文本特征提取
常用数据集数据的结构组成
- 结构:特征值 + 目标值
注:有些数据集可以没有目标值
数据中对于特征的处理
- pandas:一个数据读取非常方便以及基本的处理格式的工具
- sklearn:对于特征的处理提供了强大的接口
Scikit-learn库介绍
- Python 语言的机器学习工具
- Scikit-learn 包括许多机器学习算法的实现。
安装
- 创建一个基于 Python 3的虚拟环境
mkvirtualenv -p /usr/bin/python3.6 ml3
- 在ubuntu的虚拟环境当中运行以下命令
pip3 install Scikit-learn
注:安装scikit-learn需要Numpy, pandas等库
Scikit-learn包括:
-
Classification:分类
-
Regression:回归
-
Clustering:聚类
-
Dimensionality reduction:降维
-
Model selection: 模型选择
-
Preprocessing:特征工程
-
特征抽取对文本等数据进行特征值化
注:特征值化是为了计算机更好的去理解数据
sklearn 特征抽取 API
- sklearn.feature_extraction
1. 字典特征抽取
作用:对字典数据进行特征值化
类:sklearn.feature_extraction.DictVectorizer
DictVectorizer 语法
- DictVectorizer(sparse=True, …)
| 函数 | 参数 | 返回值 |
|---|---|---|
| DictVectorizer.fit_transform(X) | 字典或者包含字典的迭代器 | 返回 sparse 矩阵 |
| DictVectorizer.inverse_transform(X) | array数组或者sparse矩阵 | 转换之前数据格式 |
| DictVectorizer.get_feature_names() | 返回类别名称 | |
| DictVectorizer.transform(X) | 从特性名称到特性值的字典或映射 | 按照原先的标准转换 |
默认参数为sparse=True
sparse=True 时
- 控制台打印sparse矩阵
- 作用:节约内存,方便读取处理
sparse=False 时
- 显示 ndarray 二维数组
from sklearn.feature_extraction import DictVectorizer
def dictvec():
"""
字典数据抽取
:return: None
"""
# 实例化
dict = DictVectorizer(sparse=False) # 调用 sparse=False 显示 ndarray 二维数组
# 调用 fit_transform
data = dict.fit_transform([{'class': '一班', 'number': 40}, {'class': '二班', 'number': 50}, {'class': '三班', 'number': 24}])
print(dict.get_feature_names())
print(data)
return None
if __name__ == '__main__':
dictvec()
代码执行结果:

字典数据抽取:
把字典汇总一些类别数据,分别进行转换成特征数组形式,有类别的这些特征先要转换字典数据
One-hot 编码
[[ 1. 0. 0. 40.]
[ 0. 0. 1. 50.]
[ 0. 1. 0. 24.]]
为每个类别生成一个布尔列。这写列汇总只有一列可以为每个样本取值1。因此,术语一个热编码。
2.文本特征抽取
作用:对文本数据进行特征值化
类:sklearn.feature_extraction.text.CountVectorizer
CountVectorizer语法
- CountVectorizer()
- 返回词频矩阵
| 函数 | 参数 | 返回值 |
|---|---|---|
| CountVectorizer.fit_transform(X) | 文本或者包含文本字符串的可迭代对象 | 返回 sparse 矩阵 |
| CountVectorizer.inverse_transform(X) | array数组或者sparse矩阵 | 转换之前数据格式 |
| CountVectorizer.get_feature_names() | 单词列表 |
from sklearn.feature_extraction.text import CountVectorizer
def countvec():
"""
对文本进行特征值化
:return: None
"""
# 实例化CountVectorizer
cv = CountVectorizer()
# 调用fit_transform输入数据并转换
data = cv.fit_transform(["Time goes by so fast, people go in and out of your life", "You must never miss the opportunity to tell these people how much they mean to you"])
# 打印结果
print(cv.get_feature_names())
# 1.注意返回格式,利用toarray()进行 sparse 矩阵转换 array 数组
print(data.toarray())
return None
if __name__ == '__main__':
countvec()
代码执行结果:
![]()
中文文本特征值化
需要用到的第三方库
jieba 分词
安装: pip3 install jieba
返回值:词语生成器
注:CountVectorizer.fit_transform()函数不支持单个中文字,需要对中文进行分词才能详细的进行特征值化
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def cutword():
sentence1 = jieba.cut("用我们的奋斗和梦想扬起青春的船帆,当我们努力拼搏地摇浆时,成功的闸门也会慢慢地再为我们打开,我们将享受一份青春的美好,收获一份成功的喜悦。")
sentence2 = jieba.cut("曾经自己输掉的东西,只要不是你想,就一定程度可以进行再一点一点赢回来。")
sentence3 = jieba.cut("如果有一个奇迹,世界上真有,它是努力的另一个名称。")
# 转换成列表
conten1 = list(sentence1)
conten2 = list(sentence2)
conten3 = list(sentence3)
# 把列表转换成字符串
c1 = ' '.join(conten1)
c2 = ' '.join(conten2)
c3 = ' '.join(conten3)
return c1, c2, c3
def hanzivec():
"""中文特征值化
对三段话进行特征值化——流程
1. 准备句子,利用jieba.cut进行分词
2. 实例化CountVectorizer
3. 将分词结果变成字符串当作 fit_transform 的输入值
:return: None
"""
c1, c2, c3 = cutword()
print(c1, c2, c3)
cv = CountVectorizer()
data = cv.fit_transform([c1, c2, c3])
print(cv.get_feature_names())
print(data.toarray())
return None
if __name__ == '__main__':
hanzivec()
TF-IDF
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF作用:用以评估一字词对一个文件集或一个语料库中的其中一份文件的重要程度。
- Tf:term frequency:词的频率
- idf:逆文档频率inverse document frequency
- log(总文档数量 / 该词出现的文档数量)
注:log(数值):输入的数值越小,结果越小
tf * idf = 重要性程度
类:sklearn.feature_extraction.text.TfidfVectorizer
TfidfVectorizer语法
- TfidfVectorizer(stop_words=None, …)
- 返回词的权重矩阵
| 函数 | 参数 | 返回值 |
|---|---|---|
| TfidfVectorizer.fit_transform(X) | 文本或者包含文本字符串的可迭代对象 | 返回sparse矩阵 |
| TfidfVectorizer.inverse_transform(X) | array数组或者 sparse 矩阵 | 每个文档的返回关系(含非零条目) |
| TfidfVectorizer.get_feature_names() | 单词列表 |
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
import jieba
def cutword():
sentence1 = jieba.cut("用我们的奋斗和梦想扬起青春的船帆,当我们努力拼搏地摇浆时,成功的闸门也会慢慢地再为我们打开,我们将享受一份青春的美好,收获一份成功的喜悦。")
sentence2 = jieba.cut("曾经自己输掉的东西,只要不是你想,就一定程度可以进行再一点一点赢回来。")
sentence3 = jieba.cut("如果有一个奇迹,世界上真有,它是努力的另一个名称。")
# 转换成列表
conten1 = list(sentence1)
conten2 = list(sentence2)
conten3 = list(sentence3)
# 把列表转换成字符串
c1 = ' '.join(conten1)
c2 = ' '.join(conten2)
c3 = ' '.join(conten3)
return c1, c2, c3
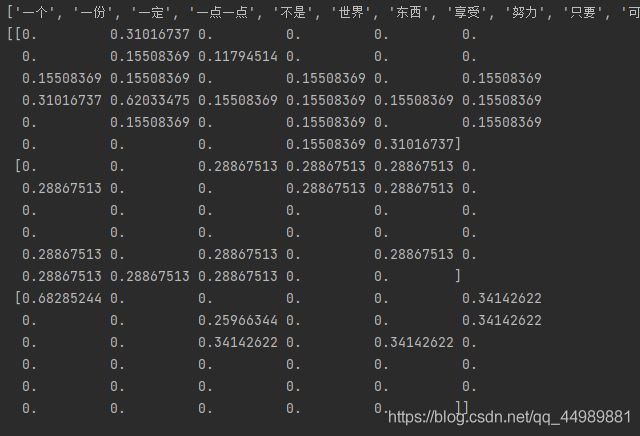
def tfidfvec():
"""
中文特征值化
:return: None
"""
c1, c2, c3 = cutword()
print(c1, c2, c3)
tf = TfidfVectorizer()
data = tf.fit_transform([c1, c2, c3])
print(tf.get_feature_names())
print(data.toarray())
return None
if __name__ == '__main__':
tfidfvec()
代码执行结果: