEye和Data2Vis训练语料库大几个数量级。我们语料库的规模允许使用1)捕获数据集许多方面的大型特征集和2)高容量模型,如深度神经网络。
第三个主要区别是数据质量。与用于训练三个现有系统的少数数据集相比,用于训练VizML模型的数据集在形状、结构和分布上极为不同。此外,其他基于ML的推荐系统使用的可视化由基于规则的系统生成,并在受控设置下进行评估。VizML使用的语料库是分析师对自己的数据集进行真实视觉分析的结果。
然而,VizML面临两个主要限制。首先,这三个基于ML的系统同时推荐数据查询和视觉编码,而VizML只推荐后者。第二,在本文中,我们不创建使用可视化模型的应用程序。面向用户的系统的设计考虑是重要的,这些系统有效地、正确地使用了基于ML的可视化推荐,但超出了本文的范围。
4 数据
我们描述了从经过处理的Plotly数据中提取特征和设计选择的过程。图1中的步骤1、步骤2和步骤3。
4.1 Plotly介绍
Plotly是一家软件公司,是数据可视化和分析创建工具和软件库。例如,Plotly Chart Studio[45]是一个web应用程序,允许用户上传数据集并手动创建超过20种可视化类型的交互式D3.js和WebGL可视化。熟悉Python的用户可以使用Plotly Python库[47]用代码创建相同的可视化效果。
Plotly中的可视化是用声明性模式指定的。在这个模式中,每个可视化都由两个数据结构指定。第一个是跟踪列表,用于指定数据集合的可视化方式。第二个是一个字典,它指定了与数据无关的可视化的美学方面,例如轴标签和注释。例如,第2节中的散点图使用单个“散点”轨迹指定,Hp为x参数,MPG为y参数:
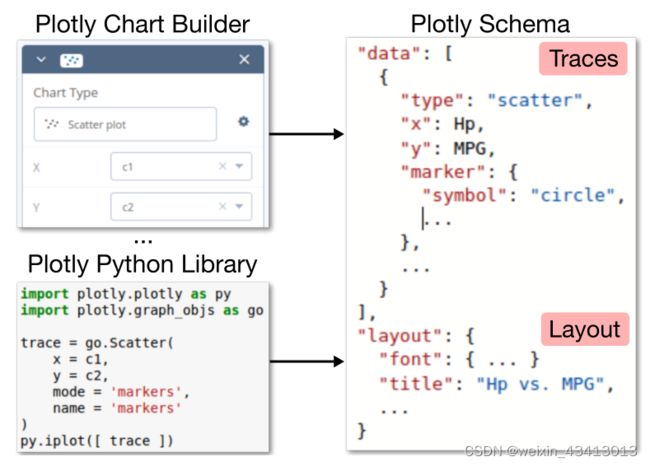
Plotly模式类似于MATLAB和matplotlib Python库的模式。流行的Vega[56]和Vega lite[55]模式是更武断的,这“允许使用简洁的JSON描述显示复杂的图表,但用户对其控制较少”[49]。尽管存在这些差异,但将绘图模式转换为其他模式还是很简单的,反之亦然。
Plotly还支持共享和协作。从2015年开始,用户可以将图表发布到Plotly Community Feed[46],它提供了一个用于搜索、排序和过滤数百万可视化内容的界面,如图S2所示。PlotlyREST API[48]中的底层/绘图端点将每个可视化与三个对象相关联:数据包含源数据,规范包含跟踪,布局定义显示配置。

4.2 数据描述和分析,收集和清理
我们描述了从Plotly Community Feed[44,46]中收集和清理230万数据集可视化对的语料库的过程,并提供了对数据的描述。本文是首次使用由143007个独立用户生成的plotly语料库来训练可视化推荐系统。该语料库和分析脚本都是公开的,可以通过以下途径获取://vizml.media.mit.edu。
使用Plotly API,我们从feed中收集了大约2.5年的公共可视化效果,从2015-07-17开始,到2018-01-06结束。我们总共收集了2359175个可视化对象,其中2102121个包含所有三个配置对象,其中1989068个被正确解析。为了避免用户上传的数据集和我们的数据集之间的混淆,我们将这个数据集可视化对集合称为Plotly语料库 .
Plotly语料库包含143007个独特用户创建的可视化效果,这些用户的使用情况差异很大。每个用户的可视化分布如图S3所示。除去拥有最多可视化效果的前0.1%用户(其中许多是通过编程生成可视化效果的机器人),用户创建的平均值为6.86,每个用户创建的可视化效果中位数为2。

数据集的列数和行数也有很大差异。虽然有些数据集包含100多列,但94.97%的数据集包含少于或等于25列。不包括超过25列的数据集,平均数据集有4.75列,中位数数据集有3列。每次可视化的列分布如图S4a所示。每个数据集的行分布如图S4b所示,平均值为3105.97,中位数为30,最大值为10×106。这些重尾分布与[38]报告的IBM ManyEyes和Tableau Public的分布一致。


虽然Plotly允许用户使用多个数据集生成可视化效果,但98.32%的可视化效果仅使用一个源数据集。因此,我们只关注使用单个数据集的可视化。此外,超过90%的可视化使用了源数据集中的所有列,因此我们无法解决数据查询选择问题。最后,在13321598条记录道中,只有0.16%的记录道具有转换或聚合。鉴于这种极端的类不平衡,我们无法将列转换或聚合作为学习任务。
4.2 数据特征提取
我们将每个数据集映射到841个特征,使用16个聚合函数从81个单列特征和30个成对列特征映射而来。有关每个特征的详细信息,请参见SM第S4节中的表S2。 表S2a中的单列特征分为四类:维度(D)(列的行数)、类型(T)(分类、时间或定量)、值(V)(统计和结构特性)和名称(N)(与列名相关)。我们区分这些特征类别有三个原因。首先,这些类别允许我们组织如何创建和解释特征。其次,我们可以**观察不同类型特征的贡献。**第三,某些类别的特征可能比其他类别的特征更难概括。我们依据这些特征对Plotly语料库的贡献将这些特征排序(D→ T→ V→ N)。

我们用30个成对列特征描述每对列。表S2b中的成对列特征分为“值”和“名称”两类。许多成对列的特征取决于在通过单列特征提取确定的单个列类型上。例如,皮尔逊相关系数需要两个数字列,“共享值的数量”特征需要两个分类列。
最后,通过使用表S2c中所示的16个聚合函数聚合这些特征,创建了841个数据集级特征。

每列由四个类别的81个单列特征描述。尺寸(D)特征是一列中的行数。类型(T)特征捕获列是分类的、时态的还是定量的。值(V)特征描述列中值的统计和结构特性。名称(N)功能描述列名。我们区分这些特征类别有三个原因。首先,这些类别允许我们组织如何创建和解释特征。其次,我们可以观察不同类型特征的贡献。第三,某些类别的特征可能比其他类别的特征更难概括。我们订购这些类别(D→ T→ 五、→ N) 我们期望这些特征对情节丰富的语料库有多大的偏见。
一个实例:

4.3 设计选择提取
Plotly中的每个可视化都包含将数据集合与视觉元素关联的轨迹。因此,我们通过解析这些跟踪来提取分析师的设计选择。编码级别设计选择的示例包括标记类型,例如散点、直线、条形;以及X或Y列编码,指定在哪个轴上表示哪个列;以及X或Y列是否是沿该轴表示的单个列。例如,图3中的可视化由两条散射迹线组成,两条散射迹线的X轴(Hp)上编码的列相同,Y轴上编码的列不同(MPG和Wgt)。
通过聚合这些编码级设计选项,我们可以描述图表的可视化级设计选项。在我们的语料库中,超过90%的可视化由同质标记类型组成。因此,我们使用可视化类型来描述所有记录道之间共享的类型,并确定可视化是否具有共享轴。图3中的实例具有散点可视化类型和单个共享轴(X)。

5 方法
我们描述了我们的特征处理流程、我们使用的机器学习模型、我们如何训练这些模型,以及我们如何评估性能。这些是图1中工作流的步骤4和5。
5.1 特征处理
通过5个阶段,我们将原始特征转换为适合建模的形式。
- 对类别特征应用one-hot编码。
- 将高于第99个百分点或低于第1个百分点的数值设置为相应的截止值。
- 使用非缺失值模式估算缺失的分类值,并使用非缺失值的平均值估算缺失的数值。
- 我们去掉了数值域的平均值,并按单位方差进行缩放。
- 我们随机删除了彼此完全相同的重复数据集,得到了唯一的1066443个数据集和288437列。然而,许多数据集都是由同一个用户上传的微小修改版本。因此,除了每个用户一个随机选择的数据集外,我们删除了所有数据集,这也消除了对更多产的用户的偏见。这种积极的重复数据消除最终产生了119815个数据集和287416列的语料库。仅精确重复数据消除的结果会显著提高语料库内测试的准确率,而基于软阈值的重复数据消除则会导致相同的测试准确率。
5.2 预测任务
我们的任务是训练使用第4节中描述的特性预测第4节中描述的设计选择的模型。两个可视化级别预测任务使用数据集级别的特征预测可视化级别的设计选择:

这三个编码级别预测任务使用有关单个列的特性来预测它们的视觉编码方式。这些预测任务独立地考虑每个列,而不是在同一数据集中并列的其他列,它们考虑列顺序的影响。

对于可视化类型和标记类型的任务,2类任务预测折线与条形,3类任务预测散点与折线与条形。虽然Plotly支持超过20种标记类型,但我们将预测结果限制在构成语料库中大多数可视化的少数类型。这种可视化类型的异质性与[4,38]的研究结果一致。
5.3 神经网络和基线模型
我们的主要模型是一个具有3个隐藏层的完全连接的前馈神经网络(NN),每个层由1000个具有ReLU激活函数的神经元组成,并使用Pytork实现[41]。为了进行比较,我们选择了四种更简单的基线模型,它们都是使用scikit学习[42]实现的,带有默认参数:朴素贝叶斯(NB)、K近邻(KNN)、逻辑回归(LR)和随机森林(RF)。对每个模型进行随机参数搜索,与报告的结果相比,没有显著提高性能。
对于所有模型,我们将数据分成60/20/20个训练/验证/测试集,并使用5倍交叉验证对每个模型进行五次训练和测试。因此,报告的结果是五个测试集的平均测试结果。我们对训练集、验证集和测试集进行了过采样,使其达到了大多数类的大小,同时确保三个集之间没有重叠。由于结果的异质性,我们样本过多,天真的分类器猜测基本比率的准确率会很高。平衡等级还允许我们报告标准准确度(正确预测的分数),这对于解释性和将结果推广到多等级C>2的情况来说非常理想,与F1分数等衡量标准形成对比。
神经网络使用Adam优化器和200的小批量进行训练。学习率初始化为5×10−4,并遵循一个学习率计划,该计划在遇到高原时将学习率降低10倍,定义为10个阶段,在此期间,验证精度不会超过10−3的阈值。训练在学习率第三次下降后结束,或在100个阶段结束。dropout、dropout和batch标准化并没有显著改善性能。
在特征方面,我们通过按顺序递增地添加特征的维度(D)、类型(T)、值(V)和名称(N)类别,构建了四个不同的特征集。我们将这些功能集称为D、D+T、D+T+V和D+T+V+N=All。使用所有四个特征集分别对神经网络进行训练和测试。四种基准型号仅使用完整的功能集(D+T+V+N=All)。
6 评估性能
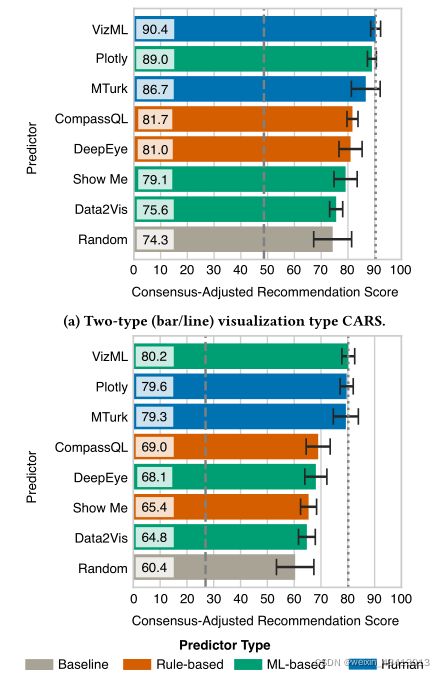
我们在表1中报告了每个模型在五项预测任务上的性能。神经网络始终优于基线模型,模型性能通常提高:NB 因为这四个特征集是一系列超集(D⊂ D+T⊂ D+T+V⊂ D+T+V+N),我们考虑每个特征集的精度。例如,在D+T+V上训练的模型的精度比在D+T上训练的模型的精度高,这是对基于价值(V)特征贡献的一种衡量。这些边际精度与基线模型精度一起显示在表1中。 我们注意到,基于值的特征集(例如,列的统计特性)比基于类型的特征集(例如,列是否分类)对性能的贡献更大,这可能是因为基于值的特征比基于类型的特征多得多。或者,由于许多基于值的功能依赖于列类型,因此基于值的功能和基于类型的功能之间可能存在重叠信息。 特征重要性有助于将我们的结果与之前的文献联系起来,并为基于规则的系统提供设计指南。在这里,我们使用标准平均减少杂质**(MDI)度量**[8,32]来确定性能最佳的随机森林模型的特征重要性。我们之所以选择这种方法,是因为它的可解释性和跨行程的稳定性。五种不同任务的前十项功能如表2a所示,所有其他任务的前十项功能如SM表S3所示。 与列类型(黄色)相关的特性对于每个预测任务都非常重要。例如,数据集是否包含字符串类型列是确定两类可视化类型的第五个最重要特征。可视化类型选择对列数据类型的依赖性与Mackinlay[35]和Cleveland and McGill[15]描述的视觉编码感知属性的类型依赖性一致。 基尼、熵、偏度和峰度等统计特征(定量、分类)在所有方面都很重要。这些高阶矩的存在是惊人的,因为低阶矩(如均值和方差)的重要性很低。这些时刻的重要性突出了捕捉分布形状的高级特征的潜在重要性。这些观察结果支持在可视化推荐中使用统计特性,如[59,70],但也支持在Foresight[16]、VizDeck[43]和Draco[37]等系统中使用高阶特性,如偏度、峰度和熵。 **有序性(绿色)的度量,特别是分类性和单调性,**对于许多任务都很重要。分类定义为列的排序值和未排序值之间的元素相关性,即| corr(Xraw,Xsorted)|,位于[0,1]范围内。单调性是通过严格增加或减少Xraw中的值来确定的。这些特征的重要性可能是由于分析员对数据集进行了预排序,这可能会揭示出哪一列被认为是独立的或解释性的列,这通常是沿着X轴可视化的。虽然直观,但我们还没有看到现有系统中的有序性因素。 我们还注意到线性或对数空间序列系数的重要性,它们是基于启发式的特征,大致捕捉了变化的规模(红色) 。这两个系数在所有四个选定的编码级别预测任务中都很重要。我们还没有看到以前的系统中使用过类似的规模度量。 总之,SM中表2a和表S3中特征的多样性表明,基于规则的推荐系统应该包含比大多数系统所依赖特征的系统更多的特征(例如[34,73])。此外,特定于任务的特征排序,以及模型中的非线性依赖,使得基于规则的系统更难在任务和领域中表现良好,因此进一步强调了基于ML的推荐系统的需求。 我们将有效性的定义从一个二进制扩展到一个可以通过众包共识确定的连续函数。然后,我们描述了从土耳其机械工人那里收集可视化类型评估的实验过程。我们使用基于共识的有效性评分来比较预测这些评估的不同模型。 如第2节所述,我们将数据可视化建模为一个制定一组设计选择C={C}的过程,该选择最大化了有效性标准Eff,该标准取决于数据集d、任务和上下文。在第6节中,我们通过在数据集设计选择对[(d,cd)]语料库上训练机器学习模型来预测这些设计选择。但是因为每个数据集仅由每个用户可视化一次,所以我们认为用户选择c_d是有效的,并且彼此选择无效。也就是说,我们认为有效性是二进制的。 但之前的研究表明,有效性是持续的。例如,Saket等人使用时间和准确性偏好来衡量任务绩效[53],Borkin等人使用标准化记忆分数[6],Cleveland和McGill使用绝对错误率来衡量基本感知任务的绩效[15]。可视化专家[25,29]的讨论还表明,在显示相同数据时,多重可视化同样有效。 我们的有效性度量应该是连续的,并反映数据可视化的模糊性,这会导致多个选择在同一数据集上获得非零甚至最大的分数。这与其他机器学习任务的性能指标一致,比如语言翻译中的BLEU分数[40]和文本摘要中的胭脂度量[11],其中多个结果可能(部分)是正确的。 为了估计这个有效性函数,我们需要观察一个由多个潜在用户可视化的数据集。假设一个设计选项c可以具有多个离散值{v}。例如,我们考虑c是的可视化类型的选择,它可以取值{bar,line, scatter}。使用n_v表示选择v的次数,我们计算做出选择v的概率为ˆP_c(v)=n_v/N,并使用{ˆPc}表示所有v的概率集合。我们通过最大概率来规范选择v的概率,以定义有效性得分ˆEffc(v)=ˆPc(v)/max({Pc})。现在,如果所有N个用户都做出相同的选择v,只有c=v会得到最大分数,其他选择将得到零分。然而,如果两个选项以相同的概率选择,因此两个选项都同样有效,则标准化将确保两个选项都获得最高分数。 开发这种众包评分,反映出做出数据可视化选择的模糊性,有三个主要目的。首先,它可以让我们在模型周围建立不确定性——在本例中,通过引导。其次,它让我们可以测试在Plotly语料库上训练的模型是否可以概括,以及Plotly用户是否真的在做出最佳选择。最后,它让我们可以对Plotly用户的性能以及其他预测指标进行基准测试。 为了生成众包评估数据,我们通过Amazon Mechanical Turk招募并成功预选了300名参与者。为了参与实验,工人们必须持有美国学士学位,年满18岁,并通过电话完成调查。工人们还必须成功地回答三个预筛选问题:1)你见过数据可视化吗?[是或否],2)二维绘图的x轴是水平运行还是垂直运行?[水平、垂直、两者都有,都没有],3)以下哪种可视化是条形图?【条形图、折线图、散点图】。150名工人成功完成了两个类的实验,而150名单独的工人完成了三个类的实验。 在成功完成预筛选后,工作人员评估了从我们的测试集中随机选择的30个数据集的可视化类型。每次评估分为两个阶段。首先,向用户展示了数据集的前10行,并告诉用户“请花点时间检查以下内容”。然后,五秒钟后,“下一步”按钮出现。在下一阶段,用户被问到“哪个可视化最能代表这个数据集?(显示X行中的前10行)。”在这个阶段,向用户展示了数据集以及代表该数据集的相应条形图、线形图和散点图。用户可以在至少十秒钟后提交此问题。通过注意力检查问题将评估分为两组,每组15人。因此,66个数据集中的每个数据集平均评估68.18次,而99个地面真相数据集中的每个数据集平均评估30次。 为了在我们的基准测试集中选择数据集,我们首先随机呈现了一组候选数据集,这些数据集被可视化为条形图、直线图或散点图。然后,我们删除了明显不完整的可视化(例如空白可视化)。最后,我们删除了无法在所有三种可视化类型中进行可视化编码而不丢失信息的数据集。从剩下的候选人中,我们随机选择了33个条形图、33个折线图和33个散点图。 在清理数据时,我们遵循了四个原则:尽可能少地修改用户的选择,将更改一致地应用于每个数据集,依赖于绘图默认值,不做任何不明显的更改。对于每个数据集,我们修改了原始列名,以消除特定于绘图的偏差(例如,删除自动附加到列名的“、x”或“、y”).我们还希望让用户的评估体验尽可能接近原始的图表创建体验。因此,如果从用户可视化轴标签或图例(例如,第一列未标记,但在X轴上显示为萼片宽度),我们将机器生成的类型的列名更改为明显的列名。由于这些修改,Plotly用户和Mechanical Turkers都获得了比我们的模型更多的信息。 我们将**这99个数据集中的每一个可视化为条形图、直线图和散点图。**我们通过分支原始的Plotly可视化,然后使用Plotly Chart Studio修改标记类型,**创建了这些可视化。**我们确保所有可视化类型的颜色选择和轴范围一致。布局的其余部分与用户的原始规范或Plotly提供的默认值保持不变。 我们在基准测试中使用了四种类型的预测因子:人类、基于规则的模型、基于ML的模型和基线。这两个人类预测器是Plotly预测器,它是Plotly用户创建的原始绘图的可视化类型,而MTurk预测器是单个随机Mechanical Turk参与者的选择。在评估单个Mechanical Turk的表现时,该个体的投票被排除在模式估计中使用的投票集之外。这两个基于规则的预测指标包括一个商业系统和另一个研究系统。第一个是Tableau的Show Me功能[34],它基于Mackinlay的APT[35]的表现力和有效性标准。第二个是CompassQL推荐引擎[71],为Voyager和 Voyager 2系统提供动力[72,73]。基于机器学习的两个预测因子是DeepEye和Data2Vis。 在所有情况下,我们都试图在合理的范围内做出最大化预测性能的选择。我们上传了逗号分隔值(CSV)文件数据集在ShowMe、DeepEye和CompassQL,并将其作为JSON对象上传到Data2Vis。不像 VizML和Data2Vis,DeepEye支持饼图、条形图和散点图可视化类型。我们将饼图和条形图建议都标记为条状预测,在两种类型的情况下,将散点图建议标记为直线预测。 对于所有工具,我们都在合理范围内修改了数据,以最大限度地增加有效结果的数量。对于剩余的错误(Data2Vis为4个,DeepEye为14个),以及没有返回结果的情况(DeepEye为12个,CompassQL为33个),我们分配了一个随机图表预测。 预测者的表现被评估为标准化有效性得分的总和。预测因子的一致性调整推荐分数(CARS)定义为: 我们首先使用基尼系数来衡量共识程度,其分布如图4所示。如果对所有可视化都达成了强烈共识,那么基尼分布将强烈地向最大值倾斜,两类情况下为1/2,三类情况下为2/3。相反,较低的基尼意味着较弱的共识,表明理想的视觉化类型模棱两可。基尼分布不偏向任何一个极端,这支持使用软评分指标,比如CARS,而不是像精度这样的硬指标。 同样的结果适用于图5b所示的三类情况,其中VizML的CARS(81.18±2.39)略高于Mechanical Turkers(79.28±4.66)和Plotly用户(79.58±2.44),但误差范围内。Data2Vis(64.75±3.13)和DeepEye(68.09±4.11)的表现优于随机测试(60.37±6.98),具有较大的裕度,但仍在误差范围内。CompassQL(68.95±4.48)略高于Show Me(65.37±2.98),误差也不太大。最低得分为(26.93±3.46)。 在本文中,我们介绍了VizML,这是一种机器学习方法,用于使用大量数据集和相应的可视化推荐。我们确定了五个关键的预测任务,并表明神经网络分类器在这些任务上获得了较高的测试精度,相对于随机猜测和简单分类器。我们还通过众包共识建立的测试集进行基准测试,并表明神经网络的性能与人类个体相当。 可视化系统开发人员有多种途径可以将基于ML的推荐程序(如VizML)纳入创作工作流。除了现有的手动规范工具(如Tableau[62]中的Show Me[34]功能)之外,部分规范建议者还依赖于学习模型提供的设计选择建议。基于代码的创作环境,如Draco[37]和 Vega Lite[55]编辑器可以使用部分规范推荐程序来支持可视化“自动完成”功能,这些功能可以实时建议设计选项,以响应用户交互。Voyager[73]和DIVE[23]等混合倡议系统可以利用Top-N建议,为用户提供一个可视化库,供其搜索和深入研究。设计与基于ML的推荐程序的交互是未来工作的一个重要领域。 为了为自己的系统开发基于ML的推荐程序,开发人员可以从识别用户设计选择和从数据中提取简单特征开始。如果有足够的容量,这些特性和设计选择可以用来训练模型,正如我们在本文中所演示的那样。或者,开发人员可以通过使用预先训练过的模型(如VizML)来克服冷启动问题。有了模型,开发者可以通过收集使用分析(例如,点击和分享等参与度指标)来建立可视化效果的定制指标,从而取得进一步进展。 我们承认Plotly语料库和我们的方法的局限性。首先,尽管采用了积极的重复数据消除,但我们的模型肯定偏向于Plotly数据集。作为一个基于网络的平台,Plotly可以吸引特定的分析师群体,通过界面设计或默认设置鼓励特定类型的绘图,或者更适合特定类型和大小的数据。其次,无论是Plotly用户还是Mechanical Turker 都不是数据可视化方面的专家。第三,我们承认,本文只关注可视化推荐管道中通常考虑的任务的子集。 未来工作的前景在于数据收集和建模方向。在数据方面,需要从其他工具(如多目和表格)获得更多不同的培训数据,并与相邻的数据科学任务(如特征选择和数据转换)相关。更丰富的训练数据使研究人员能够调查之前的偏见问题,使用基于任务(或通常是多目标)的有效性度量优化可视化推荐,推荐数据集的多个视图,研究特征工程的补充方法,并使用概率图形模型整合不同的设计选择建议。 每一个基于ML的推荐模型背后都有一个可视化效果的度量。对于可视化社区来说,确定告知有效性的参数是一个悬而未决的问题。机器学习任务,如图像注释或医学诊断,通常是客观的,因为存在一个明确的人类注释的基本事实。其他任务是主观的,如语言翻译或文本摘要任务,并以人为评估或人为生成的结果为基准。 客观可视化质量问题指向专家在可视化评估中的作用。可视化专家提供的评估是由感知研究的经验和知识提供的。但是,如果外行是可视化的目标受众,众包代理的一致意见可能是衡量可视化质量的一个很好的标准。VizML提供了大量训练语料库、初始机器学习模型和众包基准,是解决这些问题的一个进步。

解释特征重要性

我们首先注意到维度(灰色)的重要性,比如列的长度(即行的数量)或列的数量。例如,列的长度是预测该列是显示为直线还是条形跟踪的第二重要特征。标记类型对视觉元素数量的依赖性与启发式一致,比如“将条形图中的条形总数保持在12以下”,以显示条形图中的个体差异[61],以及不创建包含“超过五到七个”切片的饼图[30]。对列数的依赖性与Bertin[5]描述的启发法有关,并在Show Me[34]中进行了编码。7 基准与众包的有效性
7.1 建模和测量有效性
7.2 基准测试过程与数据准备
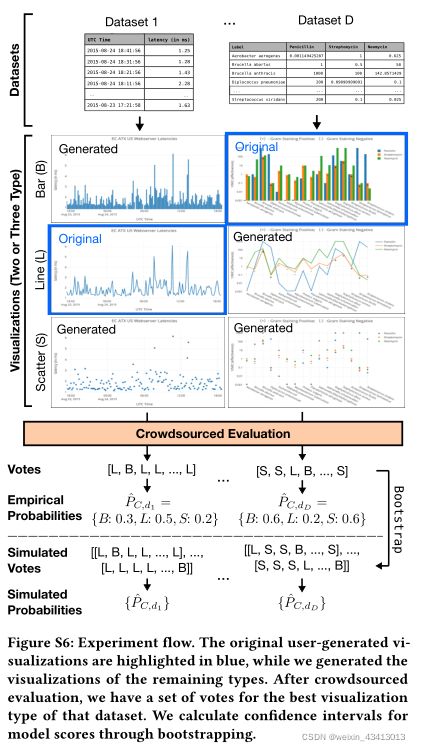
7.2 基准测试程序

其中|D|是数据集的数量(两类66,三类99),ˆc_predictor是数据集D的预测可视化类型,ˆP_c返回给定可视化类型的Mechanical Turker投票分数。请注意,最小CARS>0%。我们通过对比105个投票的自举样本,围绕这些分数建立了95%的置信区间,这些样本可以被认为是从观察到的概率分布中提取的合成投票。7.3 基准测试结果

在图5中,每个模型和任务的一致性调整推荐分数可视化为条形图。我们首先比较两类情况下VizML(88.96±1.66)与Mechanical Turkers(86.66±5.38)和Plotly用户(90.35±1.85)的CARS,如图5a所示。令人惊讶的是,VizML的性能与最初的Plotly用户相当,后者拥有领域知识,并投入时间可视化自己的数据。VizML的表现明显优于Data2Vis(75.61±2.44)和DeepEye(79.12±4.33)。Show Me实现的CARS为(81.70±2.05),与CompassQL(80.98±4.32)相似。虽然其他推荐人没有接受过进行可视化类型预测的培训,但所有推荐人的表现都略好于随机推荐人。对于这项任务,绝对最低得分为(48.61±2.95)。
8 讨论