SwinTransformer细节及代码实现(pytorch版本)
paper: https://arxiv.org/abs/2103.14030
原版code: https://github.com/microsoft/Swin-Transformer
作者分析表明,Transformer从NLP迁移到CV上没有大放异彩主要有两点原因:
- 两个领域涉及的scale不同,NLP的scale是标准固定的,而CV的scale变化范围非常大。
- CV比起NLP需要更大的分辨率,而且CV中使用Transformer的计算复杂度是图像尺度的平方,这会导致计算量过于庞大。为了解决这两个问题,Swin Transformer相比之前的ViT做了两个改进:1.引入CNN中常用的层次化构建方式构建层次化Transformer 2.引入locality思想,对无重合的window区域内进行self-attention计算。

一、文章简介
如图1(a)所示,Swin Transformer通过从小尺寸的patches(以灰色框)开始,并逐渐将相邻patches合并到更深的Transformer层中来构建层次表示。有了这些分层特征映射,Swin Transformer模型可以方便地利用高级技术进行密集预测,如特征金字塔网络(FPN)或U-Net。线性计算复杂性是通过在分割图像的非重叠窗口(用红色标出)内局部计算自我注意来实现的。每个窗口中的patches数是固定的,因此复杂性与图像大小成线性关系。这些优点使Swin Transformer适合作为各种视觉任务的通用主干,这与以前基于Transformer的体系结构]不同,后者生成单一分辨率的特征图,并且具有二次复杂性。
Swin Transformer的一个关键设计元素是在连续的自注意力层之间切换窗口分区,如下图所示。移动的窗口桥接了前一层的窗口,提供了它们之间的连接,显著增强了建模能力。这种策略对于真实世界的延迟也是有效的:一个窗口中的所有query patches都共享相同的 key set,这有助于硬件中的内存访问。相比之下,早期基于滑动窗口的自注意力在通用硬件上的延迟较低,因为不同query像素的key sets不同。移位窗口方法的延迟比滑动窗口方法低得多,但建模能力相似。事实证明,移位窗口方法也适用于所有MLP体系结构。
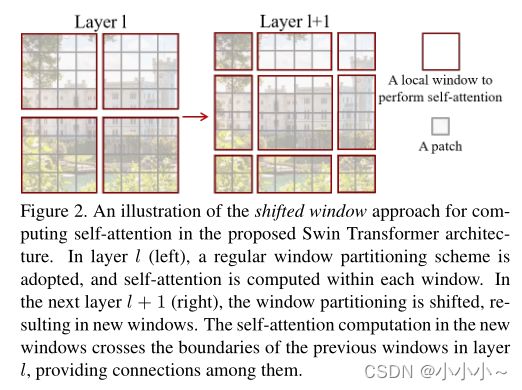
在所提出的Swin Transformer架构中,上图一个用于计算自注意力的移位窗口方法的示例。在l层(左),采用规则的窗口划分方案,并在每个窗口内计算自注意力。在下一层l+1(右)中,窗口分区被移动,从而产生新的窗口。新窗口中的自我注意计算跨越了层l中以前窗口的边界,提供了它们之间的连接。
二、整体实现

Transformer体系结构的概述,它展示了微型版本(SwinT)。它首先通过patch splitting module(如ViT)将输入的RGB图像分割为非重叠 patch。每个 patch被视为一个“token”,其特征被设置为原始像素RGB值之间的串联。在我们的实现中,我们使用4×4的patch大小,因此每个patch的特征维数为4×4×3=48。在该原始值特征上应用线性嵌入层,将其投影到任意维度(表示为C),patch块的数量为H/4 x W/4。
class PatchEmbed(nn.Module):
r""" patch splitting
Args:
img_size (int): 输入图片的尺寸
patch_size (int): Patch token的尺度. Default: 4.
in_chans (int): 输入通道的数量
embed_dim (int): 线性投影后输出的维度
norm_layer (nn.Module, optional): 这可以进行设置,在本层中设置为了None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=512, embed_dim=96, norm_layer=None):
super().__init__()
# 先将img_size、patch_size转化为元组模式(224 , 224) 、 (4 , 4)
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
# 计算出 Patch token在长宽方向上的数量
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
# 计算出patch的数量利用Patch token在长宽方向上的数量相乘的结果
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
# 判断是否使用norm_layer,在这里我们没有应用
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
# 解析输入的维度
B, C, H, W = x.shape
# 判断图像是否与设定图像一致,如果不一致会报错
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
# 经过一个卷积层来进行一个线性变换,并且在第二个维度上进行一个压平操作,维度为(B, C, Ph*Pw),后在进行一个维与二维的一个转置,维度为:(B Ph*Pw C)
x = self.proj(x).flatten(2).transpose(1, 2)
if self.norm is not None:
x = self.norm(x)
return x
在这些patch tokens上应用了几个Swin Transformer blocks的bolck。Transformer blocks 与patch tokens数量(h/4×w/4)一致,与线性嵌入一起被称为“阶段1”。
为了产生分层表示,随着网络的深入,通过patch合并层来减少patch tokens的数量。第一个patch合并层连接每个2×2相邻patch的特征(如下图红色框内的patch将合并成一组),并在4C维连接的特征上应用线性层。这将patch tokens的数量减少了2×2=4的倍数(分辨率的2×降采样),并且输出维度设置为2C。
lass PatchMerging(nn.Module):
r""" Patch合并.
Args:
input_resolution (tuple[int]): 输入特征的分辨率.
dim (int): 输入通道的数量
norm_layer (nn.Module, optional): 定义Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
# 通过一个线性层将4C降为2C
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
# 解析输入图像的分辨率,即输入图像的长宽
H, W = self.input_resolution
# 解析输入图像的维度
B, L, C = x.shape
# 判断L是否与H * W一致,如不一致会报错
assert L == H * W, "input feature has wrong size"
# 判断输入图像的长宽是否可以被二整除,因为我们是通过2倍来进行下采样的
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
# 将xreshape为维度:(B, H, W, C)
x = x.view(B, H, W, C)
# 切片操作,通过切片操作将将相邻的2*2的patch进行拼接
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
# 将合并好的patch通过c维进行拼接
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
# 将x的维度重置为B H/2*W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
# 通过一个线性层进通道降维
x = self.reduction(x)
return x
然后应用Swin Transformer blocks进行特征变换,分辨率保持在h/8×w/8。第一个patch merging和特征转换块被称为“阶段2”。该过程重复两次,分别为“阶段3”和“阶段4”,输出分辨率分别为H/16×W/16和H/32×W/32。这些阶段共同产生了一种阶段的表示。一种具有与典型卷积网络相同的特征图分辨率,例如VGG和ResNe。因此,所提出的体系结构可以方便地替代现有方法中用于各种视觉任务的主干网络。
下面先实现一下下图中的代码:

class SwinTransformerBlock(nn.Module):
r""" Swin Transformer Block.
Args:
dim (int): 输入维度的数量
input_resolution (tuple[int]): 输入图像的分辨率
num_heads (int): 应用注意力头的数量
window_size (int): 窗口的尺寸
shift_size (int): SW-MSA的循环位移的大小,默认为零
mlp_ratio (float): mlp的隐层的比例,默认为零
qkv_bias (bool, optional): 是否应用位移偏量,具体实现在下文
qk_scale (float | None, optional): 如果设置,默认qk覆盖head_dim ** -0.5。
drop (float, optional): Dropout比例,防止过拟合的操作,默认为零
attn_drop (float, optional): AttentionDropout比例,默认为零
drop_path (float, optional): 随机深度比率,默认为0.0
act_layer (nn.Module, optional): 激活函数层,默认为GELU
norm_layer (nn.Module, optional): Normalization层, 默认为 nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
if min(self.input_resolution) <= self.window_size:
# 如果Windows大小大于输入分辨率,则不分区Windows
self.shift_size = 0
self.window_size = min(self.input_resolution)
# 如果Windows大小不符合指定的数值,则报错
assert 0 <= self.shift_size < self.window_size,
self.norm1 = norm_layer(dim)
# 窗口注意力,在接下来进行详细说明
self.attn = WindowAttention_acmix(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
if self.shift_size > 0:
# 判断是否使用窗口移位,如果使用窗口移位,会使用mask windows,会在下文中进行分开讲解
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1))
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size)
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
# 向模块添加一个attn_mask的持久缓冲区
self.register_buffer("attn_mask", attn_mask)
def forward(self, x):
#解析输入图像的分辨率
H, W = self.input_resolution
# 解析输入的维度
B, L, C = x.shape
# 判断L和H * W是否一致
assert L == H * W, "input feature has wrong size"
# 进行原始的身份映射
shortcut = x
# 首先经过以一个LN层
x = self.norm1(x)
# 将维度重置为(B, H, W, C)
x = x.view(B, H, W, C)
# 判断是否进行循环移位
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
shifted_x = self.attn(shifted_x, H, W, mask=self.attn_mask)
# 循环移位进行恢复
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x

Swin Transformer是通过将Transformer块中的标准多头自注意力(MSA)模块替换为基于移动窗口的模块构建的,其他层保持不变。如下图所示,Swin Transformer block由一个基于移位窗口的MSA模块组成,然后是一个中间带有GELU非线性的两层MLP。在每个MSA模块和每个MLP之前应用LayerNorm(LN)层,在每个模块之后应用残差连接。

标准Transformer架构及其对图像分类的适应都会进行全局自注意力,其中会计算patch tokens和所有其他patch tokens之间的关系。全局计算导致patch tokens数量的二次复杂性,这使得它不适用于许多需要大量patch tokens进行密集预测或表示高分辨率图像的视觉问题。
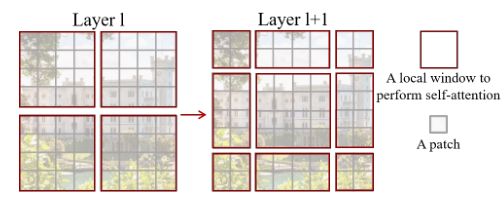
上图中红色区域是window,灰色区域是patch。W-MSA将输入图片划分成不重合的windows,然后在不同的window内进行self-attention计算。假设一个图片有hxw的patches,每个window包含MxM个patches,那么MSA和W-MSA的计算复杂度分别为:
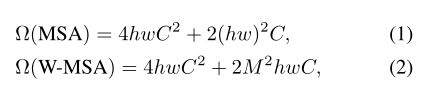
由于window的patch数量远小于图片patch数量,W-MSA的计算复杂度和图像尺寸呈线性关系。
基于窗口的自我关注模块缺乏跨窗口连接,这限制了其建模能力。为了在保持非重叠窗口高效计算的同时引入跨窗口连接,作者提出了一种移位窗口划分方法,该方法在连续的Swin
Transformer blocks中交替使用两种划分配置。
如上图所示,第一个模块使用从左上角像素开始的常规窗口分割策略,将8×8特征图均匀地分割为大小为4×4(M=4)的2×2窗口。然后,下一个模块通过将窗口从规则分区的窗口置换(m/2,m/2)像素,采用与前一层的窗口配置不同的窗口配置。使用移位窗口划分方法,连续的Swin Transformer blocks计算如下:

W-MSA和SW-MSA分别表示使用规则和移位窗口分区配置的基于窗口的多头自注意力。
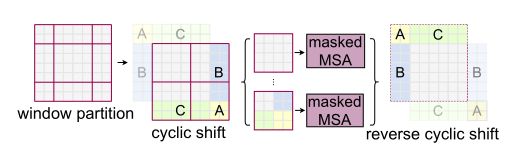
位移窗口如上:
移位窗口分区的一个问题是,它将导致更多窗口,在移位配置中从 ⌈ h / m ⌉ ∗ ⌈ w / m ⌉ \lceil{h/m}\rceil * \lceil{w/m}\rceil ⌈h/m⌉∗⌈w/m⌉到 ( ⌈ h / m ⌉ + 1 ) ∗ ( ⌈ w / m ⌉ + 1 ) (\lceil{h/m}\rceil+1) * (\lceil{w/m}\rceil+1) (⌈h/m⌉+1)∗(⌈w/m⌉+1),并且一些窗口将小于M×M。一个简单的解决方案是将较小的窗口填充到M×M的大小,并在计算注意力时屏蔽填充值。当常规分区中的窗口数很小时(例如2×2),使用这种原始解决方案增加的计算量相当大(2×2)→ 3×3,即2.25倍大)。在这里,作者提出了一种更有效的批量计算方法,方法是向左上方向循环移位。在这个移位之后,一个批处理窗口可能由几个在特征图中不相邻的子窗口组成,因此使用掩蔽机制将自我注意计算限制在每个子窗口内。通过循环移位,批处理窗口的数量与常规窗口分区的数量相同,因此也是有效的。
在计算自注意力时,计算每个头部的相对位置偏差 B ∈ R M 2 ∗ M 2 B∈R^{M^2 * M^2 } B∈RM2∗M2相似性时:
![]()
其中 Q , K , V ∈ R M 2 × d Q,K,V∈ R^{M^2×d} Q,K,V∈RM2×d是查询、键和值query, key and value矩阵;d是query/key 维度, M 2 M^2 M2是窗口中的patches。因为每个轴的相对位置都在这个范围内[−M+1,M− 1] ,作者将一个较小的偏差矩阵参数化 B ^ ∈ R ( 2 M − 1 ) × ( 2 M − 1 ) \hat{B}∈ R^{(2M−1) ×(2M−1)} B^∈R(2M−1)×(2M−1) ,B中的值取自 B ^ \hat{B} B^。
如下所示,与没有这个偏差项或使用绝对位置嵌入的对应项相比,有显著的改进。因此实现中不采用绝对位置嵌入。预训练中学习到的相对位置偏差也可用于初始化模型,以便通过双三次插值以不同的窗口大小进行微调。
对于滑动窗口,如下所示:


其中的SW-MSA代码如下:
一下代码以input_resolution为(7, 7),window_size为(4, 4),shift_size为(1, 1)
# 指定window大小,重新划分window
def window_partition(x, window_size: int):
# 将feature map(image mask) 按照 window_size的大小 划分成一个个没有重叠的window
B, H, W, C = x.shape
# [B, H//M, MH, W//M, MW, C] MH: 为窗口H MW:为窗口W
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
# permute: [B, H//M, MH, W//M, MW, C] -> [B, H//M, W//M, MH, MW, C]
# contiguous(): 变为内存连续的数据
# view: [B, H//M, W//M, M, M, C] -> [B * window_num, MH, MW, C]
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
# 最后会返回一个带有窗口数量以及窗口长宽的一个张量
return windows
if self.shift_size > 0:
# 判断是否使用SW-MSA,如果使用窗口移位,会使用mask windows
# 解析输入图像的分辨率
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
# 其中的切片操作划分后的结构如上图,切出每个窗口中分别具有相似元素的位置
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
# 开始切片,并且将相同的位置附上相同的数值
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
# nW, window_size, window_size, 1
mask_windows = window_partition(img_mask, self.window_size)
# [B * window_num * C, MH*MW]
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
# mask_windows.unsqueeze(1) 将每个窗口的行向量复制MH*MW次
# mask_windows.unsqueeze(2) 将每个窗口的行向量中每个元素 复制MH*MW次
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
# 同一区域为0 不同区域为非0数。 得到当前窗口中对应某一个像素 所采用的attention mask。
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
if self.shift_size > 0.:
# SW-MSA 从上往下 从左往右
# 上面的shift size移动到下面 左边移动右边
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
# W-MSA
shifted_x = x
attn_mask = None
经过一个重新的拼接之后就变成了如下图:图中虚线框为最后的效果
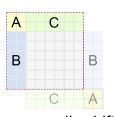
移动相关的位置之后就需要进行WindowAttention了
下图为下列代码中一些接口的演示

#
class WindowAttention(nn.Module):
r""" 基于相对位置偏差的窗口多头自注意(W-MSA)模块。
它同时支持W-MSA和SW-MSA
Args:
dim (int): 输入通道的数量
window_size (tuple[int]): window的长和宽.
num_heads (int): attention heads的数量.
qkv_bias (bool, optional): 如果为True,则向query, key, value添加一个可学习的偏差。默认值: True
qk_scale (float | None, optional): 如果设置,覆盖head_dim ** -0.5的默认qk值
attn_drop (float, optional): attention weight丢弃率,默认: 0.0
proj_drop (float, optional): output的丢弃率. 默认:: 0.0
"""
# 实现W-MSA SW-MSA
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super(WindowAttention, self).__init__()
self.dim = dim
self.window_size = window_size ## Mh, Mw
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# 定义相对位置偏差的参数表 (2*Mh-1 * 2*Mw-1, nH)
self.relative_positive_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)
))
# 获取窗口内每个token的成对相对位置索引
# 第一行为feature map中每一个像素对应的行标(x)
# 第二行为feature map中每一个像素对应的列标(y)
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
# 拼接成横纵坐标
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # [2, Mh, Mw]
# 沿着Mh这一维度进行展平
coords_flatten = torch.flatten(coords, 1) # [2, Mh*Mw] 绝对位置索引
# [2, Mh*Mw, 1] - [2, 1, Mh*Mw]
# [2, Mh*Mw, Mh*Mw] 得到相对位置索引的矩阵。 以每一个像素作为参考点 - 当前feature map/window当中所有的像素点绝对位置索引 = 得到相对位置索引的矩阵
# coords_flatten[:, :, None] 按w维度 每一行的元素复制
# coords_flatten[:, None, :] 按h维度 每一行元素整体复制
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
# permute: 将窗口中按每个像素求得的相对位置索引 组成矩阵
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # [Mh, Mw, 2]
# 二元索引->一元索引
relative_coords[:, :, 0] += self.window_size[0] - 1
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # [Mh*Mw, Mh*Mw]
# 放到模型缓存中
self.register_buffer('relative_position_index', relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
nn.init.trunc_normal_(self.relative_positive_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask: Optional[torch.Tensor] = None):
# 解析输入维度[batch_size * num_windows, Mh*Mw, total_embed_dim]
B_, N, C = x.shape
# qkv: -> [batch_size * num_windows, Mh*Mw, 3 * total_embed_dim]
# reshape: -> [batch_size * num_windows, Mh*Mw, 3, num_heads, embed_dim_per_head]
# permute: -> [3, batch_size * num_windows, num_heads, Mh*Mw, embed_dim_per_head]
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# [batch_size * num_windows, num_heads, Mh*Mw, embed_dim_per_head]
q, k, v = qkv.unbind(0)
q = q * self.scale
# transpose: -> [batch_size * num_windows, num_heads,embed_dim_per_head, Mh*Mw]
# @: multiply: -> [batch_size * num_windows, num_heads, Mh*Mw, Mh*Mw]
attn = (q @ k.transpose(-2, -1))
# self.relative_positive_bias_table.view: -> [Mh*Mw*Mh*Mw, num_head] -> [Mh*Mw, Mh*Mw, num_head]
relative_position_bias = self.relative_positive_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # [num_head, Mh*Mw, Mh*Mw]
# [batch_size * num_windows, num_heads, Mh * Mw, Mh * Mw]
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
# mask: [num_windows, Mh*Mw, Mh*Mw]
num_window = mask.shape[0]
# view: [batch_size, num_windows, num_heads, Mh * Mw, Mh * Mw]
# mask: [1, num_windows, 1, Mh*Mw, Mh*Mw]
attn = attn.view(B_ // num_window, num_window, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
# [batch_size*num_windows, num_heads, Mh * Mw, Mh * Mw]
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
# @: [batch_size*num_windows, num_heads, Mh * Mw, embed_dim_per_head]
# transpose: [batch_size*num_windows, Mh * Mw, num_heads, embed_dim_per_head]
# reshape: [num_windows, Mh * Mw, num_heads*embed_dim_per_head]
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
整体代码如下:
class SwimTransformerBlock(nn.Module):
def __init__(self, dim, num_heads, window_size=7, shift_size=0., mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super(SwimTransformerBlock, self).__init__()
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim=dim, window_size=(self.window_size, self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = (int(dim * mlp_ratio))
self.mlp = MLP(in_features=dim, hidden_features=mlp_hidden_dim, act=act_layer, drop=drop)
def forward(self, x, attn_mask):
H, W = self.H, self.W # feature map H W
B, L, C = x.shape # L = H * W
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
x_r = (self.window_size - W % self.window_size) % self.window_size
x_d = (self.window_size - H % self.window_size) % self.window_size
x = F.pad(x, (0, 0, 0, x_r, 0, x_d))
_, Hp, Wp, _ = x.shape # Hp Wp代表padding后的H W
if self.shift_size > 0.:
# SW-MSA 从上往下 从左往右
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2)) # 上面的shift size移动到下面 左边移动右边
else:
# W-MSA
shifted_x = x
attn_mask = None
# 特征图切成小窗口
x_windows = window_partition(shifted_x, self.window_size) # [B * window_num, MH, MW, C]
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # [B * window_num, MH*MW, C]
# W-MSA SW-MSA
attn_windows = self.attn(x_windows, mask=attn_mask)
# 小窗口合并成特征图
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C) # [B * window_num, MH, MW, C]
shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp) # [B, H, W, C]
# SW-MSA后还原数据 从下往上 从右往左
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
# 移除padding
if x_r > 0 or x_d > 0:
x = x[:, :H, :W, :].contiguous()
x = x.view(B, H * W, C)
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x

实验结果

