机器学习与深度学习基本概念 学习笔记
目录
什么是机器学习
数据来源与类型
数据特征工程
数据特征抽取
TF-IDF
TfidfVectorizer语法
数据的特征处理
归一化
归一化总结
标准化
结合归一化来谈标准化
StandardScaler语法
标准化总结
缺失值处理方法
Imputer流程
关于np.nan(np.NaN)
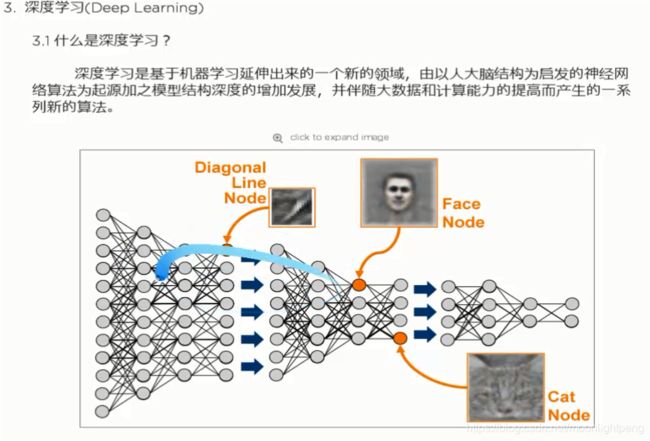








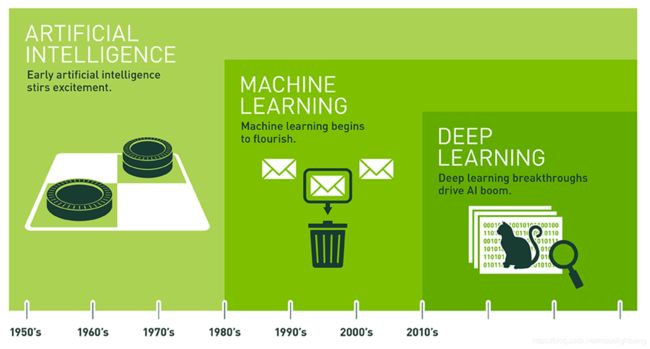

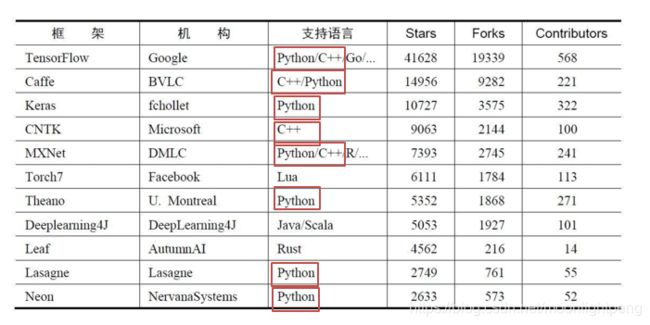
什么是机器学习
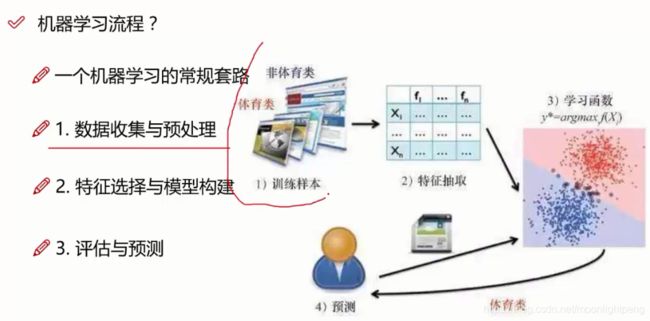
机器学习是从数据中自动分析获得规律(模型),并利用规律对未知数据进行预测
数据来源与类型

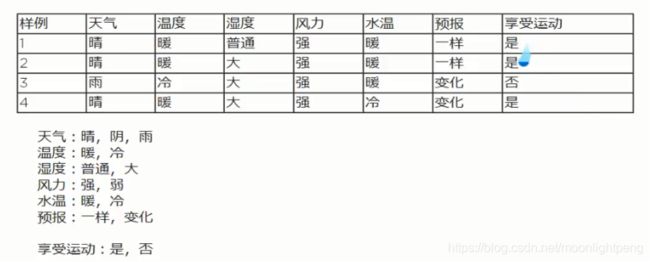
数据类型
有这些数据全部都是整数,而且不能再细分,也不能进一步提高他
们的精确度。
的,如,长度、时间、质量值等,这类整数通常是非整数,含有小数
部分。
注:只要记住一点,离散型是区间内不可分,连续型是区间内可分

Kaggle网址:https://www.kaggle.com/datasets
UCI数据集网址: http://archive.ics.uci.edu/ml/
scikit-learn网址:http://scikit-learn.org/stable/datasets/index.html#datasets
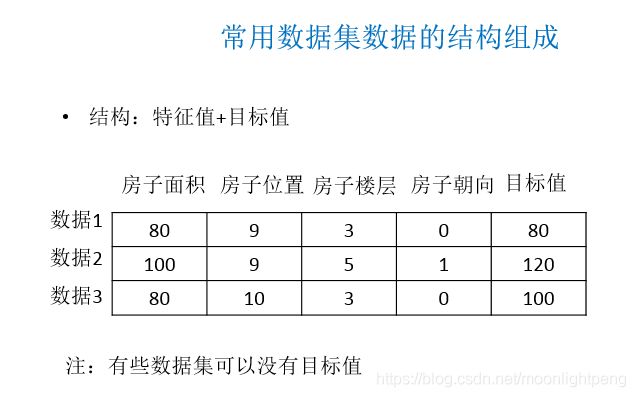
数据特征工程
特征工程是将原始数据转换为更好地代表预测模型的潜在问题的特征的过程,从而提高了对未知数据的模型准确性
特征工程的意义:•直接影响模型的预测结果

数据特征抽取

sklearn特征抽取API
• sklearn.feature_extraction
字典特征抽取作用:对字典数据进行特征值化
类:sklearn.feature_extraction.DictVectorizer


"coding = utf-8"
from sklearn.feature_extraction import DictVectorizer
def dictvec():
"""
对数据进行特征工程化处理
:return:
"""
dict = DictVectorizer(sparse=False)
Xdata = [{"city": "beijing", "temperature": 100},
{"city": "shanghai", "temperature": 90},
{"city": "shenzhen", "temperature": 80},
{"city": "lanzhou", "temperature": 75},]
data = dict.fit_transform(Xdata)
print(data)
print(dict.get_feature_names())
print(dict.get_params())
return None
def main():
print(10*"=")
dictvec()
if __name__ == "__main__":
main()
CountVectorizer语法



TF-IDF
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的概率高,
并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分
能力,适合用来分类。
TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
类:sklearn.feature_extraction.text.TfidfVectorizer
TfidfVectorizer语法
返回值:转换之前数据格式
数据的特征处理
1、特征处理的方法
2、sklearn特征处理API
特征处理是通过特定的统计方法(数学方法)将数据转换成算法要求的数据
数值型数据:标准缩放:
1、归一化
2、标准化
3、缺失值
类别型数据:one-hot编码
时间类型:时间的切分
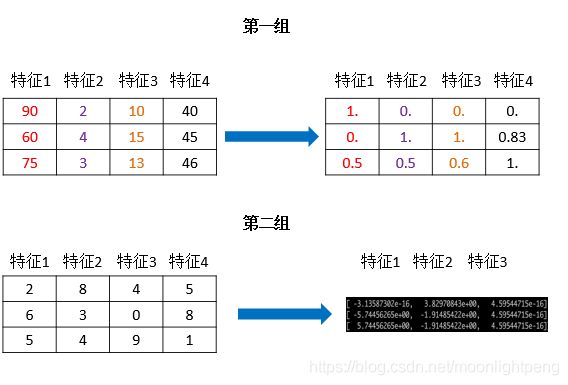
归一化
特点:通过对原始数据进行变换把数据映射到(默认为[0,1])之间


sklearn归一化API
sklearn归一化API: sklearn.preprocessing.MinMaxScaler
MinMaxScaler语法


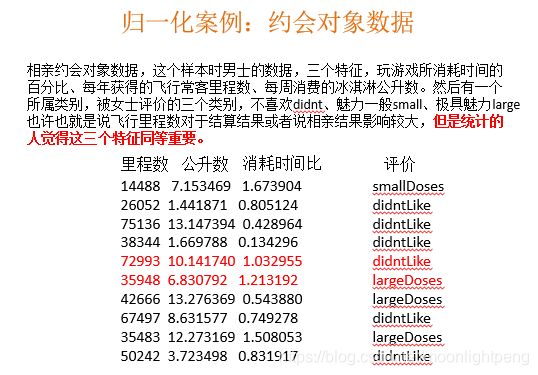
归一化总结
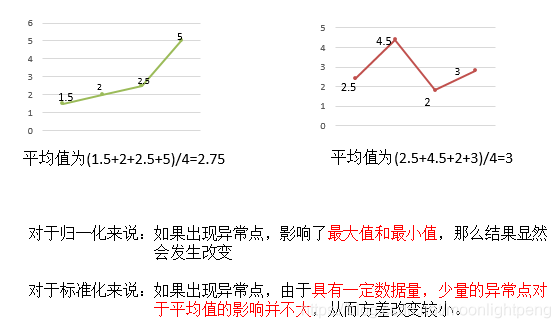
注意在特定场景下最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
标准化

结合归一化来谈标准化
StandardScaler语法


标准化总结
在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
缺失值处理方法

Imputer流程

关于np.nan(np.NaN)
