统计学是涉及数据的收集,组织,分析,解释和呈现的学科。
统计的类型
1) 描述性统计
描述性统计是以数字和图表的形式来理解、分析和总结数据。对不同类型的数据(数值的和分类的)使用不同的图形和图表来分析数据,如条形图、饼图、散点图、直方图等。所有的解释和可视化都是描述性统计的一部分。重要的是要记住,描述性统计可以在样本和总体数据上执行,但并不会使用总体数据。
2) 推论统计
从总体数据中提取一些数据样本,然后从这些数据样本中,推断一些东西(结论)。数据样本被用作对该总图作出结论的基础。这可以通过各种技术来实现,比如数据可视化和操作。
数据的类型
1、数字数字
数字数据就是指数字或数值型的数据。数值数据又分为离散和连续两类数值变量。
I) 离散数值变量——离散变量的概念是指具有有限取值范围的变量,例如教室中的排名、系中教授的数量等。
II) 连续数值变量——连续变量的值可以是无限的,可能是范围内的任意数值,例如员工的工资。
2、分类数据-
分类数据类型是数据的字符类型表示,例如名称和颜色。一般来说,这些也有两种类型。
I) 序数变量—序数分类变量,其值可以在一系列值中排序,例如学生的年级(a、B、C),或高、中、低。
II) 名义变量——这些变量没有排名,只是包含名称或一些类别,如颜色名称、主题等。
集中趋势量数的度量
集中趋势的度量给出了数据中心的概念,即数据的中心是什么。其中有几个术语,如平均值、中位数和众数。
一个特定数值变量的平均值是其中所有数值的平均值。当数据包含异常值时,不建议找出平均值并将其用于任何类型的操作,因为单个异常值会严重影响平均值。
中值是对所有数字排序后的中心值。如果总数是偶数,那么它就是中心2值的平均值。它不依赖或影响异常值,除非一半的数据是异常值(这样的话就不是异常值了)。
众数是观察结果中出现最多的数值。Numpy没有提供查找众数的函数,但是Scipy有。
在使用的时候,不要只使用他们三个的一个,可以试着全部使用这三种方法,这样就可以理解数据的本质。
数据分布度的度量
分布度度量描述了特定变量(数据项)的观察值集的相似性或变化程度。分布度的度量包括范围,四分位数和四分位数范围,方差和标准差。
1、范围
通过比较数据的最大和最小值(最大值)来定义范围。
2、四分位数
四分位数是按数字列表分为四分之一的值。找到四分位数的步骤是。
- 按顺序排列数字
- 将列表切成4个相等的部分
- 4分的切分点就是4分位数的值
可以通过描绘25、50、75和100的百分位数来找到4个四分位数。其中Q2也被称为中位数。
它通过描述与平均值的绝对偏差来描述数据的变化,也称为平均绝对偏差(MAD)。
3、四分位数范围(IQR)
四分位间范围(IQR)是前75个和后部25个百分位数之间分散体的量度。它经常出现在异常值检测和处理的情况下。
4、平均绝对偏差
它通过描述与平均值的绝对偏差来描述数据的变化,也称为平均绝对偏差(MAD)。简单地说,它告诉集合中每个点与平均绝对距离。
5、差方
方差衡量的是数据点离均值的距离。要计算方差,需要找出每个数据点与平均值的差值,然后平方,求和,然后取平均值。可以直接用numpy计算方差。
方差的问题在于:由于是平方,它与原始数据不在同一个计量单位内。因为它不是直观的,所以大多数人更喜欢标准差。
6、标准差
方差的平方根是标准差,因为我们对原始单位平方,所以我们再次得到相同测量的标准差。使用Numpy,可以直接计算这个。
正态分布
正态分布是钟形曲线形式的分布,机器学习中的大多数数据集遵循正态分布,如果不是正态分布,一般会尝试将其转换为正态分布,许多机器学习算法在此分布上会有很好的效果,因为在现实中, 世界情景也许多用例也遵循此分配。
如果任何数据遵循正态分布或高斯分布,那么它也遵循三个条件,称为经验公式
P[mean - std_dev <= mean + std_dev] = 68%
P[mean - 2*std_dev <= mean + 2*std_dev] = 95%
P[mean - 3*std_dev <= mean + 3*std_dev] = 99.7%在进行探索性数据分析的同时也可以将任何变量分布转化为标准正态分布。
偏态
偏度是对分布对称性的一种度量,可以用直方图(KDE)来绘制,它在数据众数方面有一个高峰。偏度一般分为左偏数据和右偏数据两种。有些人也把它理解为三种类型,第三种是对称分布,即正态分布。
一、数据右偏(正偏分布)
右偏态分布是指数据有一个向右的长尾(正轴)。右偏的一个经典例子是财富分配,很少人拥有很高的财富大多数人处于中等范围。
二、数据左偏(负偏分布)
左偏态分布是指数据有一个长尾朝向左侧(负轴)。一个例子可以是学生的成绩,将会有更少的学生得到更少的成绩,最大的学生将会在及格类别。

中心极限定理
中心极限定理:分析任意总体的样本数据做一些统计测量后,标准差的均值和样本均值会近似相等。这只是中心极限定理。
概率密度函数(PDF)
如果你知道直方图,然后你把数据进行分箱,就可以对数据进行可视化的分析。但是如果我们想对数值数据进行多类分析,那么很难使用直方图进行操作。这是就需要使用概率密度函数。概率密度函数是仅使用KDE(内核密度估计)在直方图内绘制的线。

在上面的图中,编写3个区分分类3个类的条件该怎么做?使用直方图和PDF可以轻松的看到区别。
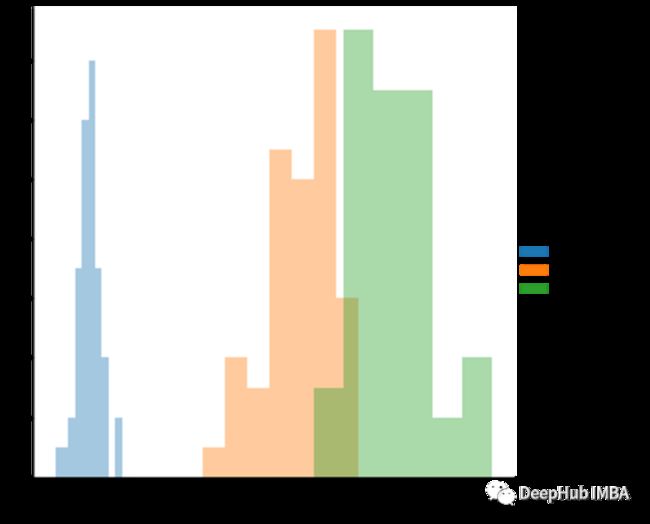
从上方直方图中可以看出,如果值小于2,则是setosa。如果大于2且小于4.5,那么它是versicolor。从5到7都是virginica。但是4.5之后的重叠区域会对判断进行干扰,在这里PDF可以为我们提供更多的理论支持。
累积分布函数(CDF)
CDF可以告诉我们有多少百分比的数据小于某个特定的数字。找到CDF的过程是,将在指定点之前的所有的直方图相加。另一种方法是使用微积分,使用曲线下面积,找到想要CDF的点,画出直线,然后求出内部面积。可以对PDF进行积分得到CDF,对CDF求导得到PDF。
如何计算PDF和CDF
我们将计算setosa的PDF和CDF。我们将花瓣长度转换为10个分箱,并提取每个箱的样本数和边缘值,这些边缘表示容器的起点和终点。为了计算PDF,我们将每个频率计数值除以总和,我们得到概率密度函数,找到PDF,就可以继续计算得到CDF。
ounts, bin_edges = np.histogram(iris_setosa[‘PL’], bins=10)
pdf = counts / sum(counts)
cdf = np.cumsum(pdf)
print(pdf)
print(cdf)https://avoid.overfit.cn/post/77b3cb6cf95c4e46b3342f7af40b6451
作者:Anjali Dharmik