Linux必知必会,答应我拿下这些Linux必备技能
- 本文纯粹就是小杰对于自己学完Linux操作系统之后回过头来对于Linux中的核心重点知识的一个梳理.
- 小杰会尽量地将其梳理清楚, 大家一起学习,共同进步, 知识不分高低, 计算机的学习小杰认为也是一个 量变 ---> 质变 的过程
- 天道酬勤, 水滴石穿, 在不同的阶段就干好自己当前阶段力所能及之事, 至少是没有在寝室的床上瘫着消磨时光 -------- 愿大家都学有所成,所获
文件IO相关系统调用 (Linux下一切皆文件, 理解掌握文件IO是必须)
-
IO系统调用内核态, 底层数据结构理解助学
- 我们调用系统调用, 是向内核中对应打开的文件中写入数据, 或者从中读取数据的. 系统调用相当于是打通用户态和内核态的一个通道.
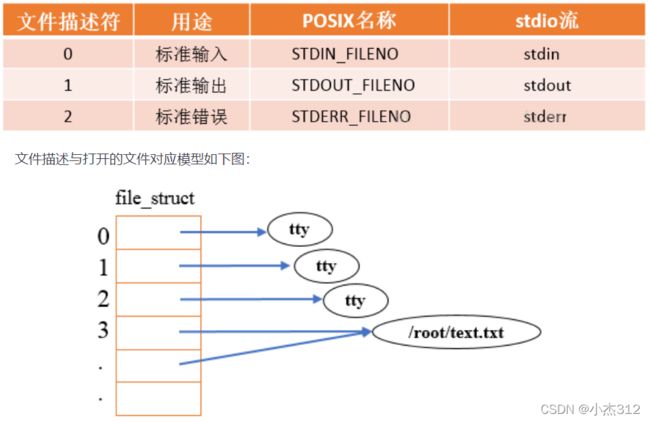
- 我们可以通过向文件描述符fd 进行写入数据, 和读取数据. why? fd: 句柄, 内核数据结构进行了完善的封装组织, 我们通过简单的操作fd, 系统调用就会将操作对应映射到对应打开的文件上面去. --- Linux下面一切皆为文件思想贯穿整个Linux的底层设计, 掌握清楚了文件IO, 对于后序的各种通信的学习和理解也是至关重要的

 inode节点中存储着文件的属性等各种文件相关重要信息., 名字,权限等信息,每一个文件都会一定一个inode, 这个的理解不易细说, 想要解释清楚,还需要结合文件系统,来理解学习.
inode节点中存储着文件的属性等各种文件相关重要信息., 名字,权限等信息,每一个文件都会一定一个inode, 这个的理解不易细说, 想要解释清楚,还需要结合文件系统,来理解学习.
-
open

功能: open file and create new fd (lowest-numbered file descriptor)
Rerturn Val :
sucess return fd failure return -1
-
close
int close(int fd);//关闭fd
括号式编程, 有open 就一定需要close
代码测试
#include
#include
#include
#include
#include
#define BUFFSIZE 1024
int main(int argc, char* argv[]) {
if (argc != 2) {
fprintf(stderr, "usage:%s ", argv[0]);
return -1;
}
char buff[BUFFSIZE] = {0};//用户态缓冲区
int fd = open("./a.txt", O_RDONLY);
if (fd == -1) {
perror("error open");
return -2;
}
printf("open file sucess and fd is %d\n", fd);
close(fd);
return 0;
} 
-
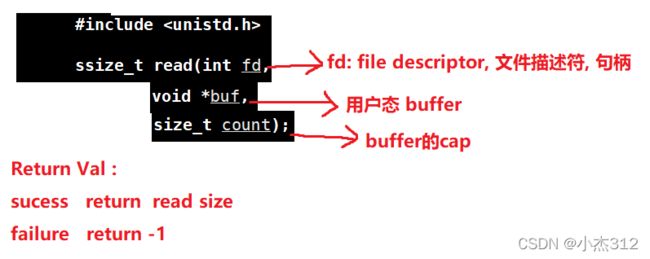
read
eg: 从a.txt 中读取所有数据. 如下是准备a.txt数据
[tangyujie@VM-4-9-centos IO]$ echo 'Hello Linux IO' > a.txt
[tangyujie@VM-4-9-centos IO]$ cat a.txt
Hello Linux IO
如下是代码实现:
#include
#include
#include
#include
#include
#define BUFFSIZE 1024
int main(int argc, char* argv[]) {
if (argc != 2) {
fprintf(stderr, "usage:%s ", argv[0]);
return -1;
}
char buff[BUFFSIZE] = {0};//用户态缓冲区
int fd = open("./a.txt", O_RDONLY);
if (fd == -1) {
perror("error open");
return -2;
}
printf("open file sucess and fd is %d\n", fd);
int read_size = 0;
while ((read_size = read(fd, buff, BUFFSIZE)) != 0) {
buff[read_size] = 0;
printf("%s", buff);
}
close(fd);
return 0;
}

- 其实可以稍作修改不再需要带上./
- 解释一下为啥我们运行系统命令cat cp ... 不需要./ ? 因为环境变量PATH中存在他们所在路径可以找到这个可执行文件进行执行, 如果我们自己写的可执行程序也想要这样执行, 我们就需要将其路径加入到PATH中 或者 是 将其加入到/user/bin 下面去
- 1将其放入到 user/bin/ 目录下面

[tangyujie@VM-4-9-centos IO]$ mycat a.txt
open file sucess and fd is 3
Hello Linux IO
- 2将可执行文件所在路径加入到PATH环境变量中去
[tangyujie@VM-4-9-centos IO]$ export PATH=/home/tangyujie/IO:${PATH}
[tangyujie@VM-4-9-centos IO]$ echo ${PATH}
/home/tangyujie/IO:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/tangyujie/.local/bin:/home/tangyujie/bin
[tangyujie@VM-4-9-centos IO]$ mycat a.txt
open file sucess and fd is 3
Hello Linux IO
-
write

作用: 向对应的fd打开的文件中写入数据 fd ---> file* ----> file.inode
测试代码: 修改上述mycat 案例中的printf 为 write:
test code
#include
#include
#include
#include
#include
#define BUFFSIZE 1024
int main(int argc, char* argv[]) {
if (argc != 2) {
fprintf(stderr, "usage:%s ", argv[0]);
return -1;
}
char buff[BUFFSIZE] = {0};//用户态缓冲区
int fd = open("./a.txt", O_RDONLY);
if (fd == -1) {
perror("error open");
return -2;
}
printf("open file sucess and fd is %d\n", fd);
int read_size = 0;
while ((read_size = read(fd, buff, BUFFSIZE)) != 0) {
write(1, buff, read_size);
}
close(fd);
return 0;
}
test ans
[tangyujie@VM-4-9-centos IO]$ export PATH=/home/tangyujie/IO:${PATH}
[tangyujie@VM-4-9-centos IO]$ echo ${PATH}
/home/tangyujie/IO:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/tangyujie/.local/bin:/home/tangyujie/bin
[tangyujie@VM-4-9-centos IO]$ mycat a.txt
open file sucess and fd is 3
Hello Linux IO
-
fstat

作用:获取file inode 信息, 文件地各种具体信息.
eg : 获取文件地size信息
#include
#include
#include
#include
int main(int argc, char* argv[]) {
if (argc != 2) {
fprintf(stderr, "%s ", argv[0]);
return -1;
}
int fd = open("./a.txt", O_RDONLY);
struct stat st;
int ret = fstat(fd, &st);
printf("file size : %d\n", st.st_size);
close(fd);
return 0;
} -
fcntl

功能:fcntl() 对打开的文件描述符fd执行下面描述的操作之一。操作由cmd决定。
案例测试, 利用fcntl 设置fd = 0为非阻塞, 然后实现一个简单的轮询机制 (flag | O_NONBLOCK)
案例功能: 在20s中不断地轮询是否有标准输入, 有就输出
#include
#include
#include
#include
#include
#include
#define BUFFSIZE 512
int main() {
//设置标准输入为非阻塞
int flags = -1;
if (-1 == (flags = fcntl(0, F_GETFL, 0))) {
perror("fcntl");
return -1;
}
if (-1 == fcntl(0, F_SETFL, flags | O_NONBLOCK)) {
perror("fcntl");
return -2;
}
char buff[BUFFSIZE] = {0};
int n = 20;//轮询20s
while (n > 0) { //轮询
int read_size = read(0, buff, BUFFSIZE);
if (read_size >= 0) {
write(1, buff, read_size);
continue;
}
if (errno == EAGAIN) {
write(1, "try try\n", 8);
} else {
break;//出错了
}
sleep(1);//休眠
n -= 1;
}
return 0;
} -
dup2

- dup2(oldfd, newfd); 函数功能:使 newfd 指向 oldfd 所对应打开地文件
Return Value :
Success return new descriptor,
Failure return -1;
eg : 简简单单地进行一下 dup(3, 1); // 这样进行标准输出, 就会输出到 open file中去了, test 案例, 其实这个就是一个输出重定向了
#include
#include
#include
int main(int argc, char* argv[]) {
if (argc != 2) {
fprintf(stderr, "%s ", argv[0]);
return -1;
}
int fd = open("./a.txt", O_RDWR);
//其实fd == 3;
int ret = dup2(fd, 1); //进行输出重定向到a.txt文件中
if (ret == -1) {
perror("dup2");
return -2;
}
write(1, "Hello Dup2\n", 11);
char buff[12];
sprintf(buff, "%d", ret);
write(1, buff, strlen(buff));
close(fd);
close(ret);
return 0;
} 理解重定向
> >> < 这些都是重定向符号, 上述, 本来该输出到显示器上地数据全部输出到open file a.txt中了, 这种就叫做重定向.
[tangyujie@VM-4-9-centos IO]$ echo "Hello 重定向" > a.txt
[tangyujie@VM-4-9-centos IO]$ cat a.txt
Hello 重定向
[tangyujie@VM-4-9-centos IO]$ echo "Hello 没有重定向, 正常输出到显示屏上"
Hello 没有重定向, 正常输出到显示屏上
echo "Hello 重定向" 本来正常应该输出到显示屏幕上地, 然后我们进行一下 > a.txt, 本应该正常输出到显示屏上地数据就写入到了a.txt文件中了, 真有意思哈
重定向理解: 本来应该输出到标准显示器设备上去地数据输出到重定向地文件中, 本来应该从标准输入设备键盘上读取地数据, 从定向从文件中读取了...
其实重定向在底层就做了两件事:close(0) close(1) 然后 open(定向文件).
文件IO小结: 提问解答, 巩固提升
- 每一个进程地task_struct如何关联文件? files*成员指针 指向 files_struct.
- fd文件描述符本质是什么? 是file* 数组地下标 fd_array下标
- file 如何获取文件各种信息? file中存在inode元信息
- fstat有啥作用? 可以获取文件各种信息
- 重定向本质是什么? fd重新对应一个open file
- dup2(oldfd, newfd)如何理解? newfd对应指向oldfd的inode
进程调度相关系统调用
-
进程理解
- 上述这张图, 几乎每一个初学进程的人都会认识的第一张图.
- 画图软件, 浏览器, 各种软件, 双击点开,究竟是干了一件什么事情?
- 将文件从硬盘加载到内存中
- 然后CPU不断的从内存中获取指令 + 数据进行运算
- 将运算的结果写回内存. (小杰盲猜是写到显存, 显卡内存) 不然你咋可以在电脑屏幕上看见效果嘞
上述的处于运行状态下的程序就是一个进程了. 程序仅仅只是一段代码, 是静态的. 是一些数据 + 指令所构成的.
进程:运行起来的程序, 是动态的.
进程:是系统资源分配的基本单位. (分配CPU 内存资源...).
PCB:进程控制块, 进程映射到内核中的数据封装, 数据结构, 管理着当前操作系统下运行的所有程序. 在Linux下的 PCB 实例 叫做 task_struct
task_struct 结构中所包含的重要信息
- pid : 进程id号, 进程的唯一标识, 类比身份证号
- 进程状态信息: running 运行 waiting stop 挂起等待 zombie 僵尸
- files* 指向一个 files_struct, files_struct 核心是包含一个file* 指针数组. 数组下标就是fd
- 程序计数器PC指针, 指向下一条指令的地址
- 优先级信息.
process 进程状态理解:
运行状态 : 进程处在运行队列的队头, CPU正在处理其中的指令进行运算刷新结果
等待状态 : 进程处在等待队列中, 整个进程休眠, 不分配CPU, 进程等待被唤醒, 存在很多进程间切换,代价不小
僵尸状态: 进程死亡了, 结束了, 但是尸体摊在哪里, 无人收尸, 故而成为僵尸, 正常来说, 进程终止运行之后会被父进程或者是操作系统回收资源. 终止后 资源得不到回收的进程 便称为 僵尸进程
等下后面我会在合适的位置为大家演示一下何为僵尸 --- 至此大家先对于僵尸的理解浅止于尸体,系统资源得不到回收的状态.
进程重点性质学习
独立性: 多个进程的进程地址空间是隔离的,进程是独占进程资源的, 多进程之间运行互不干扰
并行:在多核CPU作用下, 多个进程同时运行,同时推进, 谓之并行
并发:多个进程在一个CPU下,在一段时间内, 不停的进行进程间切换, 使得多个进程在这一段时间中都向前推进, 谓之并发. (表面上看多个任务,进程都在执行, 其实是切换着使用单CPU执行, 同一时刻仅仅只是一个进程得以运行, 但是一段时间内, 由于切换执行, 都有所推进)
-
fork
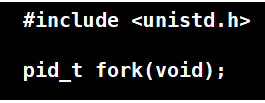
功能:复制一个子进程出来. -- 注意词语: 复制
此处我为何要用复制, 而不是创建等其他词语, 我说复制, 其实就是想告诉大家 fork 出来的子进程几乎是和原来的进程是一摸一样的, 不同仅仅只是 pid ... 些许的差别, 就像区分克隆体只能通过编号一般
fork之后, 两个进程是运行一样的代码. 相当于是在fork处进行一个分流出来一样, 都是执行相同的代码块, 但是父子往往逻辑分工不同, 此时 我们需要通过一定的判断, 区分父进程和子进程, 使其执行不同的代码逻辑. --- 各自分工.
卖个关子,留个疑惑, 我们如何通过判断区分父子进程? 先看代码 --- 父进程打印父进程pid说我是爸爸, 子进程打印子进程pid说我是儿子.
#include
#include
#include
#include
#include
int main() {
pid_t pid;
pid = fork();
if (pid == 0) { // 说明是son
printf("return val: %d sonpid: %d, I am son\n", pid, getpid());
sleep(1);//睡一下等儿子先死掉.
} else {
//说明是 fa
printf("return val: %d, pid: %d\n", getpid(), pid);
}
return 0;
} ![]() 看见结果 --- 透过表象看见了啥了? 发现 fork 之后的 return val 不一样呀我去
看见结果 --- 透过表象看见了啥了? 发现 fork 之后的 return val 不一样呀我去
其实精华出现了: 好比是开返回值盲盒. 开到了0 OK 我知道了,我是儿子, 开到了非0 我知道了,我开出来了我儿子的进程id号, 我是爸爸.
Return Val :
对于父进程 : return sonpid. 子进程id号
对于子进程 : return 0.
好了好了, 搞定了fork了, 咱就可以演示一把僵尸了. --- 咋个玩? 父进程死睡, 子进程自杀, 就可以产生僵尸, 因为子进程死了, 但是我父进程是不停的循环着睡觉, 根本睡不醒, 实在没法给孩子收尸, 孩子尸体晾在哪里, 就是僵尸进程
#include
#include
#include
#include
#include
int main() {
pid_t pid;
pid = fork();
if (pid == 0) {
return -1;//子进程直接死掉嗝屁
} else {
//fa
while (1) {
sleep(1);//不停睡, 睡醒再睡
}
}
return 0;
} ![]()
爸爸死睡觉, 儿子躺板板成僵尸了
-
wait + waitpid

传出参数status, 作用就是传出获取死亡状态信息. 其实就是获取退出码.
status的实现, 本质是啥? 其实我们应该看成是二进制位, 看成是32位二进制位, 但是我们仅仅只是研究低16位. 底16位的高八位存储的是正常退出的退出码, 低七位标识是否是正常退出的, 也就是信号码 sig code. status & 0x7F 就是 sig code. 终止信号值

多说无益, 代码才是硬道理, 情景案例: 正常杀死 + 使用 kill -9 杀死, 咱看看究竟 exit code 和 sig code 是不是对应的值就OK了
WIFEXITED(status) 判断是否是正常退出
returns true if the child terminated normally,WEXITSTATUS(status) 返回孩子的退出状态
returns the exit status of the childWIFSIGNALED(status) 判断是不是信号异常终止
returns true if the child process was terminated by a signal.WTERMSIG(status) 返回终止信号
returns the number of the signal that caused the child process to terminate.
#include
#include
#include
#include
#include
#include
int main() {
pid_t pid;
pid = fork();//创建copy进程
if (pid == 0) {
//son process
sleep(30);//子进程先进行休眠, 等待被kill
exit(100);//正常退出, 死亡状态码100
} else {
int status;//获取死亡状态信息
if (-1 == wait(&status)) {
perror("wait");
return -2;
}
//通过低7位字节判断是不是信号杀死的
if (status & 0x7F) {
//true 是信号杀死的
printf("process is exit by signal, and signal code is %d\n", status & 0x7F);
} else {
//false 正常退出的
printf("process is exited, and exit code is %d\n", (status>>8) & 0xFF);
//低16位的高八位是正常退出时候的退出码
}
}
return 0;
}
ans: 正常退出, 果然是 status的低16位的高8位就是存储的正常退出码.
ans: 被kill -9 信号杀死 status的低16位的低7位就是存储的中断信号

在休眠时间内, 将子进程给kill -9 暗杀了
方式2:通过提供的系统调用进行判断 , 其实系统调用底层也是按照二进制位进行 & 操作来获取的死亡状态信息的
#include
#include
#include
#include
#include
#include
int main() {
pid_t pid;
pid = fork();//创建copy进程
if (pid == 0) {
//son process
sleep(30);//子进程先进行休眠, 等待被kill
exit(100);//正常退出, 死亡状态码100
} else {
int status;//获取死亡状态信息
if (-1 == wait(&status)) {
perror("wait");
return -2;
}
if (WIFEXITED(status)) {
//说明是正常中断的
printf("process is exited, and exit code is %d\n", WEXITSTATUS(status));
} else if (WIFSIGNALED(status)) {
//说明是信号中断掉的
printf("process is signal, and signal code is %d\n", WTERMSIG(status));
} else {
printf("进程终止原因未知\n");
}
}
return 0;
}
-
execvp
程序替换, 将进程中的程序偷换为其他应用程序进行执行, 借进程地址空间,偷换程序执行其他程序.
exec 前后 pid 是不变的, 意思是说进程还是同一个进程, 但是进程执行的代码和数据都换了个遍
至此:理解一些东西, 我们在Linux下执行的ls , cat, pstree ... 命令, 过程究竟如何?

为啥要先 fork 再 exec执行相应的命令, 不然你以为直接exec 直接在bash 本体上干, 干完之后原来的bash 还在嘛, 所以自然是fork出来一个克隆体去进行替换执行
exec一组存在很多的封装库函数, 有各式各样的, 但是其实我个人认为最好用, 最简单的就是execvp了, exec簇函数, 都是execve系统调用的封装库函数, 作用也都是进行进程替换, 替换进程执行部的代码和数据, 让fork出来的进程去执行其他的程序

函数簇特征拆解:
- l (list):列表, 参数列表, 意思就是参数通过可变参数列表args传入, 也可以理解为参数包
- p (PATH) : 意思在于说带有p 就可以在PATH环境变量中自动查找路径, 执行程序的时候就不需要手动传入路径path
- v(vector) : 表示参数用数组来传入, 数组末尾存储的是NULL
- e(env): 是否需要传入环境变量数组. envp[]
使用execvp来使用子进程来完成一下ls -al命令的执行看看
#include
#include
#include
#include
#include
int main() {
pid_t pid = fork();
if (pid == 0) {
//son process
const char* args[] = {"ls", "-al", NULL};
execvp("ls", args);
} else {
//fa process 直接进行exit
exit(10);
}
return 0;
} execvp(const char* file, const char* argv[]);
file : 指的是可执行程序的文件名
argv : 参数包, 就是我们正常写 ls -al 这样的参数包数组, 没有指定大小, 所以需要一个结束字符, 将结束设置为NULL, 前面的 依次按照我们在执行命令时候写的参数依次拆解成字符串写入即可
eg : ls -al args[] = {"ls", "-al", NULL} ps -aux args[] = {"ps", "-aux", NULL}
进程理解,调度,提问解答, 巩固提升
- 进程是什么? 运行中的程序, CPU从内存中获取二进制指令 + 数据执行中的程序.
- PCB是什么? 进程控制块, 进程的组织管理的数据结构
- 进程有哪些状态, 如何理解? running: 运行态, 占据CPU执行的状态 ready: 除了CPU其他一切资源都准备好的状态, 只欠CPU sleeping: 阻塞休眠挂起等待状态, 一般是被阻塞函数阻塞挂起来了 zombie: 僵尸, 进程终止, 但是资源尸体得不到回收的状态
- 进程调度是啥? 分配CPU, 开始执行, 就是进程调度起来了. 从就绪状态转换到运行态, 按照一定的调度算法从就绪队列中选取合适的进程进行调度
- 进程的独立性是什么? 用户空间, 进程地址空间相互独立, 进程间互不干扰
- 并行性? 在多核CPU作用下, 多个进程同时执行, 向前推进
- 并发性? 单个CPU作用下, 多个进程切换执行, 一段时间内都向前推进
- fork进程究竟如何叫合适? 创建一个克隆进程, 区分的关键在于return val.
- ls命令执行的真相? bash 先 fork 出来一个 克隆bash 再进行exec 执行ls程序
进程间通信 (共享信息)
-
进程间通信的理解
通信是为了什么? 我知道, 是为了传递信息, 共享消息, 好日常的解释哈, perfect.
日常生活中的通信是为了在两个人之间共享消息. 进程间通信其实本质就是 两个进程之间共享一些资源,数据...
在前文我们介绍了一个进程的重点性质:独立性, 的确,在用户空间来看, 每一个进程之间都是完完全全的独立运行, 独立存在,互不干扰的. --- 为啥, 不让你乱来呀, 保持进程间的隔离独立
但是, 两个进程之间总会存在需要交流的情况, 如下
数据传输 eg: A进程需要传输 一串数据 到B进程
共享资源:eg : A B 进程之间需要共享一块内存资源memory, 使得A 跟 B 对于 这块memory都可见.
信号发送(通知): 好常见的好吧, 其实你已经用过很多了. 子进程挂了之后,父进程咋知道子进程躺尸了, 我要去为它接收退出码, 回收系统资源. --- 其实就是子进程终止会给父进程发送信号,通知
如何实现通信, 通信的场所在哪里? 内核
有必要搞得很清楚哈, 来张图: 啥意思? 各个进程之间在用户空间中确实是完全隔离的, 但是内核大家是共享的, 是操作系统来维护操作的. 所以内核好比一个交易场所, 进程间的通信都是在内核态中完成的
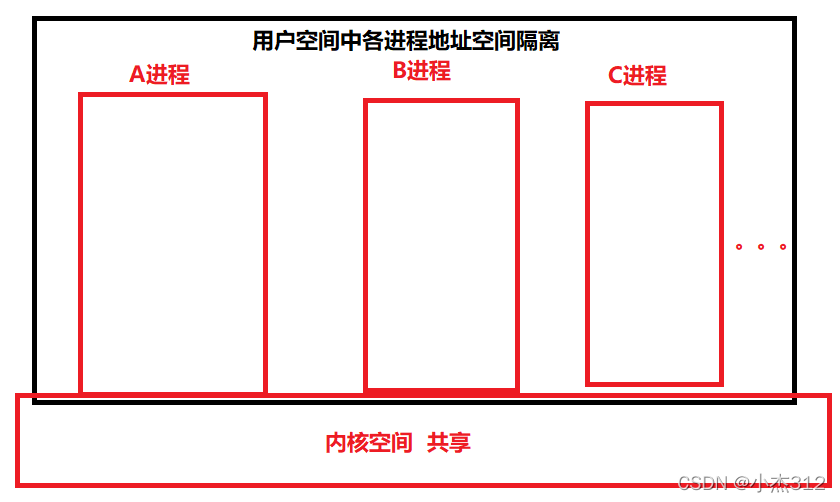
-
管道通信
-
图解管道
何为管道, 管道总是用来传输的, 下水管道是用来传输水的. 同样 进程间在内核态插入的一根管道是为了传输数据的.

管道存在空间, 是内核态的一个缓冲区, 缓存, 管道的实现还是基于Linux下一切皆为文件的思想来完成的, 所以在一定意义上面, 我们可以将pipe管道理解为一个内核文件的感觉 (仅作为个人理解, 可能存在错误, 但是将pipe理解为内核缓存是绝对OK的)
我们从用户进程A中将数据读取到内核pipe文件中, 再将数据从pipe文件写进进程B,也就实现了数据从A流向B, 传输到B的目的了
-
匿名管道
对于匿名管道, 第一印象应该是什么? 是 | ,你可能会说这不是竖划线嘛, 的确它是一根竖划线
但是,这是在你没有学习管道之前你可以这样说, 今天,请你记住它的另外一个称呼, 匿名管道. 其实很形象呀, 管道竖起来不正是很像一根竖划线吗? 对对对, 就是这样滴.
A | B 含义是什么? 将A的输出通过管道传入B 当作B的输入.
eg: 场景带如: fork出来一个子进程, 父进程关闭管道写端, 从管道中读取数据, 子进程关闭管道读端, 向管道中写入数据, 父读子写. --- 父子进程之间进行通信

#include
#include
#include
#include
#include
#include
#define EXIT_ERR(m)\
do { perror(m); exit(EXIT_FAILURE);} while(0)
int main() {
int fds[2];
if (pipe(fds) < 0) { //获取管道
EXIT_ERR("pipe");
}
pid_t pid = fork(); //fork操作一定要在pipe的后面才OK
if (pid < 0) {
EXIT_ERR("fork");
}
if (pid) { //fa
close(fds[1]); //关闭写端
char buff[1024] = {0};
int n = read(fds[0], buff, 1024);
close(fds[0]);
if (n <= 0) {
EXIT_ERR("read");
}
printf("read %d bytes\n", n);
write(1, buff, n);
putchar(10);
} else { //son
close(fds[0]); //关闭读取端口
char buff[1024];
printf("请说:");
scanf("%s", buff); //sizeof(buff) 是容器大小
write(fds[1], buff, strlen(buff) + 1); //此处绝对不能使用sizeof()
close(fds[1]);
}
return 0;
} 

匿名管道的弊端, 以及命名管道的引出, 匿名管道只能用于向父子进程这种存在血缘关系之间的进程间通信, 没有关系的进程间无法实现通信
-
命名管道
解决了匿名管道无法实现非血缘关系的进程之间的通信, 对于命名管道, 可以实现任意两个进程之间的通信.
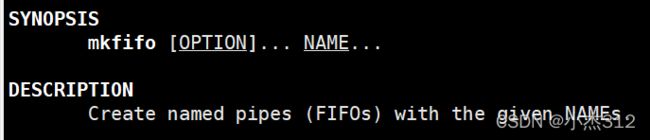
mkfifo 命令可以创建一根命名管道, 或者使用系统调用也可以创建命名管道

管道模型的优缺点以及应用场景总结:
场景: 数据从一个进程传输到另外一个进程
优点: 数据传输比较及时
缺点1:不适合频繁的交换数据, 只要交换数据就必须要打通内核态中的管道通道, 但是我们都知道信息的传输, 数据的传输还存在一种场景就是,消息太多了, 我们可以不用立刻处理, 可以将消息, 信息放在哪里, 后面慢慢看, 就像发邮件一样. --- 提出问题, 如果需要频繁沟通, 我们不一定可以实时处理, 可以借助邮件思维, 先通过一个容器存储着, 慢慢看, 慢慢交流, 慢慢的完成频繁的数据交互。
缺点2:管道有同步,阻塞的问题限制. eg : 阻塞读, 当 读取的字节数 > 管道缓冲区中的已有字节数, 读的进程就会阻塞等待, 写进程写入数据 阻塞造成了低效
-
ftok
ftok 仅仅只是一个简简单单的系统调用, 我却将其完全独立出来说明,是否小题大作了呀? NONONO, 因为后序的所有IPC 通信全部需要获取一个唯一key值, 获取这个key 值得最优方式就是通过一个file 的 inode 来获取这个全局唯一 key 值, 可以避免重复.

-
System V 消息队列
-
理解消息队列
消息队列: 生活化, 发邮件, 很日常呀, 别人发来的邮件都放在邮箱里面, 得空就可以对于邮件进行阅读和回寄邮件. 消息队列其实就蛮像一个邮箱的.
我们创建一个内核态的全局的邮箱 --- 消息队列.
通过系统调用,各个进程可以进入内核态, 像消息队列,邮箱中 send 邮件,和 recv 邮件. 这种工作模式就可以达到 频繁的数据交换
进程A : 我 send 一封邮件 (struct数据单元) 到 Message Queue 里面去
进程B : 我从 Message Queue 读取到一封邮件 (struct 数据单元) 然后按照约定回 进程A一封
注意:我特意的将每一封邮件说成是一个数据单元. 既然是一个单元, 就是存在大小和数据格式上面的限制的. --- 大小限制留疑, 其实答案在后文介绍的系统调用参数中

-
msgget

Return Value : 规则同上 failure return -1 sucess return msgid;
eg :
key : 至此开始, 几乎在每一个 IPC 通信, 下面都可以看见, 他就是一个共享容器的一个代言, 标识, 名称.
msgflag : 9位权限标志位: 我们通常使用 0x666 | IPC_CREAT | IPC_EXCL
插一个权限介绍: r : 读权限 w : 可写权限 X : 可执行权限. 所谓的9位权限标识位, 就是针对: 文件拥有者, 文件拥有组人员, 其他人员的访问权限的限制
来吧: 虽然其他后面的还没有学习, 咱可以先创建一个msgqueue出来玩一玩呀:
code :
#include
#include
#include
#include
#include
int main(int argc, char* argv[]) {
if (argc != 2) {
fprintf(stderr, "usage: %s \n", argv[0]);
return -1;
}
key_t key = ftok("./a.txt", 'k');
if (-1 == key) {
perror("ftok");
return -2;
}
printf("key: %d\n", key);
//此刻已经获取到唯一key值了
//创建一个msg queue
int msgid = msgget(key, 0666 | IPC_CREAT | IPC_EXCL);
if (-1 == msgid) {
perror("msgget");
return -3;
}
printf("msgid: %d\n", msgid);
return 0;
}
ans: 看吧 ipcs -q : 查看创建的 IPC 全局的 msg queue. ipcs -m 查看 ipc share memory

System V IPC 体系有一个统一的命令行工具:ipcmk,ipcs 和 ipcrm 用于创建、查看和删除 IPC 对象。
记忆大师 : ipcs : 就是简单的查看 ipcmk : ipc make 创建 ipcrm : ipc remove移除
-
msgsnd

功能: 像IPC queue消息队列发送一条消息
msgflg 设为 IPC_NOWAIT , 设置非阻塞 不论是 send 的时候msg queue满了, 还是 recv 的时候msg queue 是空的都不会阻塞住. 无阻塞调用
Return Val :
sucess : return 0
failure: return -1 && set errno
-
msgrcv

msgtyp : 指定接收的消息的优先级, 优先接收消息队列哪里的消息
If msgtyp is 0, then the first message in the queue is read. 读取消息队列第一条消息, 不论message 的 type, 只是接收第一条消息
如果msgtyp > 0 则会接收具有相同消息类型的第一条消息
如果msgtyp < 0 则会接收类型 <= msgtyp绝对值的第一条消息
Return Val:
success: return the number of bytes actually copied into the mtext array 成功从mtext正文中读取的字节数
failure : return -1 && set errno
-
msgctl

功能 : 功能取决于 cmd, 其实就是对于IPC 执行 cmd 操作
cmd : IPC_RMID : 删除消息队列.
消息队列模型的优缺点以及应用场景总结:
场景: 两个进程频繁的进行数据交换.
优点: 避免了管道的同步阻塞问题, 提高了效率. 相比匿名管道只能是血缘进程间通信, 消息队列支持毫不相干的两个进程间的通信
缺点1:数据块存在长度限制, 不适合大数据的传输
缺点2:通信不及时
缺点3: 存在用户空间和内核空间数据的拷贝. --- 留个思考, 共享内存是最快的通信机制, 向较于msg queue, 它连内核空间跟用户空间的数据拷贝代价都省去了
案例实操: 现在存在 A B 两个进程, 通过消息队列, 实现 A 向 B 发送消息, B 接收并且打印消息.
code msgA.c
#include
#include
#include
#include
#include
#include
#include
#define TEXT_SIZE 1024
typedef struct msgbuff {
long int type; //消息数据类型
char text[TEXT_SIZE];//正文大小
} msgbuff;
int main(int argc, char* argv[]) {
if (argc != 2) {
fprintf(stderr, "usage: %s \n", argv[0]);
return -1;
}
msgbuff buff;
//1获取key
key_t key = ftok(argv[1], 'c');//当前目录
if (key == -1) {
perror("ftok");
return -2;
}
//2.创建msg queue
int msgid = msgget(key, 0666 | IPC_CREAT | IPC_EXCL);
if (-1 == msgid) {
perror("msgget");
return -3;
}
//3.循环写入数据
while (1) {
printf("请输入消息类型type:\n");
scanf("%d", &buff.type);
printf("请输入消息正文text:\n");
scanf("%s", buff.text);
if (-1 == msgsnd(msgid, &buff, TEXT_SIZE, IPC_NOWAIT)) {
perror("msgsnd");
return -4;
}
}
return 0;
}
code msgB.c
#include
#include
#include
#include
#include
#include
#include
#include
#define TEXT_SIZE 1024
#define TYPE 2
typedef struct msgbuff {
long int type; //消息数据类型
char text[TEXT_SIZE];//正文大小
} msgbuff;
int main(int argc, char* argv[]) {
if (argc != 2) {
fprintf(stderr, "usage: %s \n", argv[0]);
return -1;
}
msgbuff buff;
buff.type = TYPE;
//1获取key
key_t key = ftok(argv[1], 'c');//当前目录
if (-1 == key) {
perror("ftok");
return -2;
}
//2.获取消息队列msgid
int msgid = msgget(key, 0666 | IPC_CREAT);
if (-1 == msgid) {
perror("msgget");
return -3;
}
//3.循环读取数据
while (1) {
memset(&buff.text, 0, TEXT_SIZE);
int read_size = msgrcv(msgid, &buff, TEXT_SIZE, TYPE, IPC_NOWAIT);
if (-1 == read_size && errno == ENOMSG) {
continue;//还没有消息到来
}
if (-1 == read_size) {
perror("msgrcv");
return -4;
}
buff.text[read_size] = 0;//设置结束字符,习惯
if (strcmp("quit", buff.text) == 0) {
break;//通信结束
}
printf("recv: %s\n", buff.text);
}
//4.结束通讯删除msg queue
if (-1 == msgctl(msgid, IPC_RMID, NULL)) {
perror("msgctl");
return -5;
}
return 0;
}
ans:

编程模型: 模子.
- 创建key = ftok() 唯一标识
- 创建消息队列, msgid = msgget()
- 收发数据 msgrcv() + msgsnd()
- 结束通信, 删除消息队列 msgctl(IPC_RMID) or ipcrm -q
-
System V 共享内存
-
理解共享内存
正常情况下, 进程地址空间中的虚拟内存,映射到的物理内存都一定是互不相同的, 是不会存在重合的, 因为进程的独立性。 --- 但是为了通信, 可以固定一块物理内存, 将其挂载到进程A, 进程B上去, 这样, A 和 B 对于这块物理内存都是可见的, 于是在这块物理内存为介质, 多进程可以实现通信
最快速,最高效的IPC 通信.

-
shmget

功能:申请共享内存
shmflag : 9位权限标志位: 我们通常使用 0x666 | IPC_CREAT | IPC_EXCL
插一个权限介绍: r : 读权限 w : 可写权限 X : 可执行权限. 所谓的9位权限标识位, 就是针对: 文件拥有者, 文件拥有组人员, 其他人员的访问权限的限制
-
shmat
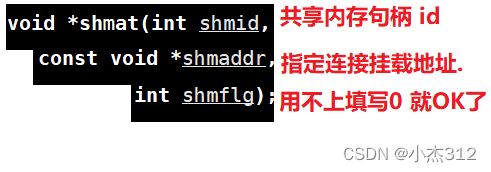
功能:将物理内存连接,挂载,关联到进程地址空间中去
shmaddr :NULL 自动选取连接地址, 不为NULL, 人为指定, 希望挂载到的地址
我们还是填写 NULL
Return Val : 返回一个ptr, 指向共享物理内存的首地址. 虚拟空间中的连接首地址
-
shmdt

功能:解除挂载, 将共享内存和当前进程进行脱离.
shmaddr : 之前 shmat 的 return val, 共享内存映射在虚拟地址空间上的首地址.
Return Val: success return 0 failure return -1
-
shmctl

cmd: IPC_RMID 删除共享内存
共享内存模型的优缺点以及应用场景总结:
场景: 多个进程都需要加载一份配置文件的场景下, 由一个进程负责将配置文件加载到共享内存中, 需要这份配置文件的进程直接挂载这个共享内存使用即可
优点: 高效, 快速, 是最快的IPC通信机制了.
缺点: 需要借助信号量来进行进程间的同步工作, 自身不支持进程间同步
案例实操: 现在存在 A B 两个进程, 共享一块内存 m, A 往里面写入数据, B 从中读取 A 写入的数据
code A:
#include
#include
#include
#include
#include
#include
#define SHM_SIZE 4096
int main(int argc, char* argv[]) {
if (argc != 2) {
fprintf(stderr, "usage: %s ", argv[0]);
return -1;
}
//1创建key
key_t key = ftok(argv[1], 'a');
if (-1 == key) {
perror("ftok");
return -2;
}
//2.创建共享内存
int shmid = shmget(key, SHM_SIZE, 0666 | IPC_CREAT | IPC_EXCL);
if (-1 == shmid) {
perror("shmget");
return -3;
}
//3. 挂载共享内存
char* p = (char*)shmat(shmid, NULL, 0);
if ((char*)-1 == p) {
perror("shmat");
return -4;
}
//4.通信阶段, 往共享内存中写入数据
*p = 0;//先设置为NULL
printf("请输入共享数据:\n");
scanf("%s", p);
return 0;
}
code B
#include
#include
#include
#include
#include
#include
#include
#define SHM_SIZE 4096
int main(int argc, char* argv[]) {
if (argc != 2) {
fprintf(stderr, "usage: %s ", argv[0]);
return -1;
}
//1创建key
key_t key = ftok(argv[1], 'a');
if (-1 == key) {
perror("ftok");
return -2;
}
//2.获取共享内存
int shmid = shmget(key, SHM_SIZE, 0666 | IPC_CREAT);
if (-1 == shmid) {
perror("shmget");
return -3;
}
//3. 挂载共享内存
char* p = (char*)shmat(shmid, NULL, 0);
if ((char*)-1 == p) {
perror("shmat");
return -4;
}
//4.通信阶段,从共享内存中读取数据
while (1) {
if (*p) break; //等A传输数据
}
printf("%s\n", p);
//5.卸载共享内存
if (-1 == shmdt(p)) {
perror("shmdt");
return -5;
}
return 0;
}
编程模型: 模子.
- 创建key = ftok() 唯一标识
- 创建共享内存 int shmid = shmget()
- 挂载共享内存 p = shmat()
- 利用共享内存完成通信
- 卸载共享内存 shmdt()
- 删除共享内存 shmctl()
-
POSIX信号量
-
理解信号量
信号量是一种资源, 是临界资源, 是操作系统封装好的, 具有保护作用的临界资源, 不需要我们手动上锁, 因为对于信号量资源的请求和归还, 操作系统自身就已经帮我们保护好了的.
目的: 是为了在多线程同步访问临界资源的时候不会产生资源竞争造成的冲突问题. 用于线程间同步访问临界资源. 这个临界资源就是sem 信号量
-
sem_init

功能:初始化信号量
Return Val : 还是老规矩, success return 0 failure return -1
-
sem_destroy

功能: 销毁信号量
-
sem_wait

功能: 申请, 消费一个sem资源.
Return Val : success return 0 and failure return -1
-
sem_post

功能: 归还, 增加一个sem 资源
Return Val : success return 0 and failure return -1
信号量的优缺点以及应用场景总结:
场景: 多线程同步访问资源, 或者是多进程同步访问资源
优点: 比文件锁有优势,效率高一些,起码不用打开文件关闭文件这些耗时间的工作, 相较加锁操作更简单方便
缺点: 不够安全,PV操作使用不当容易产生死锁,遇到复杂同步互斥问题实现复杂, 针对代码块需要加锁保护的问题无能为力, 因为代码块毕竟不是能用数字衡量的呀.
案例实操: sem经典应用, 基于信号量实现一个生产者消费者模式, 对于这个案例, 以及 线程间同步更为细节的知识点, 我以前是写过一篇博文的, 感兴趣的可以去阅读, 蟹蟹.
生产者消费者模式保姆级教程 (阻塞队列解除耦合性) 一文帮你从C语言版本到C++ 版本, 从理论到实现 (一文足以)_小杰312的博客-CSDN博客生产者消费者模式保姆级教程 (阻塞队列解除耦合性) 一文帮你从C语言版本到C++ 版本, 从理论到实现 (一文足以)https://blog.csdn.net/weixin_53695360/article/details/123082273?spm=1001.2014.3001.5502
-
网络套接字通信
对于网络套接字通信这篇, 是网络编程方面的了, 它涉及知识面广泛, 不是一两句扯得清楚的, 小杰在之前有对齐入门学习到精通的路线图, 小杰会附上入门链接一份, 如果您喜欢小杰的总结, 可以收藏起来一起学习进步呀,冲冲冲, 趁着你室友一把王者的时间偷偷入门网络套接字通信, 卷四他们
TCP网络编程模型从入门到实战基础篇,单服务器单个用户非并发版本_小杰312的博客-CSDN博客文章目录前言一、网络编程实践的必备基础知识二、系统调用方法刨析1.socket2.bind3.listen4.accept5.connect三、实现一个简单的功能, 服务器将单客户端传来的小写字母转成大写总结以及留下疑问讨论解决办法前言本文仅仅针对对于学校学习网络编程之后不知道如何运用的情况, 本章学习可以收获的是最为基本的 TCP 模型的掌握编程模型图:一、网络编程实践的必备基础知识ip地址(32位地址) : ...https://blog.csdn.net/weixin_53695360/article/details/122754482?spm=1001.2014.3001.5502
信号
-
何为信号?
-
常见的信号学习
-
如何注册自己的信号处理函数
全文终,综述留续
送君入门, 各位大哥们, 可以看到此处,实属不易呀, 或许是被小杰的文章引的入迷了, 哈哈哈,开了玩笑.
说正事, 摊在寝室床头与小学生抢人头, 说实话咱真不如去看看博文, 出去走走,锻炼锻炼, 学习学习, 计算机的学习之途本就是一头扎进汪洋大海.
没有绝对的强者, 没有绝对的天赋, 只有针对一个方向的强者, 所谓天赋偷偷告诉你,是高手们的凡尔赛, 他们肯定也是经过了无数日夜的煎熬, 刷题, 从初学, 到读书, 到总结出属于自己的知识点. 不容易呀.
看到此处,小杰真心佩服,说明您也有炙热的心, 无限的渴望提升的信念. 如果觉得小杰写的还蛮不错的, 可以伸手给小杰一个小心心, 小杰万分感谢, 对于哪个信号章节, 请原谅小杰, 创作不易, 如果硬要写完, 发文就得再拖一周, 小杰希望自己可以写出有质量, 对自己有提升的总结 --- 祝学习的学业有成, 工作的前辈们升职加薪