机器学习/深度学习-学习笔记:概念补充(中)
学习时间:2022.05.11
概念补充(中)
在进行学习机器学习和深度学习的过程中,对于部分概念会比较陌生(可能是因为没有系统深入学习过统计学、运筹学和概率统计的相关知识;也可能是因为看的东西比较偏实践,对理论的了解不是很深入),同时对有些概念的了解仅限于熟悉的或者用过的那几个,甚至有些概念会用但不知道具体的原理,所以想对其中的几个频繁出现的概念做个系统了解。主要包括:
- 上:极大似然估计、贝叶斯、傅里叶、马尔科夫、条件随机场;
- 中:凸集、凸函数与凸优化,优化算法(优化器),过拟合与欠拟合;
- 下:正则化&归一化、标准化,损失函数和伪标签等。
文章目录
- 概念补充(中)
-
- 6. 凸集、凸函数与凸优化
-
- 6.1 几何体的向量表示
- 6.2 凸集 Convex Set
- 6.3 凸函数 Convex Function
- 6.4 凸优化 Convex Optimization
- 6.5 常见凸优化问题(凸问题的特殊情况)
- 7. 优化算法
-
- 7.1 传统的梯度下降法
- 7.2 基于动量的梯度下降
- 7.3 基于自适应学习率的梯度下降
- 7.4 融合动量与自适应学习率的方法
- 7.5 其他改进方法
- 8. 过拟合与欠拟合
-
- 8.1 缓解欠拟合
- 8.2 缓解过拟合
6. 凸集、凸函数与凸优化
本节参考内容:一文详解凸函数和凸优化、凸优化学习(一)、(二)、(三)、(四)。
在很多时候,我们进行机器学习算法时希望优化某些函数的值。即,给定一个函数 f : R n → R f : R^n → R f:Rn→R ,我们想求出使函数 f ( x ) f(x) f(x)最小化(或最大化)的原像 x ∈ R n x ∈ R^n x∈Rn。我们已经看过几个包含优化问题的机器学习算法的例子,如:最小二乘算法、逻辑回归算法和支持向量机算法,它们都可以构造出优化问题。
在一般情况下,很多案例的结果表明,想要找到一个函数的全局最优值是一项非常困难的任务。然而,对于一类特殊的优化问题——凸优化问题, 我们可以在很多情况下有效地找到全局最优解。在这里,有效率既有实际意义,也有理论意义:它意味着我们可以在合理的时间内解决任何现实世界的问题,它意味着理论上我们可以在一定的时间内解决该问题,而时间的多少只取决于问题的多项式大小。
凸优化问题的重要性:
- 凸优化具有良好性质,如局部最优解是全局最优解,且凸优化问题是多项式时间可解问题,如:线性规划问题;
- 很多非凸优化或NP-Hard问题可以转化成凸优化问题,方法:对偶、松弛(扩大可行域,去掉部分约束条件),在SVM算法中,为了对目标函数进行优化,便使用了拉格朗日乘子法、对偶问题、引入松弛因子等。
6.1 几何体的向量表示
在介绍凸集等概念之前,首先介绍一下空间几何体的向量表示,下面在定义凸集概念时便用到了线段的线段表示。先通过一个例子来认识一下如何使用向量表示线段:
已知二维平面上两定点A(5, 1)、B(2, 3),给出线段AB的方程表示如下: { x 1 = θ ∗ 5 + ( 1 − θ ) ∗ 2 x 2 = θ ∗ 1 + ( 1 − θ ) ∗ 3 θ ∈ [ 0 , 1 ] \begin{cases} x_1 = θ*5+(1-θ)*2\\ x_2 = θ*1+(1-θ)*3 \end{cases}\ \ \ \ \ θ∈[0,1] {x1=θ∗5+(1−θ)∗2x2=θ∗1+(1−θ)∗3 θ∈[0,1],则:
如果将点A看成向量a,点B看成向量b,则线段AB的向量表示为: x → = θ a → + ( 1 − θ ) ∗ b → , θ ∈ [ 0 , 1 ] \overrightarrow{x} = θ\overrightarrow{a} + (1-θ)*\overrightarrow{b}, \ \ \ θ∈[0,1] x=θa+(1−θ)∗b, θ∈[0,1];
而直线的向量表示是: x → = θ a → + ( 1 − θ ) ∗ b → , θ ∈ R \overrightarrow{x} = θ\overrightarrow{a} + (1-θ)*\overrightarrow{b}, \ \ \ θ∈R x=θa+(1−θ)∗b, θ∈R;
由此衍生推广到高维,可得以下几何体的向量表示,三角形的向量表示: x → = θ 1 a 1 → + θ 2 a 2 → + θ 3 a 3 → , θ i ∈ [ 0 , 1 ] & ∑ θ i = 1 \overrightarrow{x} = θ_1\overrightarrow{a_1} + θ_2\overrightarrow{a_2} + θ_3\overrightarrow{a_3}, \ \ \ θ_i∈[0,1]\ \& \ \sumθ_i=1 x=θ1a1+θ2a2+θ3a3, θi∈[0,1] & ∑θi=1;
三维平面的向量表示: x → = θ 1 a 1 → + θ 2 a 2 → + θ 3 a 3 → , θ i ∈ R & ∑ θ i = 1 \overrightarrow{x} = θ_1\overrightarrow{a_1} + θ_2\overrightarrow{a_2} + θ_3\overrightarrow{a_3}, \ \ \ θ_i∈R\ \& \ \sumθ_i=1 x=θ1a1+θ2a2+θ3a3, θi∈R & ∑θi=1;
超几何体的向量表示: x → = θ 1 a 1 → + θ 2 a 2 → + … + θ k a k → , θ i ∈ [ 0 , 1 ] & ∑ θ i = 1 \overrightarrow{x} = θ_1\overrightarrow{a_1} + θ_2\overrightarrow{a_2} +…+ θ_k\overrightarrow{a_k}, \ \ \ θ_i∈[0,1]\ \& \ \sumθ_i=1 x=θ1a1+θ2a2+…+θkak, θi∈[0,1] & ∑θi=1;
超平面的向量表示: x → = θ 1 a 1 → + θ 2 a 2 → + … + θ k a k → , θ i ∈ R & ∑ θ i = 1 \overrightarrow{x} = θ_1\overrightarrow{a_1} + θ_2\overrightarrow{a_2} +…+ θ_k\overrightarrow{a_k}, \ \ \ θ_i∈R\ \& \ \sumθ_i=1 x=θ1a1+θ2a2+…+θkak, θi∈R & ∑θi=1;
6.2 凸集 Convex Set
集合C内任意两点间的线段也均在集合C内,则称集合C为凸集,反之为凹集。数学定义为:
∀ x 1 , x 2 ∈ C , ∀ θ ∈ [ 0 , 1 ] , 则 x = θ ⋅ x 1 + ( 1 − θ ) ⋅ x 2 ∈ C \forall{x_1,x_2\in C},\ \forall{θ\in [0,1]},则x = θ·x_1+(1-θ)·x_2\in C ∀x1,x2∈C, ∀θ∈[0,1],则x=θ⋅x1+(1−θ)⋅x2∈C
推广到k个点,即:
∀ x 1 , x 2 , … , x k ∈ C , ∀ θ i ∈ [ 0 , 1 ] 且 ∑ i = 1 k θ i = 1 , 则 x = ∑ i = 1 k θ i ⋅ x i ∈ C \forall{x_1,x_2,…,x_k\in C},\ \forall{θ_i\in [0,1]}且\sum^k_{i=1}θ_i=1,则x = \sum^k_{i=1}θ_i·x_i\in C ∀x1,x2,…,xk∈C, ∀θi∈[0,1]且i=1∑kθi=1,则x=i=1∑kθi⋅xi∈C
上面凸集定义中便用到了线段的向量表示,含义是如果点x1和点x2在集合C内,则线段x1x2上所有点都在集合c内,凸集的交集仍是凸集,下面展示几个凸集示例:
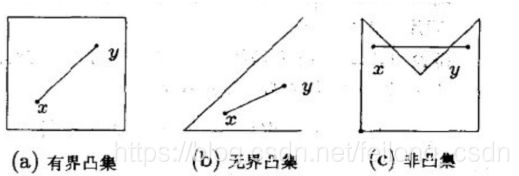
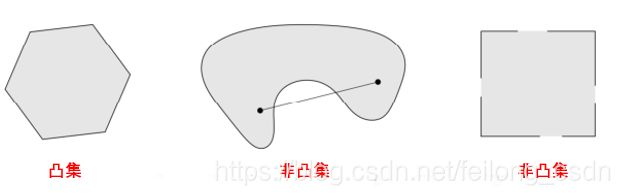
6.3 凸函数 Convex Function
对于凸集D,函数 f : D → ( − ∞ , ∞ ] f:D→(-∞,∞] f:D→(−∞,∞],对于任意的 X 1 ∈ D , X 2 ∈ D X_1\in D,X_2\in D X1∈D,X2∈D,
- λ ∈ [ 0 , 1 ] λ\in [0,1] λ∈[0,1],如果恒有 f ( λ X 1 + ( 1 − λ ) X 2 ) ≤ λ f ( X 1 ) + ( 1 − λ ) f ( x 2 ) f(λX_1+(1-λ)X_2) ≤ λf(X_1)+(1-λ)f(x_2) f(λX1+(1−λ)X2)≤λf(X1)+(1−λ)f(x2),则函数 f ( x ) f(x) f(x)为凸集D上的凸函数Convex Function;
- λ ∈ ( 0 , 1 ) λ\in (0,1) λ∈(0,1),如果恒有 f ( λ X 1 + ( 1 − λ ) X 2 ) < λ f ( X 1 ) + ( 1 − λ ) f ( x 2 ) f(λX_1+(1-λ)X_2) < λf(X_1)+(1-λ)f(x_2) f(λX1+(1−λ)X2)<λf(X1)+(1−λ)f(x2),则函数 f ( x ) f(x) f(x)为凸集D上的严格凸函数;
- 强凸函数定义如下:凸优化理论(2)。
直观理解如下:
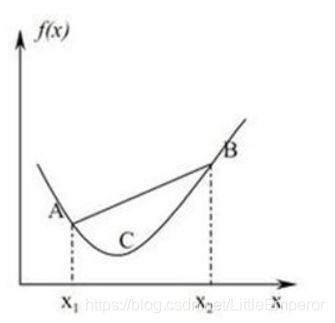
AB连线 λ f ( X 1 ) + ( 1 − λ ) f ( x 2 ) λf(X_1)+(1-λ)f(x_2) λf(X1)+(1−λ)f(x2)上的点大于等于 [ x 1 , x 2 ] [x_1,x_2] [x1,x2]之间的 f ( x ) f(x) f(x)。
例如:
f ( x ) = x 3 f(x)=x^3 f(x)=x3不是凸函数;
f ( x ) = x f(x)=x f(x)=x是凸函数,不是严格凸函数,不是强凸函数;
f ( x ) = e x f(x)=e^x f(x)=ex是凸函数,严格凸函数,不是强凸函数,因为 l i m x → − ∞ f ′ ′ ( x ) = 0 lim_{x→-∞}f''(x)=0 limx→−∞f′′(x)=0;
f ( x ) = x 2 f(x)=x^2 f(x)=x2是凸函数,严格凸函数,强凸函数。
凸函数的一阶条件和二阶条件,可见:凸优化学习(三)。
凸函数各种性质及其证明,可见:一文详解凸函数和凸优化。其性质包括:
- 性质1:设 f ⊆ R n → R 1 f ⊆ R^n → R^1 f⊆Rn→R1, C C C是凸集,若 f f f是凸函数,则对于 ∀ β ∀β ∀β,证明水平集 D β = { x ∣ f ( x ) ≤ β , x ∈ C } D_β=\{x|f(x)≤\beta,x\in C\} Dβ={x∣f(x)≤β,x∈C}是凸集;
- 性质2:凸优化问题的局部极小值是全局极小值;
- 性质3:凸函数其Hessian矩阵半正定;
- 性质4:若 x ⊆ R n , y ⊆ R n x ⊆ R^n,y⊆ R^n x⊆Rn,y⊆Rn, Q Q Q为半正定对称阵,证明 f ( x ) = X T Q X f(x) = X^TQX f(x)=XTQX为凸函数;
- ……
6.4 凸优化 Convex Optimization
一个凸优化问题在一个最优化问题中的形式如下:
m i n i m i z e f ( x ) s u b j e c t t o x ∈ C minimize\ f(x)\\ subject\ to\ x\in C minimize f(x)subject to x∈C
其中 f f f为凸函数, C C C为凸集, x x x为优化变量。然而,由于这样写可能有点不清楚,我们通常把它写成:
m i n i m i z e f ( x ) s u b j e c t t o g i ( x ) ≤ 0 , i = 1 , 2 , … , m h i ( x ) = 0 , i = 1 , 2 , … , p minimize\ f(x)\\ subject\ to\ g_i(x)≤0,\ i=1,2,…,m\\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ h_i(x)=0,\ i=1,2,…,p minimize f(x)subject to gi(x)≤0, i=1,2,…,m hi(x)=0, i=1,2,…,p
其中 f f f为凸函数, g i g_i gi为凸函数(凸函数 g i g_i gi必须小于零), h i h_i hi为仿射函数, x x x为优化变量。
仿射集(Affine set):仿射集是包含过两个不同的点的直线的所有点(所有的仿射集都可以用线性方程组的解集表示),即: x = θ x 1 + ( 1 − θ ) x 2 , ( θ ∈ R ) x=θx_1+(1−θ)x_2,\ \ (θ∈R) x=θx1+(1−θ)x2, (θ∈R),如下图:

通过以下凸优化性质便可理解何为凸优化问题:
- 目的是求解目标函数的最小值;
- 目标函数 f ( x ) f(x) f(x)和不等式约束函数 g i ( x ) g_i(x) gi(x)都是凸函数,定义域/可行域是凸集;
- 若存在等式约束函数,则等式约束函数 h i ( x ) h_i(x) hi(x)为仿射函数;仿射函数指的是最高次数为1的多项式函数,一般形式为 f ( x ) = A x + b f(x)= Ax + b f(x)=Ax+b, A A A是 m × k m×k m×k矩阵, x x x是一个 k k k向量, b b b是一个 m m m向量;
- 凸优化问题有一个良好的性质即:局部最优解便是全局最优解。
注意这些不等式的方向很重要:凸函数 g i ( x ) g_i(x) gi(x)必须小于零。这是因为 g i ( x ) g_i(x) gi(x)的 0 − s u b l e v e l 0-sublevel 0−sublevel集是一个凸集,所以可行域是许多凸集的交集,其也是凸集。如果我们要求某些凸函数 g i ( x ) g_i(x) gi(x)的不等式为 g i ( x ) ≥ 0 g_i(x)≥ 0 gi(x)≥0,那么可行域将不再是一个凸集,我们用来求解这些问题的算法也不再保证能找到全局最优解。
还要注意,只有仿射函数才允许为等式约束。直觉上来说,你可以认为一个等式约束 h i ( x ) = 0 h_i(x)=0 hi(x)=0等价于两个不等式约束 h i ( x ) ≤ 0 h_i(x)≤0 hi(x)≤0和 h i ( x ) ≥ 0 h_i(x)≥0 hi(x)≥0。然而,当且仅当 h i ( x ) h_i(x) hi(x)同时为凸函数和凹函数时,这两个约束条件才都是有效的,因此 h i ( x ) h_i(x) hi(x)一定是仿射函数。
优化问题的最优值表示成 p ∗ p^* p∗(有时表示为 f ∗ f^* f∗),并且其等于目标函数在可行域内的最小可能值。
p ∗ = m i n { f ( x ) : g i ( x ) ≤ 0 , i = 1 , 2 , … , m ; h i ( x ) = 0 , i = 1 , 2 , … , p } p^* = min\{f(x):g_i(x)≤0,\ i=1,2,…,m;\ h_i(x)=0,i=1,2,…,p\} p∗=min{f(x):gi(x)≤0, i=1,2,…,m; hi(x)=0,i=1,2,…,p}
当 f ( x ∗ ) = p ∗ f ( x^∗ ) = p^∗ f(x∗)=p∗时,我们称 x ∗ x^* x∗是一个最优点(optimal point)。 注意,即使最优值是有限的,也可以有多个最优点。
6.5 常见凸优化问题(凸问题的特殊情况)
由于各种原因,通常考虑一般凸规划公式的特殊情况比较方便。对于这些特殊情况,我们通常可以设计出非常高效的算法来解决非常大的问题,正因为如此,当人们使用凸优化技术时,你可能会看到这些特殊情况:
- 线性规划(linear program,LP):
- 如果目标函数 f ( x ) f(x) f(x)和不等式约束都 g i ( x ) g_i(x) gi(x)是仿射函数,那么凸优化问题就是一个线性规划问题。换句话说,这些问题都有如下形式:

- 其中, x ∈ R n x ∈ R^n x∈Rn是优化变量, c ∈ R n , d ∈ R , G ∈ R m × n , h ∈ R m , A ∈ R p × n , b ∈ R c ∈ R^n , d ∈ R , G ∈ R^{m × n} , h ∈ R^m , A ∈ R^{p × n} , b ∈ R c∈Rn,d∈R,G∈Rm×n,h∈Rm,A∈Rp×n,b∈R这些变量根据具体问题具体定义,符号 ⪯ ⪯ ⪯代表(多维向量中)各个元素不相等。
- 二次规划(quadratic program,QP):
- 如果不等式约束(跟线性规划)一样是仿射的,而目标函数 f ( x ) f(x) f(x)是凸二次函数,则凸优化问题是一个二次规划 问题。换句话说,这些问题都有如下形式:
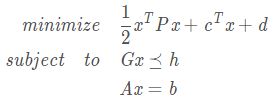
- 变量解释如上,根据具体问题具体定义,还有一个对称半正定矩阵 P ∈ R + n P ∈ R_+^n P∈R+n。
- 二次约束二次规划(quadratically constrained quadratic program,QCQP):
- 如果目标函数 f ( x ) f(x) f(x)和不等式约束条件都 g i ( x ) g_i(x) gi(x)是凸二次函数,那么凸优化问题就是一个二次约束的二次规划问题,形式如下:
- 变量解释同二次规划,与之不同的是这里还有 Q i ∈ S + n , r i ∈ R n , s i ∈ R Q_i ∈ S_+^n , r_i ∈ R^n , s_i ∈ R Qi∈S+n,ri∈Rn,si∈R,其中$i = 1 , 2, . . . , m $。
- 半定规划(Semidefinite Programming,SDP):
- 最后一个示例比前面的示例更复杂,所以如果一开始不太理解也不要担心。但是,半定规划在机器学习许多领域的研究中正变得越来越流行,所以你可能在以后的某个时候会遇到这些问题,所以提前了解半定规划的内容还是比较好的。
- 我们说一个凸优化问题是半定规划(SDP) 的,则其形式如下所示:
- 其中对称矩阵 X ∈ S n X\in S^n X∈Sn是优化变量,对称矩阵 C , A 1 , ⋯ , A p ∈ S n C,A_1,\cdots,A_p\in S^n C,A1,⋯,Ap∈Sn根据具体问题具体定义,限制条件 X ⪰ 0 X\succeq 0 X⪰0意味着 X X X是一个半正定矩阵。
- 以上这些看起来和我们之前看到的问题有点不同,因为优化变量现在是一个矩阵而不是向量。如果你好奇为什么这样的公式可能有用,你应该看看更高级的课程或关于凸优化的书。
从定义可以明显看出,二次规划比线性规划更具有一般性(因为线性规划只是 P = 0 P = 0 P=0时的二次规划的特殊情况),同样,二次约束二次规划比二次规划更具有一般性。然而,不明显的是,半定规划实际上比以前的所有类型都更一般,也就是说,任何二次约束二次规划(以及任何二次规划或线性规划)都可以表示为半定规划。
到目前为止,我们已经讨论了凸优化背后大量枯燥的数学以及形式化的定义。接下来,我们终于可以进入有趣的部分:使用这些技术来解决实际问题,详情可见:凸优化学习(四)——凸优化问题。
对偶性、KKT 条件、敏感性分析的相关内容可见:凸优化学习笔记:对偶性、KKT 条件、敏感性分析。
凸优化的优化算法可见:凸优化算法、无约束优化算法、有约束优化算法、无约束凸优化问题的求解算法。
7. 优化算法
本节参考内容:一文看懂各种神经网络优化算法、神经网络的优化算法有哪些、从SGD到AdamW原理和代码解读、神经网络中常用的优化算法、PyTorch的十个优化器。
本节主要以PyTorch中torch.optim中支持的13种优化器为基础,再加上必要的拓展来进行梳理与了解。但因为在写之前具体看过了一些优化器的原理,比较繁琐,这里可能仅会做一个列举和介绍,具体的原理内容只将连接贴出来。
在机器学习中,为了优化目标函数,就需要设计合适的优化算法,来即准确又有效率的实现最优化。优化算法的功能,是通过改善训练方式,来最小化(或最大化)损失函数E(x)。常用的有一阶优化算法梯度下降法,二阶的优化算法有牛顿法等。其体系如下(可见概览优化算法):
优化算法分为两大类:
- 一阶优化算法:这种算法使用各参数的梯度值来最小化或最大化损失函数E(x)。最常用的一阶优化算法是梯度下降。因此,对单变量函数,使用导数来分析;而梯度是基于多变量函数而产生的。
- 二阶优化算法:二阶优化算法使用了二阶导数(也叫做Hessian方法)来最小化或最大化损失函数。由于二阶导数的计算成本很高,所以这种方法并没有广泛使用。
- 牛顿法就是一种二阶优化算法:和梯度下降法相比,两者都是迭代求解,不过梯度下降法是梯度求解(一阶优化),而牛顿法是用二阶的海森矩阵的逆矩阵求解。相对而言,使用牛顿法收敛更快(迭代更少次数),但是每次迭代的时间比梯度下降法长(计算开销更大,实际常用拟牛顿法替代);
- 拟牛顿法的代表算法有DFP算法和BFGS算法,其中torch.optim中的**LBFGS(Limited-memory Broyden–Fletcher–Goldfarb–Shanno,L-BFGS)算法是在BFGS**的基础上进一步在有限的内存下进行近似而提高效率的算法,其特点是节省内存,具体介绍可见:一文读懂L-BFGS算法。
而对于神经网络,特别深度神经网络,由于其结构复杂,参数众多等等,但其所广泛应用的(比如从SGD到Adam这种)优化器都属于梯度下降法的不同优化方法。
7.1 传统的梯度下降法
这一部分有:批量梯度下降算法(Batch Gradient Descent)、小批量梯度下降算法(Mini Batch Gradient Descent)、随机梯度下降算法(Stochastic Gradient Descent,SGD)和随机平均梯度下降(Averaged Stochastic Gradient Descent,ASGD/SAG)。部分应该是有在之前的学习中就提到过的,具体可见:神经网络优化算法。
但使用梯度下降也会面临一些挑战:
- 很难选择出合适的学习率。太小的学习率会导致网络收敛过于缓慢,而学习率太大可能会影响收敛,并导致损失函数在最小值上波动,甚至出现梯度发散。
- 此外,相同的学习率并不适用于所有的参数更新。如果训练集数据很稀疏,且特征频率非常不同,则不应该将其全部更新到相同的程度,但是对于很少出现的特征,应使用更大的更新率。
- 在神经网络中,最小化非凸误差函数的另一个关键挑战是避免陷于多个其他局部最小值中。实际上,问题并非源于局部极小值,而是来自鞍点,即一个维度向上倾斜且另一维度向下倾斜的点。这些鞍点通常被相同误差值的平面所包围,这使得SGD算法很难脱离出来,因为梯度在所有维度上接近于零。
可以先提前看一下SGD与其他优化器的对比动图,最后一个没有脱离局部最优的就是SGD:
因此,我们需要对梯度下降做进一步优化。而优化算法的改进无非两个方向:① 更准确的梯度方向(加入动量);② 自适应的学习率(加入衰减率)。
7.2 基于动量的梯度下降
首先是基于动量的方法(Momentum):其思想很简单,就是对SGD优化时,高频微小的波动进行平滑,从而加速优化过程。方法就来源于物理中的动量,将参数的优化过程中,累计了一定的动能,因此不容易改变更新的方向,最终的更新方向和大小是由过去的梯度和当前梯度共同决定的。
就好比一个小球在向下滚动的过程中(即参数优化的过程),如果遇到平坦的地方,不会马上停下来,而是还会向前继续滚动。Momentum的方法不仅有助于加快学习速度,也可以有效避免落入局部最优点如鞍点。比如:SGDM(SGD with Momentum,带动量的随机梯度下降)。
但是基于动量的更新方式,容易错过最优点,因为其动能会导致其在最优点附近反复的震荡,甚至直接越过最优点。因此人们又提出了改进的方法就是Nesterov梯度加速法(Nesterov Accelerated Gradient,NAG)。
其改进的地方就是,在Momentum的基础上,让小球先试探性地,靠着已有的动能向前一动一步,然后计算出移动后的梯度,用这个梯度来更新当前的参数。从而使得小球拥有了提前感知周围环境的信息。这样靠近最优点的时候,就能让小球放慢速度。
7.3 基于自适应学习率的梯度下降
因为不同的参数,其重要性和每次更新幅度不同。对于不常变化的参数,需要其学习率大一些,能够从个别样本中学习到更多的信息;而对于频繁更新变化的参数,已经积累了大量关于样本的信息,不希望它对单个样本过于敏感,因此希望更新幅度小一些。
最经典的就是**AdaGrad(Adaptive Gradient,自适应梯度算法)**,利用了历史梯度的平方和(即二阶动量,用来度量历史更新频率),来调整合适的学习率η,对稀疏参数进行大幅更新和对频繁参数进行小幅更新。
但是AdaGrad有一个缺陷就是随着Vt逐步累积增大,会导致学习率越来越小,最终停止更新。因此又提出了一些改进的方法:
-
AdaDelta(自适应学习率调成),考虑一个改变二阶动量计算方法的策略(基本思想是用一阶的方法,近似模拟二阶牛顿法):不累积全部历史梯度,而只关注过去一段时间窗口的下降梯度(这也就是AdaDelta名称中Delta的来历);
-
RMSprop(均方根反向传播),对AdaGrad中对之前梯度的权重是相同的改进,引入指数加权平均,即给予更接近当前梯度的梯度更大的权重(RMS是均方根root meam square的意思),与AdaDelta是很相似。
RMSProp也是**RProp(弹性反向传播)算法**的改进,两者介绍及对比可见:弹性反向传播(RProp)和均方根反向传播(RMSProp)。
7.4 融合动量与自适应学习率的方法
SGD-M在SGD基础上增加了一阶动量,AdaGrad和AdaDelta在SGD基础上增加了二阶动量。把一阶动量和二阶动量都用起来,就是**Adam(Adaptive Moment Estimation,自适应动量估计)算法**了 —— Adaptive + Momentum(也可以被认为是Momentum+RMSProp)。
- SparseAdam是torch.optim中针对稀疏张量的一种“阉割版”Adam优化方法。
但是,Adams可能不收敛以及可能错失全局最优解的缺点使得大家一直在进行着Adams变体方法改进的研究。主要有以下几种(大致按照出现先后顺序):
- Adamax:对Adam增加了一个学习率上限的概念,所以也称之为Adamax;
- NAdam:Nesterov + Adam = Nadam;
- ⭐**AdamW**:Adam+L2正则化,是目前收敛最快、在实践应用中较优的优化器(BERT中用的就是AdamW);
- 与之对应的,SGDM加入L2正则化后就是SGDWM算法。
- AMSGrad:在torch.optim中,可以通过Adam的参数
amsgrad=True来开启采用AMSGrad算法。AMSGrad算法是针对Adam的改进,通过添加额外的约束,使学习率始终为正值(好像实验效果并不理想); - RAdam(Rectified Adam):“整流版的Adam”(Rectified Adam),它能根据方差分散度,动态地打开或者关闭自适应学习率,并且提供了一种不需要可调参数学习率预热的方法(详情可见论文:RAdam,不过知乎上也有人说效果一般)。
- 此外看到的还有AdaBound、PAdam、ZO-AdaMM、AdaShift、ACProp……但torch里好像就没有封装了。
Adam和SGDM作为当今最优秀的两种深度学习优化器,分别在效率和精度上有着各自的优势,Adam在前期优化速度较快,SGDM在后期优化精度较高。因此,有一种思路就是:在前期使用Adam算法,后期使用SGDM算法。比如:SWATS)(Switching from Adam to SGD)算法。
7.5 其他改进方法
- Warm up预热机制
Warm up是在ResNet论文中提到的一种学习率预热的方法,它在训练开始的时候先选择使用一个较小的学习率,训练了一些steps(15000steps,见最后代码1)或者epoches(5epoches,见最后代码2)之后,再修改为预先设置的学习来进行训练。
Warm up的意义在于,在模型训练的初始阶段:该模型对数据还很陌生,需要使用较小的学习率慢慢学习,不断的修正权重分布,如果一开始就使用很大的学习率,方向正确了影响还不大,但是一旦训偏了,可能后续需要很多个epoch才能拉回来,甚至拉不回来,直接导致过拟合。当使用较小的学习率学习了一段时间后,模型已经把每批数据都看个几遍了,形成了一些先验知识,这时候就可以使用较大的学习率加速学习,前面学习到的先验知识可以使模型的方向正确。
上述的Warmup是Constant Warm up,它的不足之处在于从一个很小的学习率一下变为比较大的学习率可能会导致训练误差突然增大。于是18年Facebook提出了Gradual Warm up来解决这个问题,即从最初的小学习率开始,每个step增大一点点,直到达到最初设置的比较大的学习率时,采用最初设置的学习率进行训练。
相关了解的文章可见:pytorch之warm-up预热学习策略、【调优方法】——warmup、学习率预热Warmup。
在torch应用时,主要通过学习率调节器
lr_scheduler来实现,方法可见:PyTorch 源码解读之 torch.optim:优化算法接口详解、pytorch之warm-up预热学习策略。
- Lookahead(k step forward,1 step back)
Lookahead(k step forward,1 step back)本质上是一种在各种优化器上层的一种优化器方法,内部可以使用任何形式的优化器,用作者的话说就是:universal wrapper for all optimizers。
Lookahead指的是:每使用优化器向前走k步,就对当前的第1步和第k步做一个加权平均(忽略中间的k-2步);以下图为例,蓝色线是优化器走的k步路径,然后将蓝线的起始点连接(图中红线),然后在红线上取一点作为k+1步的值(根据 α 而定)。
Lookahead起作用的原因:
- 标准优化方法通常需要谨慎调整学习率,以防止振荡和收敛速度过慢,这在 SGD 设置中更加重要。而 Lookahead 能借助较大的内部循环学习率减轻这一问题;
- 当 Lookahead 向高曲率方向振荡时,fast weights 更新在低曲率方向上快速前进,slow weights 则通过参数插值使振荡平滑。fast weights 和 slow weights 的结合改进了高曲率方向上的学习,降低了方差,并且使得 Lookahead 在实践中可以实现更快的收敛;
- 另一方面,Lookahead 还能提升收敛效果。当 fast weights 在极小值周围慢慢探索时,slow weight 更新促使 Lookahead 激进地探索更优的新区域,从而使测试准确率得到提升。这样的探索可能是 SGD 更新 20 次也未必能够到达的水平,因此有效地提升了模型收敛效果。
相关了解的文章可见:全新优化方法Lookahead、优化算法:《Lookahead Optimizer: k steps forward, 1 step back》。
8. 过拟合与欠拟合
过拟合与欠拟合的含义基本都知道,其解决办法其实在之前的文章也有提到过,这里做一个汇总。
8.1 缓解欠拟合
- 特征工程:欠拟合是由于学习不足,可以考虑添加特征,从数据中挖掘出更多的特征,有时候还需要对特征进行变换,使用组合特征、高次特征、添加多项式特征……;
- 模型复杂化:模型简单也会导致欠拟合,例如线性模型只能拟合一次函数的数据。尝试使用更高级的模型/非线性模型有助于解决欠拟合,如使用SVM,神经网络等;
- 正则化:正则化参数是用来防止过拟合的,出现欠拟合的情况就要考虑减少正则化参数;
- 调整超参:超参数包括:
- 神经网络中:学习率、学习衰减率、隐藏层数、隐藏层的单元数、Adam优化算法中的β1β1和β2β2参数、batch_size数值等;
- 其他算法中:随机森林的树数量,k-means中的cluster数,正则化参数λ等。
- 增加训练数据往往没有用:欠拟合本来就是模型的学习能力不足,增加再多的数据给它训练它也没能力学习好;
- 集成学习:使用集成学习方法,如将多个弱学习器进行Bagging等。
8.2 缓解过拟合
- 交叉检验:通过交叉检验得到较优的模型参数;
- 早停策略:本质上是交叉验证策略,选择合适的训练次数,避免训练的网络过度拟合训练数据;
- 集成学习:将多个弱学习器Bagging一下效果会好很多;
- 特征工程:减少特征数或使用较少的特征组合,对于按区间离散化的特征,增大划分的区间;
- 正则化:常用的有 L1、L2 正则(L1正则还可以自动进行特征选择),如果已有正则项则可以考虑增大正则项参数;
- 简化模型:对于线性回归我们可以降低多项式的次数,对于神经网络我们可以减少隐藏层层数,节点数等,对于决策树,我们可以进行剪枝操作等;
- 数据集扩增:增加训练数据量,提高模型的泛化能力;或者增加噪声数据,提升模型的鲁棒性;
- 重采样:根据当前数据集估计数据分布参数,使用该分布产生更多数据等;
- DropOut策略:在用前向传播算法和反向传播算法训练DNN模型时,一批数据迭代时,随机的从全连接DNN网络中去掉一部分隐藏层的神经元;
- BN:一种归一化方法,每个隐层都进行归一化,使每一层神经网络的输入保持相同分布的,将输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。