深度学习之损失函数
损失函数(Loss Function) - 知乎
L1和L2损失函数_gy_Rick的博客-CSDN博客_l1和l2损失函数
1、什么是损失函数?
一言以蔽之,损失函数(loss function)就是用来度量模型的预测值f(x)与真实值Y的差异程度的运算函数,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。
-损失函数:用于衡量'单个样本点'预测值与实际值的偏离程度。
-风险函数:用于衡量'样本点平均意义'下的好坏,就是说要除以batch_size。
-风险函数分为经验风险和结构风险
-经验风险:指预测结果和实际结果的差别。
-结构风险:指经验风险 + 正则项。
-风险函数是训练过程中的模型,对已知训练数据的计算。可以理解为是train过程的loss。
-泛化函数:指模型对未知数据的预测能力。
-泛化函数是训练好的模型,对未知数据的计算。可以理解为是test过程的loss。模型的结构风险函数包括了经验风险项和正则项,通常可以表示成如下式子:
其中,前面的均值函数表示的是经验风险函数,L代表的是损失函数,后面的Φ是正则化项(regularizer)或者叫惩罚项(penalty term),它可以是L1,也可以是L2,或者其他的正则函数。整个式子表示的意思是找到使目标函数最小时的θ值。
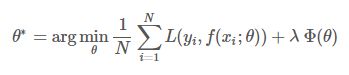
Loss Function、Cost Function 和 Objective Function 的区别和联系
- 损失函数 Loss Function 通常是针对单个训练样本而言,给定一个样本
,其机器学习模型的输出
, 而样本
, 损失函数输出一个实值损失
,
损失函数旨在表示出logit和label的差异程度,不同的损失函数有不同的表示意义,也就是在最小化损失函数过程中,logit逼近label的方式不同,得到的结果可能也不同
- 代价函数 Cost Function 通常是针对整个训练集(或者在使用 mini-batch gradient descent 时一个 mini-batch)的总损失
- 目标函数 Objective Function 是一个更通用的术语,表示任意希望被优化的函数,用于机器学习领域和非机器学习领域(比如运筹优化)
一句话总结三者的关系就是:A loss function is a part of a cost function which is a type of an objective function.

2、为什么使用损失函数?
损失函数的作用,就是计算神经网络每次迭代的前向计算结果与真实值的差距,从而指导下一步的训练向正确的方向进行。
如何使用损失函数呢?具体步骤:
- 用随机值初始化前向计算公式的参数;
- 代入样本,计算输出的预测值;
- 用损失函数计算预测值和标签值(真实值)的误差;
- 根据损失函数的导数,沿梯度最小方向将误差回传,修正前向计算公式中的各个权重值;
- goto 2, 直到损失函数值达到一个满意的值就停止迭代。
损失函数使用主要是在模型的训练阶段,每个批次的训练数据送入模型后,通过前向传播输出预测值,然后损失函数会计算出预测值和真实值之间的差异值,也就是损失值。得到损失值之后,模型通过反向传播去更新各个参数,来降低真实值与预测值之间的损失,使得模型生成的预测值往真实值方向靠拢,从而达到学习的目的。
3、常用损失函数
符号规则: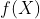 是预测值,模型输出,
是预测值,模型输出, 是样本标签值,
是样本标签值, 是损失函数值。
是损失函数值。
基于距离度量的损失函数通常将输入数据映射到基于距离度量的特征空间上,如欧氏空间、汉明空间等,将映射后的样本看作空间上的点,采用合适的损失函数度量特征空间上样本真实值和模型预测值之间的距离。特征空间上两个点的距离越小,模型的预测性能越好。
包括均方误差损失函数(MSE)、L2损失函数、L1损失函数、Smooth L1损失函数、huber损失函数
基于概率分布度量的损失函数是将样本间的相似性转化为随机事件出现的可能性,即通过度量样本的真实分布与它估计的分布之间的距离,判断两者的相似度,一般用于涉及概率分布或预测类别出现的概率的应用问题中,在分类问题中尤为常用。
包括KL散度函数(相对熵)、交叉熵损失、softmax损失函数、Focal loss
l2范数求导_L1和L2 详解(范数、损失函数、正则化)
3.1 L1损失函数
L1损失函数也叫做最⼩化绝对误差(Least Abosulote Error(LAE))。LAE就是最⼩化真实值![]()
和预测值 之间差值的绝对值的和。
之间差值的绝对值的和。

3.2 L2损失函数
L2范数损失函数,也被称为最小平方误差((Least Square Error(LSE))。总的来说,它是把目标值(![]() )与估计值()的差值的平方和(S)最小化:
)与估计值()的差值的平方和(S)最小化:
3.3 均方差损失函数
均方误差Mean Square Error(MSE) 是模型预测值与真实样本值之间差值平方和的平均值,其公式如下:
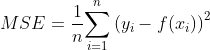
其中,![]() 和分别表示第个样本的真实值及其对应的预测值,
和分别表示第个样本的真实值及其对应的预测值, 为样本的个数。
为样本的个数。
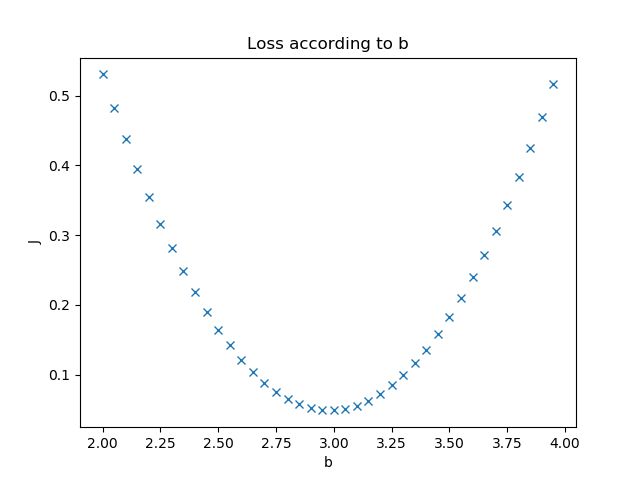
以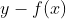 为横轴,MSE的值为纵轴,得到函数的图形如下:
为横轴,MSE的值为纵轴,得到函数的图形如下:

当和也就是真实值和预测值的差值大于1时,会放大误差;而当差值小于1时,则会缩小误差,这是平方运算决定的。MSE对于较大的误差(>1)给予较大的惩罚,较小的误差(<1)给予较小的惩罚。也就是说,对离群点比较敏感,受其影响较大。

可见,使用 MSE 损失函数,受离群点的影响较大,虽然样本中只有 5 个离群点,但是拟合的直线还是比较偏向于离群点。
MSE 主要用于回归
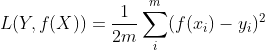 (多样本)
(多样本)
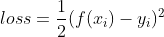 (单样本)
(单样本)
import numpy as np
# 自定义实现
def MSELoss(x:list,y:list):
"""
x:list,代表模型预测的一组数据
y:list,代表真实样本对应的一组数据
"""
assert len(x)==len(y)
x=np.array(x)
y=np.array(y)
loss=np.sum(np.square(x - y)) / len(x)
return loss
#计算过程举例
x=[1,2]
y=[0,1]
loss=((1-0)**2 + (2-1)**2)÷2=(1+1)÷2=1
# Tensorflow2.0版
y_true=tf.convert_to_tensor(y)
y_pred=tf.convert_to_tensor(x)
mse_loss = tf.keras.losses.MSE(y_true, y_pred) # y_true, y_pred都是张量格式
# pytorch版本
y_true=torch.tensor(y)
y_pred=torch.tensor(x)
mse_fc = torch.nn.MSELoss(y_true, y_pred)
mse_loss = mse_fc(x,y)3.4 平均绝对误差
平均绝对误差(Mean Absolute Error,MAE) 是指模型预测值
和真实值之间距离绝对值的平均值,其公式如下:
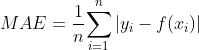
MAE曲线连续,但是![]() 在处不可导。而且 MAE 大部分情况下梯度都是相等的,这意味着即使对于小的损失值,其梯度也是大的。这不利于函数的收敛和模型的学习。但是,无论对于什么样的输入值,都有着稳定的梯度,不会导致梯度爆炸问题,具有较为稳健性的解。
在处不可导。而且 MAE 大部分情况下梯度都是相等的,这意味着即使对于小的损失值,其梯度也是大的。这不利于函数的收敛和模型的学习。但是,无论对于什么样的输入值,都有着稳定的梯度,不会导致梯度爆炸问题,具有较为稳健性的解。
针对上面带有离群点的数据,MAE的效果要好于MSE。

显然,使用 MAE 损失函数,受离群点的影响较小,拟合直线能够较好地表征正常数据的分布情况。
3.5 Smooth 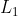 Loss
Loss
在Faster R-CNN以及SSD中对边框的回归使用的损失函数都是Smooth L1作为损失函数,
![]()
其中,![]() 为真实值和预测值的差值。
为真实值和预测值的差值。
Smooth L1 能从两个方面限制梯度:
当预测框与 ground truth 差别过大时,梯度值不至于过大;
当预测框与 ground truth 差别很小时,梯度值足够小。

smooth L1损失函数曲线
L2 Loss、L1 Loss、smooth L1 Loss 对比分析
其中 为预测框与groud truth之间的差异:
为预测框与groud truth之间的差异:
上面损失函数对的导数为:
上面导数可以看出:
- 根据公式-4,当增大时,L2的损失也增大。 这就导致在训练初期,预测值与groud truth差异过于大时,损失函数对预测值的梯度十分大,训练不稳定。
- 根据公式-5,L1对的导数为常数,在训练的后期,预测值与ground truth差异很小时,L1的导数的绝对值仍然为1,而learning rate如果不变,损失函数将在稳定值附近波动,难以继续收敛以达到更高精度。
- 根据公式-6,在较小时,Smooth L1对的梯度也会变小。 而当较大时,Smooth L1对的梯度的上限为1,也不会太大以至于破坏网络参数。Smooth L1完美的避开了L1和L2作为损失函数的缺陷。

从上面可以看出,该函数实际上就是一个分段函数,在[-1,1]之间实际上就是L2损失,这样解决了L1的不光滑问题,在[-1,1]区间外,实际上就是L1损失,这样就解决了离群点梯度爆炸的问题
因此,对于大多数CNN网络,我们一般是使用L2-loss而不是L1-loss,因为L2-loss的收敛速度要比L1-loss要快得多。
对于边框预测回归问题,通常也可以选择平方损失函数(L2损失),但L2范数的缺点是当存在离群点(outliers)的时候,这些点会占loss的主要组成部分。比如说真实值为1,预测10次,有一次预测值为1000,其余次的预测值为1左右,显然loss值主要由1000决定。所以FastRCNN采用稍微缓和一点绝对损失函数(smooth L1损失),它是随着误差线性增长,而不是平方增长。
Smooth L1 和 L1 Loss 函数的区别在于,L1 Loss 在0点处导数不唯一,可能影响收敛。Smooth L1的解决办法是在 0 点附近使用平方函数使得它更加平滑。
Smooth L1的优点
相比于L1损失函数,可以收敛得更快。
相比于L2损失函数,对离群点、异常值不敏感,梯度变化相对更小,训练时不容易跑飞。
3.5 huber损失函数
MSE 损失收敛快但容易受 outlier 影响,MAE 对 outlier 更加健壮但是收敛慢,Huber Loss 则是一种将 MSE 与 MAE 结合起来,取两者优点的损失函数,也被称作 Smooth Mean Absolute Error Loss 。其原理很简单,就是在误差接近 0 时使用 MSE,误差较大时使用 MAE,huber损失是平方损失和绝对损失的综合,它克服了平方损失和绝对损失的缺点,不仅使损失函数具有连续的导数,而且利用MSE梯度随误差减小的特性,可取得更精确的最小值。尽管huber损失对异常点具有更好的鲁棒性,但是,它不仅引入了额外的参数,而且选择合适的参数比较困难,这也增加了训练和调试的工作量。


上式中 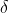 是 Huber Loss 的一个超参数, 的值是 MSE 和 MAE 两个损失连接的位置。上式等号右边第一项是 MSE 的部分,第二项是 MAE 部分,在 MAE 的部分公式为
是 Huber Loss 的一个超参数, 的值是 MSE 和 MAE 两个损失连接的位置。上式等号右边第一项是 MSE 的部分,第二项是 MAE 部分,在 MAE 的部分公式为 是为了保证误差
是为了保证误差![]() 时 MAE 和 MSE 的取值一致,进而保证 Huber Loss 损失连续可导。
时 MAE 和 MSE 的取值一致,进而保证 Huber Loss 损失连续可导。
下图是 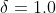 时的 Huber Loss,可以看到在
时的 Huber Loss,可以看到在![[- \delta, \delta]](http://img.e-com-net.com/image/info8/47e656688ed4452d879952f36137dc2a.gif) 的区间内实际上就是 MSE 损失,在
的区间内实际上就是 MSE 损失,在![]() 和
和 ![]() 区间内为 MAE损失。
区间内为 MAE损失。

这里超参数delta的选择非常重要,因为这决定了你对与异常点的定义。当残差大于delta,应当采用L1(对较大的异常值不那么敏感)来最小化,而残差小于超参数,则用L2来最小化。
为何要使用Huber损失?
使用MAE训练神经网络最大的一个问题就是不变的大梯度,这可能导致在使用梯度下降快要结束时,错过了最小点。而对于MSE,梯度会随着损失的减小而减小,使结果更加精确。
在这种情况下,Huber损失就非常有用。它会由于梯度的减小而落在最小值附近。比起MSE,它对异常点更加鲁棒。因此,Huber损失结合了MSE和MAE的优点。但是,Huber损失的问题是我们可能需要不断调整超参数delta。
3.6 Gold Standard Loss,又称0-1误差
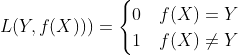
3.7 绝对值损失函数
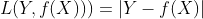
3.8 Hinge Loss,铰链/折页损失函数或最大边界损失函数
适用于 maximum-margin 的分类,支持向量机 Support Vector Machine (SVM) 模型的损失函数本质上就是 Hinge Loss + L2 正则化。合页损失的公式如下
下图是y 为正类, 即sgn(y)=1 时,不同输出的合页损失示意图
主要用于SVM(支持向量机)中
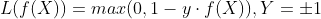
在线性支持向量机中,最优化问题可以等价于下列式子:

下面来对式子做个变形,令:
于是,原式就变成了:

如若取λ=1/(2C),式子就可以表示成:

可以看出,该式子与下式非常相似:
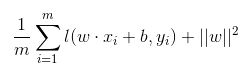
前半部分中的 l 就是hinge损失函数,而后面相当于L2正则项。
Hinge 损失函数的标准形式

可以看出,当|y|>=1时,L(y)=0。
3.9 Log Loss,对数损失函数,又叫交叉熵损失函数(cross entropy error)
交叉熵函数,主要用于神经网络的分类
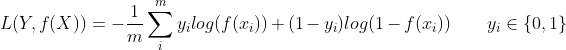
3.10 Exponential Loss,指数损失函数
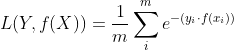
学过Adaboost算法的人都知道,它是前向分步加法算法的特例,是一个加和模型,损失函数就是指数函数。在Adaboost中,经过m此迭代之后,可以得到fm(x):
![]()
Adaboost每次迭代时的目的是为了找到最小化下列式子时的参数α 和G:
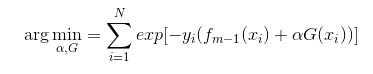
而指数损失函数(exp-loss)的标准形式如下

可以看出,Adaboost的目标式子就是指数损失,在给定n个样本的情况下,Adaboost的损失函数为:

关于Adaboost的推导,可以参考Wikipedia:AdaBoost或者《统计学习方法》P145.
4、MSE - Mean Square Error,均方差损失函数
该函数就是最直观的一个损失函数了,计算预测值和真实值之间的欧式距离。预测值和真实值越接近,两者的均方差就越小。
在回归问题中,均方误差损失函数用于度量样本点到回归曲线的距离,通过最小化平方损失使样本点可以更好地拟合回归曲线。均方误差损失函数(MSE)的值越小,表示预测模型描述的样本数据具有越好的精确度
均方差函数常用于线性回归(linear regression),即函数拟合(function fitting)
要想得到预测值a与真实值y的差距,最朴素的想法就是用 。
。
对于单个样本来说,这样做没问题,但是多个样本累计时, 有可能有正有负,误差求和时就会导致相互抵消,从而失去价值。所以有了绝对值差的想法,即
有可能有正有负,误差求和时就会导致相互抵消,从而失去价值。所以有了绝对值差的想法,即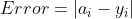 。这看上去很简单,并且也很理想,那为什么还要引入均方差损失函数呢?两种损失函数的比较如表3-1所示。
。这看上去很简单,并且也很理想,那为什么还要引入均方差损失函数呢?两种损失函数的比较如表3-1所示。
表4-1 绝对值损失函数与均方差损失函数的比较

可以看到5比3已经大了很多,8比4大了一倍,而8比5也放大了某个样本的局部损失对全局带来的影响,用术语说,就是“对某些偏离大的样本比较敏感”,从而引起监督训练过程的足够重视,以便回传误差。
图解参见(神经网络系列之三 -- 损失函数 - 五弦木头 - 博客园)


5、交叉熵损失函数
基于概率分布度量的损失函数是将样本间的相似性转化为随机事件出现的可能性,即通过度量样本的真实分布与它估计的分布之间的距离,判断两者的相似度,一般用于涉及概率分布或预测类别出现的概率的应用问题中,在分类问题中尤为常用。
如何衡量两个概率分布的相似度呢?
交叉熵是信息论中的一个概念,最初用于估算平均编码长度,引入机器学习后,用于评估当前训练得到的概率分布与真实分布的差异情况。为了使神经网络的每一层输出从线性组合转为非线性逼近,以提高模型的预测精度,在以交叉熵为损失函数的神经网络模型中一般选用tanh、sigmoid、softmax或ReLU作为激活函数。
交叉熵损失函数刻画了实际输出概率与期望输出概率之间的相似度,也就是交叉熵的值越小,两个概率分布就越接近,特别是在正负样本不均衡的分类问题中,常用交叉熵作为损失函数。目前,交叉熵损失函数是卷积神经网络中最常使用的分类损失函数,它可以有效避免梯度消散。在二分类情况下也叫做对数损失函数
交叉熵(Cross Entropy)是Shannon信息论中一个重要概念,主要用于度量两个概率分布间的差异性信息。在信息论中,交叉熵是表示两个概率分布 p,q 的差异,其中 p 表示真实分布,q 表示非真实分布,那么H(p,q)
就称为交叉熵:
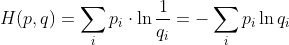
交叉熵可在神经网络中作为损失函数,p表示真实标记的分布,q 则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量 p 与 q的相似性。
交叉熵函数常用于逻辑回归(logistic regression),也就是分类(classification)。
5.1 交叉熵的由来
信息论中,信息量的表示方式:
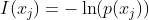
 :表示一个事件
:表示一个事件
![]() :表示 发生的概率
:表示 发生的概率
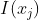 :信息量,越不可能发生时,它一旦发生后的信息量就越大
:信息量,越不可能发生时,它一旦发生后的信息量就越大
如表3-2所示有三种可能的情况发生。
表3-2 三种事件的概论和信息量
| 事件编号 | 事件 | 概率 p | 信息量 I |
|---|---|---|---|
 |
优秀 | p=0.7 | 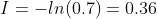 |
 |
及格 | p=0.2 | 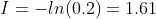 |
 |
不及格 | p=0.1 | 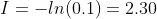 |
某同学不及格!好大的信息量!相比较来说,“优秀”事件的信息量反而小了很多。
熵
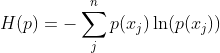
![\begin{aligned} H(p)&=-[p(x_1) \ln p(x_1) + p(x_2) \ln p(x_2) + p(x_3) \ln p(x_3)] \\ &=0.7 \times 0.36 + 0.2 \times 1.61 + 0.1 \times 2.30 \\ &=0.804 \end{aligned}](http://img.e-com-net.com/image/info8/21628de10c7a43feab8072ebe40330f6.gif)
相对熵(KL散度)
相对熵又称KL散度,如果我们对于同一个随机变量 x,有两个单独的概率分布 P(x) 和 Q(x),我们可以使用 KL 散度(Kullback-Leibler (KL) divergence)来衡量这两个分布的差异,这个相当于信息论范畴的均方差。
KL散度的计算公式:
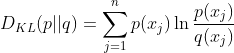
n为事件的所有可能性。D 的值越小,表示 q 分布和 p 分布越接近。
交叉熵
把上述公式变形:
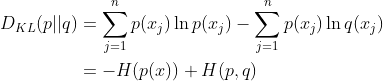
等式的前一部分恰巧就是p的熵,等式的后一部分,就是交叉熵:
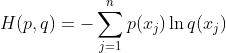
在机器学习中,我们需要评估label和predicts之间的差距,使用KL散度刚刚好,即![]() ,由于KL散度中的前一部分H(y)不变,故在优化过程中,只需要关注交叉熵就可以了。所以一般在机器学习中直接用交叉熵做损失函数来评估模型。
,由于KL散度中的前一部分H(y)不变,故在优化过程中,只需要关注交叉熵就可以了。所以一般在机器学习中直接用交叉熵做损失函数来评估模型。
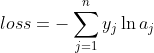
其中,n 并不是样本个数,而是分类个数。所以,对于批量样本的交叉熵计算公式是:
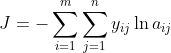
m 是样本数,n是分类数。
有一类特殊问题,就是事件只有两种情况发生的可能,比如“学会了”和“没学会”,称为0/1
分布或二分类。对于这类问题,由于n=2,所以交叉熵可以简化为:
![loss =-[y \ln a + (1-y) \ln (1-a)] ----------(9)](http://img.e-com-net.com/image/info8/3696fbcaa352452a9387c3e6e5f19625.gif)
二分类对于批量样本的交叉熵计算公式是:
![J= - \sum_{i=1}^m [y_i \ln a_i + (1-y_i) \ln (1-a_i)] --------({10})](http://img.e-com-net.com/image/info8/23380c2e56894d19830399cef4a954d7.gif)
def CrossEntropy_loss(y_true:list,y_pred:list):
"""
y_true,y_pred,分别是两个概率分布
比如:px=[0.1,0.2,0.8]
py=[0.3,0.3,0.4]
"""
assert len(y_true)==len(y_pred)
loss=0
for y,fx in zip(y_true,y_pred):
loss+=-y * np.log(fx)
return loss5.2 二分类问题交叉熵
把公式(10)分解开两种情况,当y=1时,即标签值是1,是个正例,加号后面的项为0:
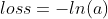
横坐标是预测输出,纵坐标是损失函数值。y=1意味着当前样本标签值是1,当预测输出越接近1时,损失函数值越小,训练结果越准确。当预测输出越接近0时,损失函数值越大,训练结果越糟糕。
当y=0时,即标签值是0,是个反例,加号前面的项为0:
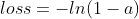
此时,损失函数值如图

假设学会了课程的标签值为1,没有学会的标签值为0。我们想建立一个预测器,对于一个特定的学员,根据出勤率、课堂表现、作业情况、学习能力等等来预测其学会课程的概率。
对于学员甲,预测其学会的概率为0.6,而实际上该学员通过了考试,真实值为1。所以,学员甲的交叉熵损失函数值是:
![]()
对于学员乙,预测其学会的概率为0.7,而实际上该学员也通过了考试。所以,学员乙的交叉熵损失函数值是:
![]()
由于0.7比0.6更接近1,是相对准确的值,所以 loss2要比 loss1小,反向传播的力度也会小。
5.3 多分类问题交叉熵
当标签值不是非0即1的情况时,就是多分类了。假设期末考试有三种情况:
- 优秀,标签值OneHot编码为[1,0,0]
- 及格,标签值OneHot编码为[0,1,0]
- 不及格,标签值OneHot编码为[0,0,1]
假设我们预测学员丙的成绩为优秀、及格、不及格的概率为:[0.2,0.5,0.3]
,而真实情况是该学员不及格,则得到的交叉熵是:
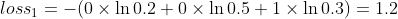
假设我们预测学员丁的成绩为优秀、及格、不及格的概率为:[0.2,0.2,0.6],而真实情况是该学员不及格,则得到的交叉熵是:
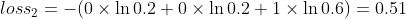
可以看到,0.51比1.2的损失值小很多,这说明预测值越接近真实标签值(0.6 vs 0.3),交叉熵损失函数值越小,反向传播的力度越小。
为什么不能使用均方差做为分类问题的损失函数?
-
回归问题通常用均方差损失函数,可以保证损失函数是个凸函数,即可以得到最优解。而分类问题如果用均方差的话,损失函数的表现不是凸函数,就很难得到最优解。而交叉熵函数可以保证区间内单调。
-
分类问题的最后一层网络,需要分类函数,Sigmoid或者Softmax,如果再接均方差函数的话,其求导结果复杂,运算量比较大。用交叉熵函数的话,可以得到比较简单的计算结果,一个简单的减法就可以得到反向误差。
注意:softmax使用的即为交叉熵损失函数,binary_cossentropy为二分类交叉熵损失,categorical_crossentropy为多分类交叉熵损失,当使用多分类交叉熵损失函数时,标签应该为多分类模式,即使用one-hot编码的向量。

1.交叉熵函数与最大似然函数的联系和区别?
区别:交叉熵函数使用来描述模型预测值和真实值的差距大小,越大代表越不相近;似然函数的本质就是衡量在某个参数下,整体的估计和真实的情况一样的概率,越大代表越相近。
联系:交叉熵函数可以由最大似然函数在伯努利分布的条件下推导出来,或者说最小化交叉熵函数的本质就是对数似然函数的最大化。
怎么推导的呢?我们具体来看一下。
设一个随机变量 X 满足伯努利分布,
![]()
则 X 的概率密度函数为:
![]()
因为我们只有一组采样数据 D ,我们可以统计得到X 和1-X 的值,但是p 的概率是未知的,接下来我们就用极大似然估计的方法来估计这个 p值。
对于采样数据 D ,其对数似然函数为:

可以看到上式和交叉熵函数的形式几乎相同,极大似然估计就是要求这个式子的最大值。而由于上面函数的值总是小于0,一般像神经网络等对于损失函数会用最小化的方法进行优化,所以一般会在前面加一个负号,得到交叉熵函数(或交叉熵损失函数):

这个式子揭示了交叉熵函数与极大似然估计的联系,最小化交叉熵函数的本质就是对数似然函数的最大化。
现在我们可以用求导得到极大值点的方法来求其极大似然估计,首先将对数似然函数对 p 进行求导,并令导数为0,得到

消去分母,得:

所以:

这就是伯努利分布下最大似然估计求出的概率p 。
在用sigmoid作为激活函数的时候,为什么要用交叉熵损失函数,而不用均方误差损失函数?
其实这个问题求个导,分析一下两个误差函数的参数更新过程就会发现原因了。
对于均方误差损失函数,常常定义为:

其中 y 是我们期望的输出, a为神经元的实际输出(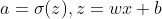 )。在训练神经网络的时候我们使用梯度下降的方法来更新w 和b ,因此需要计算代价函数对w 和 b的导数:
)。在训练神经网络的时候我们使用梯度下降的方法来更新w 和b ,因此需要计算代价函数对w 和 b的导数:

然后更新参数 w和 b :

因为sigmoid的性质,导致 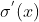 在 z 取大部分值时会很小(如下图标出来的两端,几乎接近于平坦),这样会使得
在 z 取大部分值时会很小(如下图标出来的两端,几乎接近于平坦),这样会使得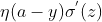 很小,导致参数 w和 b 更新非常慢。
很小,导致参数 w和 b 更新非常慢。
那么为什么交叉熵损失函数就会比较好了呢?同样的对于交叉熵损失函数,计算一下参数更新的梯度公式就会发现原因。交叉熵损失函数一般定义为:

其中 y 是我们期望的输出, a为神经元的实际输出( )。同样可以看看它的导数:

另外,

所以有:


所以参数更新公式为:

可以看到参数更新公式中没有 这一项,权重的更新受![]() 影响,受到误差的影响,所以当误差大的时候,权重更新快;当误差小的时候,权重更新慢。这是一个很好的性质。
影响,受到误差的影响,所以当误差大的时候,权重更新快;当误差小的时候,权重更新慢。这是一个很好的性质。
所以当使用sigmoid作为激活函数的时候,常用交叉熵损失函数而不用均方误差损失函数。
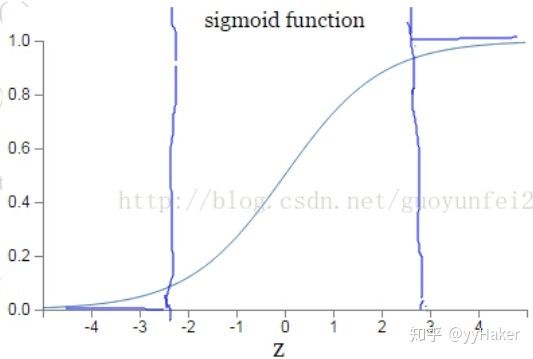
6、 Softmax Loss
Softmax Loss是深度学习中最常见的损失函数,完整的叫法是 Cross-entropy loss with softmax,其由三部分组成:Fully Connected Layer, Softmax Function 和 Cross-entropy Loss。使用softmax loss的pipline为:先使用一个encoder来学习数据的特征,再经过一个全连接层、softmax 函数,最后使用交叉熵计算损失。
6.1 softmax函数

其中 为第i个节点的输出值,K为输出节点的个数,即分类的类别个数。通过Softmax函数就可以将多分类的输出值转换为范围在[0, 1]和为1的概率分布。
它接受一个向量(或者一组变量)作为输入,每个变量指数化后除以所有指数化变量之和,(顺便说一下,sigmoid函数就是其输入数为2时的特例),有点类似于对输入进行归一化,事实上它就叫做归一化指数函数

为了更直观的理解先来看一个栗子,现有一个向量如下

将其作为softamax的输入,先对其进行指数化:

最后(归一化)就是:



得到的向量所有元素之和为1,每一个元素表示其概率。例如,在MNIST识别手写数字(0到9)的任务中, x 就是一个包含10个元素的向量, softmax(x)计算的结果的每个元素的值表示所要识别的数字为该数字的概率,取概率最高的作为结果
- 引入指数形式的优点

y = e^{x}函数图像
指数函数曲线呈现递增趋势,最重要的是斜率逐渐增大,也就是说在x轴上一个很小的变化,可以导致y轴上很大的变化。这种函数曲线能够将输出的数值拉开距离。假设拥有三个输出节点的输出值为![[z_1,z_2,z_3 ]](http://img.e-com-net.com/image/info8/c30b619445424dd6a35ac461398150f2.gif) 为[2, 3, 5]。首先尝试不使用指数函数
为[2, 3, 5]。首先尝试不使用指数函数  ,接下来使用指数函数的Softmax函数计算。
,接下来使用指数函数的Softmax函数计算。
import tensorflow as tf
print(tf.__version__) # 2.0.0
a = tf.constant([2, 3, 5], dtype = tf.float32)
b1 = a / tf.reduce_sum(a) # 不使用指数
print(b1) # tf.Tensor([0.2 0.3 0.5], shape=(3,), dtype=float32)
b2 = tf.nn.softmax(a) # 使用指数的Softmax
print(b2) # tf.Tensor([0.04201007 0.11419519 0.8437947 ], shape=(3,), dtype=float32)两种计算方式的输出结果分别是:
- tf.Tensor([0.2 0.3 0.5])
- tf.Tensor([0.04201007 0.11419519 0.8437947 ],)
结果还是挺明显的,经过使用指数形式的Softmax函数能够将差距大的数值距离拉的更大。
在深度学习中通常使用反向传播求解梯度进而使用梯度下降进行参数更新的过程,而指数函数在求导的时候比较方便。比如 。
。
6.2 交叉熵损失函数(CrossEntropyLoss)
网络的训练需要有损失函数,而softmax对应的损失函数就是交叉熵损失函数,它多作做分类任务中,计算公式如下:

上式中, a 是softmax的计算结果;y 是训练样本的标签,表示该样本正确的分类类型,如果以向量表示的话,其中只有一个元素为1,其余元素都为0(one-hot编码):

基于这个特性,所以损失大小只与网络判断正确分类的概率有关。举个栗子,一个样本的正确分类是第t类,即  ,
,  ,所以损失的公式可以简化为:
,所以损失的公式可以简化为:

来看看对数函数的图像:
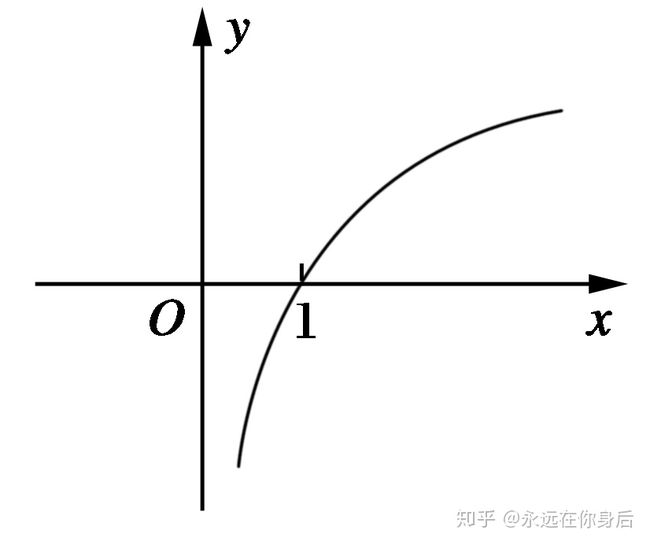
因为  是网络判断该样本属于第t类的概率,
是网络判断该样本属于第t类的概率, ,所以 的值越接近1,损失越小(趋近0),所以 的值越接近0,损失越大(趋近无穷大)
,所以 的值越接近1,损失越小(趋近0),所以 的值越接近0,损失越大(趋近无穷大)
6.3 梯度计算
参见Softmax与交叉熵损失的实现及求导 - 知乎
一文详解Softmax函数 - 知乎
现在可以构建比较复杂的神经网络模型,最重要的原因之一得益于反向传播算法。反向传播算法从输出端也就是损失函数开始向输入端基于链式法则计算梯度,然后通过计算得到的梯度,应用梯度下降算法迭代更新待优化参数。
首先是损失关于  的梯度(注意为网络计算最后输出,见下图)。因为损失是一个标量(数值),而 是一个向量,所以损失关于 的梯度也是一个向量
的梯度(注意为网络计算最后输出,见下图)。因为损失是一个标量(数值),而 是一个向量,所以损失关于 的梯度也是一个向量

因为公式损失的计算公式很简单,所以梯度推导也不复杂,下面直接写公式(![]() 为样本标签):
为样本标签):




最后得到:
(,one-hot 编码)
接下来是是softmax梯度的推导,先回顾下softmax函数的公式:

将其计算路径如下图所示:

观察上图中的计算路径,可以将  看作 的多元复合函数
看作 的多元复合函数

所以,该函数的导数偏导计算公式如下:
 (1)
(1)
为了方便理解,顺便贴一下求导路径:

式(1)分为两部分,分别来计算:
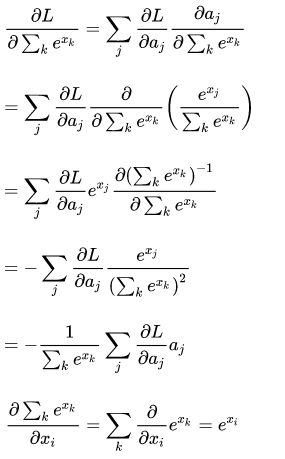
整理得到:
 (2)
(2)
然后是另一部分:
将(2),(3)的结果带入(1)中,得到:

在实现中,如果是将softmax实现为独立的层(Layer)的话,根据到这一步为止的讨论已经可以写出softmax的代码了:
class Softmax:
def forward(self, x):
v = np.exp(x - x.max(axis=-1, keepdims=True))
self.a = v / v.sum(axis=-1, keepdims=True)
return self.a
def backward(self, y):
return self.a * (eta - np.einsum('ij,ij->i', eta, self.a, optimize=True))上面代码中反向计算的实现使用了爱因斯坦求和约定,不太了解的可以参考这个链接
然而在一些网络的实现中,softmax层并不包含在其中,例如,有一个分类任务,所有的样本分别属于三类,假设对于某个样本,网络的最后一层的输出为:
![]()
显然,现在已经知道网络对该样本类别的推断了(softmax不过是进一步计算各个类别的概率而已)
所以,交叉熵损失的梯度计算中会包含softmax的这部分,所以把  的具体值代入到(4)中:
的具体值代入到(4)中:


因为  只有一个元素为1,其余都为0,所以
只有一个元素为1,其余都为0,所以 ,最终得到:
,最终得到:
最后,是交叉熵损失函数的实现代码:
class CrossEntropyLoss:
def __init__(self):
# 内置一个softmax作为分类器
self.classifier = Softmax()
def backward(self):
return self.classifier.a - self.y
def __call__(self, a, y):
'''
a: 批量的样本输出
y: 批量的样本真值
return: 该批样本的平均损失
'''
a = self.classifier.forward(a) # 得到各个类别的概率
self.y = y
loss = np.einsum('ij,ij->', y, np.log(a), optimize=True) / y.shape[0]
return -loss6.4 Softmax Loss函数求导
参见:
详解softmax函数以及相关求导过程 - 知乎
15分钟搞定Softmax Loss求导 - 知乎


当我们对分类的Loss进行改进的时候,我们要通过梯度下降,每次优化一个step大小的梯度,这个时候我们就要求Loss对每个权重矩阵的偏导,然后应用链式法则。那么这个过程的第一步,就是对softmax求导传回去。
下面一个例子:
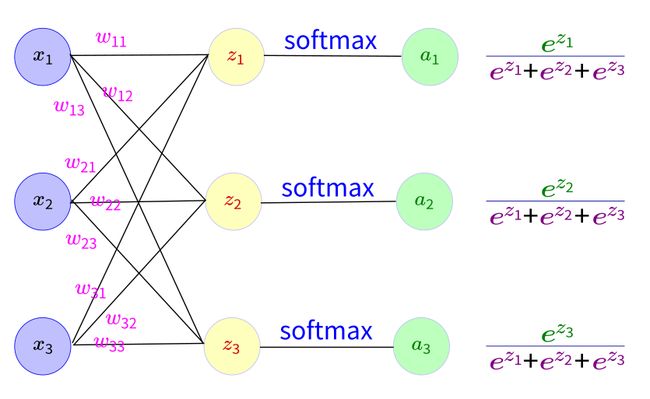
我们能得到下面公式:
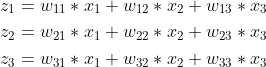
那么我们可以经过softmax函数得到

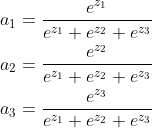
怎么根据求损失函数的梯度,然后利用梯度下降方法更新梯度?
1. 输入为z向量,![\mathbf{z} =[ {z_1,z_2,z_3,....z_n}]](http://img.e-com-net.com/image/info8/ee74eb3d29a2484f829e21b982f630a4.gif) ,维度为(1,n)
,维度为(1,n)
2. 经过softmax函数, 
可得输出a向量, ,维度为(1,n)
3. Softmax Loss损失函数定义为L, ![]() ,L是一个标量,维度为(1,1)
,L是一个标量,维度为(1,1)
其中
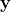 向量为模型的Label,维度也是(1,n),为已知量,一般为one-hot形式。
向量为模型的Label,维度也是(1,n),为已知量,一般为one-hot形式。
我们假设第 j 个类别是正确的,则![\mathbf {y}=[0,0,...,1,..,0]](http://img.e-com-net.com/image/info8/17f6345aace54c7ca92ca7290e59782d.gif) ,只有
,只有 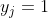 ,其余
,其余 ![]()
那么 我们使用交叉熵作为我们的损失函数。即:
由于训练数据的真实输出为第j个为1,其它均为0,所以损失函数可以简化为:

既然![]() ,进一步简化为
,进一步简化为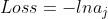
我们的目标是求 标量 对向量 的导数
的导数![]() ,
,
由链式法则,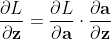 ,其中a和z均为维度为(1,n)的向量。
,其中a和z均为维度为(1,n)的向量。
L为标量,它对向量a求导。见CS224N Lecture 3的一页ppt

而向量a对向量z求导,可得Jacobian矩阵,也见CS224N Lecture 3的一页ppt:

其中f对应的就是softmax函数,x对应的为z。可知向量a对向量z求导是一个Jacobian矩阵,维度为(n,n)。
现在求解
1. 求 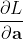
由 ,可知最终的Loss只跟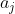 有关。
有关。
![]()
2. 求 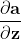
a是一个向量, z也是一个向量,则 是一个Jacobian矩阵,类似这样:

可以发现其实Jacobian矩阵的每一行对应着 ![]() 。
。
由于 只有第j列不为0,由矩阵乘法,其实我们只要求 的第j行,也即 ![]() ,
, ,其中
,其中  。
。
(分子的导数*分母-分子*分母的导数)/分母的平方


只要正向求一次得出结果,然后反向传梯度的时候,只需要将它结果减1即可


如下,我这时对的是j不等于i,往前传:
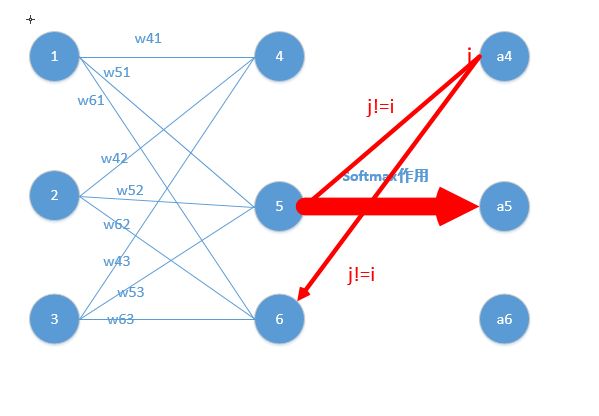
只要正向求一次得出结果,然后反向传梯度的时候,只需要将它结果保存即可
所以,  即
即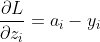 。
。
Softmax Cross Entropy Loss的求导结果非常优雅,就等于预测值与Label的差。
举个例子,通过若干层的计算,最后得到的某个训练样本的向量的分数是[ 2, 3, 4 ],
那么经过softmax函数作用后概率分别就是=[![]() ,
,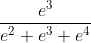 ,
,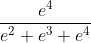 ] = [0.0903,0.2447,0.665],如果这个样本正确的分类是第二个的话,那么计算出来的偏导就是[0.0903,0.2447-1,0.665]=[0.0903,-0.7553,0.665],然后再根据这个进行back propagation就可以了
] = [0.0903,0.2447,0.665],如果这个样本正确的分类是第二个的话,那么计算出来的偏导就是[0.0903,0.2447-1,0.665]=[0.0903,-0.7553,0.665],然后再根据这个进行back propagation就可以了
最后为了直观的感受Softmax与交叉熵的效果,我使用一个简单的输出值[4, -4, 3],通过计算做了下面三分类的表格。
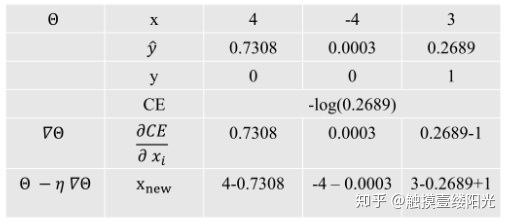
按比例推所有拉一个
此时 是模型输出的实际值,而 是真实的标签值。
是模型输出的实际值,而 是真实的标签值。
- 计算交叉熵损失值:
import tensorflow as tf
print(tf.__version__) # 2.0.0
z = tf.constant([4, -4, 3], dtype = tf.float32)
y_hat = tf.nn.softmax(z)
y = tf.one_hot(2, depth = 3)
print("x:",z)
print("y_hat:", y_hat)
print("y:", y)
CE = tf.keras.losses.categorical_crossentropy(y, z, from_logits = True)
CE = tf.reduce_mean(CE)
print("cross_entropy:", CE)输出结果:
x: tf.Tensor([ 4. -4. 3.], shape=(3,), dtype=float32)
y_hat: tf.Tensor([7.3087937e-01 2.4518272e-04 2.6887551e-01], shape=(3,), dtype=float32)
y: tf.Tensor([0. 0. 1.], shape=(3,), dtype=float32)
cross_entropy: tf.Tensor(1.3135068, shape=(), dtype=float32)- 计算梯度值:
import tensorflow as tf
print(tf.__version__) # 2.0.0
z = tf.constant([4, -4, 3], dtype = tf.float32)
# 构造梯度记录器
with tf.GradientTape(persistent = True) as tape:
tape.watch([z])
# 前向传播过程
y = tf.one_hot(2, depth=3)
CE = tf.keras.losses.categorical_crossentropy(y, z, from_logits=True)
CE = tf.reduce_mean(CE)
dCE_dz = tape.gradient(CE, [z])[0]
print(dCE_dz)输出结果:
最后参数更新只需看最后一行,可以看出Softmax和交叉熵损失函数的梯度下降更新结果:
- 先将所有的 z 值减去对应的Softmax的结果,可以简单记为推所有;
- 然后将真实标记中的对应位置的值加上1,简单记为拉一个;
总的概括Softmax+交叉熵损失函数参数更新为"推所有,拉一个"。
在线LaTeX公式编辑器-编辑器