2020讯飞开发者大赛,温室温度预测baseliene,mse =0.12389
官网
回归问题,提供的特征值包括室内外的湿度,室内外的气压,室外的温度,预测室内的温度。
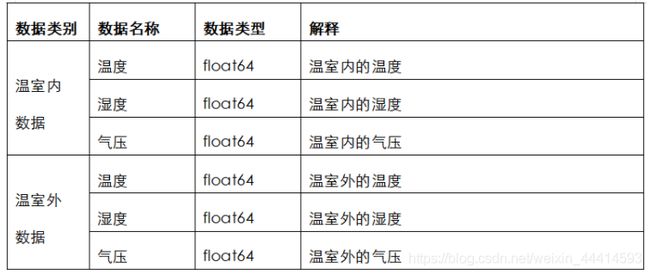
方案流程
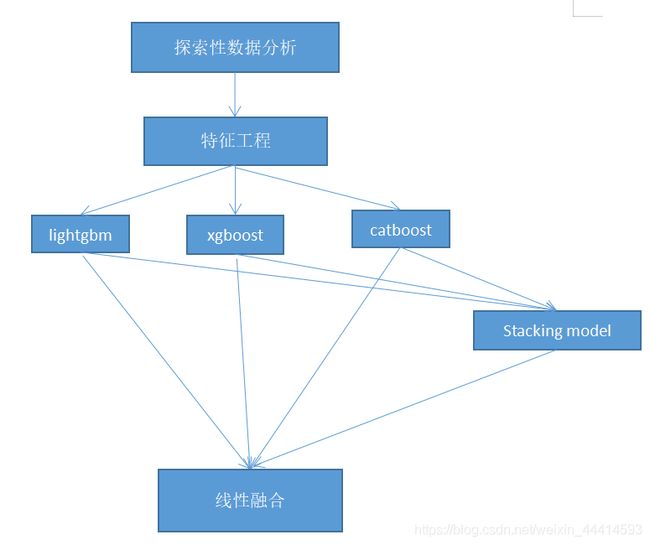
baseline & code
PART1 eda
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm
from scipy import stats
import gc
plt.rcParams['font.sans-serif']=['Songti SC'] #用来正常显示中文标签
import warnings
warnings.filterwarnings('ignore')
train_data = pd.read_csv('C:/ml_data/kdxf/train/train.csv')
test_data = pd.read_csv('C:/ml_data/kdxf/test/test.csv')
train_data.columns = ['timestamp', 'year', 'month', 'day', 'hour', 'min', 'sec', 'outtemp', 'outhum', 'outatmo',
'inhum', 'inatmo', 'temperature']
test_data.columns = ['timestamp', 'year', 'month', 'day', 'hour', 'min', 'sec', 'outtemp', 'outhum', 'outatmo',
'inhum', 'inatmo']
异常值处理
本例中需要先做异常值处理,因为缺失值填充需要用到临近值,如果异常值没有处理的话可能用到了异常值。
plt.plot(train_data['outatmo'][0:3000])
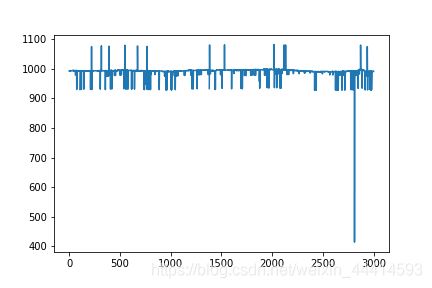
原始数据中,室内外的气压值,有很多数据值过小(400多),也有很多数据值过大(1600多),我在网上查阅资料得知,一天中气压值上下浮动几十是正常的,像这种气压骤降到400多明显是异常值。本例中气压值在900~1100中视为正常值。本例中异常值按照缺失值处理,使用临近点的数值,按照时间差进行线性填充。
#训练集outatmo并没有连续的异常值
for i in tqdm(range(1,len(train_data)-1)):
if train_data['outatmo'][i] < 800 or train_data['outatmo'][i] > 1200:
train_data['outatmo'][i] = train_data['outatmo'][i-1] + (train_data['outatmo'][i+1] - train_data['outatmo'][i-1])*(train_data['timestamp'][i]-train_data['timestamp'][i-1])/(train_data['timestamp'][i+1]-train_data['timestamp'][i-1])
#训练集inatmo并没有连续的异常值
for i in tqdm(range(1,len(train_data)-1)):
if train_data['inatmo'][i] < 950 or train_data['inatmo'][i] > 1200:
train_data['inatmo'][i] = train_data['inatmo'][i-1] + (train_data['inatmo'][i+1] - train_data['inatmo'][i-1])*(train_data['timestamp'][i]-train_data['timestamp'][i-1])/(train_data['timestamp'][i+1]-train_data['timestamp'][i-1])
#测试集outatmo并不认为存在异常值
#测试集inatmo并没有连续的异常值
for i in tqdm(range(1,len(test_data)-1)):
if test_data['inatmo'][i] < 950 or test_data['inatmo'][i] > 1200:
test_data['inatmo'][i] = test_data['inatmo'][i-1] + (test_data['inatmo'][i+1] - test_data['inatmo'][i-1])*(test_data['timestamp'][i]-test_data['timestamp'][i-1])/(test_data['timestamp'][i+1]-test_data['timestamp'][i-1])
下面这种图是异常值处理之前的测试集气压值。
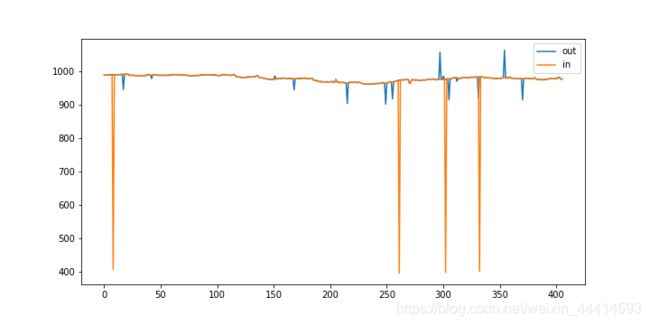
室外气压看起来还比较正常,室内气压存在几处骤降,室内外气压差达到了600,按照物理原理来说,室内外气压差这么大,怕不是温室要爆炸了吧。
修改后的测试集气压值。
plt.figure(figsize=(10,5))
plt.plot([x for x in range(0,len(test_data))], test_data['outatmo'], label='out')
plt.plot([x for x in range(0,len(test_data))], test_data['inatmo'], label='in')
plt.legend()
plt.show()
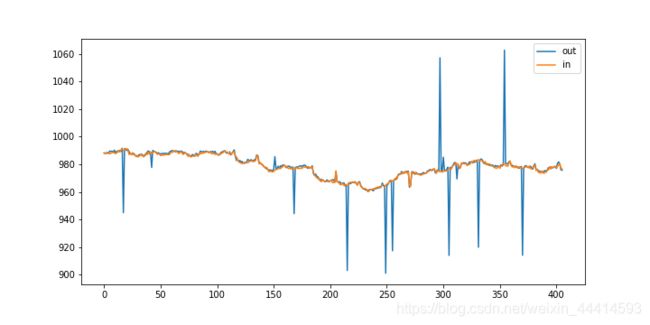
室内的气压值比较平缓,符合常识,室外的气压存在少量波动,波动的数值在几十之内,也符合常识。
训练集缺失值处理
tempeture(预测值)的缺失行直接删除。保留了97.29%的数据。
tempa_miss = [x for x in range(len(train_data['temperature'].isnull())) if train_data['temperature'].isnull()[x] == True]
len_0= train_data.shape[0]
train_data = train_data.drop(axis=0,index = tempa_miss).reset_index()
len_1 = train_data.shape[0]
print('remain_ratio :',len_1/len_0)
del train_data['index']
特征的缺失值处理
室外的温度,气压的湿度存在缺失,
train_features_with_missing = ['outtemp','outhum','outatmo']
使用临近点的数值,做按照时间差,线性融合填充。
for feature_single in tqdm(train_features_with_missing):
miss_index = [x for x in range(len(train_data[feature_single].isnull())) if train_data[feature_single].isnull()[x] == True]
for index in miss_index:
value_last = train_data[feature_single][index - 1]
j = 1
while True:
if train_data[feature_single][index +j] > 0:
break
j += 1
ratio_ = (train_data['timestamp'][index] - train_data['timestamp'][index-1])/(train_data['timestamp'][index+j] - train_data['timestamp'][index-1])
train_data[feature_single][index] = ratio_*(train_data[feature_single][index +j] - train_data[feature_single][index - 1] ) + train_data[feature_single][index - 1]
测试集缺失值填充
test_features_with_missing = ['outtemp','outhum','outatmo','inhum','inatmo']
都是使用临近点的数值,做按照时间差,线性融合填充。
for feature_single in tqdm(test_features_with_missing):
miss_index = [x for x in range(len(test_data[feature_single].isnull())) if test_data[feature_single].isnull()[x] == True]
for index in miss_index:
value_last = test_data[feature_single][index - 1]
j = 1
while True:
if test_data[feature_single][index +j] > 0:
break
j += 1
ratio_ = (test_data['timestamp'][index] - test_data['timestamp'][index-1])/(test_data['timestamp'][index+j] - test_data['timestamp'][index-1])
test_data[feature_single][index] = ratio_*(test_data[feature_single][index +j] - test_data[feature_single][index - 1] ) + test_data[feature_single][index - 1]
删除冗余和无用的特征,修改特征
del train_data['timestamp']
del test_data['timestamp']
train_data['day'] = (train_data['month'] - 3) * 31 + train_data['day']
test_data['day'] = (test_data['month'] - 3) * 31 + test_data['day']
del train_data['year']
del train_data['month']
del test_data['year']
del test_data['month']
train_data['min'] = train_data['hour'] * 60 + train_data['min']
test_data['min'] = test_data['hour'] * 60 + test_data['min']
train_data['sec'] = train_data['min'] * 60 + train_data['sec']
test_data['sec'] = test_data['min'] * 60 + test_data['sec']
目标值从室内温度修改为室内外温度差。
train_data['gaptemp'] = train_data['temperature'] - train_data['outtemp']
del train_data['temperature']
all_data = pd.concat([train_data,test_data], axis=0, ignore_index=True)
还有一种异常值需要处理。
tt = [x for x in all_data['outhum']]
yy = [x for x in all_data['inhum']]
plt.plot(tt[0:30000)
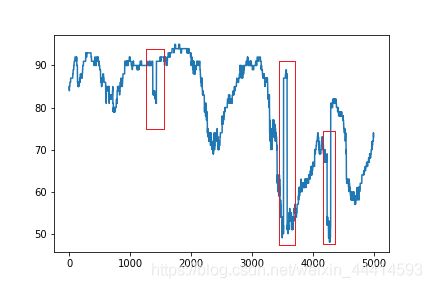
可以看到,在某些片刻,数据值突然增大或者减小好多,而且预测值室内温度在相同时间也受到了影响。

PS:本博文中的图片和原始数据的图片存在一些差异,因为我在做eda的时候并没有保存原始图片,现在是稍微复现一下eda的过程。
我个人怀疑是某些时刻传感器故障,或者当时在进行什么实验造成了数据波动,亦或是数据提供方中国农业大学人工制造的数据异常,你们也太坏了,你妈妈出门买菜必涨价,超级加倍!
这种异常就不能按照常规的异常值处理了,因为预测值缺失受到了这种异常的影响,所以我新增了一个特征’up_wave’表示这种波动。'up_wave’表示波动的百分比,向上为正。
for i in tqdm(range(23831,23840)):
all_data['up_wave'][i] = (1-(i-23831)/(23840-23831)) * (11.39240506329114)
'up_wave’的数值填充纯手工填充的,数据量不多工作量不大,代码实现较难,这里仅展示部分填充的代码,因为其他的填充代码我都删了,jupyter notebook。。。。。。
查看预测值正态化程度
train_data['gaptemp'].skew()
-1.4887741645252575
train_data['gaptemp'].kurt()
3.352724719572008
偏度可以接受,不做正态化处理了。
PS:事后分析,当初还是应该做正态化处理的。偏度越小越好,而不是偏度小于某个阈值后就可以不处理了。
基础特征
all_data.columns
Index([‘day’, ‘gaptemp’, ‘hour’, ‘inatmo’, ‘inhum’, ‘min’, ‘outatmo’, ‘outhum’,
‘outtemp’, ‘sec’, ‘up_wave’],
dtype=‘object’)
新增特征
室内外湿度/气压的差值,以及比例。
all_data = pd.concat([train_data,test_data], axis=0, ignore_index=True)
all_data['gapatmo'] = all_data['inatmo'] - all_data['outatmo']
all_data['gaphum'] = all_data['inhum'] - all_data['outhum']
all_data['gapatmo_ratio'] = all_data['gapatmo'].values/all_data['outatmo'].values * 10000
all_data['gaphum_ratio'] = all_data['gaphum'].values/all_data['outhum'].values * 100
统计特征,数据点所在的一个小时之内的均值,中位数,最大小值等
group_features = []
for f in tqdm(['outtemp', 'outhum', 'outatmo', 'inhum', 'inatmo']):
all_data['MDH_{}_medi'.format(f)] = all_data.groupby(['day', 'hour'])[f].transform('median')
all_data['MDH_{}_mean'.format(f)] = all_data.groupby(['day', 'hour'])[f].transform('mean')
all_data['MDH_{}_max'.format(f)] = all_data.groupby(['day', 'hour'])[f].transform('max')
all_data['MDH_{}_min'.format(f)] = all_data.groupby(['day', 'hour'])[f].transform('min')
all_data['MDH_{}_std'.format(f)] = all_data.groupby(['day', 'hour'])[f].transform('std')
group_features.append('MDH_{}_medi'.format(f))
group_features.append('MDH_{}_mean'.format(f))
all_data = all_data.fillna(method='bfill')
for f in tqdm(['gapatmo','gaphum','gapatmo_ratio','gaphum_ratio']):
all_data['MDH_{}_medi'.format(f)] = all_data.groupby(['day', 'hour'])[f].transform('median')
all_data['MDH_{}_mean'.format(f)] = all_data.groupby(['day', 'hour'])[f].transform('mean')
all_data['MDH_{}_max'.format(f)] = all_data.groupby(['day', 'hour'])[f].transform('max')
all_data['MDH_{}_min'.format(f)] = all_data.groupby(['day', 'hour'])[f].transform('min')
all_data['MDH_{}_std'.format(f)] = all_data.groupby(['day', 'hour'])[f].transform('std')
all_data = all_data.fillna(method='bfill')
室内外气压,湿度的特征组合
for f1 in tqdm(['outtemp', 'outhum', 'outatmo', 'inhum', 'inatmo'] + group_features):
for f2 in ['outtemp', 'outhum', 'outatmo', 'inhum', 'inatmo'] + group_features:
if f1 != f2:
colname = '{}_{}_ratio'.format(f1, f2)
all_data[colname] = all_data[f1].values / all_data[f2].values
all_data = all_data.fillna(method='bfill')
气压差,湿度差的特征组合
for f1 in tqdm(['gapatmo','gaphum'] ):
for f2 in ['gapatmo','gaphum'] :
if f1 != f2:
colname = '{}_{}_ratio'.format(f1, f2)
#存在被除数为的情况
all_data[colname] = all_data[f1].values / (all_data[f2].values - np.min(all_data[f2])+1)
all_data = all_data.fillna(method='bfill')
数据点之前的均值
for f in ['outtemp', 'outhum', 'outatmo', 'inhum', 'inatmo','gapatmo','gaphum','gapatmo_ratio','gaphum_ratio']:
tmp_df = pd.DataFrame()
for t in tqdm(range(15, 45)):
tmp = all_data[all_data['day'] < t].groupby(['hour'])[f].agg({'mean'}).reset_index()
tmp.columns = ['hour', 'hit_{}_mean'.format(f)]
tmp['day'] = t
tmp_df = tmp_df.append(tmp)
all_data = all_data.merge(tmp_df, on=['day', 'hour'], how='left')
all_data = all_data.fillna(method='bfill')
连续值分桶
for f in ['outtemp', 'outhum', 'outatmo', 'inhum', 'inatmo','gapatmo','gaphum','gapatmo_ratio','gaphum_ratio']:
all_data[f + '_20_bin'] = pd.cut(all_data[f], 20, duplicates='drop').apply(lambda x: x.left).astype(int)
all_data[f + '_50_bin'] = pd.cut(all_data[f], 50, duplicates='drop').apply(lambda x: x.left).astype(int)
all_data[f + '_100_bin'] = pd.cut(all_data[f], 100, duplicates='drop').apply(lambda x: x.left).astype(int)
all_data[f + '_200_bin'] = pd.cut(all_data[f], 200, duplicates='drop').apply(lambda x: x.left).astype(int)
for i in tqdm(['outtemp', 'outhum', 'outatmo', 'inhum', 'inatmo','gapatmo','gaphum','gapatmo_ratio','gaphum_ratio']):
f1 = i + '_20_bin'
for f2 in ['outtemp', 'outhum', 'outatmo', 'inhum', 'inatmo','gapatmo','gaphum','gapatmo_ratio','gaphum_ratio']:
all_data['{}_{}_medi'.format(f1, f2)] = all_data.groupby([f1])[f2].transform('median')
all_data['{}_{}_mean'.format(f1, f2)] = all_data.groupby([f1])[f2].transform('mean')
all_data['{}_{}_max'.format(f1, f2)] = all_data.groupby([f1])[f2].transform('max')
all_data['{}_{}_min'.format(f1, f2)] = all_data.groupby([f1])[f2].transform('min')
f1 = i + '_20_bin'
for f2 in ['outtemp', 'outhum', 'outatmo', 'inhum', 'inatmo','gapatmo','gaphum','gapatmo_ratio','gaphum_ratio']:
all_data['{}_{}_medi'.format(f1, f2)] = all_data.groupby([f1])[f2].transform('median')
all_data['{}_{}_mean'.format(f1, f2)] = all_data.groupby([f1])[f2].transform('mean')
all_data['{}_{}_max'.format(f1, f2)] = all_data.groupby([f1])[f2].transform('max')
all_data['{}_{}_min'.format(f1, f2)] = all_data.groupby([f1])[f2].transform('min')
f1 = i + '_100_bin'
for f2 in ['outtemp', 'outhum', 'outatmo', 'inhum', 'inatmo','gapatmo','gaphum','gapatmo_ratio','gaphum_ratio']:
all_data['{}_{}_medi'.format(f1, f2)] = all_data.groupby([f1])[f2].transform('median')
all_data['{}_{}_mean'.format(f1, f2)] = all_data.groupby([f1])[f2].transform('mean')
all_data['{}_{}_max'.format(f1, f2)] = all_data.groupby([f1])[f2].transform('max')
all_data['{}_{}_min'.format(f1, f2)] = all_data.groupby([f1])[f2].transform('min')
f1 = i + '_200_bin'
for f2 in ['outtemp', 'outhum', 'outatmo', 'inhum', 'inatmo','gapatmo','gaphum','gapatmo_ratio','gaphum_ratio']:
all_data['{}_{}_medi'.format(f1, f2)] = all_data.groupby([f1])[f2].transform('median')
all_data['{}_{}_mean'.format(f1, f2)] = all_data.groupby([f1])[f2].transform('mean')
all_data['{}_{}_max'.format(f1, f2)] = all_data.groupby([f1])[f2].transform('max')
all_data['{}_{}_min'.format(f1, f2)] = all_data.groupby([f1])[f2].transform('min')
保存训练集和测试集
train_data = all_data[0:24807]
test_data = all_data[24807:25213]
train_data.to_csv('C:/ml_data/kdxf/train_data_eda_8.csv',index = False)
del test_data['gaptemp']
test_data.to_csv('C:/ml_data/kdxf/test_data_eda_8.csv',index = False)
PART2 建模调参
#添加路径
import os
import sys
'''
sys.path.append('/home/tione/notebook/LightGBM/python-package/')
sys.path.append('/opt/spark-2.4.5-bin-hadoop2.7/python')
sys.path.append('/home/tione/notebook')
sys.path.append('/opt/conda/envs/JupyterSystemEnv/lib/python36.zip')
sys.path.append('/opt/conda/envs/JupyterSystemEnv/lib/python3.6')
sys.path.append('/opt/conda/envs/JupyterSystemEnv/lib/python3.6/lib-dynload')
sys.path.append('/home/tione/.local/lib/python3.6/site-packages')
sys.path.append('/opt/conda/envs/JupyterSystemEnv/lib/python3.6/site-packages')
sys.path.append('/opt/conda/envs/JupyterSystemEnv/lib/python3.6/site-packages/xgboost')
'''
ko = ['', '/opt/spark-2.4.5-bin-hadoop2.7/python', '/home/tione/notebook', '/opt/conda/envs/JupyterSystemEnv/lib/python36.zip',
'/opt/conda/envs/JupyterSystemEnv/lib/python3.6', '/opt/conda/envs/JupyterSystemEnv/lib/python3.6/lib-dynload',
'/home/tione/.local/lib/python3.6/site-packages', '/opt/conda/envs/JupyterSystemEnv/lib/python3.6/site-packages']
for i in ko:
sys.path.append(i)
#数据分析,特征工程等
import pandas as pd
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
#模型选择,辅助
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_absolute_error,mean_squared_error
from sklearn.model_selection import train_test_split
#建模
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import SGDRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.tree import DecisionTreeRegressor
import lightgbm as lgb
import xgboost as xgb
import catboost as cb
train_data = pd.read_csv('eda_files/train_data_eda_8.csv')
test_data = pd.read_csv('eda_files/test_data_eda_8.csv')
pred_data = pd.read_csv('original_data/sss.csv')
pred_out_temp = test_data['outtemp']
留出法划分训练集和测试集。
PS:实际上并没有用到,还是用的五折交叉验证。
train_ = train_data[0:18832]
train_y_ = train_['gaptemp']
del train_['gaptemp']
train_x_ = train_.values
test_ = train_data[18832:len(train_data)-1]
test_y_ = test_['gaptemp']
del test_['gaptemp']
test_x_ = test_.values
train_x_spl_ = train_x_[0:15620]
train_y_spl_ = train_y_[0:15620]
test_x_spl_ = train_x_[15620:len(train_x_)]
test_y_spl_ = train_y_[15620:len(train_x_)]
train_y = train_data['gaptemp']
del train_data['gaptemp']
train_x = train_data.values
test_x = test_data.values
Ridge
model_ridge = Ridge(alpha = 1.48,normalize=True,random_state=2020)
lightgbm
model_lgb_002 = lgb.LGBMRegressor(objective='regression',
metric='mse',
learning_rate=0.02,
n_estimators=6102,
max_depth=7,
num_leaves=47,
min_child_samples = 20,
min_child_weight = 0.001,
bagging_fraction = 0.75,
feature_fraction = 0.65,
bagging_frequency = 7,
lambda_l1 = 0.5,
lambda_l2 = 1.0
)
xgboost
xgb_params_final = {'eta': 0.01,
'n_estimators': 445,
'gamma': 0,
'max_depth': 4,
'min_child_weight':5,
'gamma':0.49,
'subsample': 0.76,
'colsample_bytree': 0.59,
'reg_lambda': 59,
'reg_alpha': 0,
'colsample_bylevel': 1,
'seed': 2020}
modelxgb = xgb.XGBRegressor(**xgb_params_final)
catboost模型基本没怎么调参,上catboost时已经没有多少时间到deadline了,我随便跑跑看效果不错就上线了。catboost模型参数不放上来了。
最终提交的结果
result_upload = result_ctb*0.7 + result_lgb*0.17 + result_xgb*0.13
并没有采用ridge。
三个模型中,catboost得分最佳,人工给与权重0.7,剩下的0.3权重xgb和lgb瓜分,瓜分的比例是单模型线上得分(mse)的倒数,这种瓜分方式也是卡尔曼滤波的方法。
表现最好的模型是catboost,catboost对预测偏移的处理较好,侧面也印证了训练集和测试集是存在数据偏移的。
单模型线上得分是0.13多一点,融合线上得分为0.12389,差一丢丢进复赛。
存在的问题
调参时发现了一个很严重的问题,params_a在无论使用五折交叉验证还是留出法训练+验证,效果都是比params_b好的,但是在科大讯飞的线上得分却远差于params_b。这个问题导致了调参几乎无法进行了。此时距离deadline仅剩3 4天了,这个问题一直没有正确的解决掉。
总结反思
1.科大讯飞提供的训练集是30秒一采样,而测试集是30分钟一采样。我的eda中基于小时做的统计特征在训练集表现OK,在测试几乎误差会非常大!因为一个小时就两个数据,统计量就失去了意义。可能是这个原因导致了调参的那个问题。
2.参与太晚,eda做的不仔细。eda时居然没有发现测试30秒一采样这个问题,直到8月18号晚上才发现这个问题,deadline是8月20号,为时已晚。
3.经验太少。在处理调参这个问题时,我的思路是问题又两个因素导致,过拟合+异常值,对训练集和测试集再次进行异常值检测并没有收获。可是这个竞赛是时间序列啊,采样频率这个因素居然没有想到。如果竞赛或者工程经验丰富了,也许处理这个问题就会迅捷的多。
4.eda做的感觉还是差很多,在时间关系上应该挖掘更多的特征。