读懂反向传播算法(bp算法)
读懂反向传播算法(bp算法)
文章目录
- 读懂反向传播算法(bp算法)
-
- 介绍
- 思想
-
- 定义元素
- 损失函数对参数的偏导
- 链式法则
- 总结
介绍
反向传播算法可以说是神经网络最基础也是最重要的知识点。基本上所以的优化算法都是在反向传播算出梯度之后进行改进的。同时,也因为反向传播算法是一个递归的形式,一层一层的向后传播误差即可,很容易实现(这部分听不懂没关系,下面介绍)。不要被反向传播吓到,掌握其核心思想就很容易自己手推出来。
思想
我们知道神经网络都是有一个loss函数的。这个函数根据不同的任务有不同的定义方式,但是这个loss函数的目的就是计算出当前神经网络建模出来输出的数据和理想数据之间的距离。计算出loss之后,根据反向传播算法就可以更新网络中的各种参数以此使loss不断下降,即可使输出的数据更加理想。
所以,现在的任务是,已知一个网络的loss之后,如何根据loss来更新参数呢?具体点即如何更新网络节点中的权重w和偏差b的值呢?
定义元素
这里我们采用的是全连接神经网络进行说明。
要想把这个过程说清楚,首先需要将神经网络中各个参数用文字表达清楚。定义的就是w和b在网络中的准确位置。
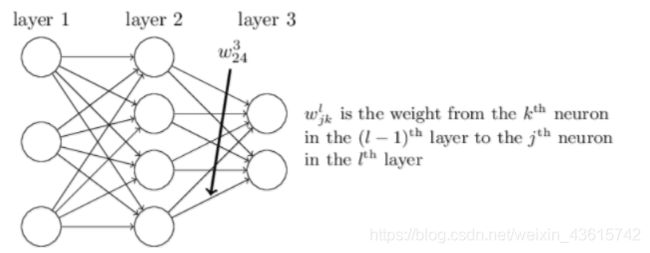
对于 w j k l w _{jk} ^l wjkl表示的是神经网络中第 l − 1 l-1 l−1层第k个节点到神经网络中第 l l l层第j个节点之间的权重。注意w的下标是首位表示的是节点后层节点的位置,末尾表示是前层节点的位置。理解这样的表达方式在后面的计算中会很好理解。
同理,对于b的表示:
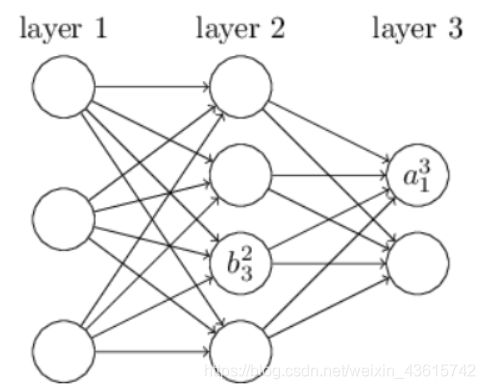
b的表示相比于w要简单一些,符号 b j l b _j ^l bjl表示第l层网络在第j个节点的偏置。无论w还是b的表示,上标都是表示层数。并且 w j k l w _{jk} ^l wjkl和 b j l b _j ^l bjl表示都是第l层网络第j个节点的参数。所以该节点的输出可以表示为:
z j l = ∑ k w j k l a k l − 1 + b j l z_{j}^{l}=\sum_{k} w_{j k}^{l} a_{k}^{l-1}+b_{j}^{l} zjl=k∑wjklakl−1+bjl
神经网络输出之后会经过一个激活函数,这用激活函数用 σ \sigma σ表示,则经过激活函数输出为:
a j l = σ ( z j l ) = σ ( ∑ k w j k l a k l − 1 + b j l ) a_{j}^{l}=\sigma(z_{j}^{l})=\sigma\left(\sum_{k} w_{j k}^{l} a_{k}^{l-1}+b_{j}^{l}\right) ajl=σ(zjl)=σ(k∑wjklakl−1+bjl)
至此,根据上面符号 w j k l w _{jk} ^l wjkl、 b j l b _j ^l bjl、 z j l z_{j}^{l} zjl、 a j l a_{j}^{l} ajl。我们可以对于神经网络里面每一个数据准确的表示了。
损失函数对参数的偏导
给定一个损失函数之后,用 C C C表示,说白了反向传播就是求∂C/∂w和∂C/∂b,然后将这个值乘以和对应的w,b进行相减就可以实现一次的参数更新了。为什么这样的操作就可以优化网络,减小loss值呢?
来源于导数的概念和速度相关。∂C/∂w和∂C/∂b相当于loss值C相对于w和v变化的速度。如果∂C/∂w是正的,则增大w,C也会增大,如果希望C减小的话,应该减小w;并且∂C/∂w的绝对值越大,表示w对C的值影响越大,w稍微有一点变化,C就会有大幅变化。如果要优化C变小,w应该对应的减少多少呢?也没有一个确定的答案。这里通过变化的速度和学习率相乘作为一个减小的值。通过多轮迭代。最终是希望c达到最小点。而当函数落入最小值的时候,无论是局部最小还是全局最小,其周围一定是平滑的。所以此时∂C/∂w和∂C/∂b将会变得很小甚至为0,即参数不在更新了。当函数在局部最小点处参数不在更新出现梯度消失的问题时,目前也有各种trick进行解决。不是这里的重点。
为了好说明,这里定义一个很简单的损失函数C:

C = 1 2 ∥ y − a L ∥ 2 = 1 2 ∑ j ( y j − a j L ) 2 C=\frac{1}{2}\left\|y-a^{L}\right\|^{2}=\frac{1}{2}\sum_{j}\left(y_{j}-a_{j}^{L}\right)^{2} C=21∥∥y−aL∥∥2=21j∑(yj−ajL)2
即:网络输出的值和label之间的均方差。
链式法则
接下来就是有意思的阶段了。这里还是利用上一节中∂C/∂w和∂C/∂b的解释。如果我们想要求出∂C/∂w和∂C/∂b的值,即具体的 w j k l w _{jk} ^l wjkl、 b j l b _j ^l bjl对C影响速率的值,我们找一个中间变量∂C/∂ z j l z_{j}^{l} zjl。因为我们知道:
z j l = ∑ k w j k l a k l − 1 + b j l z _{j}^{l}=\sum _{k} w _{j k} ^{l} a _{k} ^{l-1}+b _{j} ^{l} zjl=k∑wjklakl−1+bjl
我们定义:
δ j l ≡ ∂ C ∂ z j l \delta_{j}^{l} \equiv \frac{\partial C}{\partial z_{j}^{l}} δjl≡∂zjl∂C
当我们知道了 δ j l \delta_{j}^{l} δjl值之后,我们根据 z j l = ∑ k w j k l a k l − 1 + b j l z _{j}^{l}=\sum _{k} w _{j k} ^{l} a _{k} ^{l-1}+b _{j} ^{l} zjl=∑kwjklakl−1+bjl式子可以很容易求出 ∂ C ∂ c j k l \frac{\partial C}{\partial c_{jk}^{l}} ∂cjkl∂C。
利用导数的链式法则:
∂ C ∂ w j k l = ∂ C ∂ z j l ∂ z j l ∂ w j k l = δ j l a k l − 1 \frac{\partial C}{\partial w_{jk}^{l}} =\frac{\partial C}{\partial z_{j}^{l}} \frac{\partial z_{j}^{l}}{\partial w_{jk}^{l}}= \delta_{j}^{l} a _{k} ^{l-1} ∂wjkl∂C=∂zjl∂C∂wjkl∂zjl=δjlakl−1
很容易推出来不是?同理可以求出:
∂ C ∂ b j l = ∂ C ∂ z j l ∂ z j l ∂ b j l = δ j l \frac{\partial C}{\partial b_{j}^{l}} =\frac{\partial C}{\partial z_{j}^{l}} \frac{\partial z_{j}^{l}}{\partial b_{j}^{l}}= \delta_{j}^{l} ∂bjl∂C=∂zjl∂C∂bjl∂zjl=δjl
可以看出通过媒介 δ j l \delta_{j}^{l} δjl很容易求出∂C/∂w和∂C/∂b。那么我们现在来理解一下 δ j l \delta_{j}^{l} δjl到底是什么意思,以及如何求出来每一个l层j节点的 δ j l \delta_{j}^{l} δjl值。
根据定义:
δ j l ≡ ∂ C ∂ z j l \delta_{j}^{l} \equiv \frac{\partial C}{\partial z_{j}^{l}} δjl≡∂zjl∂C
可以看出来 δ j l \delta_{j}^{l} δjl就是 z j l { z_{j}^{l}} zjl对于C的影响大小(联系之前说的导数和速率的关系)。而 z j l z_{j}^{l} zjl是第 l l l层第 j j j个神经元未进过激活函数之前的输出。所以我们可以理解 δ j l \delta_{j}^{l} δjl为网络中第 l l l层第 j j j个神经元对loss的影响。所以很直观的看法就是我们先求出单个神经元对loss值得影响,然后再计算该神经元内部参数对于loss的影响。
ok,如果我们已经理解了为什么要引入 δ j l \delta_{j}^{l} δjl变量以及如何利用该变量计算具体参数的梯度后,接下来我们就可以看看如何获得 δ j l \delta_{j}^{l} δjl值。反向传播的名字我想也就是通过计算 δ j l \delta_{j}^{l} δjl的方式而来的。是一层一层递归而来的。
既然说是递归的方式,我们来思考一下 δ j l \delta_{j}^{l} δjl和 δ k l + 1 \delta_{k}^{l+1} δkl+1之间有什么关系,如果找到这个关系之后,我们就可以默认我们如果知道最后一层网络节点的 δ j l \delta_{j}^{l} δjl值,我们就可以获得倒数第二层网络节点的 δ j l \delta_{j}^{l} δjl值,倒数第三层,倒数第四层,……以此推类即可获得整个网络的每个节点的 δ j l \delta_{j}^{l} δjl值。至此我们的反向传播也基本完成了。
所以最重要的有两点:
- δ j l \delta_{j}^{l} δjl和 δ k l + 1 \delta_{k}^{l+1} δkl+1之间有什么关系
- 假设最后一层网络是L,最后一层 δ j L \delta_{j}^{L} δjL如何计算得出
先看问题1,直接根据求导的链式法则就可以找出两个的关系,具体公式如下,可以多看看手写一下,思路上也很简单。
δ j l = ∂ C ∂ z j l = ∑ k ∂ C ∂ z k l + 1 ∂ z k l + 1 ∂ z j l = ∑ k ∂ z k l + 1 ∂ z j l δ k l + 1 \delta_{j}^{l}=\frac{\partial C}{\partial z_{j}^{l}}=\sum_{k} \frac{\partial C}{\partial z_{k}^{l+1}} \frac{\partial z_{k}^{l+1}}{\partial z_{j}^{l}}=\sum_{k} \frac{\partial z_{k}^{l+1}}{\partial z_{j}^{l}} \delta_{k}^{l+1} δjl=∂zjl∂C=k∑∂zkl+1∂C∂zjl∂zkl+1=k∑∂zjl∂zkl+1δkl+1
觉得这样的链式公式还是很直观的,如果不好理解,可以自己画一个神经网络图,连上节点与节点之间的线,标上参数,然后推一下应该就能理解了。
这里的 z z z都表示的未经过激活函数的神经元的输出。 σ \sigma σ表示激活函数。因为:
z k l + 1 = ∑ j w k j l + 1 a j l + b k l + 1 = ∑ j w k j l + 1 σ ( z j l ) + b k l + 1 z_{k}^{l+1}=\sum_{j} w_{k j}^{l+1} a_{j}^{l}+b_{k}^{l+1}=\sum_{j} w_{k j}^{l+1} \sigma\left(z_{j}^{l}\right)+b_{k}^{l+1} zkl+1=j∑wkjl+1ajl+bkl+1=j∑wkjl+1σ(zjl)+bkl+1
所以:
∂ z k l + 1 ∂ z j l = w k j l + 1 σ ( z j l ) \frac{\partial z_{k}^{l+1}}{\partial z_{j}^{l}}=w_{k j}^{l+1} \sigma\left(z_{j}^{l}\right) ∂zjl∂zkl+1=wkjl+1σ(zjl)
带入上式就可以得出:
δ j l = ∑ k w k j l + 1 δ k l + 1 σ ( z j l ) \delta_{j}^{l}=\sum_{k} w_{k j}^{l+1} \delta_{k}^{l+1} \sigma\left(z_{j}^{l}\right) δjl=k∑wkjl+1δkl+1σ(zjl)
至此就找出了 δ j l \delta_{j}^{l} δjl和 δ k l + 1 \delta_{k}^{l+1} δkl+1之间的关系了。
(还能简化,根据最开始我们定义的 a j l = σ ( z j l ) a_{j}^{l}=\sigma(z_{j}^{l}) ajl=σ(zjl))。
δ j l = ∑ k w k j l + 1 δ k l + 1 a j l \delta_{j}^{l}=\sum_{k} w_{k j}^{l+1} \delta_{k}^{l+1} a_{j}^{l} δjl=k∑wkjl+1δkl+1ajl
理解起来就是网络中前面一层某一个神经元对于loss的影响与该层的后一层所有的神经元对loss的影响、该神经元的输出大小、该神经元与后一层神经元连接的权重有关系的,并且是一个累加的效应。这样的理解也是非常直观合乎常理的。
现在万事具备,只差问题2了。即假设最后一层网络是L,最后一层 δ j L \delta_{j}^{L} δjL如何计算得出。最后一层的 δ j L \delta_{j}^{L} δjL值就像一个导火索,一旦有了开始,就可以利用我们之前推出来的: δ j l = ∑ k w k j l + 1 δ k l + 1 σ ( z j l ) \delta_{j}^{l}=\sum_{k} w_{k j}^{l+1} \delta_{k}^{l+1} \sigma\left(z_{j}^{l}\right) δjl=∑kwkjl+1δkl+1σ(zjl)公式进行反向传播了(反向传播还是很形象的不是?)。现在解决这个问题。这个问题就是和损失函数具体怎么定义有关系了。不过我们先不考虑C的具体形式,根据通用的链式法则我们可以得到:
δ j L = ∑ k ∂ C ∂ a k L ∂ a k L ∂ z j L \delta_{j}^{L}=\sum_{k} \frac{\partial C}{\partial a_{k}^{L}} \frac{\partial a_{k}^{L}}{\partial z_{j}^{L}} δjL=k∑∂akL∂C∂zjL∂akL
这里需要注意的是最后一层激活函数使用的是哪种。最后一层激活函数在计算某一个神经元的输出时可能会结合其他节点的输出来计算。比如softmax激活函数,其输出的是一个概率值【0,1】。输出大小就是结合输出所有的值。
现在我们来考虑两个具体的损失函数,并且采用之前定义的均方误差损失函数 C = 1 2 ∥ y − a L ∥ 2 = 1 2 ∑ j ( y j − a j L ) 2 C=\frac{1}{2}\left\|y-a^{L}\right\|^{2}=\frac{1}{2}\sum_{j}\left(y_{j}-a_{j}^{L}\right)^{2} C=21∥∥y−aL∥∥2=21∑j(yj−ajL)2:
-
sigmoid损失函数
形式: S ( x ) = 1 1 + e − x S(x)=\frac{1}{1+e^{-x}} S(x)=1+e−x1
函数曲线: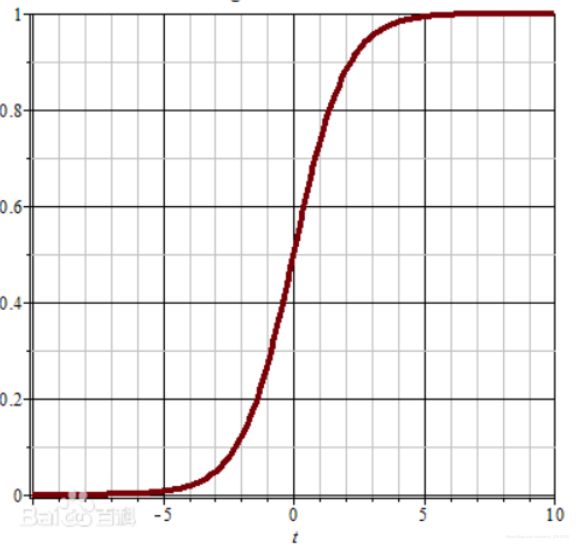
求导为: S ′ ( x ) = e − x ( 1 + e − x ) 2 = S ( x ) ( 1 − S ( x ) ) S^{\prime}(x)=\frac{e^{-x}}{\left(1+e^{-x}\right)^{2}}=S(x)(1-S(x)) S′(x)=(1+e−x)2e−x=S(x)(1−S(x))
因为sigmoid输出的值仅仅和输入的x值有关 。所以 ∂ a k L ∂ z j L \frac{\partial a_{k}^{L}}{\partial z_{j}^{L}} ∂zjL∂akL当 k ≠ j k \neq j k̸=j时值为0.所以:
δ j L = ∑ k ∂ C ∂ a k L ∂ a k L ∂ z j L = ∂ C ∂ a j L ∂ a j L ∂ z j L = ( a j L − y j ) ∗ a j L ( 1 − a j L ) \delta_{j}^{L}=\sum_{k} \frac{\partial C}{\partial a_{k}^{L}} \frac{\partial a_{k}^{L}}{\partial z_{j}^{L}}=\frac{\partial C}{\partial a_{j}^{L}} \frac{\partial a_{j}^{L}}{\partial z_{j}^{L}}=(a_{j}^{L}-y _j)*a_{j}^{L}(1-a_{j}^{L}) δjL=k∑∂akL∂C∂zjL∂akL=∂ajL∂C∂zjL∂ajL=(ajL−yj)∗ajL(1−ajL) -
softmax损失函数
形式: S ( z j ) = e z j ∑ k = 1 K e z k , j = 1 , … , K S(z _{j})=\frac{e^{z_{j}}}{\sum_{k=1}^{K} e^{z_{k}}}, j=1, \ldots, K S(zj)=∑k=1Kezkezj,j=1,…,K
函数形式:输出也是【0,1】的值,不过需要依赖最后一层所有的数来计算分母
求导:- δ S ( z j ) δ z j = S ( z j ) ( 1 − S ( z j ) ) \frac {\delta S(z _{j})} {\delta z _{j}} = S(z _{j})(1-S(z _{j})) δzjδS(zj)=S(zj)(1−S(zj))
- δ S ( z j ) δ z k = − S ( z j ) S ( z k ) , k ≠ j \frac {\delta S(z _{j})} {\delta z _{k}} = -S(z _{j})S(z _k) ,k \neq j δzkδS(zj)=−S(zj)S(zk),k̸=j
所以
δ j L = ∑ k ∂ C ∂ a k L ∂ a k L ∂ z j L = ∂ C ∂ a j L ∂ a j L ∂ z j L − ∑ k ≠ j ∂ C ∂ a k L ∂ a k L ∂ z j L = ( a j L − y j ) ∗ a j L ( 1 − a j L ) − ∑ k ≠ j ( a j L − y j ) ∗ a j L a k L \delta_{j}^{L}=\sum_{k} \frac{\partial C}{\partial a_{k}^{L}} \frac{\partial a_{k}^{L}}{\partial z_{j}^{L}}=\frac{\partial C}{\partial a_{j}^{L}} \frac{\partial a_{j}^{L}}{\partial z_{j}^{L}}-\sum_{k \neq j} \frac{\partial C}{\partial a_{k}^{L}} \frac{\partial a_{k}^{L}}{\partial z_{j}^{L}}=(a_{j}^{L}-y _j)*a_{j}^{L}(1-a_{j}^{L}) -\sum_{k \neq j} (a_{j}^{L}-y _j)*a_{j}^L a_{k}^L δjL=k∑∂akL∂C∂zjL∂akL=∂ajL∂C∂zjL∂ajL−k̸=j∑∂akL∂C∂zjL∂akL=(ajL−yj)∗ajL(1−ajL)−k̸=j∑(ajL−yj)∗ajLakL
总结
根据上面,BP推导有三部曲,先求出 δ j l \delta_{j}^{l} δjl,再根据 δ j l \delta_{j}^{l} δjl分别求出 w j k l w _{jk} ^l wjkl、 b j l b _j ^l bjl。总结公式如下:
δ j l = ∑ k w k j l + 1 δ k l + 1 a j l \delta_{j}^{l}=\sum_{k} w_{k j}^{l+1} \delta_{k}^{l+1} a_{j}^{l} δjl=k∑wkjl+1δkl+1ajl
∂ C ∂ w j k l = ∂ C ∂ z j l ∂ z j l ∂ w j k l = δ j l a k l − 1 \frac{\partial C}{\partial w_{jk}^{l}} =\frac{\partial C}{\partial z_{j}^{l}} \frac{\partial z_{j}^{l}}{\partial w_{jk}^{l}}= \delta_{j}^{l} a _{k} ^{l-1} ∂wjkl∂C=∂zjl∂C∂wjkl∂zjl=δjlakl−1
∂ C ∂ b j l = ∂ C ∂ z j l ∂ z j l ∂ b j l = δ j l \frac{\partial C}{\partial b_{j}^{l}} =\frac{\partial C}{\partial z_{j}^{l}} \frac{\partial z_{j}^{l}}{\partial b_{j}^{l}}= \delta_{j}^{l} ∂bjl∂C=∂zjl∂C∂bjl∂zjl=δjl
启动上面反传的导火索是最后一层的 δ j L \delta_{j}^{L} δjL值,计算公式为:
δ j L = ∑ k ∂ C ∂ a k L ∂ a k L ∂ z j L \delta_{j}^{L}=\sum_{k} \frac{\partial C}{\partial a_{k}^{L}} \frac{\partial a_{k}^{L}}{\partial z_{j}^{L}} δjL=k∑∂akL∂C∂zjL∂akL
根据最后一层不同类型的激活函数不同对待。