Python 进程、线程、协程傻傻分不清楚?详细总结(附代码)

目录
- 1 什么是并发编程?
- 2 进程与多进程
- 3 线程与多线程
- 4 协程与多协程
- 5 总结
1 什么是并发编程?
并发编程是实现多任务协同处理,改善系统性能的方式。Python中实现并发编程主要依靠
- 进程(Process):进程是计算机中的程序关于某数据集合的一次运行实例,是操作系统进行资源分配的最小单位
- 线程(Thread):线程被包含在进程之中,是操作系统进行程序调度执行的最小单位
- 协程(Coroutine):协程是用户态执行的轻量级编程模型,由单一线程内部发出控制信号进行调度
直接上一张图看看三者概念间的关系。
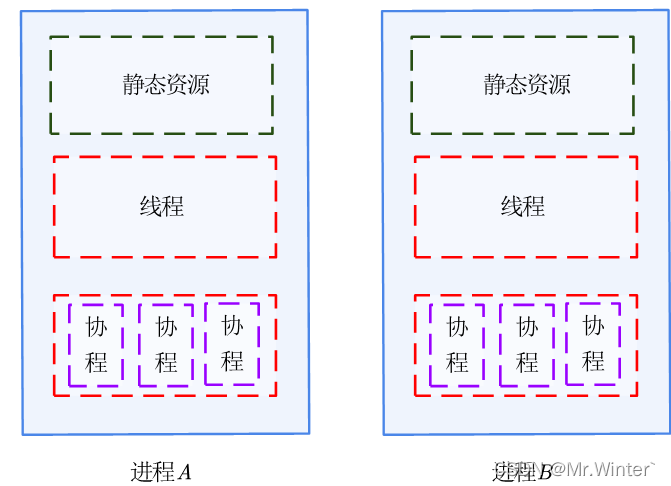
这张图说明了什么?首先,一条线程是进程中一个单一的顺序控制流,一个进程可以并发多个线程执行不同任务。协程由单一线程内部发出控制信号进行调度,而非受到操作系统管理,因此协程没有切换开销和同步锁机制,具有极高的执行效率。
进程、线程、协程间的特性决定了它们的应用场景不同:
协程常用于IO密集型工作,例如网络资源请求等;而进程、线程常用于计算密集型工作,例如科学计算、人工神经网络等。
接下来对每种并发编程方法进行详细阐述。
2 进程与多进程
Python多进程依赖于标准库mutiprocessing,进程类Process的常用方法如下
| 序号 | 方法 | 含义 |
|---|---|---|
| 1 | start() | 创建一个Process子进程实例并执行该实例的run()方法 |
| 2 | run() | 子进程需要执行的目标任务 |
| 3 | join() | 主进程阻塞等待子进程直到子进程结束才继续执行,可以设置等待超时时间timeout |
| 4 | terminate() | 终止子进程 |
| 5 | is_alive() | 判断子进程是否终止 |
| 6 | daemon | 设置子进程是否随主进程退出而退出 |
创建多进程任务的实例如下
import os, time
import multiprocessing
class myProcess(multiprocessing.Process):
def __init__(self, *args, **kwargs) -> None:
super().__init__()
self.name = kwargs['name']
def run(self):
print("process name:", self.name)
for i in range(10):
print(multiprocessing.current_process(), "process pid:",
os.getpid(), "正在执行...")
time.sleep(0.2)
if __name__ == "__main__":
task = myProcess(name="testProcess")
task.start()
task.join() # 该语句会阻塞主进程直至子进程结束
print("----------------")
注意:Windows系统在子进程结束后会立即自动清除子进程实例;而Linux系统子进程实例仅当主进程结束后才被回收,在子进程结束但主进程仍在运行的时间内处于僵尸进程状态,会造成性能损失甚至死锁。对子进程实例的手动回收可以通过
p.terminate()
p.join()
完成,此外,start()函数也有清除僵尸进程的功能。在使用多进程处理任务时并非进程越多越好,因为进程切换会造成性能开销。
3 线程与多线程
Python多线程依赖于标准库threading,线程类Thread的常用方法如下表:
| 序号 | 方法 | 含义 |
|---|---|---|
| 1 | start() | 创建一个Thread子线程实例并执行该实例的run()方法 |
| 2 | run() | 子线程需要执行的目标任务 |
| 3 | join() | 主进程阻塞等待子线程直到子线程结束才继续执行,可以设置等待超时时间timeout |
| 4 | is_alive() | 判断子线程是否终止 |
| 5 | daemon | 设置子线程是否随主进程退出而退出 |
关于线程与进程的关系,还有一个很生动的例子
把一条公路看作一道进程,那么公路上的各个车道就是进程中的各个线程。这些线程(车道)共享了进程(道路)的公共资源;这些线程(车道)之间可以并发执行(各个车道相对独立),也可以互相同步(交通信号灯)。
多线程可以通过线程锁来进行数据同步,可用于保护共享资源同时被多个线程读写引起冲突导致错误。给出一个实例:
rsrc = 10
lock = threading.Lock()
def task1(name):
global rsrc, lock
for i in range(5):
with lock:
rsrc += 1
print("task1:", rsrc)
return name + "has been done!"
def task2(name):
global rsrc, lock
for i in range(5):
lock.acquire()
rsrc -= 1
print("task2:", rsrc)
lock.release()
return name + "has been done!"
结果如下
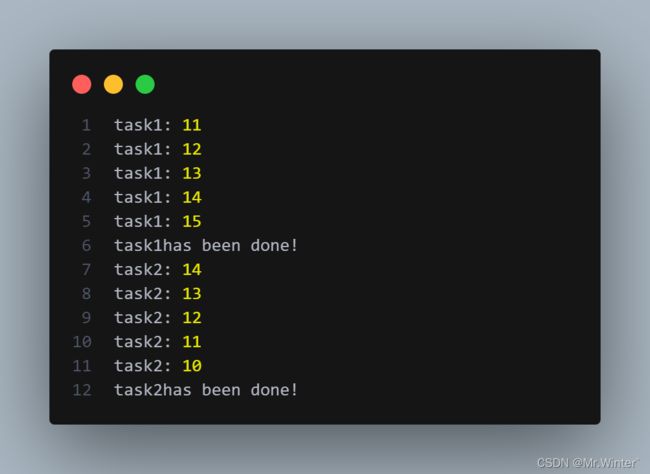
在多线程并发过程中,若没有控制好线程间的执行逻辑,将可能产生死锁现象,可以使用with关键词在线程访问临界区结束后自动释放锁,也可使用release()方法手动释放句柄。
4 协程与多协程
协程适用于I/O密集型而非计算密集型场景。在协程发起I/O请求后返回结果前往往有大量闲置时间——该时间可能用于网络数据传输、获取协议头、服务器查询数据库等,而I/O请求本身并不耗时,因此协程可以发送一个请求后让渡给系统干别的事,这就是协程提高性能的原因。
协程编程的框架如下:
- 创建协程对象并将其封装成任务实例;
- 创建事件循环实例并监听任务队列;
- 获取协程结果(可在事件循环结束后获取,或提前添加回调函数)。
一个嵌套协程的示例如下:
import asyncio, time
# 内层协程
async def do_some_work(x):
print('Waiting: ', x)
await asyncio.sleep(x)
return 'Done after {}s'.format(x)
def OnCallBack(res):
print(res.result())
# 外层协程main
async def main():
# 创建三个协程对象并封装成任务
task1 = asyncio.ensure_future(do_some_work(1))
task2 = asyncio.ensure_future(do_some_work(8))
task3 = asyncio.ensure_future(do_some_work(4))
# 添加回调
task1.add_done_callback(OnCallBack)
task2.add_done_callback(OnCallBack)
task3.add_done_callback(OnCallBack)
# 内层任务列表
tasks = [task1, task2, task3]
# 将列表转为可等待对象
dones, pendings = await asyncio.wait(tasks)
# 外层协程func
async def func():
for i in range(5):
print("func:", i)
# 外层任务列表
tasks = [asyncio.ensure_future(func()), asyncio.ensure_future(main())]
# 创建事件循环
loop = asyncio.get_event_loop()
start = time.time()
# 监听异步任务
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print("总耗时:", end - start)
5 总结
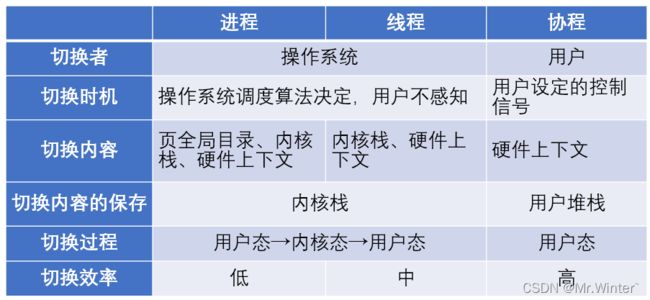
看了这么多概念可能有点晕了,下面这张表总结了本文的内容。总得来说,进程、线程、协程各有各的应用场景,不能说多进程、多线程、多协程就一定好,而是要根据具体的使用情况来确定。
更多精彩专栏:
- 《机器人原理与技术》
- 《ROS从入门到精通》
- 《计算机视觉教程》
- 《机器学习》
- 《数值优化方法》
- …
欢迎加入社区和更多志同道合的朋友交流:AI 技术社