From Goals, Waypoints & Paths To Long Term Human Trajectory Forecasting(一)
cvpr2021行人轨迹预测论文,写一写对论文的翻译,当然水平在这只能是意译。
Abstract
人类轨迹预测一直以来都是多模态问题。未来轨迹的不确定性主要来自两个方面:(a)知道人的行为意图,但不知道怎么去建模,例如长期目标(预测);(b)既不知道人的行为意图,也不知道怎么去建模,例如行人的目的以及决策的随意性。我们提出将这种不确定性分解为认知因素和随机因素(两方面)。对于认知不确定性,可以通过在长期目标(预测)中的多模态进行建模;对于随机不确定性,可以通过在沿路点与其路径(预测)中的多模态进行建模。为了验证这一想法,我们还提出了一种新的用于长期轨迹预测的方法,这种方法的预测时长高达一分钟,比以往(工作)方法高出一大截。最后,我们还提出了Y-Net模型,一种与场景兼容的轨迹预测网络,利用先前所述的认知(不确定性)和随机(不确定性)模型,预测不同的轨迹。...
1. Introduction
序列预测是信号处理、模式识别、控制工程等多个工程学科以及几乎所有与时间测量有关的领域中的一个基本问题。... 时间序列预测是序列预测问题的一个关键实例,在这种情况下,序列由实践采样的元素组成。一些经典的技术,例如自回归移动平均模型(ARMA)已经被纳入现代先进时间序列预测方法的深度学习体系结构当中。
然而,人类不是无生命的牛顿实体抑或是物理规律的奴隶。预测台球在摩檫力和物理约束条件下在台球桌上的平稳滚动的未来运动,与预测人(在未来时间)如何运动、位置在哪(的方法)不同。人类不像是台球(没有思想),人类是目标的产物,会发挥主观能动性实现他们既定的目标。预测人类的运动对于动态智能体,例如其他人、自动化的机器人、自动驾驶的汽车来说是及其重要的。人的运动本质是以目标为导向的,并由自身实现,以达到预期的目的。
可是,仅以一个人过去的运动和长期的目标(导向)为条件,就能够决定将来的轨迹吗?现在想象这样一个场景:你呢,站在一个繁忙的街道上等红绿灯,当然,你的目的是要走到街的另一边去,然而你的行动轨迹可能是随机的,因为你可能急转弯去避让其他行人,或者因为即将要变的红灯突然加速,再或者因为难以控制的骑自行车的人的猛冲而突然停止。因此,即便以过去的运动和语义场景为条件,人类轨迹仍然随机性的,潜在的决策变量(比如长期目标)引起的认知不确定性和随机决策变量(如环境因素)引起的任意变化是(造成这种随机性的)主要原因。 ...
这促使人类动力学建模采用因式多模态的方法,其中随机性的两个因素都是分层建模的,而不是集中在一起的。我们假定行人(内心)长期潜在的目标代表了运动预测中的认知不确定性。尽管行人有在心中计划这个目标,但是我们不知道这个目标goal会不会变啊。这在现实中就相当于某个人要去哪里的问题。同样地,你有了目标,但是怎么去实现这个目标的路径就是随机不确定性,这种随机不确定性包含了环境因素例如其他行人,和决策中无意识的随机性。在现实中这就相当于某个人心里有了目的地怎么实现的问题。
因此我们提出先将认知不确定性进行建模,然后以认知不确定性为条件,再对随机不确定性建模(简单来说就是先定好目的地,再规划好到达目的地的路径)。具体来说就是给定一张RGB的三通道场景照片和行人的运动历史,先对行人的目的地(或者说长期目标)进行概率估计,这不就是上面提到的预测系统中的认知不确定性吗?于此同时,我们还得对几个选定的航路点(waypoint)做出估计,这些航路点将与咱们的目标点(长期目标)一起用于获得所有通往目的地轨迹的显式概率图。(简单来说就是只有目的地不行,还得确定几个航路点,这几个航路点与目的地共同构成了多条轨迹路径)这不就是上面提到的预测系统中的任意不确定性吗?总结一下,长期目标goal、航路点waypoint,以及多条轨迹路径一同构成了咱们的未来轨迹。(所以说是多模态的问题嘛)
说了这么多,我们有什么贡献呢?我们有三大贡献:一是提出了长期轨迹预测的方法,预测时间高达一分钟,比之前文献中的方法高了一大截。二是提出了Y-Net网络模型,Y-Net是一种与场景兼容的长期预测网络,在有效利用场景语义的同时,明确地对目标(目的地)和路径(多条轨迹路径)进行建模。三是提出的Y-Net超越了SOTA的方法,表明因式化建模的可行性。...
2. Related Works
这一部分就不写了,因为不想写。关键词得记一下并了解:Social Forces、Social LSTM、CVAE、inverse reinforcement learning、Social GAN...
3. Proposed Method
多模态预测问题可以正式地用公式表述为:给定一张RGB三通道的图片 和在该图片中行人在
和在该图片中行人在![]() 时刻的过去位置
时刻的过去位置![]() ,模型将预测行人在下一时刻
,模型将预测行人在下一时刻![]() 的位置,表示为
的位置,表示为![]() ,其中
,其中![]() 。由于未来是随机的,因此对(行人)未来的轨迹有着多种预测。在我们的工作中,我们将所有的随机性分成了两种模式。第一种是与认知不确定性相关的模式,也就是最终目的地的多模性,目的地的多模性我们用
。由于未来是随机的,因此对(行人)未来的轨迹有着多种预测。在我们的工作中,我们将所有的随机性分成了两种模式。第一种是与认知不确定性相关的模式,也就是最终目的地的多模性,目的地的多模性我们用![]() 来表示。第二种是与随机不确定性相关的模式,也就是到达目的地路径的多模性,这源于给定目的地的不可控的随机性,路径的多模性咱们用
来表示。第二种是与随机不确定性相关的模式,也就是到达目的地路径的多模性,这源于给定目的地的不可控的随机性,路径的多模性咱们用![]() 来表示。在短时间预测中,由于总的路径长度很短,因此通往给定目的地的路径选项是有限的,并且这些路径彼此还都相似。自然而然,由于这种特性,我们在短期预测中常把
来表示。在短时间预测中,由于总的路径长度很短,因此通往给定目的地的路径选项是有限的,并且这些路径彼此还都相似。自然而然,由于这种特性,我们在短期预测中常把![]() 设置为1。但是在长时间预测中,显然到达一个相同的目的地会有着不同的路径,所以在长期预测中
设置为1。但是在长时间预测中,显然到达一个相同的目的地会有着不同的路径,所以在长期预测中![]() >1。另外,我们在3.2小结中详细描述了我们所提出的Y-Net模型以及其三个子网络
>1。另外,我们在3.2小结中详细描述了我们所提出的Y-Net模型以及其三个子网络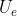 、
、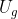 、
、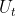 和损失函数。
和损失函数。
3.1 Y-Net Sub-Networks
为了有效地使用语义空间中的场景信息和轨迹信息(坐标),需要在不同模式之间创建像素级对齐。之前的工作是怎么实现这一要求的呢——对RGB图像进行编码作为一个隐藏的状态向量,该隐藏状态向量来自预训练的CNN网络。虽然这为网络提供了场景信息,但任何有意义的空间信号在展平为向量时都会高度融合,(这会使得)像素对齐被破坏。... 在我们的工作中,我们采用了一种基于场景轨迹热力图的表示方法,在图像相同空间中表示轨迹(的方法)来解决对齐问题。
3.1.1 Trajectory-on-Scene Heatmap Representation
上面提到一种基于场景的热力图的表示方法来解决像素对齐问题,那具体是怎么操作的呢?首先,(给定的)RGB图像首先使用语义分割网络(如U-Net)进行处理,该语义分割网络生成图像的分割图 ,(语义)分割图有
,(语义)分割图有 个类别,类是根据行人当前的行为如行走、站立、跑步等动作而确定的。与此同时,咱们还得做一件事——将行人的过去运动
个类别,类是根据行人当前的行为如行走、站立、跑步等动作而确定的。与此同时,咱们还得做一件事——将行人的过去运动![]() 转换成与图像空间大小(一致)、有着
转换成与图像空间大小(一致)、有着![]() 个通道的轨迹热力图
个通道的轨迹热力图 ,其中每个timestep对应一个通道。数学表达式为:
,其中每个timestep对应一个通道。数学表达式为:
![]()
随后,将轨迹热力图沿通道维度与语义分割图进行concatenate拼接,得到基于场景的轨迹热力图向量![]() ,其维度为
,其维度为![]() ,将其作为输入向量送到编码器当中去。
,将其作为输入向量送到编码器当中去。
3.1.2 Trajectory-on-Scene Heatmap Encoder
刚才咱们提到轨迹热力图向量![]() ,那接下来该做什么事情呢?
,那接下来该做什么事情呢?![]() 首先会被送到编码器当中去,编码器设计成U-Net encoder的形式,但并不是单纯的U-Net encoder,因为在U-Net中encoder是vgg形式,而在这里被设计成了ResNet-101的形式。编码器由
首先会被送到编码器当中去,编码器设计成U-Net encoder的形式,但并不是单纯的U-Net encoder,因为在U-Net中encoder是vgg形式,而在这里被设计成了ResNet-101的形式。编码器由 个block组成,每个block后面都有一个最大池化操作(步长为2),这使得空间尺寸逐block减半(但通道数此时不变),池化后面紧跟卷积+ReLU的操作,使得通道维度逐block递增(但此时空间尺寸不变)。Encoder的最终输出
个block组成,每个block后面都有一个最大池化操作(步长为2),这使得空间尺寸逐block减半(但通道数此时不变),池化后面紧跟卷积+ReLU的操作,使得通道维度逐block递增(但此时空间尺寸不变)。Encoder的最终输出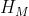 与其中间输出
与其中间输出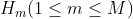 将会被送到目标解码器和轨迹解码器当中去。
将会被送到目标解码器和轨迹解码器当中去。
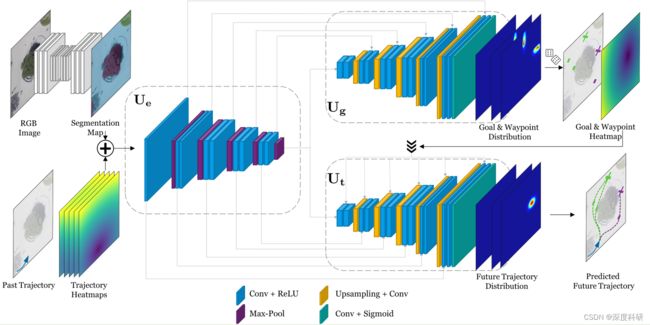
3.1.3 Goal and Waypoint Heatmap Decoder
刚才呢有提到,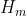 实际上就是编码器的中间输出,它有着不同的空间分辨率。在encoder 中我们干了一件什么事情呢?我们做了这样一件事:将基于场景的轨迹热力图向量
实际上就是编码器的中间输出,它有着不同的空间分辨率。在encoder 中我们干了一件什么事情呢?我们做了这样一件事:将基于场景的轨迹热力图向量![]() 输入到我得encoder当中,经过一些列的池化和卷积的交替操作,得到有着不同空间分辨率的基于场景的轨迹热力图向量和encoder的最终输出。将与(
输入到我得encoder当中,经过一些列的池化和卷积的交替操作,得到有着不同空间分辨率的基于场景的轨迹热力图向量和encoder的最终输出。将与( 有范围,表示说我的有多个不同的取值)送入到目标解码器当中去,也是仿照U-net decoder的架构设计。 那的架构长什么样呢?首先,一个center block接收我的,该center block由两个卷积层+ReLu组成;然后,在每个block的一开始,先进行双线性上采样和卷积的操作(也就是反卷积),这会使得空间分辨率逐block倍增;在反卷积之后是两层的卷积层,来自编码器的中间输出将会与这两层卷积层的前一层的输出进行skip connection,实际上就是特征融合,然后再送到两层卷积的后一层,再开始反卷积——卷积——skip connection的循环操作。有必要一提的是,这种融合来自编码过程中高分辨率特征图的举措是非常有必要的,因为如果仅仅使用的最终输出特征,将会极大地限制goal heatmap的最终分辨率,这将丢失保存在中间特征图中的精细空间细节。总的来说,重复反卷积——卷积——skip connection操作次就构成了基本的网络结构,但是还有一点没有说明,那就是的输出是怎样的呢?的输出层由一个卷积层后跟一个像素级的sigmoid函数组成,对于每个
有范围,表示说我的有多个不同的取值)送入到目标解码器当中去,也是仿照U-net decoder的架构设计。 那的架构长什么样呢?首先,一个center block接收我的,该center block由两个卷积层+ReLu组成;然后,在每个block的一开始,先进行双线性上采样和卷积的操作(也就是反卷积),这会使得空间分辨率逐block倍增;在反卷积之后是两层的卷积层,来自编码器的中间输出将会与这两层卷积层的前一层的输出进行skip connection,实际上就是特征融合,然后再送到两层卷积的后一层,再开始反卷积——卷积——skip connection的循环操作。有必要一提的是,这种融合来自编码过程中高分辨率特征图的举措是非常有必要的,因为如果仅仅使用的最终输出特征,将会极大地限制goal heatmap的最终分辨率,这将丢失保存在中间特征图中的精细空间细节。总的来说,重复反卷积——卷积——skip connection操作次就构成了基本的网络结构,但是还有一点没有说明,那就是的输出是怎样的呢?的输出层由一个卷积层后跟一个像素级的sigmoid函数组成,对于每个![]() 选定的航路点
选定的航路点![]() 和目的地
和目的地![]() 在归一化后产生一个明确地、没有参数地概率分布
在归一化后产生一个明确地、没有参数地概率分布![]() 、
、![]() 。的输出维度为
。的输出维度为![]() ,因此,对于每个
,因此,对于每个![]() 航路点和目的地goal,将产生一个
航路点和目的地goal,将产生一个![]() 的矩阵,矩阵中的第
的矩阵,矩阵中的第 个元素表示行人在选定的timestep时刻于位置处的估计概率值。
个元素表示行人在选定的timestep时刻于位置处的估计概率值。
3.1.4 Trajectory Heatmap Decoder
从上面的网络结构图不难看出,轨迹热力图解码器的网络结构与目的地&航路点轨迹热力图解码器的网络结构差不多,也是一个center block后跟着反卷积——卷积——skip connection的操作。在中我们可以得到目标点goal、航路点waypoint的概率分布,利用这个概率分布就能够采样我们所需的goal and waypoint。具体的采样过程在3.2小结以及增补附录中有详细说明。总的来说,我们要在中干一件什么事呢?首先根据中的概率分布得到我们想要的目的地goal和航路点waypoint,我们得到![]() 个目标点和
个目标点和![]() 个航路点,那通往一个相同的目标点就应该由
个航路点,那通往一个相同的目标点就应该由![]() 条路径。其次,将获得的目标点
条路径。其次,将获得的目标点![]() 和中间航路点
和中间航路点![]() 的坐标(在同一幅图中)转换为相应的热力图,用
的坐标(在同一幅图中)转换为相应的热力图,用 表示(也就是图中Goal & Waypoint Heatmap),这有点类似于3.1.1中的过去轨迹热力图表示。最后,对向量进行下采样以匹配每个block的空间尺寸(从图中来看是要下采样6次,匹配的意思指的是”拼接“,而不是”输入“),与类似,在反卷积之后是两层的卷积层,来自编码器的中间输出将会与这两层卷积层的前一层的输出进行skip connection,实际上就是特征融合,然后再送到两层卷积的后一层,再开始反卷积——卷积——skip connection的循环操作。需要注意的是每次反卷积都有特征融合。对于未来每个timestep,预测一个单独的概率分布,从而产生形状为
表示(也就是图中Goal & Waypoint Heatmap),这有点类似于3.1.1中的过去轨迹热力图表示。最后,对向量进行下采样以匹配每个block的空间尺寸(从图中来看是要下采样6次,匹配的意思指的是”拼接“,而不是”输入“),与类似,在反卷积之后是两层的卷积层,来自编码器的中间输出将会与这两层卷积层的前一层的输出进行skip connection,实际上就是特征融合,然后再送到两层卷积的后一层,再开始反卷积——卷积——skip connection的循环操作。需要注意的是每次反卷积都有特征融合。对于未来每个timestep,预测一个单独的概率分布,从而产生形状为![]() 的输出,伴随着每个通道对应于每个timestep的位置分布。
的输出,伴随着每个通道对应于每个timestep的位置分布。
3.2 Non-parametric Distribution Sampling
之前有说所需的目标点goal与航路点waypoints是通过中的概率分布采样得到的,那采样的过程是怎样的呢?实际上说了跟没说似的,得去看代码和增补附录才能知道。论文中提到,给定未来帧位置的分布 作为概率
作为概率 的矩阵,其目的是采样一个二维点作为我们对行人位置的估计(这比不说还难受)。... 仅用简单的argmax已经不能满足要求了,得用所提议的softargmax来估计行人的位置,具体公式如下:
的矩阵,其目的是采样一个二维点作为我们对行人位置的估计(这比不说还难受)。... 仅用简单的argmax已经不能满足要求了,得用所提议的softargmax来估计行人的位置,具体公式如下:

3.3 Loss Function
由于与预测(结果)是每个timestep上的显示概率分布,因此我们直接将损失加在(概率)估计分布![]() 上,而不是加在绘制的坐标样本上。Ground truth被表示为以观测点为中心的高斯热力图(Gaussian Heatmap ),具有预先设定的方差
上,而不是加在绘制的坐标样本上。Ground truth被表示为以观测点为中心的高斯热力图(Gaussian Heatmap ),具有预先设定的方差![]() 。、、这三个网络都是端到端联合训练的,在预测目标点goal、航路点waypoints以及轨迹分布中使用的都是二进制交叉熵的加权组合。具体公式如下:
。、、这三个网络都是端到端联合训练的,在预测目标点goal、航路点waypoints以及轨迹分布中使用的都是二进制交叉熵的加权组合。具体公式如下:
4. Result
我们使用三个数据集——SDD、InD以及ETH/UCY作为基准数据来测试Y-Net的性能。
Stanford Drone Dataset(SDD):我们在SDD数据集上测试了Y-Net模型,在过去几年里,所提出的一些(行人轨迹预测)的方法都在SDD数据集上取得了SOTA的卓越性能。SDD数据集包含了11000位不同的行人,横跨20个自上而下的场景,这些场景由无人机通过鸟瞰的方式在斯坦福大学所拍摄。对于短期预测,我们遵循[35,28]标准设置和数据分割(的方法),以FPS=2.5进行采样,得到长度为![]() 的输入序列,和长度为
的输入序列,和长度为![]() 的输出序列,在之前有说
的输出序列,在之前有说![]() ,所以这里
,所以这里![]() ;同理
;同理![]()
在长期预测中,我们以FPS=1进行采样,在(输入序列)![]() 的条件下得到
的条件下得到![]() ,然后预测未来一分钟(行人的运动轨迹)。此外,我们用语义分割(的方法)标记场景,(某个)场景的语义分割图由
,然后预测未来一分钟(行人的运动轨迹)。此外,我们用语义分割(的方法)标记场景,(某个)场景的语义分割图由![]() 类“东西”组成(其实加上背景应该有6类),即路面、地形、结构、树木和道路,具体取决于实际场景。在数据集处理上,以预测短期(轨迹)相同的方式分割数据集场景,以评估在训练期间对不可见场景的性能。论文说的好像不是人话啊。。。
类“东西”组成(其实加上背景应该有6类),即路面、地形、结构、树木和道路,具体取决于实际场景。在数据集处理上,以预测短期(轨迹)相同的方式分割数据集场景,以评估在训练期间对不可见场景的性能。论文说的好像不是人话啊。。。
Intersection Drone Dataset(InD):...
ETH & UCY datasets:...
Implementation Details:我们使用Adam优化器对整个网络进行端到端的训练,设置学习率为![]() ,
,![]() 。使用预训练分割模型,并在指定的数据集上进行微调。更多的实验细节在增补材料中有提及。
。使用预训练分割模型,并在指定的数据集上进行微调。更多的实验细节在增补材料中有提及。
Metrics:我们使用平均位移误差(ADE)与最终位移误差(FDE)来评估模型性能的好坏。ADE计算的是每个预测位置和每个真值位置之间的平均欧式距离差值。 FDE计算的是终点预测位置和终点真值位置之间的平均欧式距离差值。根据以往的工作[13],在有多个预测(结果)的情况下,最终的误差报告为所有预测(结果)的最小误差。...
4.1 Short Term Forecasting Results
Stanford Drone Results:表一展示了SDD数据集在短期预测的结果。我们分了![]() 和
和![]() 两种情况。由于在短期预测中任意多模态(的情况)是有限的,我们将
两种情况。由于在短期预测中任意多模态(的情况)是有限的,我们将![]() 设为1能够与之前的工作(将
设为1能够与之前的工作(将![]() 设为20)进行对比。...
设为20)进行对比。...

ETH/UCY Results:...