Redis压缩列表、跳表、位图的实现原理
ziplist数据结构
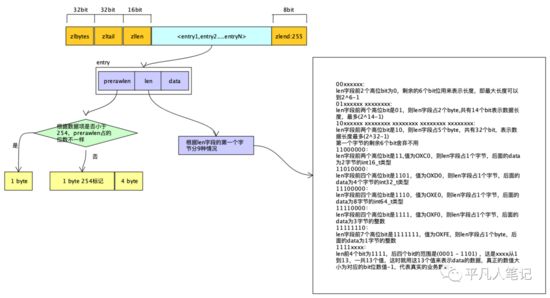
内存会一次性开辟一块大的连续的空间,来存放ziplist。
-
• zlbytes
32bit内存空间,表示ziplist占用的字节总数
-
• zltail
32bit内存空间,表示ziplist表中最后一项(entry)在ziplist中的偏移字节数,通过zltail可以很方便的找到最后一项,从而可以在ziplist尾端快速的执行push或pop操作。
-
• zllen
16bit内存空间,表示ziplist中数据项entry的个数
-
• zlend:255
ziplist最后一个字节,是一个结束标记,值固定等于255
-
• entry
表示真正存放数据的数据项,长度不定
-
• prerawlen
表示上一个节点的数据长度信息。
如果前一个元素的大小prerawlen等于254,用一个字节作为标记项,在用4个字节描述前一个元素大小。
ziplist额外的信息最多需要5个字节存储,相比quicklist双端链表的一个元素需要2个指针16个字节来说节省很多内存开销。
-
• len
entry中数据的长度
-
• data
表示当前元素里面的真实数据,业务数据存储,这是一个非常紧凑的二进制数据结构。
连续的内存空间也会存在弊端?

ziplist放入n多个元素的时候,再往里面添加元素,都需要分配新的内存空间,并且完成数据的完整拷贝。元素比较少还好,但如果元素很多的情况下,会很消耗性能。
那么就需要借助双端链表来控制ziplist的大小,如果超过一定的大小,则分裂成两个,保证每个ziplist不能太大。
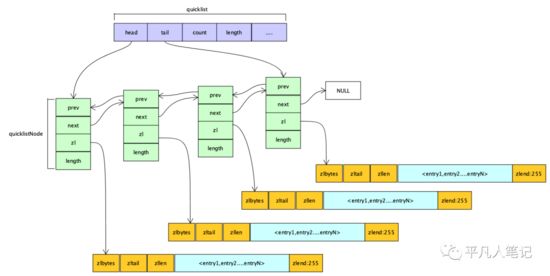
quicklist的底层是quicklistNode,quicklistNode指向ziplist。
加一些数据,比如加入到ziplist里面去,不需要对数据整个做偏移,因为数据已经分配到不同的ziplist里面去了,修改数据,只需要修改某一个ziplist就可以了。
这是基于双端链表做的优化,可以从前往后遍历,也可以从后往前遍历。
接下来看下lpush源码
pushGenericCommand

先从redis数据库获取数据
-
• c->db
db就是要操作的redis数据库
-
• c->argv[1]
比如执行lpush命令
lpush alist a b c argv[0]就是lpush argv[1]就是alist
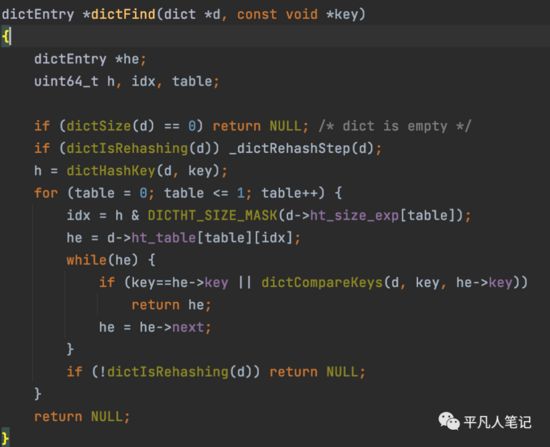
根据key去db中查找数据
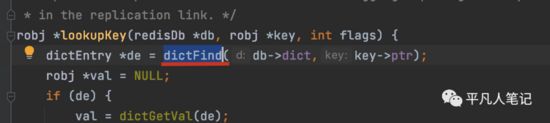
-
• key->ptr
key真正所执行的字符串
进行rehash操作
-1表示没有进行rehash,不等于-1表示正在进行rehash。

做rehash的方法

筛选非空的hash槽

有时候,hash槽上不一定有数据,因为hashtable散列之后有的是空的,如果循环的时候发现有empty_visits=10个hash槽是空的,就不做rehash了。
这个while循环结束之后,剩下的都是非空的hash槽。
获取非空hash槽上链表的头节点
开始遍历链表,重新计算hash值。

这里是进行与运算,而不是求模运算,性能更高。
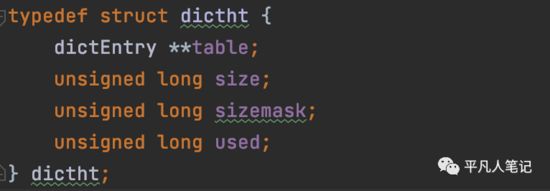
-
• size
size大小为2^n
-
• sizemask
sizemask=size-1=2^n-1
公式
任意数 % 2^n <=> 任意数 & (2^n-1)
即累除法求余数,一次位运算就能计算出结果,更加高效。

计算出key在新的hashtable上的位置之后,将老的hash槽索引指向新的hashtable的表头,并将老的hash槽上的链表迁移到新的hashtable上去,完成了数据迁移操作。

迁移过来之后,老的hashtable上的元素个数减1,新的加1。
一个hash槽一个hash槽的迁移数据。
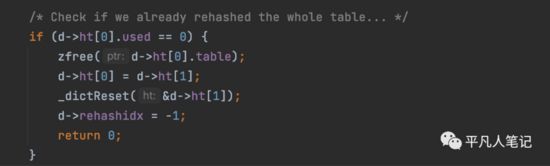
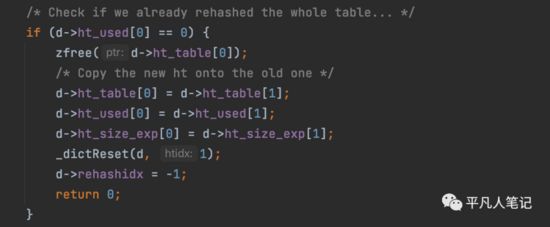
判断老的hashtable中还有没有元素,如果没有的话,就释放掉老的hashtable。
将老的hashtable(ht[0])指向新的hashtable(ht[1]),新的hashtable(ht[1])就释放掉了。
至此,就完成了rehash的过程。
rehash完之后,接下来就是查找key的过程

先从老的hashtable查找(ht[0]),有的话就返回,没有的话再查找新的hashtable(ht[1]),还没有的话就返回null。
接下来就是检查查询到数据的类型
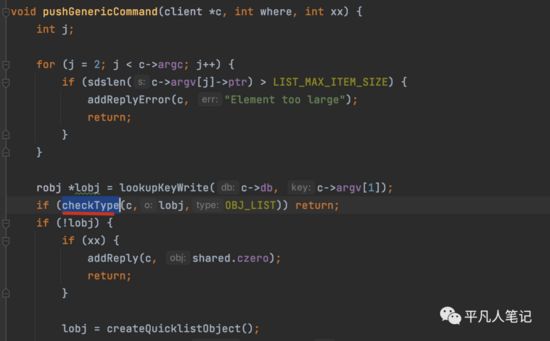
看是否为List数据类型
lpush alist a b c
如果alist不是List而是string 则会报异常提示类型不匹配
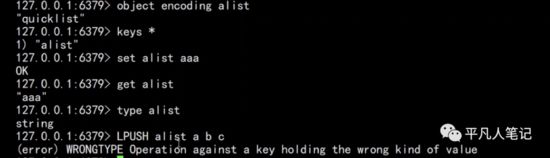
如果在db中没有找到数据,则创建一个quicklist
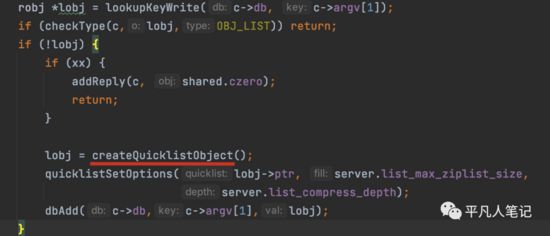

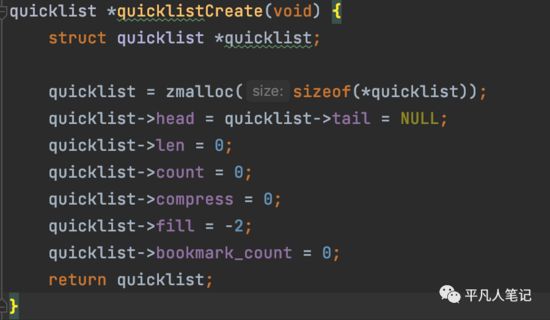


list数据类型,底层编码是quicklist。
接下来就是把创建好的数据添加到字典中了
quicklistSetOptions
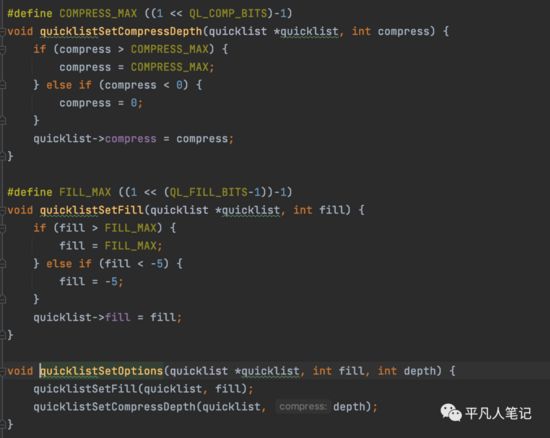
设置每个ziplist的最大容量,quicklist的数据压缩范围,提升数据的存取效率
-
• list-max-ziplist-size -2
单个ziplist节点最大能存储8kb,超过则进行分裂,将数据存储在新的ziplist节点中
默认8kb的数据可以分链
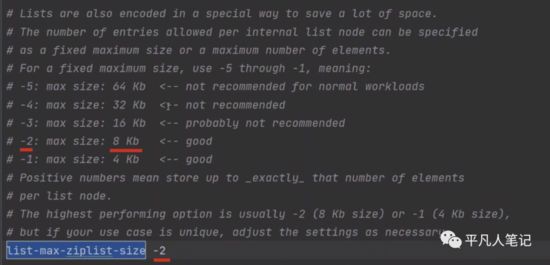
不推荐-5,因为数据大了往内存中添加元素,会涉及到数据的拷贝,导致性能降低。
-
• list-compress-depth 1
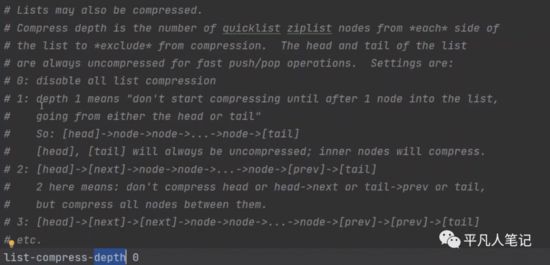
0代表所有节点,都不进行压缩,1代表从头节点往后走一个,尾节点往前走一个不用压缩,其他的全部压缩,2,3,4以此类推

双端链表内存是不连续的,就会导致内存碎片问题,压缩了之后,就可以做成整块的内存空间了,使得数据更加的有规律,节省了内存空间。
dbAdd

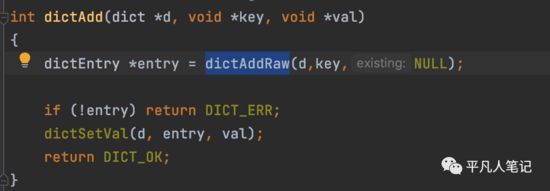
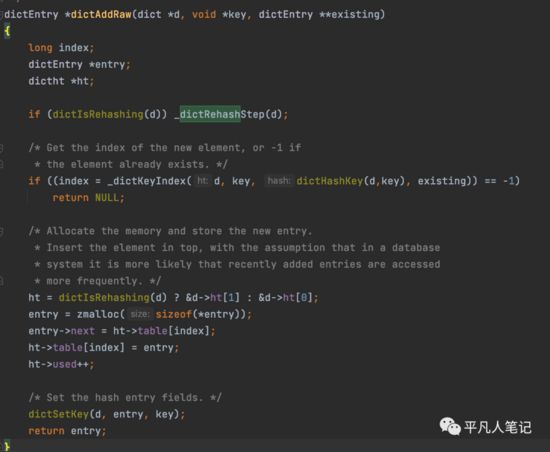
每次访问hashtable都会做一次rehash的操作。
rehash完之后,求索引值

存放元素:如果正在做rehash,则将新增的元素放入新的hashtable中
采用头插法,最新添加的,会被更频繁的访问
老的hashtable索引指向新创建的元素地址,entry就是新创建的节点

hashtable指向的就是链表的头部节点
接下来把添加的数据追加到list中去

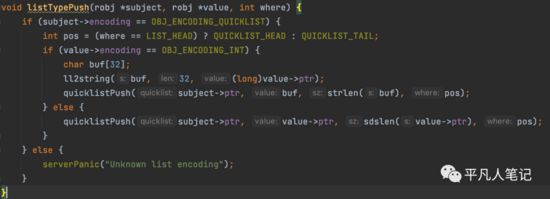
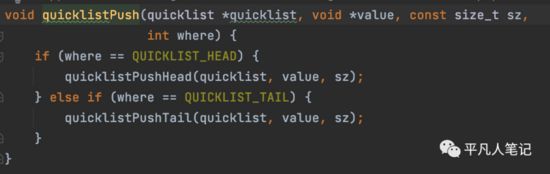
创建quicklistNode和ziplist

Set 数据类型
set语义上来说是无序的


上面这种整数的、元素不多的是通过有序的数据结构实现的

基于上面都是整数元素的基础上添加一个字符串元素,返回结果是1,因为只添加进去一个元素。
此时的编码是hashtable,因为字符串数据的那个元素没有办法用整型值编码的时候,会重新转换成一个hashtable。
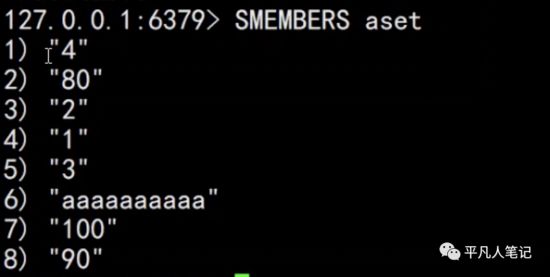
此时就变成无序的了,因为hashtable本身就是无序的数据结构。
Set为无序,自动去重的集合数据类型,Set数据结构底层实现为一个value为null的字典(dict),当数据可以用整型表示时,Set集合将被编码为intset数据结构。以下两个条件任意满足一个,Set将用hashtable存储数据
-
• 元素个数大于set-max-intset-entries
set-max-intset-entries 512 intset能存储的最大元素个数,超过则用hashtable编码
-
• 元素无法用整型表示
intset就是一个数组,有序,都是整形元素。通过二分查找来判断某个元素是否存在。用整型数组更节省空间。
sadd源码
从server.c 文件中的 redisCommand redis命令集合中找到sadd

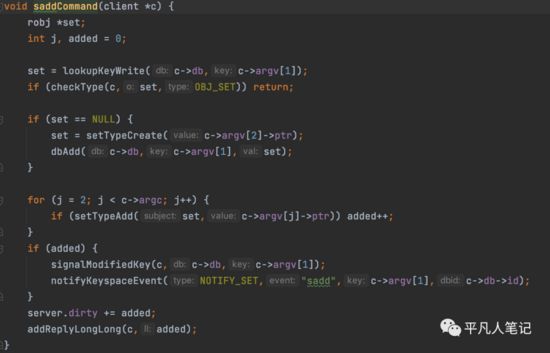
查询redis db中是否存在set集合

如果不存在的话,则创建set集合

判断字符串是否可以转换成long,如果可以则创建intset


创建intset集合
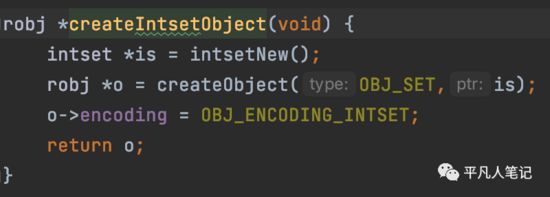
数据类型是set,数据编码是intset
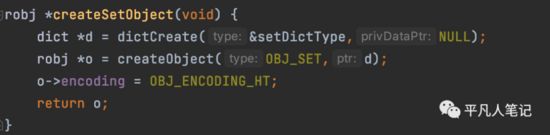
否则创建hashtable

set集合创建好之后,将set添加到db中
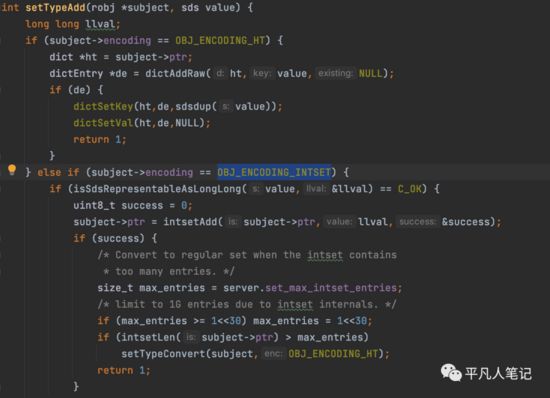
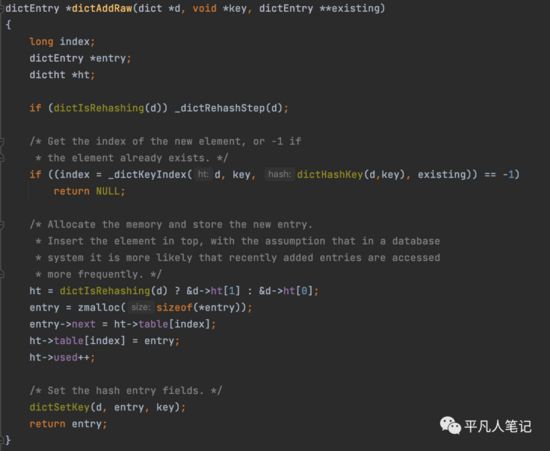
dictAddRaw
如果数据编码是hashtable
值设置为NULL

intset
如果是数字,则追加到intset中去
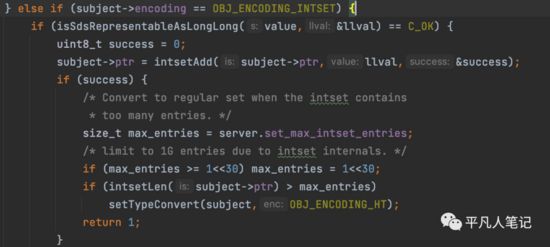
intsetAdd

intsetValueEncoding
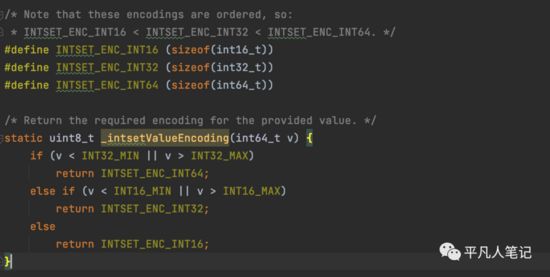
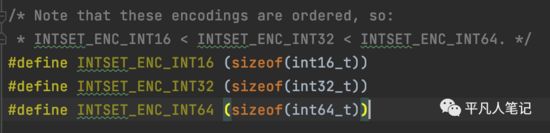
判断下数据范围,3种类型的数组,16个bit位的,32bit位,64bit位的,判断下追加的值属于哪个范围,就用对应的数组,这是为了节省内存空间,根据数据的范围去创建不同的数组,如果数据量非常大的话,就用大一点的位数去创建数组。

如果范围比现有的范围还大的话,就进行升级,如果超过了32位就用64位,超过了16位,就用32位的数组。
如果小于现有的编码长度的话
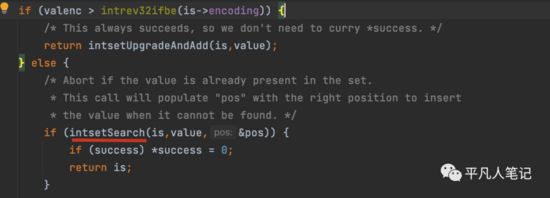
查询下数据在当前intset中是否存在,intset也会自动去重,已经存在的话,就直接返回。
intsetSearch
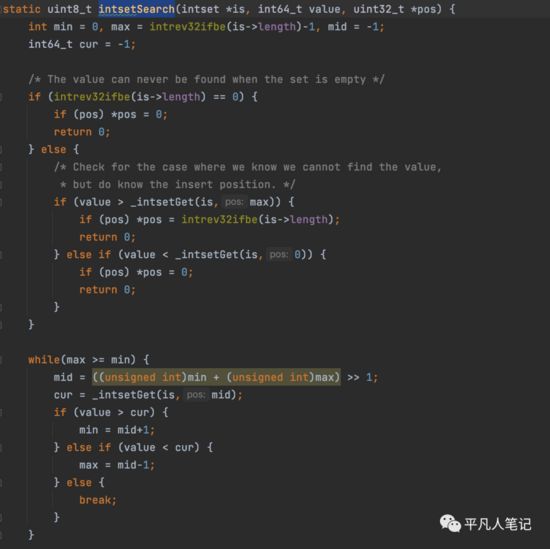
这里使用的是二分查找,break就是终止了,然后判断是否存在
往右移动一位就是除以2

相等就是存在,否则就是不存在,不存在的话,就记录下position,这样就知道下一次数据放在哪个位置了。
因为要添加元素,所以要重新扩容


扩容之后,在对应的position上把添加的元素放进去

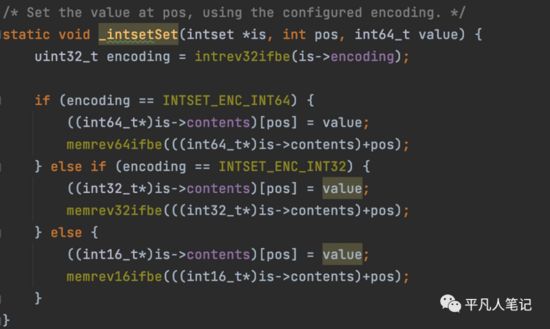
根据数据的长度采用不同的存储类型来存放
Set 数据类型底层intset编码
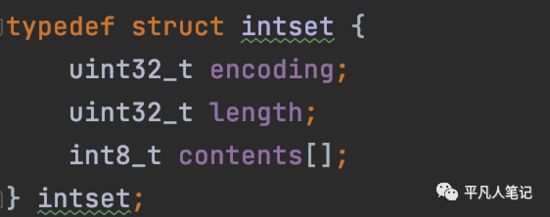
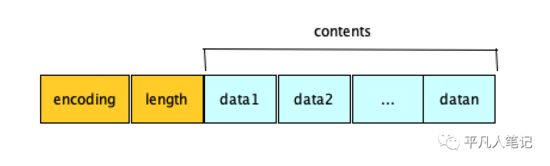
整数集合是一个有序的,存储整型数据的结构,整型集合在redis中可以保存int16_t,int32_t,int64_t类型的整型数据,并且可以保证集合中不会出现重复数据。
Hash 数据类型
Hash数据结构底层实现是一个字典(dict),也是RedisDB用来存储K-V的数据结构,当数据量比较小,或者单个元素比较小时,底层用ziplist存储。数据大小和元素阈值可以通过如下参数设置:
-
• hash-max-ziplist-entries 512
ziplist元素个数超过512,将改为hashtable编码
-
• hash-max-ziplist-value 64
单个元素大小超过64byte时,将改为hashtable编码
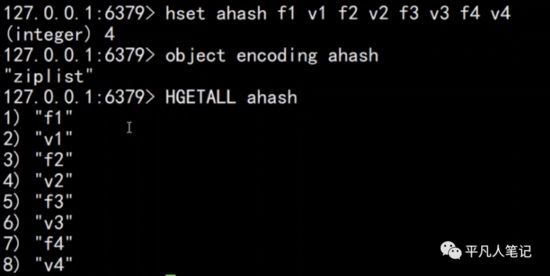
按照放入顺序存取
Hash数据类型ziplist编码
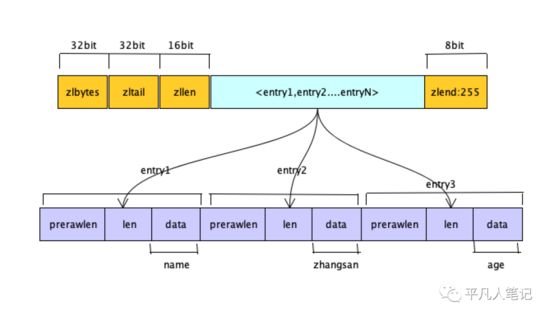
用hash去存储K-V的时候,比如name、age,一个键值对拆成2个元素放到一个ziplist里面,从而更有效的利用内存。

单个元素超过64字节,就会变成无序的hashtable编码存储

有序的ZSet
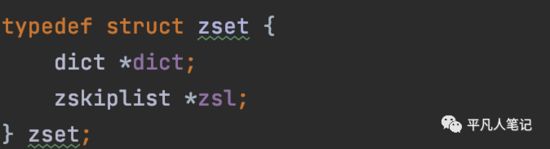
zset/sorted_set数据类型
ZSet是有序的,自动去重的集合数据类型,ZSet数据结构底层实现为字典(dict)+跳表(skiplist),当数据比较少时,用ziplist编码结构存储
-
• zset-max-ziplist-entries 128
元素个数超过128,将用skiplist编码
-
• zset-max-ziplist-value 64
单个元素超过64byte,将用skiplist
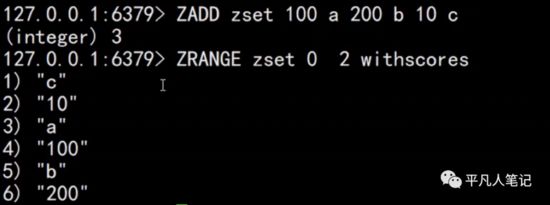
0,2表示排名;withscores表示分值打印

当数据量比较小的时候,编码是紧凑的连续空间,对内存利用率高,可自动去重。
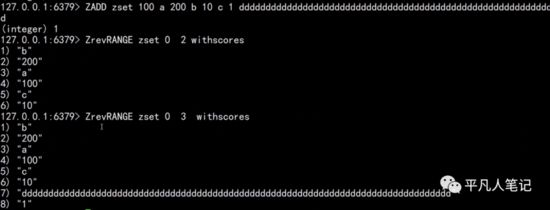

当数据量比较大的时候,底层编码就变成了skiplist 跳表
skiplist 跳表数据结构

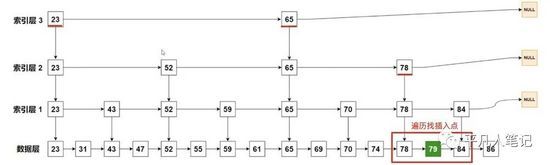
这是一个有序的链表,想要找元素79,挨个遍历才能找到,时间复杂度是O(n)。

在数据层基础之上提一个索引层出来,每隔一个元素就提一个索引出来,用索引帮助查询数据,在索引层直到找到比79大的数据,就不往后找了即索引层找到78,下沉到数据层78,再往后找一个就是79了,这样就会跳过很多的元素,提高查询效率。

再提一个索引层2

再提一个索引层3
时间复杂度分析
数据:n
index 1 n/2
index 2 n/2^2
index 3 n/2^3
index k n/2^k
每添加一个索引层就减少一半的数据量即索引第三层是索引第二层的一半,索引第二层是索引第一层的一半,索引第一层是数据层的一半。
每一层都只需要常数级别查询次数即可,该查询次数就是层高。
根据数据归纳法,假设索引层最顶层有2个数据,即n/2^k=2 => 2^k=n/2 => k= log_2 n
以2为底,n的对数即log n的时间复杂度。
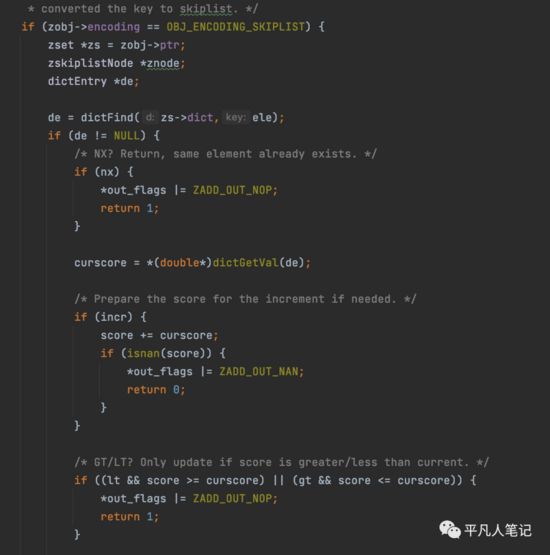
zadd源码
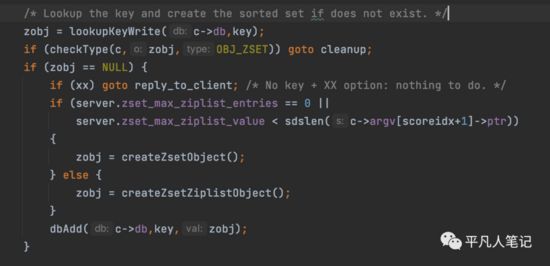
查询zset,如果没有,则创建一个跳表或zskiplist
-
• 创建跳表zskiplist

-
• 创建ziplist
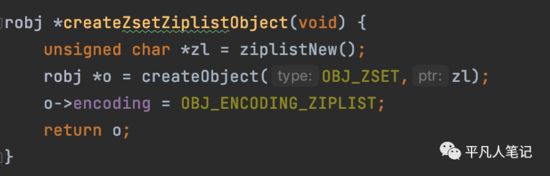
zset是复合型数据结构:字典+跳表
字典可以最快速的索引到记录,跳表存储的是有序的数据。
zscore O(1)的时间复杂度,通过元素拿到分值,查询效率高效是源于zset的dict字典数据结构。
dict里面存储的是索引,不是真正的值,真正的值只有一份,是由dict和zskiplist共享,尽量减少存储空间的前提下提升访问速度。
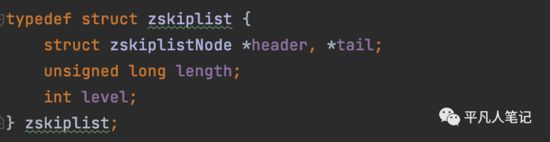
zskiplist
-
• skiplistNode *header, *tail
双向指针
1、可以从前往后遍历

升序
2、也可以从后往前遍历

倒序
-
• long length
元素个数
-
• int level
索引最高的层高。在redis中索引层的索引没有那么规律,而是用随机数生成的。
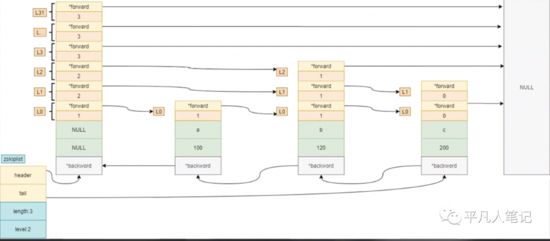
zskiplistNode

-
• sds ele 元素
-
• double score 分值
-
• zskiplistNode *backward; 同类型指针,指向后面的节点
-
• zskiplistLevel level[] 索引层 是个数组
-
• zskiplistLevel.zskiplistNode 指向前面的节点
-
• long span 两个索引层之间的间隔

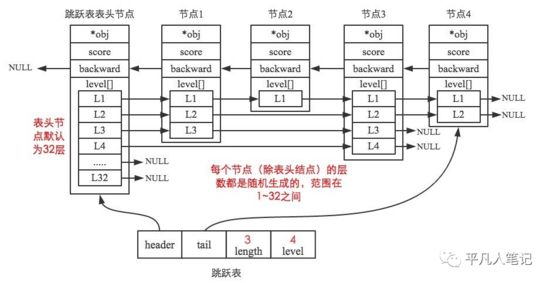
zskiplist数据结构补充说明
-
• header指向头结点,头结点的层高始终为64层
-
• level保存跳表中节点层数最高值,但是不计算头结点的层高
-
• length保存跳表中节点个数,但是不包括头结点
-
• tail指向尾节点
举例说明:
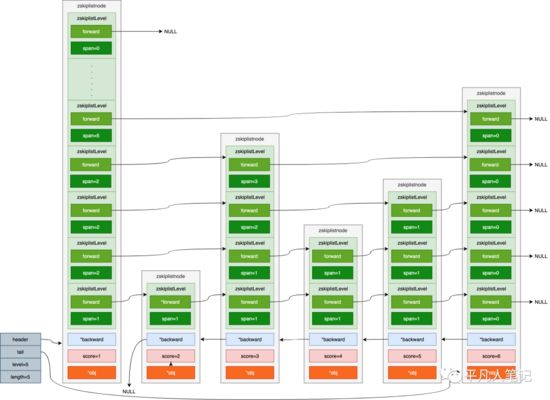
假设要找score为5的元素
(1)首先从头结点的最高层(也就是64层)开始查找,但是由于头指针中保存了当前跳表的最高层数,所以直接从头结点的level层开始查找即可。如果zkiplistLevel的forward为NULL,则继续向下
(2)直到头结点中第5层的zskiplistLevel的forward不为空,它指向了第6个节点的第5层,但是这个节点的score为6,大于5,所以还要从头结点向低层继续查找
(3)头结点中第4层的zskiplistLevel的forward指向第3个节点的第4层,这个节点的score为3,小于4,继续从这个节点的forward向后遍历。它的forward指向第6个节点的第4层,这个节点的score为6,大于5,所以还要从前一个score为3的节点向低层继续查找
(4)第3个节点第3层的zskiplistLevel的forward指向第5个节点的第3层,而它的score正好为5,查找成功
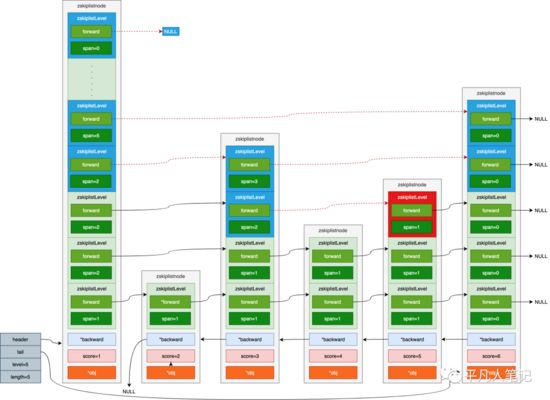

求元素79的排名,每经过一个节点就计算它之间的span,就能算出它的排名。

将生成好的zset放入db中
先rehash,然后存储在hashtable中去。
然后就是计算分值并往zset中添加元素

-
• 往ziplist添加元素
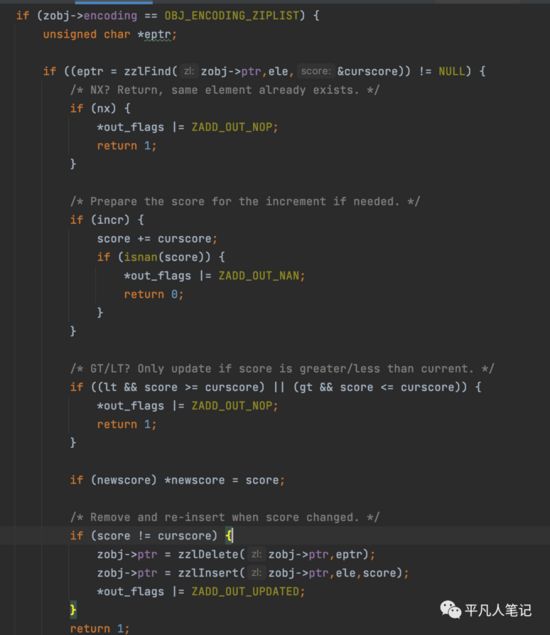
-
• 往跳表中添加元素
从跳表字典中查找记录
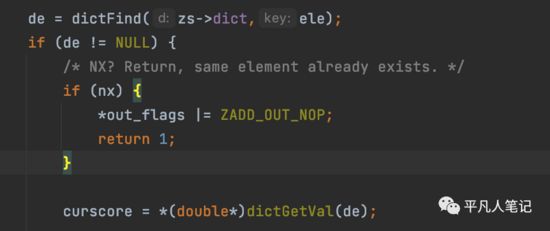
时间复杂度是O(1)。
如果de不为空,说明元素之前已存在了,此时如果是setnx,则会直接抱异常,否则可以修改它的值。

如果两个值不相等,先删除再插入数据。
zslUpdateScore
Redis中的做法比较简单,先找到待修改的节点,直接删除,然后插入修改后的新的节点。

找新增元素的位置:遍历所有的索引层,找位置。
判断分值在什么地方,如果在原来元素的位置,不用移动元素,更新分值即可。
比如

将b元素的分值由200修改成201,其他元素没有变化,排名不变。

将b由200修改成301,排名发生变化

删除原来的元素,再插入新的
删除逻辑 zslDeleteNode
(1)找到待删除的节点,删除节点,更新前面节点的跨度和跳表最大层高
(2)更新新节点的各层的forward以及backward指针

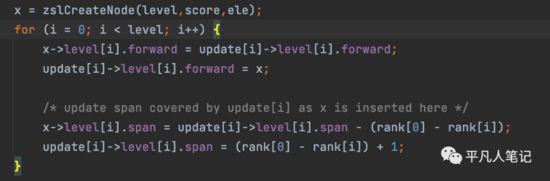
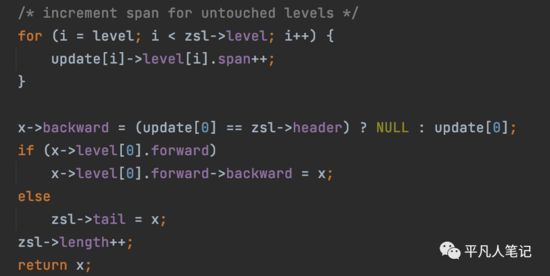
新增逻辑 zslInsert
(1)首先,插入结点时,都会随机为新的节点分配一个小于64的层数,并且层数越小概率越大,层数越高概率越小
(2)查找到小于待插入score的分数值中最大的那个节点,如果score相等,则通过value比较
(3)在找到的节点后面插入新的节点。同时更新前面节点的跨度和跳表最大层高
(4)更新新节点的各层的forward以及backward指针
插入节点,最关键在于索引层的创建和指针的关联关系
第一步:找插入的位置

第二步:创建索引层
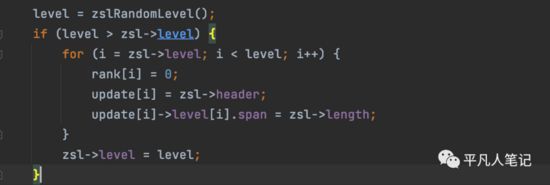
在创建节点之前,先创建索引层,通过随机算法生成


while循环的条件是随机数random 小于 P=1/4 ,结束循环的条件是1-P
1、
level=1 第一层索引的生成概率即生成完第一层索引循环就结束的概率是1-P=3/4
2、
level=2 第二层索引的生成概率即生成完第二层索引循环就结束的概率是 P*(1-P)
-
• 第一次level=1 生成第一层索引的概率是1/4
-
• 第二次level=2 生成第二层索引的概率是3/4
3、
level=3 第三层索引的生成概率是 P^2 * (1-P)
-
• 第一次level=1 生成第一层索引的概率是1/4
-
• 第二次level=2 生成第二层索引的概率是1/4
-
• 第三次level=3 生成第三层索引的概率是3/4
综上:层数越高,生成的概率越低,导致越高层的索引就越少,越低层的索引更多。
层数越高,出现的概率越低,节点越少,能够一次性判别的元素更多。
创建好索引之后,每个索引的初始化参数都设置好,包括span的重新设置。
第三步: 创建节点
索引层作为参数传递进入
节点创建好之后,再更新节点关系,包括头节点指向它的关系、和两边节点之间的关系都需要重新创建、span的重新计算
再把对应的统计数据++,因为新增了一个元素
Redis高级数据类型BitMap位图
bit是计算机最小的存储单元,取值为0和1。
bitmap提供了对bit位的设值、操作、统计的命令,通常被用来在极小的空间消耗下通过位运算(AND/OR/XOR/NOT)来实现对状态的操作,常见的使用场景:
-
• 海量用户系统的日活/周活统计
-
• 连续登录用户统计
-
• 海量用户会员判断
-
• 判断是否状态的记录,如是否签到
二进制数据在内存中是连续的空间
随机索引到要操作的bit位的效率非常高,时间复杂度是O(1)。
-
• bitmap可以判断某一个bit位上是0还是1
-
• 对一组bit流上的数据统计所以为1的个数
-
• 对两个bit流进行位运算(&与、|或、异或XO)
bitmap基本操作

对二进制序列进行具体的操作

key就是在内存中的一个二进制bit序列,每个序列都有一个索引,就是它的顺序,其实就是offset偏移量。value值是0或1。
bitmap底层是string类型实现的,bitmap本身就是一个string。
help @string


setbit返回的0是指老值是0

其他bit位都默认是0

统计key所对应的二进制序列中bit位为1的个数。