2.5 点选验证码(bilibili点选验证码识别)
-
点选验证码是一种相对复杂的验证码,如下图所示,它不仅需要识别文字的内容,而且还需要识别文字的位置。
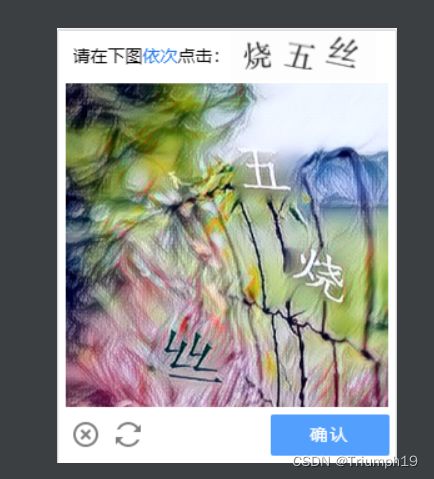
-
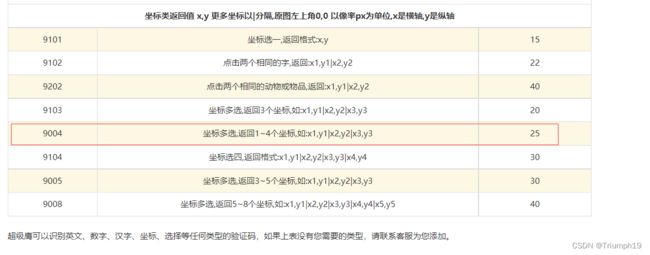
通过传统的识别手段点选验证码会比较麻烦,好在超级鹰也提供了相应的接口,如下图所示(详见https://www.chaojiying.com/price.html)。
-
我们只需修改2.1节中定义的cjy()函数的代码,将其中的PosPic()函数的第2个参数改成与点选验证码的类型对应的接口,如9004,修改后的代码如下:
def cjy(): #使用超级鹰识别图像验证码的自定义函数
chaojiying = Chaojiying_Client('账号', '密码', '软件id') # 用户中心>>软件ID
im = open('a.png', 'rb').read() # 打开本地图片文件,有时WIN系统须要//
code = chaojiying.PostPic(im,9004)['pic_str']
- 最后返回的code是各个点选文字的坐标,例如返回的是285,54|472,59|513,144|342,157,那么4个点选文字的坐标分别是(285,54)、(472,59)、(513,144)、(342,157)。
2.5.1 本地网页识别
- 先用本书作者搭建的本地网页来演示如何用超级鹰识别点选验证码。和2.1节讲过的类似,要把“chaojiying.py”文件复制到编写代码的文件夹中,或者复制到Python安转位置下的Lib文件夹中。
- 网页中点选验证码识别的基本思路如下:
-
- (1)用Selenium库打开网页
-
- (2)用Selenium库的screenhot()函数截取点选验证码的图片并保存
-
- (3)用cjy()函数识别点选验证中各个文字的坐标;
-
- (4)对获取的坐标进行数据处理,方便下一步进行模拟单击
-
- (5)用Selenium库依次模拟单击文字
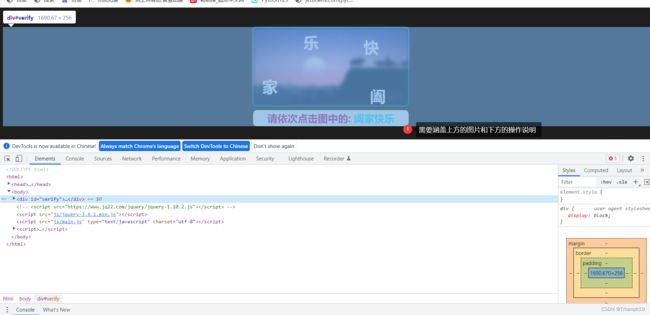
- 如下图所示,在浏览器中打开包含点选验证码的本地网页文件“index.html”,打开开发者工具,复制点选验证码相关图片的XPath表达式(//*[@id=“verify”]),编写代码时会用到。
- 下面开始编写代码。先用Selenium库访问网址,代码如下:
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = r'D:\works\python_crawl1\《Python爬虫(进阶与进通)》代码汇总\2.验证码反爬\5.点选验证码\点选验证码本地版\index.html'
browser.get(url) #用模拟浏览器打开网页
time.sleep(5) #等待一段时间,让验证码加载完毕
- 因为本例的点选验证码在刷新时有一个短暂的动态缩放效果,所以在打开网页之后,在第6行代码用time库的sleep()函数等待5秒,让验证码加载完毕,使之后的截图更加准确。
- 接着用Selenium库的screenhot()函数截取验证码图片,代码如下:
canvas = browser.find_element_by_xpath('//*[@id="verify"]') #定位点选验证码
canvas.screenshot('a.png') #截取图片
- 关于上述代码有两点需要说明:第一,这里没有直接写browser.find_element_by_xpath(‘//[@id=“verify”]’).screenshot(‘a1.png’),而是先定位点选验证码并赋给变量canvas("画步"的意思),再用screenshot()函数截取图片,这是因为在后面依次模拟单击文字时需要用到变量canvas;第二,因为cjy()函数中打开的本地图片文件是“a.png”,所以在截取图片时也要保存为“a.png”。
- 然后用超级鹰识别图片,获得各个文字的坐标,代码如下:
from chaojiying import Chaojiying_Client
def cjy(): #使用超级鹰识别图像验证码的自定义函数
chaojiying = Chaojiying_Client('账号', '密码', 'ID') # 用户中心>>软件ID
im = open('a.png', 'rb').read() # 打开本地图片文件,有时WIN系统须要//
code = chaojiying.PostPic(im,9004)['pic_str']
return code
result = cjy()
result
- 识别结果如下:
'393,55|405,118|552,43|553,165'
- 上述结果对应的就是4个文字的坐标,并按文字的单击顺序排列。但是Selenium库的函数不能识别这种格式的坐标,所以还需要进行简单的数据处理。观察这一串坐标,可以发现各组坐标之间以“|”号分隔,每组坐标的x坐标和y坐标之间又以逗号分隔。根据这两个符号对字符串进行拆分,就可提取出各个文字的x坐标和y坐标,再整理成需要的格式,代码如下:
all_location = [] # 创建一个空列表,用于汇总处理后的各个文字的坐标
list_temp = result.split('|') #根据“|”拆分字符串,存储为临时列表
print(list_temp)
['393,55', '405,118', '552,43', '553,165']
for i in list_temp:
list_i = [] # 创建一个空列表,用于存储每个文字的坐标
x = int(i.split(',')[0]) #根据","拆分字符串,提取第1个元素(x坐标)并转换为整数
y = int(i.split(",")[1])
list_i.append(x) #添加x坐标
list_i.append(y) #添加y坐标
all_location.append(list_i)
all_location
[[393, 55], [405, 118], [552, 43], [553, 165]]
- 处理号坐标后,就可以用Selenium库依次模拟单击文字了,代码如下:
for i in all_location:
x = i[0] # 提取x坐标
y = i[1] # 提取y坐标
action = webdriver.ActionChains(browser) # 启动动作链
action.move_to_element_with_offset(canvas,x,y).click().perform() #根据坐标模拟单击文字
time.sleep(1)

- 完整代码如下:
from chaojiying import Chaojiying_Client
from selenium import webdriver
import time
# 1.访问网址
browser = webdriver.Chrome()
url = r'D:\works\python_crawl1\《Python爬虫(进阶与进通)》代码汇总\2.验证码反爬\5.点选验证码\点选验证码本地版\index.html'
browser.get(url) #用模拟浏览器打开网页
time.sleep(5) #等待一段时间,让验证码加载完毕
# 2.截取点选验证码图片
canvas = browser.find_element_by_xpath('//*[@id="verify"]') #定位点选验证码
canvas.screenshot('a.png') #截取图片
# 3.使用超级鹰识别,获得各个文字的坐标
def cjy(): #使用超级鹰识别图像验证码的自定义函数
chaojiying = Chaojiying_Client('账号', '密码', ' 932868') # 用户中心>>软件ID
im = open('a.png', 'rb').read() # 打开本地图片文件,有时WIN系统须要//
code = chaojiying.PostPic(im,9004)['pic_str']
return code
result = cjy()
print(result)
# 4.对获得的坐标进行数据处理
all_location = [] # 创建一个空列表,用于汇总处理后的各个文字的坐标
list_temp = result.split('|') #根据“|”拆分字符串,存储为临时列表
print(list_temp)
for i in list_temp:
list_i = [] # 创建一个空列表,用于存储每个文字的坐标
x = int(i.split(',')[0]) #根据","拆分字符串,提取第1个元素(x坐标)并转换为整数
y = int(i.split(",")[1])
list_i.append(x)
list_i.append(y)
all_location.append(list_i)
print(all_location)
# 5.依次模拟单击文字
for i in all_location:
x = i[0] # 提取x坐标
y = i[1] # 提取y坐标
action = webdriver.ActionChains(browser) # 启动动作链
action.move_to_element_with_offset(canvas,x,y).click().perform() #根据坐标模拟单击文字
time.sleep(1)
2.5.2 bibibi点选验证码识别初探
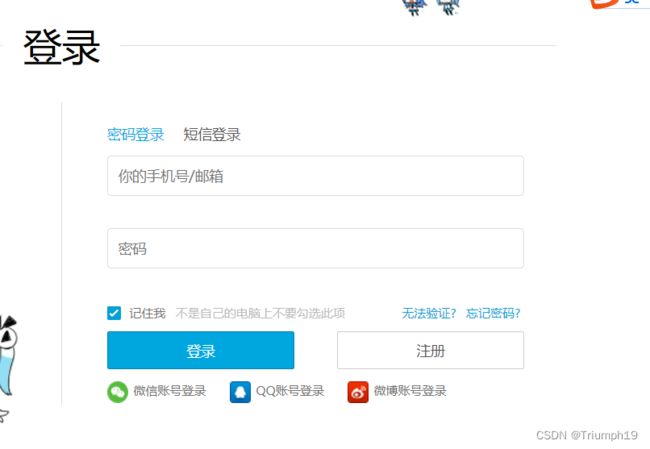
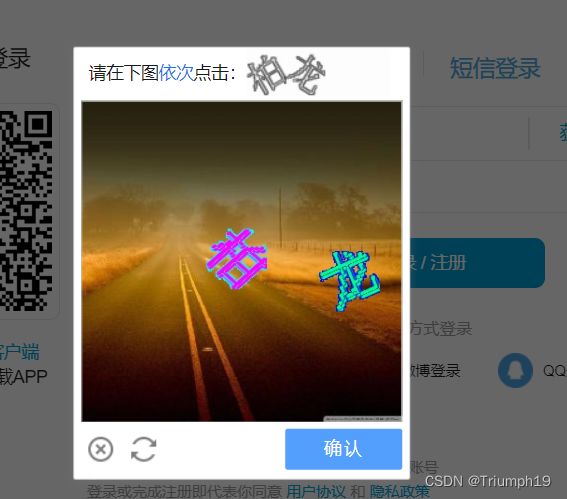
- 在浏览器中打开网址https://passport.bilibili.com/login,在下图所示的登录表单中输入账号和密码,单击“登录”按钮,就会出现下图所示的点选验证码。根据提示依次单击图片中的文字即可验证成功,如果单击的顺序或位置错误,都会验证失败。
- 最简单的解决方法是设置一定的等待时间,然后手动登录。这里为了巩固2.5.1讲解的方法,使用超级鹰来识别点选验证码。
- 先用Selenium库打开bilibili的登录页面,代码如下:
user = '账号' #需要改为实际登录的账号
password = '密码' #需改为实际登录的密码
browser.find_element_by_xpath('//*[@id="login-username"]').send_keys(user) #模拟输入账号
browser.find_element_by_xpath('//*[@id="login-passwd"]').send_keys(password) #模拟输入密码
browser.find_element_by_xpath('//*[@id="geetest-wrap"]/div/div[5]/a[1]').click() #模拟单击“登录"按钮
time.sleep(2)
- 然后截取验证码图片,保存为"bilibili.png",代码如下:
canvas = browser.find_element_by_xpath('//*[@id="login-app"]/div/div[2]/div[3]/div[3]')
canvas.screenshot('bilibili.png')
- 将图片传给超级鹰进行识别,并接受超级鹰的识别结果。因为bilibili点选验证码中的文字为2~4个,所以选用9004接口,如下图所示(https://www.chaojiying.com/price.html):

- 这里没有定义cjy()函数,而是直接使用超级鹰接口,代码如下:
from chaojiying import Chaojiying_Client
chaojiying = Chaojiying_Client('超级鹰账号', '密码', 'ID')
im = open('bilibili.png','rb').read() #打开本地图片文件
str = chaojiying.PostPic(im,9004)['pic_str'] #使用9004接口
- 对超级鹰进行返回的识别结果进行数据整理,代码如下:
all_location = [] # 创建一个空列表,用于汇总处理后的各个文字的坐标
list_temp = str.split('|') #根据“|”拆分字符串,存储为临时列表
print(list_temp)
for i in list_temp:
list_i = [] # 创建一个空列表,用于存储每个文字的坐标
x = int(i.split(',')[0]) #根据","拆分字符串,提取第1个元素(x坐标)并转换为整数
y = int(i.split(",")[1])
list_i.append(x)
list_i.append(y)
all_location.append(list_i)
print(all_location)
- 处理好坐标后,用Selenium库依次模拟单击文字,代码如下:
for i in all_location:
x = i[0] # 提取x坐标
y = i[1] # 提取y坐标
action = webdriver.ActionChains(browser) # 启动动作链
action.move_to_element_with_offset(canvas,x,y).click().perform() #根据坐标模拟单击文字
time.sleep(1)
- 最后模拟单击“确认”按钮,代码如下:
browser.find_element_by_xpath('/html/body/div[2]/div[2]/div[6]/div/div/div[3]/a/div').click() #模拟单击验证码“确认"按钮
- 完整代码如下:
from chaojiying import Chaojiying_Client
from selenium import webdriver
import time
# 1.访问网址
browser = webdriver.Chrome()
url = 'https://passport.bilibili.com/login'
browser.get(url) #用模拟浏览器打开网页
# 2.模拟登录账号和密码,并模拟单击“登录”按钮
user = '账号' #需要改为实际登录的账号
password = '密码' #需改为实际登录的密码
browser.find_element_by_xpath('//*[@id="login-username"]').send_keys(user) #模拟输入账号
browser.find_element_by_xpath('//*[@id="login-passwd"]').send_keys(password) #模拟输入密码
browser.find_element_by_xpath('//*[@id="geetest-wrap"]/div/div[5]/a[1]').click() #模拟单击“登录"按钮
time.sleep(2)
# 3.截取点选验证码图片
canvas = browser.find_element_by_xpath('//*[@id="login-app"]/div/div[2]/div[3]/div[3]')
canvas.screenshot('bilibili.png')
# 4.使用超级鹰识别点选验证码
chaojiying = Chaojiying_Client('账号', '密码', ' 932868')
im = open('bilibili.png','rb').read() #打开本地图片文件
str = chaojiying.PostPic(im,9004)['pic_str'] #使用9004接口
print(str)
# 4.对获得的坐标进行数据处理
all_location = [] # 创建一个空列表,用于汇总处理后的各个文字的坐标
list_temp = str.split('|') #根据“|”拆分字符串,存储为临时列表
print(list_temp)
for i in list_temp:
list_i = [] # 创建一个空列表,用于存储每个文字的坐标
x = int(i.split(',')[0]) #根据","拆分字符串,提取第1个元素(x坐标)并转换为整数
y = int(i.split(",")[1])
list_i.append(x)
list_i.append(y)
all_location.append(list_i) # 汇总各个文字的坐标
print(all_location)
# 6.依次模拟单击文字
for i in all_location:
x = i[0] # 提取x坐标
y = i[1] # 提取y坐标
action = webdriver.ActionChains(browser) # 启动动作链
action.move_to_element_with_offset(canvas,x,y).click().perform() #根据坐标模拟单击文字
time.sleep(1)
# 7.模拟单击“确认”按钮,完成按钮
time.sleep(3)
browser.find_element_by_xpath('/html/body/div[2]/div[2]/div[6]/div/div/div[3]/a/div').click() #模拟单击验证码“确认"按钮
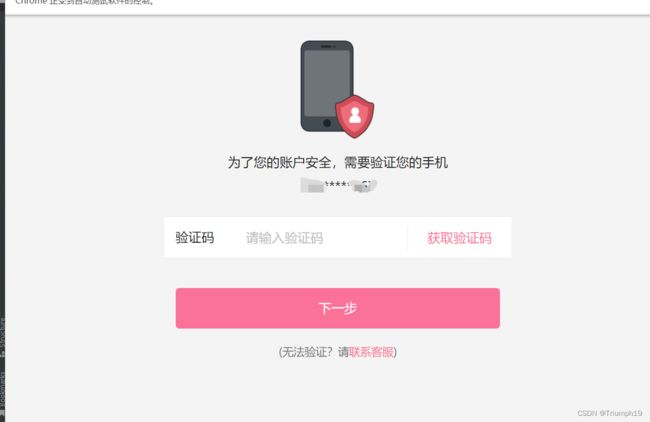
- 虽然经过两次尝试,成功点击所选的中文验证码,但是又出现了如下需要验证的页面。
2.5.3 bilibili点选验证码识别升级:无限尝试版
- 超级鹰并不是每次都能识别准确,因此,本级对2.5.2节的代码进行升级改造,实现自动判断是否登录成功,如果不成功就自动进行无限次尝试,直到成功为止。本节的思路也适用于对本章其他节的案例进行升级改造,希望读者好好体会。
- 无限尝试与24小时不间断爬虫类似,同样是通过while True构造无限循环,其思路具体如下:
- (1)定义一个识别函数,如yzm()函数(其名称来自“验证码”的拼音首字母缩写);
- (2)进行一次识别和登录,然后判断是否登录成功;
- (3)若登录失败,则等待3秒后,继续调用识别函数对新的验证码进行识别和登录;
- (4)若登录成功,则用break语句退出循环。
- 其核心代码如下:
while True:
result = yzm()
if '密码登录' in result and '短信登录' in result:
time.sleep(3)
else:
break
- 接下来要解决两个关键问题:如何定义yzm()函数;如何判断是否登录成功。
- 先来看第1个问题。yzm()函数的定义其实非常简单,先把2.5.2节从开始截取验证码图片直到模拟点击“确认”按钮的代码都打包到yzm()函数中,然后添加代码,获取此时的网页源代码并设置为yzm()函数的返回值,方便之后使用。具体如下:
def yzm(): #定义验证码识别函数
# 3.截取点选验证码的图片
# 4.使用超级鹰识别点选验证码
# 5.对获取的坐标进行数据处理
# 6.依次模拟单击文字
# 7.模拟单击“确认”按钮,完成登录
# 8.等待2秒后,获取此时的网页源代码
time.sleep(2)
data = browser.page_source
return data
- yzm()函数返回的网页源代码也是解决第2个问题的关键。如果超级鹰识别正确,那么单击“确认”按钮后就会登录成功,跳转到bilibili的首页;如果超级鹰识别错误,那么在单击“确认”按钮后则会留在登录页面,并更换新的验证码。因此,通过判断yzm()函数返回的网页源代码是否具备某些特征,我们就知道是否登录成功。
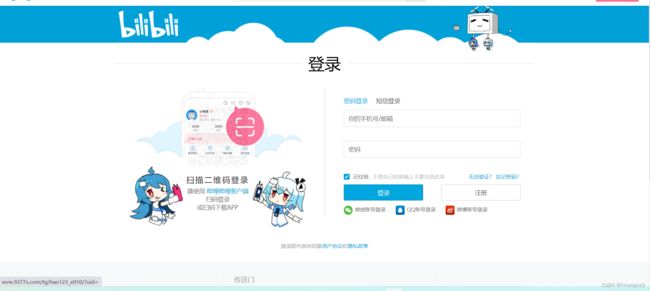
- 如下图所示,登录页面中有“密码登录”和“短信登录”这两个字符串,而这两个字符串是bilibili的首页所没有的,根据这一特征即可判断是否登录成功。
- 我们再来看看如下几行代码,配合注释,就能更好地理解了。
while True:
result = yzm() #调用定义的yzm()函数,函数的返回值为网页源代码
if '密码登录' in result and '短信登录' in result: #判断是否为登录页面,如果是登录页面,说明登录失败
time.sleep(3) #等待3秒后继续循环
else: # 如果不是登录页面,说明进入首页,登录成功
break # 跳出循环
- 完整代码如下:
from chaojiying import Chaojiying_Client
from selenium import webdriver
import time
# 1.访问网址
browser = webdriver.Chrome()
url = 'https://passport.bilibili.com/login'
browser.get(url) #用模拟浏览器打开网页
# 2.模拟登录账号和密码,并模拟单击“登录”按钮
user = '账号' #需要改为实际登录的账号
password = '密码' #需改为实际登录的密码
browser.find_element_by_xpath('//*[@id="login-username"]').send_keys(user) #模拟输入账号
browser.find_element_by_xpath('//*[@id="login-passwd"]').send_keys(password) #模拟输入密码
browser.find_element_by_xpath('//*[@id="geetest-wrap"]/div/div[5]/a[1]').click() #模拟单击“登录"按钮
time.sleep(2)
def yzm(): #定义验证码识别函数
# 3.截取点选验证码图片
canvas = browser.find_element_by_xpath('//*[@id="login-app"]/div/div[2]/div[3]/div[3]')
canvas.screenshot('bilibili.png')
# 4.使用超级鹰识别点选验证码
chaojiying = Chaojiying_Client('账号', '密码', ' 932868')
im = open('bilibili.png','rb').read() #打开本地图片文件
str = chaojiying.PostPic(im,9004)['pic_str'] #使用9004接口
print(str)
# 4.对获得的坐标进行数据处理
all_location = [] # 创建一个空列表,用于汇总处理后的各个文字的坐标
list_temp = str.split('|') #根据“|”拆分字符串,存储为临时列表
print(list_temp)
for i in list_temp:
list_i = [] # 创建一个空列表,用于存储每个文字的坐标
x = int(i.split(',')[0]) #根据","拆分字符串,提取第1个元素(x坐标)并转换为整数
y = int(i.split(",")[1])
list_i.append(x)
list_i.append(y)
all_location.append(list_i) # 汇总各个文字的坐标
print(all_location)
# 6.依次模拟单击文字
for i in all_location:
x = i[0] # 提取x坐标
y = i[1] # 提取y坐标
action = webdriver.ActionChains(browser) # 启动动作链
action.move_to_element_with_offset(canvas,x,y).click().perform() #根据坐标模拟单击文字
time.sleep(1)
# 7.模拟单击“确认”按钮,完成按钮
time.sleep(3)
browser.find_element_by_xpath('/html/body/div[2]/div[2]/div[6]/div/div/div[3]/a/div').click() #模拟单击验证码“确认"按钮
# 8.等待2秒后,获取此时的网页源代码
time.sleep(2)
data = browser.page_source
return data
# 9.无限尝试识别验证码并登录,直到登录成功为止
while True:
result = yzm() #调用定义的yzm()函数,函数的返回值为网页源代码
if '密码登录' in result and '短信登录' in result: #判断是否为登录页面,如果是登录页面,说明登录失败
time.sleep(3) #等待3秒后继续循环
else: # 如果不是登录页面,说明进入首页,登录成功
break # 跳出循环
- 以上代码能够实现模拟点击验证码,但是仍会出现如下验证页面。
- 如果遇到有难以处理的验证码(如淘宝的登录验证码),则可用一个讨巧的方法来解决:用Selenium库模拟访问网址后,借助time.sleep()等待一段时间,在这段时间内手动登录(如扫码登录)。