神经网络(线性神经网络、Delta学习规则)
线性神经网络
线性神经网络在结构上与感知器非常相似,只是激活函数不同。在模型训练时把原来的sign函数改成了purelin函数:y = x
除了sign和purelin,还有很多常用的激活函数:

Delta学习规则
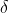 学习规则是一种利用梯度下降法的一般性的学习规则,也可以称为连续感知器学习规则。
学习规则是一种利用梯度下降法的一般性的学习规则,也可以称为连续感知器学习规则。
首先也要定义代价函数(损失函数),二次代价函数:

误差E是权向量W的函数,我们可以使用梯度下降法来最小化E的值:

对应的梯度下降法一维和二维情况如图所示:

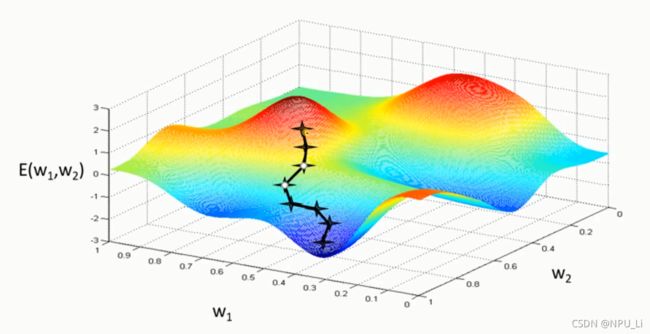
梯度下降法的问题:学习率难以选取,太大会产生震荡,太小收敛缓慢
容易陷入局部最优解(局部极小值)
实战
异或问题
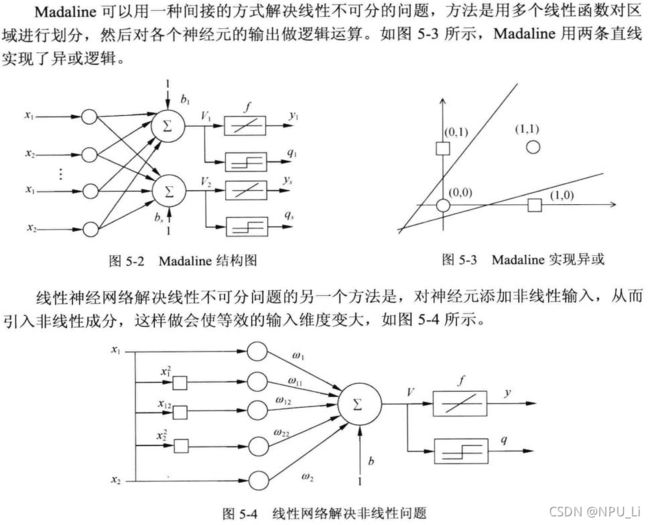
解决异或(非线性)问题,需要加入非线性项:

第一步:导库、导数据、定义更新函数
import numpy as np
import matplotlib.pyplot as plt
#输入数据
X = np.array([[1,0,0,0,0,0],
[1,0,1,0,0,1],
[1,1,0,1,0,0],
[1,1,1,1,1,1]])
#标签
Y = np.array([[1],
[1],
[-1],
[-1]])
#权值初始化,6行1列,取值范围-1到1
W = (np.random.random([6,1])-0.5)*2
lr = 0.11
#神经网络输出
O = 0
def update():
global X,Y,W,lr
O = np.dot(X,W)
W_C = lr*(X.T.dot(Y-O))/int(X.shape[0])
W = W + W_C第二步:训练模型、可视化、结果
for i in range(100):
update()#更新权值
#正样本
x1 = [0,1]
y1 = [1,0]
#负样本
x2 = [0,1]
y2 = [0,1]
def calculate(x,root):
a=W[3]
b=W[2]+x*W[4]
c=W[0]+x*W[1]+x*x*W[3]
if root==1:
return (-b+np.sqrt(b*b-4*a*c))/(2*a)
if root==2:
return (-b-np.sqrt(b*b-4*a*c))/(2*a)
x_data=np.linspace(0,5)
plt.figure()
plt.plot(x_data,calculate(x_data,1),'r')
plt.plot(x_data,calculate(x_data,2),'r')
plt.scatter(x1,y1,c='bo')
plt.scatter(x2,y2,c='yo')
plt.show()
O=np.dot(X,W,T)
print(O)这是我学习 覃秉丰老师的《机器学习算法基础》的自学笔记,课程在B站中的地址为:
机器学习算法基础-覃秉丰_哔哩哔哩_bilibili