卷积神经网络学习笔记—— Pytorch & CNN & trick(持续更新)
目录
Trick
不增加计算损耗的trick(Bag of freebies)
仅增加微小的计算损耗的trick(Bag of specials)
issue
性能评价指标
物体检测:
混淆矩阵(confusion matrix)
Precision&recall
AP(average precision)
mAP(mean average precision)
语义分割:
(1)像素准确率(Pixel Accuracy,PA)
(2)类别平均像素准确率(Mean Pixel Accuracy,MPA)
(3)交并比(Intersection over Union,IoU)
(4)平均交并比(Mean Intersection over Union,MIoU)
(5)频权交并比(Frequency Weighted Intersection over Union)FWIoU
(6)DICE系数
注意力机制
注意力机制的使用
特征融合
增强感受野
1、SPP(Spatial Pyramid Pooling)
2、ASPP(Atrous Spatial Pyramid Pooling)
3、RFB(Receptive Field Block)
计算机视觉中的多尺度模型架构
多尺度特征融合
(1) 并行多分支结构
(2) 串行多分支结构
目标检测篇
1. YOLOv5 -v5
网络结构
网络训练
语义分割篇
一、PSPnet
Pytorch学习笔记
下述参考仅供学习,如有侵权,请联系删除谢谢!
Trick
论文阅读笔记(YOLOv4之trick总结)(1) - 知乎
-
不增加计算损耗的trick(Bag of freebies)
- 像素级数据增强(亮度、对比度、色彩、饱和度、噪声;随机尺度、裁剪、翻转、旋转)
- 模拟目标遮挡(Random Erase、Cutout、Hide-and-seek、Grid-mask;Dropout、DropConnect、DropBlock)
- 使用多张图混合增强(Mixup、CutMix)
- 样本不平衡问题(困难样本挖掘(HEM、OHEM)、Focalloss)
- Onehot类标无法表示各类之间关系(Labelsmooth、Label refinement network)
- 边框回归损失函数(IoU、GIoU、DIoU、CIoU loss)
-
仅增加微小的计算损耗的trick(Bag of specials)
- 增强感受野(SPP、ASPP、RFB、PPM)
- 注意力机制(SE、SAM)
- 特征融合(SFAM、ASFF、BiFPN)
- 激活函数(LReLU、PReLU、ReLU6、Scaled Exponential Linear Unit(SELU)、Swish、hard-Swish、Mish)
- 非极大值抑制(GreedyNMS、softNMS、DIoUNMS)
- 标准化方法(BN、CGBN、FRN、CBN)
issue
既然准确率和损失都是评价模型好坏的,那么用一个不行吗?为什么要用两个并不完全等价的评价指标呢?
这是因为,在分类问题中,可能准确率更加的直观,也更具有可解释性,更重要,但是它不可微,无法直接用于网络训练,因为反向传播算法要求损失函数是可微的。而损失函数一个很好的性质就是可微,可以求梯度,运用反向传播更新参数。即首选损失不能直接优化(比如准确率)时,可以使用与真实度量类似的损失函数。 损失函数的可微性,使得可以采用多种方式进行优化求解,例如牛顿法、梯度下降法、极大似然估计等。另外在分类任务中,使用accuracy可以,但是在回归任务中,accuracy便不再可用,只能使用loss。
性能评价指标
深度学习常见任务的一些评价指标总结(如图像分类,目标检测,图像分割等) - 知乎
物体检测:
混淆矩阵(confusion matrix)
图像分类任务中,选择混淆精度这一指标的策略如下。
优点:清晰易懂且直观,为后续的其它指标提供了计算依据(如TP,TN,FP,FN等)。
缺点:对于不平衡数据集(即正负样本的比例相差很大时),混淆矩阵的效果可能不好。
使用情况:一般需要对分类的具体类别做结果分析时会使用此指标,并且如果想得到进一步的指标如PR曲线,ROC曲线等,也需要计算混淆矩阵指标。
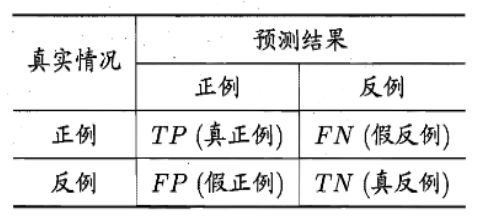
二分类混淆矩阵
Precision&recall
Precision和recall都很高,模型查的既准、又全!
Precision决定了预测出来为正样本的结果中,有多少是正确分类

Recall 决定了检测的目标中是否包括了全部的目标(正样本),值越大那么检测到目标的性能越好。

AP(average precision)
就是Precision-recall 曲线下围成的面积,通常来说一个越好的分类器,AP值越高。

mAP(mean average precision)
是多个类别AP的平均值。
语义分割:
图像语义分割中的评价指标标准通常是像素精度及IoU的变种。为便于解释,假设如下:共有k+1个类(从L0到Lk,其中包含一个空类或背景),Pij表示本属于类i但被预测为类j的像素数量。即Pii表示真正的数量,而Pij和Pji则分别被解释为假正和假负。并且下面以一个图示的方法来展示在分割图中TP/TN/FP/FN等概念。

GT分割图与预测分割图
在上图中,左侧是GT,右侧是Prediction,即预测的掩码图。Prediction图被分成四个部分,其中大块的白色斜线标记的是true negative(TN,预测中真实的背景部分),红色线部分标记是false negative(FN,预测中被预测为背景,但实际上并不是背景的部分),蓝色的斜线是false positive(FP,预测中分割为某标签的部分,但是实际上并不是该标签所属的部分),中间荧光黄色块就是true positive(TP,预测的某标签部分,符合真值)。

GT分割图与预测分割图的交集和并集
在上图中,左侧是GT,右侧是Prediction,即预测的掩码图。左侧是预测掩码图和真值掩码图的交集,右侧是预测掩码图和真值掩码图的并集。
(1)像素准确率(Pixel Accuracy,PA)
像素准确率的含义是预测类别正确的像素数占总像素数的比例。它对应上述的准确率(Accuracy),计算公式如下:
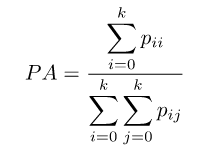
(2)类别平均像素准确率(Mean Pixel Accuracy,MPA)
类别平均像素准确率(mean pixel accuracy)简称MPA,它表示的意义是分别计算每个类被正确分类像素数的比例,然后累加求平均。

(3)交并比(Intersection over Union,IoU)
交并比表示的含义是模型对某一类别预测结果和真实值的交集与并集的比值。只不过对于目标检测而言是检测框和真实框之间的交并比,而对于图像分割而言是计算预测掩码和真实掩码之间的交并比。
计算公式:以计算二分类正例(类别1)的IoU为例。
交集为TP,并集为TP、FP、FN之和,那么IoU的计算公式如下。
![]()
转存失败重新上传取消
(4)平均交并比(Mean Intersection over Union,MIoU)
平均交并比(mean IOU)简称mIOU,即预测区域和实际区域交集除以预测区域和实际区域的并集,这样计算得到的是单个类别下的IoU,然后重复此算法计算其它类别的IoU,再计算它们的平均数即可。
它表示的含义是模型对每一类预测的结果和真实值的交集与并集的比值,之后求和再计算平均。
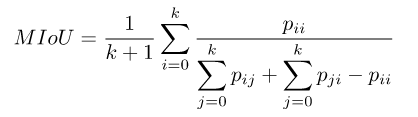
(5)频权交并比(Frequency Weighted Intersection over Union)FWIoU
频权交并比FWIoU是MIoU的一种提升,这种方法根据每个类出现的频率为其设置权重。
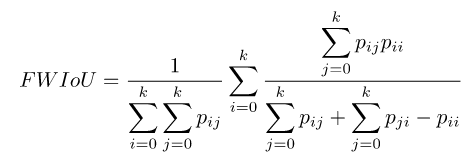
(6)DICE系数
DICE系数也是常用的分割评价标准之一,DICE系数的取值范围为0到1,越接近1说明构建的模型越好,分割的效果越好。DICE系数是像素级别的,真实的目标ground truth出现在某片区域X,模型预测结果的目标区域为Y,那么Dice系数公式如下图所示。

DICE系数计算公式
上图中,红色矩形块是GroundTruth(用X表示),绿色矩形框是预测的矩形框(用Y表示),它们之间的黄色交集区域是True Positive,剩余的绿色区域为False Positive,剩余的红色区域为False Negative。IOU的计算公式为:

因此可得IOU与DICE系数之间的关系为:
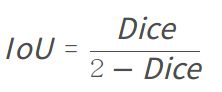
用法:
DICE系数常常应用在很多关于医学图像分割的竞赛、论文和项目中。DICE系数常用于构建DICE系数损失函数,公式如下。

Dice loss的优点:比较适用于样本极度不均的情况。
Dice loss的缺点:一般的情况下,使用 dice loss 会对反向传播造成不利的影响,容易使训练变得不稳定。
注意力机制
神经网络学习小记录64——Pytorch 图像处理中注意力机制的解析与代码详解_Bubbliiiing的博客-CSDN博客_pytorch图像处理
- 1、SENet的实现
- 2、CBAM的实现
- 3、ECA的实现
注意力机制的使用
注意力机制的基本思想和实现原理(很详细)_hpulfc的博客-CSDN博客_注意力机制实现
在对多尺度的特征图融合前施加注意力模型需要考虑深层的特征图的抽象性对注意力权重的影响
特征融合
由于CNN基本构建模块的特点,在最后输出的feature map往往是浓缩了大量的语义信息(“高级的特征”)但分辨率较低、对细节的保留较少,因此对于小目标的检测效果不尽如人意,且模型对检测对象的尺度不变性大部分也只能来自于训练数据。
几种检测的方法
(a).传统差分图像金字塔,抽值实现降采样
(b).深度学习经典做法,使用顶层feature map检测
(c).SSD的做法,利用深度网络提取feature并在每一层map上检测
(d).FPN做法,top-down融合并在不同的map上检测
FPN详解_技术挖掘者的博客-CSDN博客_fpn
SPPNet提出的空间金字塔池化通过对最后一层feature map执行stride大小不同的池化后再进行concatenate,能在一定程度上解决不同尺度物体的检测问题。但是仅仅使用了高级特征(或者说特征其实还是来自同一层),对于不同尺度的融合还是不太好。

SSD首先提出在Backbone的不同层输出进行检测,就是希望能同时利用不同层次的信息。但是对于多个feature map的检测也导致了效率的低下,并且低层的feature map能够提供的信息太少而直接检测的计算量又大(分辨率高),虽然对于不同尺度的物体检测能力略有提升,但是速度相对YOLO下降的比较多。
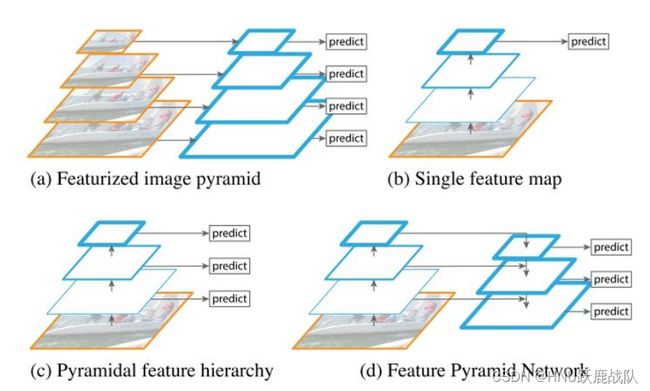
那么很自然的我们就会想到,有没有什么方法可以综合底层的细节和高层语义信息
增强感受野
1、SPP(Spatial Pyramid Pooling)
SPP模块是何凯明大神在2015年的论文《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》中被提出。
由于CNN网络后面接的全连接层需要固定的输入大小,故往往通过将输入图像resize到固定大小的方式输入卷积网络,这会造成几何失真影响精度。SPP模块就解决了这一问题,他通过三种尺度的池化,将任意大小的特征图固定为相同长度的特征向量,传输给全连接层。因为卷积层后面的全连接层的结构是固定的。但在现实中,我们的输入的图像尺寸总是不能满足输入时要求的大小,然而通常的手法就是裁剪(crop)和拉伸(warp),但这样做总归是不好的,其扭曲了原始的特征。而SPP层通过将候选区的特征图划分为多个不同尺寸的网格,然后对每个网格内都做最大池化,这样依旧可以让后面的全连接层得到固定的输入。

上图,将256 channels 的 feature map 作为输入,在SPP layer被分成1x1,2x2,4x4三个pooling结构,对每个输入都作max pooling(论文使用的),这样无论输入图像大小如何,出来的特征固定是(16+4+1)x256维度。这样就实现了不管图像中候选区域尺寸如何,SPP层的输出永远是(16+4+1) x 256 特征向量。
2、ASPP(Atrous Spatial Pyramid Pooling)
受到SPP的启发,语义分割模型DeepLabv2中提出了ASPP模块,该模块使用具有不同采样率的多个并行空洞卷积层。为每个采样率提取的特征在单独的分支中进一步处理,并融合以生成最终结果。该模块通过不同的空洞rate构建不同感受野的卷积核,用来获取多尺度物体信息,具体结构比较简单如下图所示:
ASPP(atrous spatial pyramid pooling)是在deeplab中提出来的,在后续的deeplab版本中对其做了改进,如加入BN层、加入深度可分离卷积等,但基本的思路还是没变。
讲到ASPP时,首先需要提到空洞卷积(Atrous/Dilated Convolution)。在于语义分割任务中,想要对图片提取的特征具有较大的感受野,并且又想让特征图的分辨率不下降太多(分辨率损失太多会丢失许多关于图像边界的细节信息),但这两个是矛盾(参考:卷积神经网络中感受野的详细介绍_Microstrong0305的博客-CSDN博客_感受野)的,想要获取较大感受野需要用较大的卷积核或池化时采用较大的strid,对于前者计算量太大,后者会损失分辨率。而空洞卷积就是用来解决这个矛盾的。即可让其获得较大感受野,又可让分辨率不损失太多。空洞卷积如下图:
(a)是rate=1的空洞卷积,卷积核的感受野为3×3,其实就是普通的卷积。
(b)是rate=2的空洞卷积,卷积核的感受野为7x7
(c)是rate=4的空洞卷积,卷积核的感受野为15x15
空洞卷积感受野的计算
空洞卷积感受野的大小分两种情况:
(1)正常的空洞卷积:
若空洞卷积率为dilate rate
则感受野尺寸= ( d i l a t e r a t e − 1 ) ∗ ( k − 1 ) + k (dilate rate-1)*(k-1)+k(dilaterate−1)∗(k−1)+k ( 其中 k为卷积核大小)
(2)padding的空洞卷积:
若空洞卷积率为dilate rate
则感受野尺寸=2 ( d i l a t e r a t e − 1 ) ∗ ( k − 1 ) + k 2(dilate rate-1)*(k-1)+k2(dilaterate−1)∗(k−1)+k ( 其中 k为卷积核大小)
进行分割任务时,图像存在多尺度问题,有大有小。一种常见的处理方法是图像金字塔,即将原图resize到不同尺度,输入到相同的网络,获得不同的feature map,然后做融合,这种方法的确可以提升准确率,然而带来的另外一个问题就是速度太慢。DeepLab v2为了解决这一问题,参考了SPP、PPM等引入了ASPP(atrous spatial pyramid pooling)模块,即是将feature map通过并联的采用不同膨胀速率的空洞卷积层用于捕获多尺度信息,并将输出结果融合得到图像的分割结果。如下图所示,这是在deeplab v3中改进后的ASPP。用了一个1×1的卷积和3个3×3的空洞卷积,每个卷积核有256个且都有BN层。事实上,1×1的卷积相当于rate很大的空洞卷积,因为rate越大,卷积核的有效参数就越小,这个1×1的卷积核就相当于大rate卷积核的中心的参数。
3、RFB(Receptive Field Block)
RFB模块是在(ECCV2018:Receptive Field Block Net for Accurate and Fast Object Detection)一文中提出的,该文的出发点是模拟人类视觉的感受野从而加强网络的特征提取能力,在结构上RFB借鉴了Inception的思想,主要是在Inception的基础上加入了空洞卷积,从而有效增大了感受野
RFB的效果示意图如所示,其中中间虚线框部分就是RFB结构。RFB结构主要有两个特点:
1、不同尺寸卷积核的卷积层构成的多分枝结构,这部分可以参考Inception结构。在Figure2的RFB结构中也用不同大小的圆形表示不同尺寸卷积核的卷积层。
2、引入了dilated卷积层,dilated卷积层之前应用在分割算法Deeplab中,主要作用也是增加感受野,和deformable卷积有异曲同工之处。
在RFB结构中用不同rate表示dilated卷积层的参数。结构中最后会将不同尺寸和rate的卷积层输出进行concat,达到融合不同特征的目的。结构中用3种不同大小和颜色的输出叠加来展示。最后一列中将融合后的特征与人类视觉感受野做对比,从图可以看出是非常接近的,这也是这篇文章的出发点,换句话说就是模拟人类视觉的感受野进行RFB结构的设计
如下图是两种RFB结构示意图。(a)是RFB,整体结构上借鉴了Inception的思想,主要不同点在于引入3个dilated卷积层(比如3×3conv, rate=1),这也是这篇文章增大感受野的主要方式之一。(b)是RFB-s。RFB-s和RFB相比主要有两个改进,一方面用3×3卷积层代替5×5卷积层,另一方面用1×3和3×1卷积层代替3×3卷积层,主要目的应该是为了减少计算量,类似Inception后期版本对Inception结构的改进。
【AI不惑境】深度学习中的多尺度模型设计 - 简书
计算机视觉中的多尺度模型架构
卷积神经网络通过逐层抽象的方式来提取目标的特征,其中一个重要的概念就是感受野。如果感受野太小,则只能观察到局部的特征,如果感受野太大,则获取了过多的无效信息,因此研究人员一直都在设计各种各样的多尺度模型架构,主要是图像金字塔和特征金字塔两种方案,但是具体的网络结构可以分为以下几种:(1) 多尺度输入。(2) 多尺度特征融合。(3) 多尺度特征预测融合。(4) 以上方法的组合。
多尺度特征融合
多尺度特征融合网络常见的有两种,第一种是并行多分支网络,第二种是串行的跳层连接结构,都是在不同的感受野下进行特征提取。
(1) 并行多分支结构
比如Inception网络中的Inception基本模块,包括有四个并行的分支结构,分别是1×1卷积,3×3卷积,5×5卷积,3×3最大池化,最后对四个通道进行组合。

除了更高卷积核大小,还可以使用带孔卷积来控制感受野。在图像分割网络Deeplab V3[2]和目标检测网络trident networks[3]中都使用了这样的策略,网络结构如下图:


还有一种比不同大小的卷积核和带孔卷积计算代价更低的控制感受野的方法,即直接使用不同大小的池化操作,被PSPNet[4]采用。
值得注意的是,这样的多分支结构对于模型压缩也是有益处的,以Big-little Net[5]为代表,它采用不同的尺度对信息进行处理。
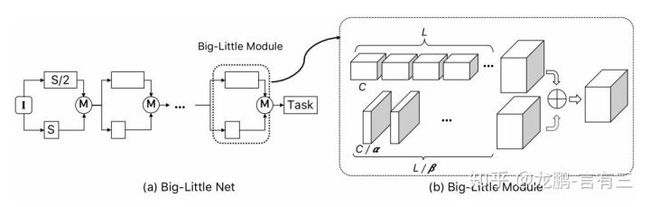
对于分辨率大的分支,使用更少的卷积通道,对于分辨率小的分支,使用更多的卷积通道,这样的方案能够更加充分地使用通道信息。
(2) 串行多分支结构
串行的多尺度特征结构以FCN[6],U-Net为代表,需要通过跳层连接来实现特征组合,这样的结构在图像分割/目标检测任务中是非常常见的。
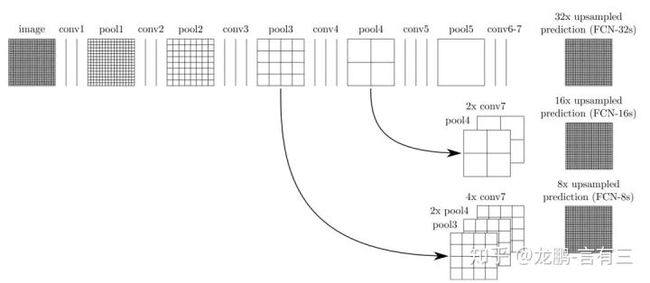
从上面这些模型可以看出,并行的结构能够在同一层级获取不同感受野的特征,经过融合后传递到下一层,可以更加灵活地平衡计算量和模型能力。串行的结构将不同抽象层级的特征进行融合,对于边界敏感的图像分割任务是不可缺少的。
目标检测篇
1. YOLOv5 -v5
网络结构
结构图参考:
YOLOv5网络详解_太阳花的小绿豆的博客-CSDN博客
睿智的目标检测56——Pytorch搭建YoloV5目标检测平台_Bubbliiiing的博客-CSDN博客

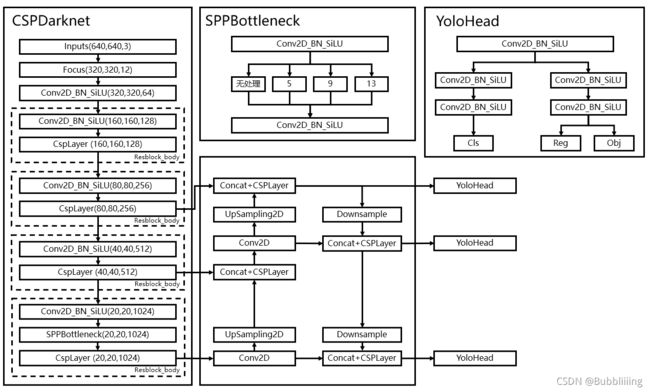
Backbone网络结构:
残差结构详解_Star_ACE的博客-CSDN博客_残差结构
Batch Normalization详解以及pytorch实验_太阳花的小绿豆的博客-CSDN博客_batchnormalization pytorch
睿智的目标检测26——Pytorch搭建yolo3目标检测平台_Bubbliiiing的博客-CSDN博客_睿智的目标检测26
睿智的目标检测30——Pytorch搭建YoloV4目标检测平台_Bubbliiiing的博客-CSDN博客_yolov4目标检测
睿智的目标检测56——Pytorch搭建YoloV5目标检测平台_Bubbliiiing的博客-CSDN博客
睿智的目标检测53——Pytorch搭建YoloX目标检测平台_Bubbliiiing的博客-CSDN博客
Neck网络结构:
双线性插值_太阳花的小绿豆的博客-CSDN博客
PANet算法笔记_AI之路的博客-CSDN博客_panet
Head网络结构:
同上述YOLO系列backbone
网络训练
损失函数相关
YOLOv5代码阅读笔记 - 损失函数_ChiruZy的博客-CSDN博客_yolov5损失函数
yolov5目标检测神经网络——损失函数计算原理_萌萌哒程序猴的博客-CSDN博客_yolov5损失函数
快速理解binary cross entropy 二元交叉熵_Cy_coding的博客-CSDN博客_二元交叉熵
图像分割
全景分割这一年,端到端之路_weixin_33670786的博客-CSDN博客
图像分割任务发展出了以下几个子领域:
- 语义分割(semantic segmentation)
- 实例分割(instance segmentation)
- 全景分割(panoptic segmentation)
三者差异
首先搞清楚类别 things 和 类别stuff 的区别:图像中的内容可以按照是否有固定形状分为 things 类别和 stuff 类别,其中,人,车等有固定形状的物体属于 things 类别(可数名词通常属于 things);天空,草地等没有固定形状的物体属于 stuff 类别(不可数名词属于 stuff)
简言之,thing类是可数的形象的事物;stuff类是如草地、天空、背景等非规则事物。
语义分割只注重「类别之间的区分」,而实例分割更注重「个体之间的区分」,全景分割则是二者兼顾。
以下图为例,从上到下分别是原图、语义分割结果和实例分割结果。
语义分割会重点将前景里的人群和背景里树木、天空和草地分割开,但是它不区分人群的单独个体,如图中的人全部标记为红色,导致右边黄色框中的人无法辨别是一个人还是不同的人;
实例分割会重点将人群里的每一个人分割开,但是不在乎草地、树木和天空的分割。

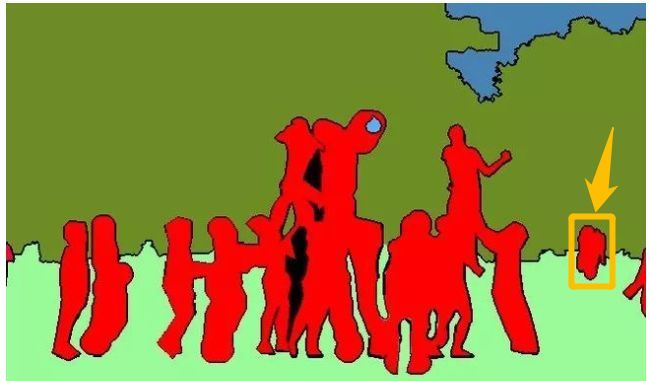
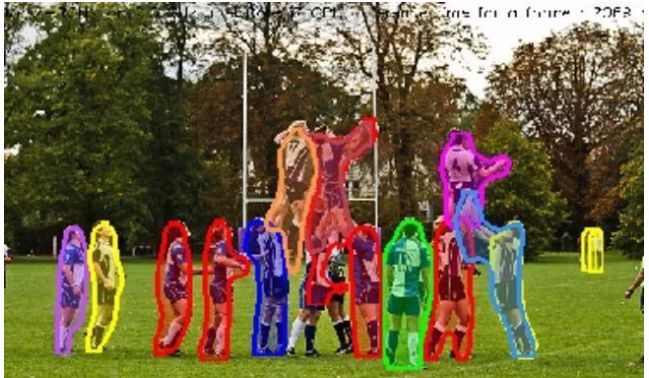
全景分割可以说是语义分割和实例分割的结合,下图是同一张原图的全景分割结果,每个 stuff 类别与 things 类别都被分割开,可以看到,things 类别的不同个体也被彼此分割开了。
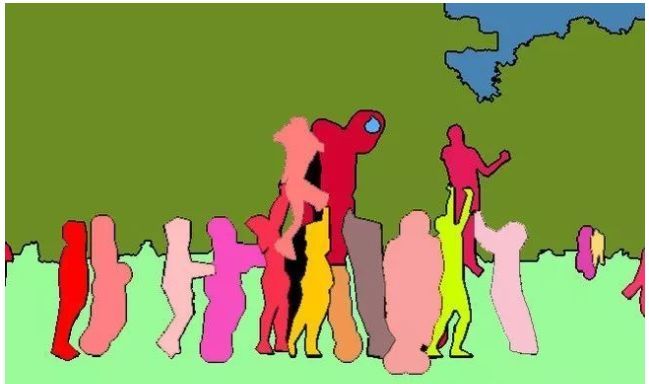
目前用于全景分割的常见公开数据集包括:MSCOCO、Vistas、ADE20K 和 Cityscapes。
语义分割篇
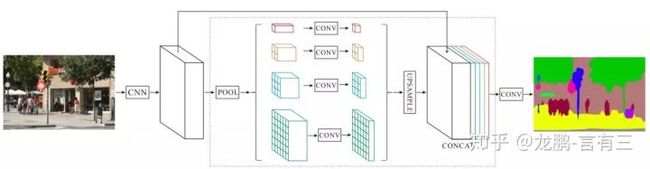
一、PSPnet
3、ECA的实现
该模型提出的金字塔池化模块(Pyramid Pooling Module)能够聚合不同区域的上下文信息,从而提高获取全局信息的能力
包含模块:
# PSP / 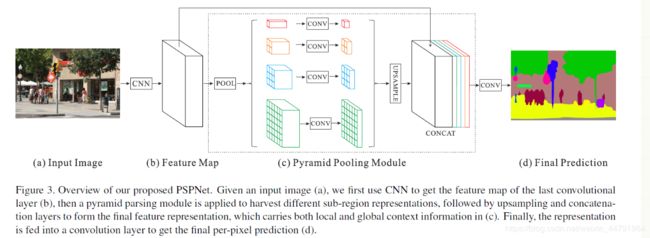
PSPNet所使用的加强特征提取结构是PSP模块。
PSP结构的做法是将获取到的特征层划分成不同大小的区域,每个区域内部各自进行平均池化。实现聚合不同区域的上下文信息,从而提高获取全局信息的能力。
在PSPNet中,PSP结构典型情况下,会将输入进来的特征层划分成6x6,3x3,2x2,1x1的区域,然后每个区域内部各自进行平均池化。
假设PSP结构输入进来的特征层为30x30x320,此时这个特征层的高和宽均为30,如果我们要将这个特征层划分成6x6的区域,只需要使得平均池化的步长stride=30/6=5和kernel_size=30/6=5就行了,此时的平均池化相当于将特征层划分成6x6的区域,每个区域内部各自进行平均池化。
当PSP结构输入进来的特征层为30x30x320时,PSP结构的具体构成如下。

class _PSPModule(nn.Module):
def __init__(self, in_channels, pool_sizes, norm_layer):
super(_PSPModule, self).__init__()
out_channels = in_channels // len(pool_sizes)
self.stages = nn.ModuleList([self._make_stages(in_channels, out_channels, pool_size, norm_layer)
for pool_size in pool_sizes])
self.bottleneck = nn.Sequential(
nn.Conv2d(in_channels+(out_channels * len(pool_sizes)), out_channels,
kernel_size=3, padding=1, bias=False),
norm_layer(out_channels),
nn.ReLU(inplace=True),
nn.Dropout2d(0.1)
)
def _make_stages(self, in_channels, out_channels, bin_sz, norm_layer):
prior = nn.AdaptiveAvgPool2d(output_size=bin_sz)
conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
bn = norm_layer(out_channels)
relu = nn.ReLU(inplace=True)
return nn.Sequential(prior, conv, bn, relu)
def forward(self, features):
h, w = features.size()[2], features.size()[3]
pyramids = [features]
pyramids.extend([F.interpolate(stage(features), size=(h, w), mode='bilinear',
align_corners=True) for stage in self.stages])
output = self.bottleneck(torch.cat(pyramids, dim=1))
return output
Pytorch学习笔记
yolov5损失函数
(最小化交叉熵损失函数等价于最大化训练数据集所有标签类别的联合预测概率。)
# 分类、置信度损失
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
# Focal loss
g = h['fl_gamma'] # focal loss gamma
if g > 0:
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
FLOPs:
# Test FLOPs
from fvcore.nn import FlopCountAnalysis, parameter_count_table
tensor_count = (torch.rand(1,3,224,224),)
flops = FlopCountAnalysis(model, tensor_count)
print("FLOPs", flops.total())
print(parameter_count_table(model))# 实现输入特征图的resize (如上采样操作)
F.interpolate(stage(features), size=(h, w), mode='bilinear',
align_corners=True) for stage in self.stagesnn.Upsample(scale_factor=2, mode='bilinear', align_corners=True),