深度学习之超分辨率算法——VDSR
- 比较于之前的FSRCNN来说,VDSR我认为主要引入了以下优秀特点
- 首先是卷积层数的上的增加,卷积层数直接代表着模型提取特征的能力强弱
- 小卷积核的进一步引入,利用卷积核3x3堆叠层数,模型一共20层。
- 引入残差网络
- 缺点:
- 原文依然采用的MSE损失,单纯比较像素之间的差异。图像相对比较平滑。
- 训练依然采用是SRCNN的训练方法,先上采样到高分辨率尺寸大小再进行训练。

两张图理解:
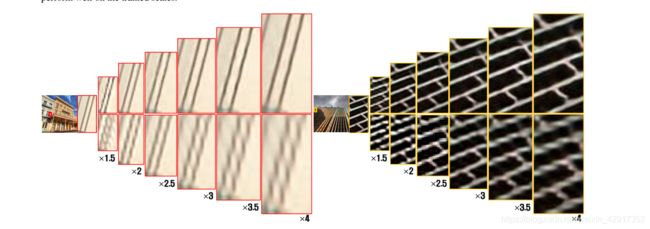
(输入尺寸等于输出尺寸的模型实现)
- 使用数据集:train.h5
model.py
import torch
import torch.nn as nn
from math import sqrt
class VDSR(nn.Module):
def __init__(self):
super(VDSR, self).__init__()
# 残差网络
self.residual_layer = self.make_layer(Conv_ReLU_Block, 18)
# 输入
self.input = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=(3,3), stride=(1,1), padding=(1,1), bias=False)
self.output = nn.Conv2d(in_channels=64, out_channels=1, kernel_size=(3,3), stride=(1,1), padding=(1,1), bias=False)
self.relu = nn.ReLU(inplace=True)
self.init_weights()
def init_weights(self):
# 模型初始化参数
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, sqrt(2. / n))
def make_layer(self, block, num_of_layer):
# 做18层网络呀.....
layers = []
for _ in range(num_of_layer):
layers.append(block())
return nn.Sequential(*layers)
def forward(self, x):
residual = x
# 1
out = self.relu(self.input(x))
# 18
out = self.residual_layer(out)
# 1
out = self.output(out)
# 残差
out = residual+out
return out
class Conv_ReLU_Block(nn.Module):
def __init__(self):
super(Conv_ReLU_Block, self).__init__()
self.sequential = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.sequential(x)
if __name__ == '__main__':
x= torch.randn(1,1,224,224)
net = VDSR()
print(net(x).shape)
dataset.py (数据读取方式)
import torch.utils.data as data
import torch
import h5py
from PIL import Image
import numpy as np
class DatasetFromHdf5(data.Dataset):
def __init__(self, file_path="./data/train.h5"):
super(DatasetFromHdf5, self).__init__()
hf = h5py.File(file_path)
self.data = hf.get('data')
self.target = hf.get('label')
def __getitem__(self, index):
image = torch.from_numpy(self.data[index,:,:,:]).float()
label = torch.from_numpy(self.target[index,:,:,:]).float()
return image,label
def __len__(self):
return self.data.shape[0]
if __name__ == '__main__':
data = DatasetFromHdf5()
print(len(data))
image = data[0][0]
label = data[0][1]
print(image.numpy()[0].shape)
# 显示图片
image = Image.fromarray(image.numpy()[0]*255)
label = Image.fromarray(label.numpy()[0] * 255)
image.show()
label.show()
- train.py
import argparse, os
import torch
import random
import torch.backends.cudnn as cudnn
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from vdsr import VDSR
from dataset import DatasetFromHdf5
def init():
# Training settings
parser = argparse.ArgumentParser(description="the VDSR of Pytorch")
# batch_size 每次投入模型的图像数据数
parser.add_argument("--batch_size", type=int, default=128, help="Training batch size")
# 训练轮次
parser.add_argument("--epochs", type=int, default=1000, help="Number of epochs to train for")
# 学习率
parser.add_argument("--lr", type=float, default=0.0001, help="Learning Rate. Default=0.1")
# 动态学习率调整系数
parser.add_argument("--step", type=int, default=10, help="Sets the learning rate to the initial LR decayed by momentum every n epochs, Default: n=10")
# 使用cuda
parser.add_argument("--cuda", action="store_true",default=True,help="Use cuda?")
# 已训练权重
parser.add_argument("--resume", default="", type=str, help="Path to checkpoint (default: none)")
# 开始轮次
parser.add_argument("--start-epoch", default=1, type=int, help="Manual epoch number (useful on restarts)")
# 梯度裁剪系数
parser.add_argument("--clip", type=float, default=0.4, help="Clipping Gradients. Default=0.4")
# 单线程
parser.add_argument("--num_workers", type=int, default=1, help="Number of threads for data loader to use, Default: 1")
# 优化器动量
parser.add_argument("--momentum", default=0.9, type=float, help="Momentum, Default: 0.9")
# 正则化系数
parser.add_argument("--weight-decay", "--wd", default=1e-4, type=float, help="Weight decay, Default: 1e-4")
# 预训练
parser.add_argument('--pretrained', default='', type=str, help='path to pretrained model (default: none)')
# 默认GPU为0
parser.add_argument("--gpus", default="0", type=str, help="gpu ids (default: 0)")
return parser
def main():
parser = init()
# 获得所有参数
opt = parser.parse_args()
print(opt)
# cuda设置gpu参数
cuda = opt.cuda
# gpu配置
if cuda:
print("=> use gpu id: '{}'".format(opt.gpus))
os.environ["CUDA_VISIBLE_DEVICES"] = opt.gpus
if not torch.cuda.is_available():
raise Exception("No GPU found or Wrong gpu id, please run without --cuda")
# 随机种子参数
opt.seed = random.randint(1, 10000)
print("Random Seed: ", opt.seed)
torch.manual_seed(opt.seed)
if cuda:
# 设置固定生成随机数的种子,使得每次运行该.py
# 文件时生成的随机数相同
torch.cuda.manual_seed(opt.seed)
# 设置加速,优化运行效率
cudnn.benchmark = True
print("===> Loading datasets")
train_set = DatasetFromHdf5()
# training_data_loader = DataLoader(dataset=train_set,num_workers=opt.num_workers, batch_size=opt.batch_size, shuffle=True)
training_data_loader = DataLoader(dataset=train_set, batch_size=opt.batch_size,
shuffle=True)
print("===> Building model")
model = VDSR()
criterion = nn.MSELoss()
print("===> Setting GPU")
if cuda:
model = model.cuda()
criterion = criterion.cuda()
# optionally resume from a checkpoint
if opt.resume:
if os.path.isfile(opt.resume):
print("=> loading checkpoint '{}'".format(opt.resume))
checkpoint = torch.load(opt.resume)
opt.start_epoch = checkpoint["epoch"] + 1
model.load_state_dict(checkpoint["model"].state_dict())
else:
print("=> no checkpoint found at '{}'".format(opt.resume))
# optionally copy weights from a checkpoint
if opt.pretrained:
if os.path.isfile(opt.pretrained):
print("=> loading model '{}'".format(opt.pretrained))
weights = torch.load(opt.pretrained)
model.load_state_dict(weights['model'].state_dict())
else:
print("=> no model found at '{}'".format(opt.pretrained))
print("===> Setting Optimizer")
optimizer = optim.SGD(model.parameters(), lr=opt.lr, momentum=opt.momentum, weight_decay=opt.weight_decay)
print("===> Training")
for epoch in range(opt.start_epoch, opt.epochs + 1):
train(opt,training_data_loader, optimizer, model, criterion, epoch)
save_checkpoint(model, epoch)
def adjust_learning_rate(opt, epoch):
"""Sets the learning rate to the initial LR decayed by 10 every 10 epochs"""
lr = opt.lr * (0.1 ** (epoch //opt.step))
return lr
def train(opt,training_data_loader, optimizer, model, criterion, epoch):
# lr = adjust_learning_rate(opt, epoch-1)
lr = opt.lr
for param_group in optimizer.param_groups:
param_group["lr"] = lr
print("Epoch = {}, lr = {}".format(epoch, optimizer.param_groups[0]["lr"]))
model.train()
for iteration, batch in enumerate(training_data_loader):
input, target = torch.Tensor(batch[0]), torch.Tensor(batch[1])
if opt.cuda:
input = input.cuda()
target = target.cuda()
# print("meodel:",model(input).shape)
# print(target.shape)
loss = criterion(model(input), target)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(),opt.clip)
optimizer.step()
if iteration%100 == 0:
print("===> Epoch[{}]({}/{}): Loss: {:.10f}".format(epoch, iteration, len(training_data_loader), loss.item()))
def save_checkpoint(model, epoch):
model_out_path = "checkpoint/" + "model_epoch_{}.pth".format(epoch)
state = {"epoch": epoch ,"model": model}
if not os.path.exists("checkpoint/"):
os.makedirs("checkpoint/")
torch.save(state, model_out_path)
print("Checkpoint saved to {}".format(model_out_path))
if __name__ == "__main__":
main()
eval.py
import argparse, os
import torch
from torch.autograd import Variable
import numpy as np
import time, math, glob
import scipy.io as sio
parser = argparse.ArgumentParser(description="PyTorch VDSR Eval")
parser.add_argument("--cuda", action="store_true", help="use cuda?")
parser.add_argument("--model", default="model/model_epoch_100.pth", type=str, help="model path")
parser.add_argument("--dataset", default="Set5", type=str, help="dataset name, Default: Set5")
parser.add_argument("--gpus", default="0", type=str, help="gpu ids (default: 0)")
def PSNR(pred, gt, shave_border=0):
height, width = pred.shape[:2]
pred = pred[shave_border:height - shave_border, shave_border:width - shave_border]
gt = gt[shave_border:height - shave_border, shave_border:width - shave_border]
imdff = pred - gt
rmse = math.sqrt(np.mean(imdff ** 2))
if rmse == 0:
return 100
return 20 * math.log10(255.0 / rmse)
opt = parser.parse_args()
cuda = opt.cuda
if cuda:
print("=> use gpu id: '{}'".format(opt.gpus))
os.environ["CUDA_VISIBLE_DEVICES"] = opt.gpus
if not torch.cuda.is_available():
raise Exception("No GPU found or Wrong gpu id, please run without --cuda")
model = torch.load(opt.model, map_location=lambda storage, loc: storage)["model"]
scales = [2,3,4]
image_list = glob.glob(opt.dataset+"_mat/*.*")
for scale in scales:
avg_psnr_predicted = 0.0
avg_psnr_bicubic = 0.0
avg_elapsed_time = 0.0
count = 0.0
for image_name in image_list:
if str(scale) in image_name:
count += 1
print("Processing ", image_name)
# 加载模型
im_gt_y = sio.loadmat(image_name)['im_gt_y']
# 双线性插值
im_b_y = sio.loadmat(image_name)['im_b_y']
im_gt_y = im_gt_y.astype(float)
im_b_y = im_b_y.astype(float)
psnr_bicubic = PSNR(im_gt_y, im_b_y,shave_border=scale)
avg_psnr_bicubic += psnr_bicubic
im_input = im_b_y/255.
im_input =torch.Tensor(torch.from_numpy(im_input).float()).reshape(1, -1, im_input.shape[0], im_input.shape[1])
if cuda:
model = model.cuda()
im_input = im_input.cuda()
else:
model = model.cpu()
start_time = time.time()
HR = model(im_input)
elapsed_time = time.time() - start_time
avg_elapsed_time += elapsed_time
HR = HR.cpu()
im_h_y = HR.data[0].numpy().astype(np.float32)
im_h_y = im_h_y * 255.
im_h_y[im_h_y < 0] = 0
im_h_y[im_h_y > 255.] = 255.
im_h_y = im_h_y[0,:,:]
psnr_predicted = PSNR(im_gt_y, im_h_y,shave_border=scale)
avg_psnr_predicted += psnr_predicted
print("Scale=", scale)
print("Dataset=", opt.dataset)
print("PSNR_predicted=", avg_psnr_predicted/count)
print("PSNR_bicubic=", avg_psnr_bicubic/count)
print("It takes average {}s for processing".format(avg_elapsed_time/count))
像素重采样的VDSR
-
原文VDSR训练时,直接将原图上采样后"高分辨率"图像加入到模型中进行计算。
-
使用训练集VOC2012,RGB图
-
训练集目录如下:
-
data存放数据假设bat_size = 1(1,3,224,224)
-
SRF_2下:target:(1,3,448,448)
-
SRF_3下:target(1,3,2243,2243)

-
dataset.py
class DatasetFromVoc(data.Dataset):
def __init__(self, file_path="./train",scale=2):
super(DatasetFromVoc, self).__init__()
if scale==2:
dir_path = os.path.join(file_path,"SRF_2")
elif scale==3:
dir_path = os.path.join(file_path,"SRF_3")
else:
dir_path = os.path.join(file_path,"SRF_4")
self.data_path = os.path.join(dir_path,"data")
self.target_path = os.path.join(dir_path,"target")
self.dataset = []
for img_name in os.listdir(self.data_path):
img_path = os.path.join(self.data_path,img_name)
img_target = os.path.join(self.target_path,img_name)
self.dataset.append([img_path,img_target])
def __getitem__(self, index):
img_path,label_path = self.dataset[index]
img_data = cv.imread(img_path)
label_data = cv.imread(label_path)
# print(img_data.shape)
# print(label_data.shape)
img_data = img_data.transpose([2,0,1])
label_data = label_data.transpose([2,0,1])
img_data = np.array(img_data,dtype=np.float32)/255.
label_data = np.array(label_data,dtype=np.float32)/255.
return img_data,label_data
def __len__(self):
return len(self.dataset)
vsnr.py
模型中我采取ESPCN的输出方式,采用像素混洗的方法,最后输出的时候才进行上采样,节约计算量。
进一步改进:损失函数应该加入感受损失
class VDSR_ESPCN(nn.Module):
def __init__(self,input_channel=1,scale=2):
super(VDSR_ESPCN, self).__init__()
# 残差网络
self.residual_layer = self.make_layer(Conv_ReLU_Block, 18)
# 输入
self.input = nn.Conv2d(in_channels=input_channel, out_channels=64, kernel_size=(3,3), stride=(1,1), padding=(1,1), bias=False)
self.output = nn.Conv2d(in_channels=64, out_channels=input_channel, kernel_size=(3,3), stride=(1,1), padding=(1,1), bias=False)
self.relu = nn.ReLU(inplace=True)
self.last_part = nn.Sequential(
nn.Conv2d(input_channel, input_channel* (scale ** 2), kernel_size=(3, 3), padding=(3 // 2, 3 // 2)),
nn.PixelShuffle(scale)
)
self.init_weights()
def init_weights(self):
# 模型初始化参数
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, sqrt(2. / n))
def make_layer(self, block, num_of_layer):
# 做18层网络呀.....
layers = []
for _ in range(num_of_layer):
layers.append(block())
return nn.Sequential(*layers)
def forward(self, x):
residual = x
# 1
out = self.relu(self.input(x))
# 18
out = self.residual_layer(out)
# 1
out = self.output(out)
# 残差
out = residual+out
# print(out.shape)
out = self.last_part(out)
return out
class Conv_ReLU_Block(nn.Module):
def __init__(self):
super(Conv_ReLU_Block, self).__init__()
self.sequential = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.sequential(x)
trian_VDSR_ESPCN.py
import argparse, os
import torch
import random
import torch.backends.cudnn as cudnn
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from vdsr import VDSR_ESPCN
from dataset import DatasetFromVoc
def init():
# Training settings
parser = argparse.ArgumentParser(description="the VDSR of Pytorch")
# batch_size 每次投入模型的图像数据数
parser.add_argument("--batch_size", type=int, default=32, help="Training batch size")
# 训练轮次
parser.add_argument("--epochs", type=int, default=1000, help="Number of epochs to train for")
# 学习率
parser.add_argument("--lr", type=float, default=0.0001, help="Learning Rate. Default=0.1")
# 动态学习率调整系数
parser.add_argument("--step", type=int, default=10, help="Sets the learning rate to the initial LR decayed by momentum every n epochs, Default: n=10")
# 使用cuda
parser.add_argument("--cuda", action="store_true",default=True,help="Use cuda?")
# 已训练权重
parser.add_argument("--resume", default="", type=str, help="Path to checkpoint (default: none)")
# 开始轮次
parser.add_argument("--start-epoch", default=1, type=int, help="Manual epoch number (useful on restarts)")
# 梯度裁剪系数
parser.add_argument("--clip", type=float, default=0.4, help="Clipping Gradients. Default=0.4")
# 单线程
parser.add_argument("--num_workers", type=int, default=1, help="Number of threads for data loader to use, Default: 1")
# 优化器动量
parser.add_argument("--momentum", default=0.9, type=float, help="Momentum, Default: 0.9")
# 正则化系数
parser.add_argument("--weight-decay", "--wd", default=1e-4, type=float, help="Weight decay, Default: 1e-4")
# 预训练a
parser.add_argument('--pretrained', default='', type=str, help='path to pretrained model (default: none)')
# 默认GPU为0
parser.add_argument("--gpus", default="0", type=str, help="gpu ids (default: 0)")
return parser
def main():
parser = init()
# 获得所有参数
opt = parser.parse_args()
print(opt)
# cuda设置gpu参数
cuda = opt.cuda
# gpu配置
if cuda:
print("=> use gpu id: '{}'".format(opt.gpus))
os.environ["CUDA_VISIBLE_DEVICES"] = opt.gpus
if not torch.cuda.is_available():
raise Exception("No GPU found or Wrong gpu id, please run without --cuda")
# 随机种子参数
opt.seed = random.randint(1, 10000)
print("Random Seed: ", opt.seed)
torch.manual_seed(opt.seed)
if cuda:
# 设置固定生成随机数的种子,使得每次运行该.py
# 文件时生成的随机数相同
torch.cuda.manual_seed(opt.seed)
# 设置加速,优化运行效率
cudnn.benchmark = True
print("===> Loading datasets")
train_set = DatasetFromVoc(scale=2)
# training_data_loader = DataLoader(dataset=train_set,num_workers=opt.num_workers, batch_size=opt.batch_size, shuffle=True)
training_data_loader = DataLoader(dataset=train_set, batch_size=opt.batch_size,
shuffle=True)
print("===> Building model")
model = VDSR_ESPCN(scale=2,input_channel=3)
criterion = nn.MSELoss()
print("===> Setting GPU")
if cuda:
model = model.cuda()
criterion = criterion.cuda()
# optionally resume from a checkpoint
if opt.resume:
if os.path.isfile(opt.resume):
print("=> loading checkpoint '{}'".format(opt.resume))
checkpoint = torch.load(opt.resume)
opt.start_epoch = checkpoint["epoch"] + 1
model.load_state_dict(checkpoint["model"].state_dict())
else:
print("=> no checkpoint found at '{}'".format(opt.resume))
# optionally copy weights from a checkpoint
if opt.pretrained:
if os.path.isfile(opt.pretrained):
print("=> loading model '{}'".format(opt.pretrained))
weights = torch.load(opt.pretrained)
model.load_state_dict(weights['model'].state_dict())
else:
print("=> no model found at '{}'".format(opt.pretrained))
print("===> Setting Optimizer")
optimizer = optim.SGD(model.parameters(), lr=opt.lr, momentum=opt.momentum, weight_decay=opt.weight_decay)
print("===> Training")
for epoch in range(opt.start_epoch, opt.epochs + 1):
train(opt,training_data_loader, optimizer, model, criterion, epoch)
save_checkpoint(model, epoch)
def adjust_learning_rate(opt, epoch):
"""Sets the learning rate to the initial LR decayed by 10 every 10 epochs"""
lr = opt.lr * (0.1 ** (epoch //opt.step))
return lr
def train(opt,training_data_loader, optimizer, model, criterion, epoch):
# lr = adjust_learning_rate(opt, epoch-1)
lr = opt.lr
for param_group in optimizer.param_groups:
param_group["lr"] = lr
print("Epoch = {}, lr = {}".format(epoch, optimizer.param_groups[0]["lr"]))
model.train()
for iteration, batch in enumerate(training_data_loader):
input, target = torch.Tensor(batch[0]), torch.Tensor(batch[1])
if opt.cuda:
input = input.cuda()
target = target.cuda()
# print("meodel:",model(input).shape)
# print(target.shape)
loss = criterion(model(input), target)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(),opt.clip)
optimizer.step()
if iteration%100 == 0:
print("===> Epoch[{}]({}/{}): Loss: {:.10f}".format(epoch, iteration, len(training_data_loader), loss.item()))
def save_checkpoint(model, epoch):
model_out_path = "checkpoint_vdsrespcn/" + "model_epoch_{}.pth".format(epoch)
state = {"epoch": epoch ,"model": model}
if not os.path.exists("checkpoint_vdsrespcn/"):
os.makedirs("checkpoint_vdsrespcn/")
torch.save(state, model_out_path)
print("Checkpoint saved to {}".format(model_out_path))
if __name__ == "__main__":
main()
训练比较久…

- 以上我自己的改写,具体测试还在进行汇总,关于单通道的图片PSNR达到27.65
- 小伙伴们有问题欢迎加微信一起解决哦
