网络爬虫+深度学习LSTM模型预测中彩网快乐8彩票中奖教程
网络爬虫+深度学习预测快乐8彩票中奖教程
背景
快乐8开奖查询:https://www.zhcw.com/kjxx/kl8/
快乐8游戏规则:https://www.zhcw.com/c/2020-09-22/618869.shtml
本项目主题:使用爬虫爬取中彩网快乐8中奖信息并使用LSTM进行预测。
import json
import math
import matplotlib.pyplot as plt
import matplotlib.mlab as mlab
import numpy as np
import requests
import torch
import torch.nn as nn
import torch.nn.functional
import xlwt
import xlrd
下面是爬虫的请求函数。下面这段除了参考网上爬虫外,我自己也在中彩网使用开发者工具研究了很长时间。
issueCount=431
#快乐8在20201028发行第一期,在当年发行了65期,在2021年总共发行了351期,截止20220115共发行了65+351+15=431期,大家可以在运行本代码时根据实际日期修改本变量。
def requests_data(index):
headers = {
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36',
'Accept': '*/*',
'Sec-Fetch-Site': 'same-site',
'Sec-Fetch-Mode': 'no-cors',
'Referer': 'https://www.zhcw.com/kjxx/kl8/',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
params = (
('callback', 'jQuery1122035713028555611515_1607745050216'),
('transactionType', '10001001'),
('lotteryId', '6'),#快乐8的ID为6
('issueCount', issueCount),
('startIssue', ''),
('endIssue', ''),
('startDate', ''),
('endDate', ''),
('type', '0'),
('pageNum', index),
('pageSize', '30'),
('tt', '0.24352317020584802'),
('_', '1607745050225'),
)
# 获取服务器返回数据
response = requests.get('https://jc.zhcw.com/port/client_json.php', headers=headers, params=params).content.decode('utf-8')
return response
#print(response)
下面开始爬取中彩网快乐8数据并存储到新建的EXCEL表格中。
wb = xlwt.Workbook()
sheet= wb.add_sheet('快乐8')
# 存储表头文件
row=["期号","开奖日期","开奖号码","总销售额(元)"]
# 写入表头
for i in range(0,len(row)):
sheet.write(0,i,row[i])
i=1
range_max = math.floor(issueCount/30+1) if issueCount%30==0 else math.floor(issueCount/30+2)
#如果issueCount是30的整数倍则range_max=math.floor(issueCount/30+1),否则range_max=math.floor(issueCount/30+2)
for pageNum_i in range(1,range_max):#页数必须正好,多了就会返回重复数据,431/30=14.3
tony_dict=requests_data(pageNum_i)
for j in tony_dict:
if j != '{':
tony_dict=tony_dict[-(len(tony_dict)-1):]
else :
break
if tony_dict[len(tony_dict)-1]==')':
tony_dict=tony_dict[:len(tony_dict)-1]#删除最后一个右括号)
content = json.loads(tony_dict)
content_data=content['data']
for item in content_data:
sheet.write(i, 0, item['issue'])
sheet.write(i, 1, item['openTime'])
sheet.write(i, 2, item['frontWinningNum'])
sheet.write(i, 3, item['saleMoney'])
i=i+1
# 保存
wb.save("快乐8开奖情况.xls")
这样,从第一次开奖以来的快乐8至撰稿日共431期数据存到了“快乐8开奖情况.xls”文件中。本来想写个time函数读取当前日期来自动爬到最新的数据,但是仔细一想太麻烦,大家可以自行修改issueCount变量的获取方法。下面读取.xls数据。最后输出的data_np应该为一个一维数组。
#接下来读取.xls数据
data= xlrd.open_workbook('./快乐8开奖情况.xls')
table = data.sheets()[0]
data_lstm=[]
for i in range(issueCount,0,-1):#在excel中最新的数据在最上面因此要倒序读excel
x=table.row(i)[2].value
for j in range(20):
data_lstm=np.append(data_lstm,float(x[3*j])*10+float(x[3*j+1]))
print(data_lstm)
data_np=data_lstm
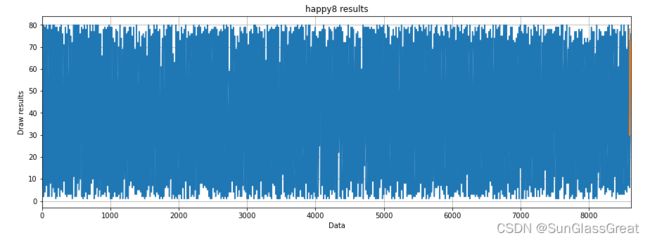
绘制快乐8的一维开奖数据。
#绘制快乐8的一维开奖数据
fig_size = plt.rcParams['figure.figsize']
fig_size[0] = 15
fig_size[1] = 5
plt.rcParams['figure.figsize'] = fig_size
plt.title("happy8 results")
plt.ylabel("Draw results")
plt.xlabel("Data")
plt.grid(True)
plt.autoscale(axis='x',tight=True)
plt.plot(data_np)
plt.show()
下面为数据预处理。输出应为8600和20。
"""
数据预处理
"""
all_data = data_np#本步无意义
#划分测试集和训练集
test_data_size = 20
train_data = all_data[:-test_data_size]#除了最后20个数据,其他全取
test_data = all_data[-test_data_size:]#取最后20个数据
print(len(train_data))
print(len(test_data))
下面为最大最小缩放器进行归一化,减小误差。
#最大最小缩放器进行归一化,减小误差,注意,数据标准化只应用于训练数据而不应用于测试数据
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(-1, 1))
train_data_normalized = scaler.fit_transform(train_data.reshape(-1, 1))
#查看归一化之后的前5条数据和后5条数据
print(train_data_normalized[:5])
print(train_data_normalized[-5:])
下面将数据集转换为tensor。
#将数据集转换为tensor,因为PyTorch模型是使用tensor进行训练的,并将训练数据转换为输入序列和相应的标签
train_data_normalized = torch.FloatTensor(train_data_normalized).view(-1)
#view相当于numpy中的resize,参数代表数组不同维的维度;
#参数为-1表示,这个维的维度由机器自行推断,如果没有-1,那么view中的所有参数就要和tensor中的元素总个数一致
下面定义create_inout_sequences函数。
#定义create_inout_sequences函数,接收原始输入数据,并返回一个元组列表。
"""
注意:
create_inout_sequences返回的元组列表由一个个序列组成,
每一个序列有21个数据,分别是设置的20个数据(train_window)+ 第21个数据(label)
第一个序列由前20个数据组成,第21个数据是第一个序列的标签。
同样,第二个序列从第二个数据开始,到第21个数据结束,而第22个数据是第二个序列的标签,依此类推。
"""
def create_inout_sequences(input_data, tw):
inout_seq = []
L = len(input_data)
for i in range(L-tw):
train_seq = input_data[i:i+tw]
train_label = input_data[i+tw:i+tw+1]#预测time_step之后的第一个数值
inout_seq.append((train_seq, train_label))#inout_seq内的数据不断更新,但是总量只有tw+1个
return inout_seq
train_window = 20#设置训练输入的序列长度为20,类似于time_step = 20
train_inout_seq = create_inout_sequences(train_data_normalized, train_window)
print(train_inout_seq[:5])#产看数据集改造结果
下面创建LSTM模型。
"""
创建LSTM模型
参数说明:
1、input_size:对应的及特征数量,此案例中为1,即passengers
2、output_size:预测变量的个数,及数据标签的个数
2、hidden_layer_size:隐藏层的特征数,也就是隐藏层的神经元个数
"""
"""
forward方法:LSTM层的输入与输出:out, (ht,Ct)=lstm(input,(h0,C0)),其中
一、输入格式:lstm(input,(h0, C0))
1、input为(seq_len,batch,input_size)格式的tensor,seq_len即为time_step
2、h0为(num_layers * num_directions, batch, hidden_size)格式的tensor,隐藏状态的初始状态
3、C0为(seq_len, batch, input_size)格式的tensor,细胞初始状态
二、输出格式:output,(ht,Ct)
1、output为(seq_len, batch, num_directions*hidden_size)格式的tensor,包含输出特征h_t(源于LSTM每个t的最后一层)
2、ht为(num_layers * num_directions, batch, hidden_size)格式的tensor,
3、Ct为(num_layers * num_directions, batch, hidden_size)格式的tensor,
"""
class LSTM(nn.Module):#注意Module首字母需要大写
def __init__(self, input_size=1, hidden_layer_size=100, output_size=1):
super().__init__()
self.hidden_layer_size = hidden_layer_size
# 创建LSTM层和linear层,LSTM层提取特征,linear层用作最后的预测
##LSTM算法接受三个输入:先前的隐藏状态,先前的单元状态和当前输入。
self.lstm = nn.LSTM(input_size, hidden_layer_size)
self.linear = nn.Linear(hidden_layer_size, output_size)
#初始化隐含状态及细胞状态C,hidden_cell变量包含先前的隐藏状态和单元状态
self.hidden_cell = (torch.zeros(1, 1, self.hidden_layer_size),
torch.zeros(1, 1, self.hidden_layer_size))
# 为什么的第二个参数也是1
# 第二个参数代表的应该是batch_size吧
# 是因为之前对数据已经进行过切分了吗?????
def forward(self, input_seq):
lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq), 1, -1), self.hidden_cell)
#lstm的输出是当前时间步的隐藏状态ht和单元状态ct以及输出lstm_out
#按照lstm的格式修改input_seq的形状,作为linear层的输入
predictions = self.linear(lstm_out.view(len(input_seq), -1))
return predictions[-1]#返回predictions的最后一个元素
下面创建LSTM()类的对象,定义损失函数和优化器。
#创建LSTM()类的对象,定义损失函数和优化器
model = LSTM()
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)#建立优化器实例
print(model)
下面开始训练,
"""
模型训练
batch-size是指1次迭代所使用的样本量;
epoch是指把所有训练数据完整的过一遍;
由于默认情况下权重是在PyTorch神经网络中随机初始化的,因此可能会获得不同的值。
"""
epochs = 20
for i in range(epochs):
for seq, labels in train_inout_seq:
#清除网络先前的梯度值
optimizer.zero_grad()#训练模型时需要使模型处于训练模式,即调用model.train()。缺省情况下梯度是累加的,需要手工把梯度初始化或者清零,调用optimizer.zero_grad()
#初始化隐藏层数据
model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
#实例化模型
y_pred = model(seq)
#计算损失,反向传播梯度以及更新模型参数
single_loss = loss_function(y_pred, labels)#训练过程中,正向传播生成网络的输出,计算输出和实际值之间的损失值
single_loss.backward()#调用loss.backward()自动生成梯度,
optimizer.step()#使用optimizer.step()执行优化器,把梯度传播回每个网络
# 查看模型训练的结果
if i%2 == 1:
print(f'epoch:{i:3} loss:{single_loss.item():10.8f}')
print(f'epoch:{i:3} loss:{single_loss.item():10.10f}')
下面为预测代码。
"""
预测
注意,test_input中包含20个数据,
在for循环中,20个数据将用于对测试集的第一个数据进行预测,然后将预测值附加到test_inputs列表中。
在第二次迭代中,最后20个数据将再次用作输入,并进行新的预测,然后 将第二次预测的新值再次添加到列表中。
由于测试集中有20个元素,因此该循环将执行12次。
循环结束后,test_inputs列表将包含24个数据,其中,最后12个数据将是测试集的预测值。
"""
fut_pred = 20
test_inputs = train_data_normalized[-train_window:].tolist()#首先打印出数据列表的最后20个值
print(test_inputs)
下面更改模型为测试或者验证模式。
#更改模型为测试或者验证模式
model.eval()#把training属性设置为false,使模型处于测试或验证状态
for i in range(fut_pred):
seq = torch.FloatTensor(test_inputs[-train_window:])
with torch.no_grad():
model.hidden = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
test_inputs.append(model(seq).item())
#打印最后的20个预测值
print(test_inputs[fut_pred:])
#由于对训练集数据进行了标准化,因此预测数据也是标准化了的
#需要将归一化的预测值转换为实际的预测值。通过inverse_transform实现
actual_predictions = scaler.inverse_transform(np.array(test_inputs[train_window:]).reshape(-1, 1))
print(actual_predictions)
下面绘制所有的实际值以及最后一期的20个预测值。总共八九千个数据把20个值掩盖了。
"""
根据实际值,绘制预测值
"""
x = np.arange(len(data_np)-fut_pred, len(data_np), 1)
plt.title('happy8 results')
plt.ylabel('Draw results')
plt.xlabel('Data')
plt.grid(True)
plt.autoscale(axis='x', tight=True)
plt.plot(data_np)
plt.plot(x, actual_predictions)
plt.show()
因此我们主要看最后20个的观测数据。
#绘制最近20个数字的实际和预测开奖号码
plt.title('happy8 results')
plt.ylabel('Draw results')
plt.xlabel('Data')
plt.grid(True)
plt.autoscale(axis='x', tight=True)
plt.plot(x,data_np[-train_window:])
plt.plot(x, np.rint(actual_predictions))
plt.show()

上图结果不唯一。下面是输出最近20个数字的预测。
actual_predictions_rint=np.rint(actual_predictions)
actual_predictions_rint_sort=np.sort(actual_predictions_rint.ravel())
actual_predictions_rint_sort_unique=np.unique(actual_predictions_rint_sort)
print(actual_predictions_rint_sort_unique)
输出结果为长度不足20的有序数组。LSTM预测最后20个数字是可能有重复的因此我去掉重复并排序了。输出结果可能为[30. 34. 38. 40. 42. 44. 47. 50. 53. 55. 58. 61. 64. 67. 69. 70. 72. 73.
78.]
不足
- 我并没认真花时间研究LSTM模型到底是怎么学习怎么预测的。
- 爬虫时针对issueCount变量可以获得当前时间从而自动爬得最新最全数据,有待改进。
- 只能预测最新20个数字,也就是只能预测一期,怎么改变预测集?
- 怎么强制要求LSTM学习到快乐8的规则如20个数字为一期/这20个数字为从小到大排序/这20个数字范围为1-80。
参考文献
LSTM模型部分我参考了这篇文章:https://blog.csdn.net/ch206265/article/details/106962354/
网络爬虫部分我参考了这篇文章https://www.jianshu.com/p/54011214ca95