Day_12 Redis
01-mysql存在的问题(掌握)
- 现象
- 现象特征
- 第一,用户比较多,海量用户
- 第二,高并发
- 原因分析
- 性能瓶颈:磁盘IO性能低下
- 扩展瓶颈:数据关系复杂,扩展性差,不便于大规模集群
- 解决方案
- 减少读写磁盘,越少越好
- 去除数据间关系,越简单越好
- 不使用mysql

02-NoSQL概念(掌握)
- 概述
- NoSQL:即 Not-Only SQL( 泛指非关系型的数据库),作为关系型数据库的补充。
- 作用:应对基 于海量用户和海量数据前提下的数据处理问题。
- 之前,数据存储使用SQL,还可以用别的东西来存储数据。这种非SQL存储数据的方案叫做NoSQL。
- 特征
- 可扩容,可伸缩。SQL数据关系过于复杂,你扩容一下难度很高,那我们Nosql 这种的,不存关系, 所以它的扩容就简单一些。
- 大数据量下高性能。包数据非常多的时候,它的性能高,因为你不走磁盘IO,你走的是内存,性能肯 定要比磁盘IO的性能快一些。
- 灵活的数据模型、高可用。他设计了自己的一些数据存储格式,这样能保证效率上来说是比较高的, 最后一个高可用,我们等到集群内部分再去它!
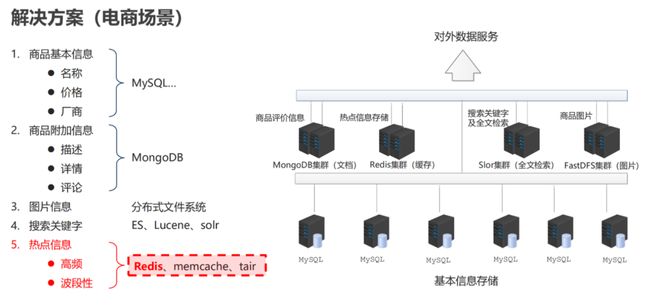
- 应用场景
03-Redis概述(掌握)
- 概述
- 特征
- 数据存储在缓存中,缓存的读取速度快,能够大大的提高运行效率;
- 数据间没有必然的关联关系;
- 内部采用单线程机制进行工作;
- 多数据类型支持 支持持久化,可以进行数据灾难恢复
- 应用场景
- 为热点数据加速查询(主要场景)。如热点商品、热点新闻、热点资讯、推广类等高访问量信息等。
- 即时信息查询。如各位排行榜、各类网站访问统计、公交到站信息、在线人数信息(聊天室、网 站)、设备信号等。
- 时效性信息控制。如验证码控制、投票控制等。
- 分布式数据共享。如分布式集群架构中的 session 分离 消息队列.
04-Redis下载和安装(掌握)
-
下载
- Download | Redis
-
开发步骤
- ①将redis-6.2.4.tar.gz上传到/usr/local目录中
- ②解压redis-6.2.4.tar.gz
- ③编译redis
- ④安装redis
- ⑤启动redis服务器
-
①将redis-6.2.4.tar.gz上传到/usr/local目录中
-
②解压redis-6.2.4.tar.gz
tar -zxvf redis-6.2.4.tar.gz -
③编译redis
make -
④安装redis
make install -
⑤启动redis服务器
redis-server
05-Redis启动服务器(掌握)
-
概述
- 首先,得启动redis服务器,才能够使用redis客户端来访问使用.
-
语法
#手动设置参数启动 , 默认端口号6379 redis-server [--port 端口号] #配置文件启动 redis-server 配置文件路径 -
代码实现
redis-server --port 6379
06-Redis配置文件(掌握)
-
配置文件
# 服务器设置 # 指定redis服务端只接收来自于该IP地址的请求,如果不进行设置,那么将处理所有请求 # bind 127.0.0.1 # redis服务器端口 port 6379 # 设置为no,redis不在后台运行。如果有配置日志文件,那么日志会记录到日志文件中,不会显示到控制台;如果没有配置日志文件,那么日志显示到控制台。 # 设置为yes,redis在后台运行,日志会记录到日志文件中,不会显示到控制台 daemonize no # 设置工作目录 , RDB文件、AOF文件、日志文件的存储路径 dir /usr/local/redis-6.2.4/data # 客户端设置 # 最大客户端连接数 maxclients 50 # 设置客户端连接时的超时时间,单位为秒。当客户端在这段时间内没有发出任何指令,那么关闭该连接。0是关闭此设置 timeout 0 # 日志记录设置 # 设置日志级别,默认为verbose # debug : 记录很多信息,用于开发和测试 # verbose : 有用的信息,不像debug会记录那么多 ,开发环境推荐 # notice : 普通的verbose,常用于生产环境,生产环境推荐 # warning : 只有非常重要或者严重的信息会记录到日志 # loglevel debug # 设置日志文件的生成位置 # logfile "log-6379.log" # 设置无密码访问 protected-mode no -
启动服务器
redis-server redis-6379.conf
07-Redis启动客户端(掌握)
-
概述
- 启动redis客户端来访问redis服务器
-
语法
#[-h ip] [-p port]都不写,意味着连接本机的6379的redis服务器 redis-cli [-h ip] [-p port] -
代码实现
redis-cli redis-cli -h 192.168.148.110 -p 6379
08-Redis数据类型(掌握)
- 数据类型
- string , hash , list , set , zset(sorted set)
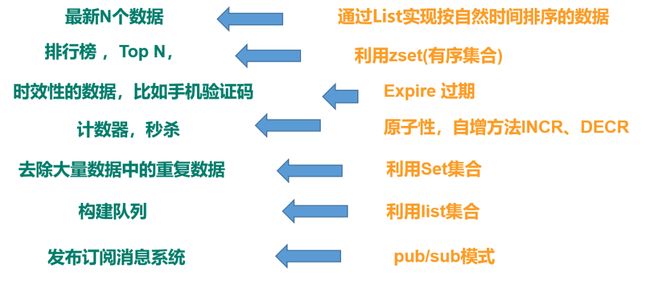
- 应用场景
09-string概述(掌握)
- 概述
- string自身是一个 Map,其中所有的数据都是采用 key : value 的形式存储。
- 存储结构

- 单个数据,最简单的数据存储类型,也是最常用的数据存储类型。
- 存储数据的格式:一个key对应一个value
- 一个Redis中字符串value最多可以是512MB.
10-string基本操作(掌握)
-
语法
#添加/修改值 set key value #获取值 get key #添加多个值 mset key1 value1 [key2 value2]... #获取多个值 mget key1 [key2]... #获取指定数据的长度 strlen key #追加内容,如果没有指定key就新建,如果有指定key就追加 append key value
11-string扩展操作(掌握)
-
概述
- 一块是对数字进行操作的,第二块是对我们的key的 时间进行操作的。
-
语法
#指定数据加1 incr key #指定数据加num incrby key num #指定数据减1 decr key #指定数据减num decrby key num#添加数据,并指定有效期(秒) setex key seconds value #添加数据,并指定有效期(毫秒) psetex key milliseconds value
12-key命名约定(掌握)
-
命令约定
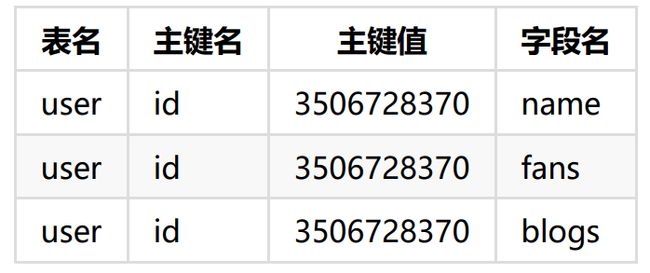
- key=表名:主键名:主键值:字段名
-
代码实现
set name oldqiu set fans 10000 set blogs 120#符合key命名约束 set t_user:userId:1:name oldiqu set t_user:userId:1:fans 10000 set t_user:userId:1:blogs 120
13-string应用场景(掌握)
-
需求
-
代码实现
#错误 set focus 83 set fans 12210947 set blogs 6164set user:id:1989:focus 83 set user:id:1989:fans 12210947 set user:id:1989:blogs 6164set user:id:1989 '{"focus":83,"fans":12210947,"blogs":6164}'

14-hash概述(掌握)
- string存在问题
- 使用string类型来处理,如果我们用单条去存的话,它存的条数会很多。如果我们用 json格式,它存一条数据就够了,但是,假如说现在粉丝数量发生变化了,你要把整个值都改了。
- 概述
- hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。 类似Java里面的Map
- 结构

- key : 相当于string的key的相同部分
- field : 相当于string的key的不同部分
- value : 相当于string的value
15-hash基本操作(掌握)
-
语法
#添加/修改数据 hset key fiedl1 value1 [field2 value2]... #获取指定key中指定field的数据 hget key field #获取指定key中的所有field的数据 hgetall key #删除指定key中的指定field hdel key field1 [field2]... #获取指定key中的field的数量 hlen key #判断指定field在指定key中是否存在 hexists key field -
需求
- 解决string存在的问题
-
代码实现
hset user:id:1989 focus 83 fans 12210947 blogs 6164 hgetall user:id:1989
16-hash扩展操作(掌握)
-
语法
#获取所有的field hkeys key #获取所有的value hvals key #指定key的指定field去加/减num(如果是正数就是加,如果是负数就是减) hincrby key field num
17-hash应用场景(掌握)
-
需求

- 双11活动日,销售手机充值卡的商家对移动、联通、电信的30元、50元、100元商品推出抢购活动。
- 商家1,有30元商品800张,有50元商品600张,有100元商品500张
- 商家2,有30元商品900张,有50元商品400张,有100元商品550张
- 商家1,30元商品卖出了120张,50元商品卖出了200张,100元商品卖出了80张
- 商家2,30元商品卖出了180张,50元商品卖出了300张,100元商品卖出了90张
-
代码实现
#商家1,有30元商品800张,有50元商品600张,有100元商品500张 hset shop1 product30 800 product50 600 product100 500 #商家2,有30元商品900张,有50元商品400张,有100元商品550张 hset shop2 product30 900 product50 400 product100 550 #商家1,30元商品卖出了120张,50元商品卖出了200张,100元商品卖出了80张 hincrby shop1 product30 -120 hincrby shop1 product50 -200 hincrby shop1 product100 -80 #商家2,30元商品卖出了180张,50元商品卖出了300张,100元商品卖出了90张 hincrby shop2 product30 -180 hincrby shop2 product50 -300 hincrby shop2 product100 -90 #抢购完成后,统计商品数量 hgetall shop1 hgetall shop2
18-list概念(掌握)
- hash存在的问题
- hash可以存储多个数据,但是没有顺序
- 概述
- 是简单的字符串列表,按照插入顺序排序。你可以添加一个元素导列表的头部(左边)或者尾部(右 边)
- 结构

- list的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差
19-list基本使用(掌握)
-
语法
#从list的左边添加数据 lpush key value1 [value2]... #从list的右边添加数据 rpush key value1 [value2]... // 3 2 1 4 5 6 #从list的左边获取数据,范围从begin到end lrange key begin end #获取指定index索引处的元素 lindex key index #获取list长度 llen key #获取list最左侧的元素并移除 lpop key #获取list最右侧的元素并移除 rpop key
20-list扩展操作(掌握)
-
语法
#移除指定key中count个value lrem key count value #获取并移除最左侧的元素,如果没有就等待timeout秒 blpop key timeout #获取并移除最右侧的元素,如果没有就等待timeout秒 brpop key timeout
21-list应用场景(掌握)
-
需求
-
①按照时间先后顺序
rpush logs alog:in blog:run alog:sale clog:out alog:safe blog:err lrange logs 0 -1 -
②按照最新操作顺序
lpush logs2 alog:in blog:run alog:sale clog:out alog:safe blog:err lrange logs2 0 -1

22-set概述(掌握)
- list存在的问题
- ①数据结构是双向链表,查询速度比较慢;
- ②对列表中的数据无法去重.
- 概述
- set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储 一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否 在一个set集合内的重要接口,这个也是list所不能提供的。
- 结构
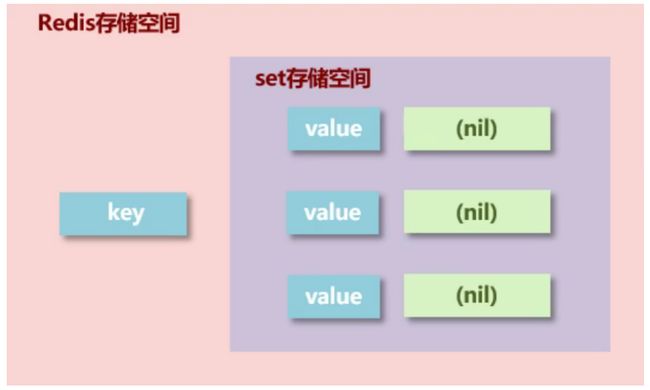
- 底层就是hash结构
- hash的key是set的key,hash的field是set的value,hash的value就是nil
23-set基本操作(掌握)
-
语法
#添加数据 sadd key member1 [member2]... #获取所有数据 smembers key #移除指定数据 srem key member1 [member2]... #获取长度 scard key #判断指定key的set是否包含指定member sismember key member #获取指定key的set的指定count数量的随机元素,count默认为1 srandmember key [count] #获取指定key的set的指定count数量的随机元素,并移除,count默认为1 spop key [count]
24-set扩展操作(掌握)
-
语法
#获取key1和key2交集 sinter key1 key2 #获取key1和key2并集 sunion key1 key2 #获取key1和key2差集 sdiff key1 key2#获取key1和key2的交集并存储到key3 sinterstore key3 key1 key2 #获取key1和key2的并集并存储到key3 sunionstore key3 key1 key2 #获取key1和key2的差集并存储到key3 sdiffstore key3 key1 key2
25-set应用场景(掌握)
-
需求
- 解决文件上传中产生的垃圾文件。
-
代码实现
#设置所有上传文件列表 sadd allfiles girl1.jpg girl2.jpg girl3.jpg #设置有效上传文件列表 sadd validfiles girl2.jpg girl3.jpg #获取垃圾文件列表 sdiff allfiles validfiles
26-zset概述(掌握)
- 概述
- zset与set非常相似,是一个没有重复元素的字符串集合。不同之处是有序,集合的每个成员都关联了 一个评分(score) ,这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集 合的成员是唯一的,但是评分可以是重复了 。
- 因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的 元素。访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的列 表。
27-zset基本操作(掌握)
-
语法
#添加元素,并指定score zadd key score1 value1 [score2 value2]... #获取指定key的zset中的元素,脚标从start开始到stop结束 #[withscores]:是否携带score值 zrange key start stop [withscores] #按照指定范围(min max)的分数获取指定key的zset中的元素(按照score从小到大) #[withscores] : 设置是否携带score #[limit offset count] : 对结果进行截取(从offset开始的count个元素) zrangebyscore key min max [withscores] [limit offset count] #按照指定范围(max min)的分数获取指定key的zset中的元素(按照score从大到小) #[withscores] : 设置是否携带score #[limit offset count] : 对结果进行截取(从offset开始的count个元素) zrevrangebyscore key max min [withscores] [limit offset count]
28-zset扩展操作(掌握)
-
语法
#给指定key的指定value的score值增加指定的increment zincrby key increment value #从指定key的zset中移除指定value zrem key value #按照分数范围(min max)来统计指定key的元素个数 zcount key min max #获取value元素在指定key中的索引 zrank key value
29-zset应用场景(掌握)
-
需求
- 实现一个文章访问量的排行榜
-
代码实现
zadd bookranks 1000 javase 10 javame 10000 javaee #按照分数从小到大排序 zrange bookranks 0 -1 zrangebyscore bookranks 1 10000000 #按照分数从大到小排序 zrevrangebyscore bookranks 10000000 1 limit 0 2