Ceph分布式存储(架构 配置与使用 原理 性能调优)
Ceph分布式存储
- Ceph分布式存储
-
- 1. Ceph概述
-
- 1.1 背景
- 1.2 介绍
- 1.3 特点
- 1.4 分布式存储系统横纵对比
- 2. Ceph架构设计
-
- 2.1 Ceph整体设计
- 2.2 逻辑架构
- 2.3 Ceph 专业术语
- 3. Ceph集群部署配置
-
- 3.1 部署结构
- 3.2 系统配置
- 3.3 免密码SSH登陆
- 3.4 集群搭建配置
- 3.5 安装管理后台
- 3.6 创建Cephfs
- /usr/local/cephfs_directory目录已成功挂载。
- 4. Ceph Swift Api 配置与使用
-
- 4.1 Ceph Swift Api 说明
- 4.2 Ceph Swift Api 特点
- 4.3 Ceph RGW 介绍
- 4.4 Ceph 存储结构
- 4.5 Ceph Swift Api 服务端的配置
- 4.6 Ceph Swift Api 调用验证
- 5. Ceph Swift 实践运用
-
- 5.1 Ceph封装与自动化装配
- 5.2 创建用户管理工程
- 5.3 Ceph文件上传实现
- 5.4 Ceph文件下载实现
- 5.5 功能验证
- 6. 深入Ceph原理
-
- 6.1 Crush算法与作用
- 6.2 Crush算法说明
- 6.3 Crush算法原理
- 6.4 IO流程图
- 6.5 Ceph 通信机制
- 6.6 Ceph RBD 块存储 IO流程图
- 6.7 Ceph 心跳和故障检测机制
- 7. Ceph性能调优
-
- 7.1 系统配置调优
- 7.2 Ceph集群优化配置
-
- 7.3 调优最佳实践
Ceph分布式存储
1. Ceph概述
1.1 背景
Ceph是一个去中心化的分布式存储系统, 提供较好的性能、可靠性和可扩展性。Ceph项目最早起源于Sage就读博士期间的工作(最早的成果于2004年发表),并随后贡献给开源社区, 遵循LGPL协议(LESSER GENERAL PUBLIC LICENSE的简写,中文译为“较宽松公共许可证”)。在经过了数年的发展之后,目前已得到众多云计算厂商(OpenStack、CloudStack、OpenNebula、Hadoop)的支持并被广泛应用。
1.2 介绍
Ceph是一个可靠、自动重均衡、自动恢复的分布式存储系统,根据场景划分可以将Ceph分为三大块,分别是对象存储、块设备和文件系统服务。
Ceph的主要优点是分布式存储,在存储每一个数据时,都会通过计算得出该数据存储的位置,尽量将数据分布均衡,不存在传统的单点故障的问题,可以水平扩展。
Ceph存储集群至少需要一个Ceph Monitor和两个OSD守护进程。而运行Ceph文件系统客户端时,则必须要有元数据服务器(Metadata Server)。
1.3 特点
Ceph适合跨集群的小文件存储, 拥有以下特点:
- 高性能
Client和Server直接通信, 不需要代理和转发;
Client不需要负责副本的复制, 有Primary主节点负责, 这样可以有效降低clien网络的消耗;
采用CRUSH算法,数据分布均衡,并行度高,支持上千个存储节点, 支持TB及PB级数据。
- 高可用性
数据多副本, 支持故障域分隔,数据强一致性;
没有单点故障,较好的容错性, 有效支撑各种故障场景;
支持所有故障的检测和自动恢复,可以做到自动化管理;
支持并行恢复,能够极大的降低数据恢复时间, 提高数据的可靠性。
- 高扩展性
高度并行化设计,没有单个中心控制组件,所有负载都能动态的划分到各个服务器上。
去中心化、灵活、随节点增加线性增长。
- 场景丰富
支持三种存储接口类型: 块存储、文件存储、对象存储。 同时支持自定义接口,C++为底层实现,兼容多种语言。
块存储: 将磁盘空间映射给主机使用, 适用 docker容器、虚拟机磁盘存储分配;日志存储,文件存储。
文件存储: 解决块存储无法共享问题, 在服务器架设FTP和NFS服务器,适用目录结构的存储、日志存储等。
对象存储: 大容量硬盘, 安装存储管理软件, 对外提供读写访问能力, 具备块存储的高速读写能力, 也具备文件存储共享的特性; 适用图片存储或视频存储。
1.4 分布式存储系统横纵对比
2. Ceph架构设计
2.1 Ceph整体设计

-
基础存储系统RADOS
Reliable, Autonomic,Distributed Object Store,即可靠的、自动化的、分布式的对象存储这就是一个完整的对象存储系统,所有存储在Ceph系统中的用户数据事实上最终都是由这一层来存储的。而Ceph的高可靠、高可扩展、高性能、高自动化等等特性本质上也是由这一层所提供的。 -
基础库librados
这层的功能是对RADOS进行抽象和封装,并向上层提供API,以便直接基于RADOS(而不是整个Ceph)进行应用开发。特别要注意的是,RADOS是一个对象存储系统,因此,librados实现的API也只是针对对象存储功能的。RADOS采用C++开发,所提供的原生librados API包括C和C++两种。 -
高层应用接口
这层包括了三个部分:RADOS GW(RADOS Gateway)、 RBD(Reliable Block Device)和CephFS(Ceph File System),其作用是在librados库的基础上提供抽象层次更高、更便于应用或客户端使用的上层接口。其中,RADOS GW是一个提供与Amazon S3和Swift兼容的RESTful API的gateway,以供相应的对象存储应用开发使用。RADOS GW提供的API抽象层次更高,但功能则不如librados强大。
- 应用层
这层是不同场景下对于Ceph各个应用接口的各种应用方式,例如基于librados直接开发的对象存储应用,基于RADOS GW开发的对象存储应用,基于RBD实现的云硬盘等等。librados和RADOS GW的区别在于,librados提供的是本地API,而RADOS GW提供的则是RESTfulAPI。
由于Swift和S3支持的API功能近似,这里以Swift举例说明。Swift提供的API功能主要包括:
- 用户管理操作:用户认证、获取账户信息、列出容器列表等;
- 容器管理操作:创建/删除容器、读取容器信息、列出容器内对象列表等;
- 对象管理操作:对象的写入、读取、复制、更新、删除、访问许可设置、元数据读取或更新等。
2.2 逻辑架构
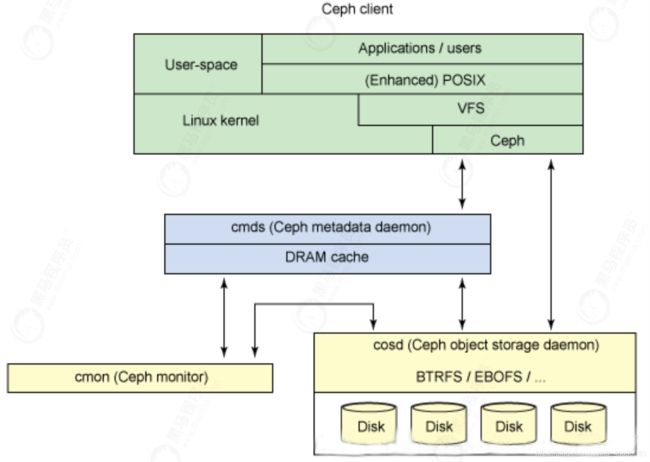
2.3 Ceph 专业术语

- OSD:Ceph的对象存储设备,OSD守护进程的功能是存储数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他OSD守护进程的心跳来向Ceph Monitors 提供一些监控信息。
- Monitors: Ceph监视器,Monitor维护着展示集群状态的各种图表,包括监视器图、OSD图、归置组(PG)图、和CRUSH图。
- PG:Ceph归置组,每个Object最后都会通过CRUSH计算映射到某个PG中,一个PG可以包含多个Object。
- MDS: Ceph元数据服务器(MDS),为Ceph文件系统存储元数据。
- CephFS: Ceph文件系统,CephFS提供了一个任意大小且兼容POSIX的分布式文件系统。
- RADOS: Reliable Autonomic Distributed Object Store,表示可靠、自动、分布式的对象存储。Ceph中的一切都是以对象形式存储,RADOS就负责存储这些对象,RADOS层确保数据一致性和可靠性。
- Librados:librados库是一种用来简化访问RADOS的方法,目前支持PHP、Python、Ruby、Java、C和C++语言。
- RBD:Ceph 的块设备,它对外提供块存储,可以被映射、格式化进而像其他磁盘一样挂载到服务器。
- RGW/RADOSGW:Ceph 对象网关,它提供了一个兼容S3和Swift的restful API接口。
3. Ceph集群部署配置
3.1 部署结构

虚拟机创建三台服务器,CENTOS版本为7.6, IP网段192.168.116.2/24。三台主机名称为:
- CENTOS7-1: IP为192.168.116.141, 既做管理节点, 又做子节点。
- CENTOS7-2: IP为192.168.116.142, 子节点。
- CENTOS7-3: IP为192.168.116.143, 子节点。
3.2 系统配置
系统配置工作, 三台节点依次执行:
- 修改主机名称
[root@CENTOS7-1 ~]# vi /etc/hostname
CENTOS7-1
- 编辑hosts文件
192.168.116.141 CENTOS7-1
192.168.116.142 CENTOS7-2
192.168.116.143 CENTOS7-3
注意, 这里面的主机名称要和节点名称保持一致, 否则安装的时候会出现问题

3. 修改yum源
vi /etc/yum.repos.d/ceph.repo
为避免网速过慢问题, 这里采用的是清华镜像源:
[Ceph]
name=Ceph packages for $basearch
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-mimic/el7/x86_64/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
[Ceph-noarch]
name=Ceph noarch packages
# 官方源
#baseurl=http://download.ceph.com/rpm-mimic/el7/noarch
# 清华源
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-mimic/el7/noarch/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-source]
name=Ceph source packages
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-mimic/el7/SRPMS/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
- 安装ceph与ceph-deploy组件
yum update && yum -y install ceph ceph-deploy
安装完成, 如果执行ceph-deploy出现ImportError: No module named pkg_resources
安装python2-pip:
yum -y install python2-pip
yum install epel-release -y
- 安装NTP时间同步工具
yum install ntp ntpdate ntp-doc -y
确保时区是正确, 设置开机启动:
systemctl enable ntpd
并将时间每隔1小时自动校准同步。编辑 vi /etc/rc.d/rc.local 追加:
/usr/sbin/ntpdate ntp1.aliyun.com > /dev/null 2>&1; /sbin/hwclock -w
配置定时任务, 执行crontab -e 加入:
0 */1 * * * ntpdate ntp1.aliyun.com > /dev/null 2>&1; /sbin/hwclock -w
3.3 免密码SSH登陆
- 官方建议不用系统内置用户, 创建名为ceph_user用户, 密码也设为ceph_user:
useradd -d /home/ceph_user -m ceph_user
passwd ceph_user
- 设置sudo权限
echo "ceph_user ALL = (root) NOPASSWD:ALL" | sudo tee
/etc/sudoers.d/ceph_user
sudo chmod 0440 /etc/sudoers.d/ceph_user
1、2两个步骤依次在三台机器上执行。
接下来在主节点, 继续执行:
3. 生成密钥:
切换用户: su ceph_user
执行ssh-keygen,一直按默认提示点击生成RSA密钥信息。
4. 分发密钥至各机器节点
ssh-copy-id ceph_user@CENTOS7-1
ssh-copy-id ceph_user@CENTOS7-2
ssh-copy-id ceph_user@CENTOS7-3
- 修改管理节点上的 ~/.ssh/config 文件, 简化SSH远程连接时的输入信息:
管理节点是会有root和ceph_user多个用户, ssh远程连接默认会以当前用户身份进行登陆,
如果我们是root身份进行远程连接, 还是需要输入密码, 我们想简化, 该怎么处理?
切换root身份,
su root
修改~/.ssh/config 文件
Host CENTOS7-1
Hostname CENTOS7-1
User ceph_user
Host CENTOS7-2
Hostname CENTOS7-2
User ceph_user
Host CENTOS7-3
Hostname CENTOS7-3
User ceph_user
注意修改文件权限, 不能采用777最大权限:
chmod 600 ~/.ssh/config
进行ssh远程连接时, Host的主机名称是区分大小写的, 所以要注意配置文件的主机名称。
6. 开放端口, 非生产环境, 可以直接禁用防火墙:
systemctl stop firewalld.service
systemctl disable firewalld.service
- SELINUX设置
SELinux设为禁用:
setenforce 0
永久生效:
编辑 vi /etc/selinux/config修改:
SELINUX=disabled
3.4 集群搭建配置
采用root身份进行安装
- 在管理节点创建集群配置目录,cd /usr/local:
mkdir ceph-cluster
cd ceph-cluster
注意: 此目录作为ceph操作命令的基准目录, 会存储处理配置信息。
2. 创建集群, 包含三台机器节点:
ceph-deploy new CENTOS7-1 CENTOS7-2 CENTOS7-3
创建成功后, 会生一个配置文件。
3. 如果接下来集群的安装配置出现问题, 可以执行以下命令清除, 再重新安装:
ceph-deploy purge CENTOS7-1 CENTOS7-2 CENTOS7-3
ceph-deploy purgedata CENTOS7-1 CENTOS7-2 CENTOS7-3
ceph-deploy forgetkeys
将三台节点的mon信息也删除
rm -rf /var/run/ceph/
- 修改配置文件, 有些配置后面需用到:
vi /usr/local/ceph-cluster/ceph.conf
加入:
[global]
# 公网网络
public network = 192.168.116.0/24
# 设置pool池默认分配数量 默认副本数为3
osd pool default size = 2
# 容忍更多的时钟误差
mon clock drift allowed = 2
mon clock drift warn backoff = 30
# 允许删除pool
mon_allow_pool_delete = true
[mgr]
# 开启WEB仪表盘
mgr modules = dashboard
第一项为副本数, 设为2份。
第二项为对外IP访问网段,注意根据实际IP修改网段。
第三、四项为允许一定时间的漂移误差。
- 执行安装:
ceph-deploy install CENTOS7-1 CENTOS7-2 CENTOS7-3
如果出现错误:
ceph_deploy][ERROR ] RuntimeError: Failed to execute command: ceph --version
可以在各节点上单独进行安装
yum -y install ceph
如果没有仓库文件ceph.repo, 按上面的步骤手工创建。
- 初始monitor信息:
ceph-deploy mon create-initial
## ceph-deploy --overwrite-conf mon create-initial

7. 同步管理信息:
下发配置文件和管理信息至各节点:
ceph-deploy admin CENTOS7-1 CENTOS7-2 CENTOS7-3
- 安装mgr(管理守护进程), 大于12.x版本需安装, 我们装的是最新版,需执行:
ceph-deploy mgr create CENTOS7-1 CENTOS7-2 CENTOS7-3
- 安装OSD(对象存储设备)
注意: 新版本的OSD没有prepare与activate命令。
这里需要新的硬盘作为OSD存储设备, 关闭虚拟机, 增加一块硬盘, 不用格式化。
重启, fdisk -l 查看新磁盘名称:
执行创建OSD命令:
ceph-deploy osd create --data /dev/sdb CENTOS7-1
三台节点都需分别依次执行。
ceph-deploy gatherkeys CENTOS7-1
10. 验证节点:
输入ceph health 或 ceph -s查看, 出现HEALTH_OK代表正常。
通过虚拟机启动, 如果出现错误:
[root@CENTOS7-1 ~]# ceph -s
cluster:
id: 0ec99aa9-e97e-43d3-b5b9-90eb21c4abff
health: HEALTH_WARN
1 filesystem is degraded
1 osds down
1 host (1 osds) down
Reduced data availability: 41 pgs inactive
Degraded data redundancy: 134/268 objects degraded (50.000%), 22 pgs
degraded, 87 pgs undersized
39 slow ops, oldest one blocked for 2286 sec, daemons
[osd.0,mon.CENTOS7-2,mon.CENTOS7-3] have slow ops.
clock skew detected on mon.CENTOS7-2, mon.CENTOS7-3
services:
mon: 3 daemons, quorum CENTOS7-1,CENTOS7-2,CENTOS7-3
mgr: centos7-1(active), standbys: centos7-3, centos7-2
mds: fs_test-1/1/1 up {0=centos7-1=up:replay}
osd: 3 osds: 1 up, 2 in
data:
pools: 9 pools, 128 pgs
objects: 134 objects, 64 KiB
usage: 1.0 GiB used, 19 GiB / 20 GiB avail
pgs: 32.031% pgs unknown
134/268 objects degraded (50.000%)
65 active+undersized
41 unknown
22 active+undersized+degraded
在各节点执行命令, 确保时间同步一致:
ntpdate ntp1.aliyun.com
3.5 安装管理后台
- 开启dashboard模块
ceph mgr module enable dashboard
- 生成签名
ceph dashboard create-self-signed-cert
- 创建目录
mkdir mgr-dashboard
[root@CENTOS7-1 mgr-dashboard]# pwd
/usr/local/ceph-cluster/mgr-dashboard
- 生成密钥对
cd /usr/local/ceph-cluster/mgr-dashboard
openssl req -new -nodes -x509 -subj "/O=IT/CN=ceph-mgr-dashboard" -days 3650 -keyout dashboard.key -out dashboard.crt -extensions v3_ca
[root@CENTOS7-1 mgr-dashboard]# ll
total 8
-rw-rw-r-- 1 ceph_user ceph_user 1155 Jul 14 02:26 dashboard.crt
-rw-rw-r-- 1 ceph_user ceph_user 1704 Jul 14 02:26 dashboard.key
- 启动dashboard
ceph mgr module disable dashboard
ceph mgr module enable dashboard
- 设置IP与PORT
ceph config set mgr mgr/dashboard/server_addr 192.168.116.141
ceph config set mgr mgr/dashboard/server_port 18843
- 关闭HTTPS
ceph config set mgr mgr/dashboard/ssl false
- 查看服务信息
[root@CENTOS7-1 mgr-dashboard]# ceph mgr services
{
"dashboard": "https://CENTOS7-2:8443/"
}
- 设置管理用户与密码
ceph dashboard set-login-credentials admin admin
- 访问

3.6 创建Cephfs
集群创建完后, 默认没有文件系统, 我们创建一个Cephfs可以支持对外访问的文件系统。
ceph-deploy --overwrite-conf mds create CENTOS7-1 CENTOS7-2 CENTOS7-3
- 创建两个存储池, 执行两条命令:
ceph osd pool create cephfs_data 128
ceph osd pool create cephfs_metadata 64
少于5个OSD可把pg_num设置为128
OSD数量在5到10,可以设置pg_num为512
OSD数量在10到50,可以设置pg_num为4096
OSD数量大于50,需要计算pg_num的值
通过下面命令可以列出当前创建的存储池:
ceph osd lspools
- 创建fs, 名称为fs_test:
ceph fs new fs_test cephfs_metadata cephfs_data
- 状态查看, 以下信息代表正常:
[root@CENTOS7-1 mgr-dashboard]# ceph fs ls
name: fs_test, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
[root@CENTOS7-1 mgr-dashboard]# ceph mds stat fs_test-1/1/1 up {0=centos7-1=up:active}
附: 如果创建错误, 需要删除, 执行
ceph fs rm fs_test --yes-i-really-mean-it
ceph osd pool delete cephfs_data cephfs_data --yes-i-really-really-mean-it
确保在ceph.conf中开启以下配置:
[mon]
mon allow pool delete = true
- 采用fuse挂载
先确定ceph-fuse命令能执行, 如果没有, 则安装:
yum -y install ceph-fuse
- 创建挂载目录
mkdir -p /usr/local/cephfs_directory
- 挂载cephfs
[root@node3 ~]# ceph-fuse -k /etc/ceph/ceph.client.admin.keyring -m
192.168.116.141:6789 /usr/local/cephfs_directory
ceph-fuse[6687]: starting ceph client
2019-07-14 21:39:09.644181 7fa5be56e040 -1 init, newargv = 0x7fa5c940b500
newargc=9
ceph-fuse[6687]: starting fuse
- 查看磁盘挂载信息
[root@CENTOS7-1 mgr-dashboard]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 38G 3.0G 35G 8% /
devtmpfs 1.9G 0 1.9G 0% /dev
tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs 1.9G 20M 1.9G 2% /run
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
/dev/sda1 197M 167M 31M 85% /boot
tmpfs 378M 0 378M 0% /run/user/0
tmpfs 1.9G 24K 1.9G 1% /var/lib/ceph/osd/ceph-0
ceph-fuse 27G 0 27G 0% /usr/local/cephfs_directory
tmpfs 378M 0 378M 0% /run/user/1000
/usr/local/cephfs_directory目录已成功挂载。
3.7 客户端连接验证(Rados Java)
- 安装好JDK、GIT和MAVEN。
- 下载rados java客户端源码
git clone https://github.com/ceph/rados-java.git
下载目录位置:
[root@CENTOS7-1 rados-java]# pwd
/usr/local/sources/rados-java
- 执行MAVEN安装, 忽略测试用例:
[root@CENTOS7-1 rados-java]# mvn install -Dmaven.test.skip=true
生成jar包, rados-0.7.0.jar
[root@CENTOS7-1 target]# ll
总用量 104
drwxr-xr-x 3 root root 17 8月 11 18:32 classes
drwxr-xr-x 2 root root 27 8月 11 18:32 dependencies
drwxr-xr-x 3 root root 25 8月 11 18:32 generated-sources
drwxr-xr-x 2 root root 28 8月 11 18:32 maven-archiver
drwxr-xr-x 3 root root 35 8月 11 18:32 maven-status
-rw-r--r-- 1 root root 105701 8月 11 18:32 rados-0.7.0.jar
- 创建软链接, 加入CLASSPATH
ln -s /usr/local/sources/rados-java/target/rados-0.7.0.jar
/opt/jdk1.8.0_301/jre/lib/ext/rados-0.7.0.jar
安装jna
yum -y install jna
创建软链接
ln -s /usr/share/java/jna.jar /opt/jdk1.8.0_301/jre/lib/ext/jna.jar
查看
[root@CENTOS7-1 target]# ll /opt/jdk1.8.0_301/jre/lib/ext/jna.jar
lrwxrwxrwx 1 root root 23 8月 11 19:00 /opt/jdk1.8.0_301/jre/lib/ext/jna.jar
-> /usr/share/java/jna.jar
[root@CENTOS7-1 target]# ll /opt/jdk1.8.0_301/jre/lib/ext/rados-0.7.0.jar
lrwxrwxrwx 1 root root 52 8月 11 18:59 /opt/jdk1.8.0_301/jre/lib/ext/rados-
0.7.0.jar -> /usr/local/sources/rados-java/target/rados-0.7.0.jar
- 创建JAVA测试类
CephClient类,注意, 最新版0.6的异常处理包位置已发生变化。
import com.ceph.rados.Rados;
import com.ceph.rados.exceptions.*;
import java.io.File;
public class CephClient {
public static void main (String args[]){
try {
Rados cluster = new Rados("admin");
System.out.println("Created cluster handle.");
File f = new File("/etc/ceph/ceph.conf");
cluster.confReadFile(f);
System.out.println("Read the configuration file.");
cluster.connect();
System.out.println("Connected to the cluster.");
} catch (RadosException e) {
System.out.println(e.getMessage() + ": " +
e.getReturnValue());
}
}
}
- 运行验证
需要在linux环境下运行,且要在client节点。
编译并运行:
[root@CENTOS7-1 sources]# javac CephClient.java
[root@CENTOS7-1 sources]# java CephClient
Created cluster handle.
Read the configuration file.
Connected to the cluster.
成功与ceph建立连接。
注意:如果java和javac版本不同,可以使用rpm -qa |grep java 进行查找, rpm -e --nodeps jdk进行删除,source /etc/profile进行生效
jdk的位数为64位
4. Ceph Swift Api 配置与使用
4.1 Ceph Swift Api 说明
在ceph的使用上, 互联网大规模的文件场景下, fs并不能满足生产的使用要求,rados本地化操作也不便于服务的接入与使用, 这里我们就要采用Ceph Swift Api 来实现文件的存储管理。
4.2 Ceph Swift Api 特点
Swift是由Rackspace开发,用来为云计算提供可扩展存储的项目。专注于对象存储, 并提供一套REST风格的Api来访问, 与Ceph强一致性不同, 它是最终一致性。两者都是优秀的开源项目, 并无明显优劣之分,在使用场景上有所不同, 如果是专注于对象存储, 那么可以选择swift即可满足需要, 如果还
有块存储要求, 那么选择Ceph更为合适。这里选择Ceph, 因为通过网关可以适配兼容swift api, 同时在数据访问上具有较强的扩展性:
- Ceph可通过Rados网关用兼容S3的RESTful API访问,对AWS云环境下的其他内容也能很好的兼容, 比如OpenStack Swift的对象存储访问接口。
- CephFS:是一个POSIX兼容的文件系统,可以在任何Linux发行版上运行,操作系统可直接访问Ceph存储。
- RBD:RBD是一个Linux内核级的块设备,允许用户像任何其他Linux块设备一样访问Ceph。
- ISCSI 网关:这一增加的功能是SUSE加上去的,它允许管理员在Ceph之上运行iSCSI(互联网小型计算机系统接口)网关,从而将其转变为任何操作系统都可以访问的SAN(Storage Area Network,存储区域网络)文件管理器。
4.3 Ceph RGW 介绍
Ceph可以提供块、文件和对象三种形态的存储。RGW就是提供对象存储的网关,也即对象存储网关。
所谓对象存储网关,也就是对象存储的入口,本质上是一个HTTP服务器,与Nginx和Apache无特殊差别。通过这个网关入口,用户可以采用HTTP协议,以RESTful的方式访问Ceph的对象存储。
4.4 Ceph 存储结构
在使用对象存储之前, 先要了解桶(container容器)概念及其存储结构:
Ceph Swift Api的调用, 需要先创建相应用户进行认证才能操作, 每个用户下面可以创建多个桶, 桶里面可以存储对象,对象就是各种数据文件, 包括文档, 图片等。传统上传文件的使用, 我们往往会指定路径信息, 在这里, 桶和对象的关系好比文件夹与文件的概念, 不同之处是桶不能再嵌套桶, 也就
是没有层级路径的概念。
Ceph存储结构:
4.5 Ceph Swift Api 服务端的配置
- 确保集群正常安装并启动:
[root@CENTOS7-1 ceph-cluster]# ceph -s
cluster:
id: 0ec99aa9-e97e-43d3-b5b9-90eb21c4abff
health: HEALTH_OK
services:
mon: 3 daemons, quorum CENTOS7-1,CENTOS7-2,CENTOS7-3
mgr: centos7-1(active), standbys: centos7-3, centos7-2
mds: fs_test-1/1/1 up {0=centos7-1=up:active}
osd: 3 osds: 3 up, 3 in
rgw: 3 daemons active
data:
pools: 9 pools, 128 pgs
objects: 257 objects, 166 KiB
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs: 128 active+clean
如果rgw没有显示, 检查服务状态:
[root@CENTOS7-1 ceph-cluster]# systemctl list-unit-files|grep enabled|grep
ceph
ceph-crash.service enabled
[email protected] enabled
[email protected] enabled
[email protected] enabled
[email protected] enabled-runtime
[email protected] enabled
[email protected] enabled
ceph-mds.target enabled
ceph-mgr.target enabled
ceph-mon.target enabled
ceph-osd.target enabled
ceph-radosgw.target enabled
ceph.target enabled
重启RGW服务:
ceph-deploy --overwrite-conf --ceph-conf ceph.conf rgw create CENTOS7-1
systemctl restart ceph-radosgw@*.service
- 验证网关是否正常
访问地址,http://192.168.116.141:7480
出现以下提示代表正常

- 创建Swift用户, 用于接口请求认证
sudo radosgw-admin user create --subuser="cephtester:subtester" --
uid="cephtester" --display-name="cephtester" --key-type=swift --
secret="654321" --access=full
uid 为主用户, subuser为子用户信息, secret指定密钥, 不指定则随机生成, access拥有权限设定。
返回结果:
[root@CENTOS7-1 ceph-cluster]# sudo radosgw-admin user create --
subuser="cephtester:subtester" --uid="cephtester" --display-
name="cephtester" --key-type=swift --secret="654321" --access=full
{
"user_id": "cephtester",
"display_name": "cephtester",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"auid": 0,
"subusers": [
{
"id": "cephtester:subtester",
"permissions": "full-control"
}
],
"keys": [],
"swift_keys": [
{
"user": "cephtester:subtester",
"secret_key": "654321"
}
],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}
记住swift_keys下面的user和secret_key信息, 代码中需使用。
4. 激活管理后台的对象存储模块:
5. 创建一个管理用户:
radosgw-admin user create --uid=mgruser --display-name=mgruser --system
返回结果:
[root@CENTOS7-1 ceph-cluster]# radosgw-admin user create --uid=mgruser --
display-name=mgruser --system
{
"user_id": "mgruser",
"display_name": "mgruser",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"auid": 0,
"subusers": [],
"keys": [
{
"user": "mgruser",
"access_key": "LDX7XCBUE5BETTRJW7AW",
"secret_key": "tZhGrHOLR2AOCBohc9EOkvCbeocQvdwfkDMs0YU9"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"system": "true",
"default_placement": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}
根据生成的access_key与secret_key, 执行:
ceph dashboard set-rgw-api-access-key LDX7XCBUE5BETTRJW7AW
ceph dashboard set-rgw-api-secret-key tZhGrHOLR2AOCBohc9EOkvCbeocQvdwfkDMs0YU9
打开管理界面,https://192.168.116.141:18843 可以查看到我们刚才创建的两个用户

4.6 Ceph Swift Api 调用验证
- 创建ceph-demo工程:
增加SwiftOperator接口:
mport org.javaswift.joss.client.factory.AccountConfig;
import org.javaswift.joss.client.factory.AccountFactory;
import org.javaswift.joss.client.factory.AuthenticationMethod;
import org.javaswift.joss.model.Account;
import org.javaswift.joss.model.Container;
import org.javaswift.joss.model.StoredObject;
import org.springframework.stereotype.Component;
import java.io.File;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
@Component
@Log4j2
public class SwiftOperator {
/**
* 用户名信息, 格式: 主用户名:子用户名
*/
private String username ="cephtester:subtester";
/**
* 用户密码
*/
private String password = "654321";
/**
* 接口访问地址
*/
private String authUrl = "http://192.168.116.141:7480/auth/1.0";
/**
* 默认存储的容器名称(bucket)
*/
private String defaultContainerName = "user_datainfo";
/**
* Ceph的账户信息
*/
private Account account = null;
/**
* Ceph的容器信息
*/
private Container container;
/**
* 进行Ceph的初始化配置
*/
public SwiftOperator() {
// 1. Ceph的账户信息配置
AccountConfig config = new AccountConfig();
config.setUsername(username);
config.setPassword(password);
config.setAuthUrl(authUrl);
config.setAuthenticationMethod(AuthenticationMethod.BASIC);
account = new AccountFactory(config).createAccount();
// 2.获取容器信息
Container newContainer = account.getContainer(defaultContainerName);
if(!newContainer.exists()) {
container = newContainer.create();
System.out.println("container create ==> " + defaultContainerName);
}else {
container = newContainer;
}
}
/**
* 文件上传处理
* @param remoteName
* @param filePath
*/
public void createObject(String remoteName, String filePath) {
// 1. 从容器当中获取远程存储对象信息
StoredObject object = container.getObject(remoteName);
// 2. 执行文件上传处理
object.uploadObject(new File(filePath));
}
/**
* 文件的下载处理
* @param objectName
* @param outPath
*/
public void retrieveObject(String objectName, String outPath) {
// 1. 从容器当中获取远程存储对象信息
StoredObject object = container.getObject(objectName);
// 2. 执行文件的下载方法
object.downloadObject(new File(outPath));
}
/**
* 获取用户下面的所有容器信息
* @return
*/
public List listContainer() {
List list = new ArrayList();
Collection<Container> containers = account.list();
for(Container container : containers) {
list.add(container.getName());
System.out.println("current container name : " + container.getName());
}
return list;
}
}
- 测试验证
测试思路, 在d盘创建一个文件, 并上传到ceph系统, 然后从ceph系统下载到指定路径下面。
这里要注意,我们默认的容器配置的是”user_datainfo“, 从ceph系统上传和下载的文件名称要一致, 启动打印"complete" , 无异常代表执行成功。
5. Ceph Swift 实践运用
5.1 Ceph封装与自动化装配
- 创建ceph-starter自动化工程:
- pom文件依赖:
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-actuator-autoconfigureartifactId>
dependency>
<dependency>
<groupId>com.cephgroupId>
<artifactId>radosartifactId>
<version>0.6.0version>
dependency>
<dependency>
<groupId>com.cephgroupId>
<artifactId>libcephfsartifactId>
<version>0.80.5version>
dependency>
<dependency>
<groupId>org.javaswiftgroupId>
<artifactId>jossartifactId>
<version>0.10.2version>
dependency>
dependencies>
直接采用目前的最新版, 加入Ceph相关的三个依赖。
3. 代码实现
封装Ceph操作接口, CephSwiftOperator类:
import org.javaswift.joss.client.factory.AccountConfig;
import org.javaswift.joss.client.factory.AccountFactory;
import org.javaswift.joss.client.factory.AuthenticationMethod;
import org.javaswift.joss.model.Account;
import org.javaswift.joss.model.Container;
import org.javaswift.joss.model.StoredObject;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.File;
import java.io.InputStream;
import java.lang.invoke.MethodHandles;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
public class CephSwiftOperator {
private static final Logger log = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());
/**
* 用户名
*/
private String username;
/**
* 密码
*/
private String password;
/**
* 认证接入地址
*/
private String authUrl;
/**
* 默认容器名称
*/
private String defaultContainerName;
/**
* Ceph账户对象
*/
private Account account;
/**
* Ceph容器对象
*/
private Container container;
public CephSwiftOperator(String username, String password, String authUrl, String defaultContainerName) {
// 初始化配置信息
this.username = username;
this.password = password;
this.authUrl = authUrl;
this.defaultContainerName = defaultContainerName;
init();
}
/**
* 初始化建立连接
*/
public void init() {
try {
// Ceph用户认证配置
AccountConfig config = new AccountConfig();
config.setUsername(username);
config.setPassword(password);
config.setAuthUrl(authUrl);
config.setAuthenticationMethod(AuthenticationMethod.BASIC);
account = new AccountFactory(config).createAccount();
// 获取容器
Container newContainer = account.getContainer(defaultContainerName);
if (!newContainer.exists()) {
container = newContainer.create();
log.info("account container create ==> " + defaultContainerName);
} else {
container = newContainer;
log.info("account container exists! ==> " + defaultContainerName);
}
}catch(Exception e) {
// 做异常捕获, 避免服务不能正常启动
log.error("Ceph连接初始化异常: " + e.getMessage());
}
}
/**
* 上传对象
* @param remoteName
* @param filepath
*/
public void createObject(String remoteName, String filepath) {
StoredObject object = container.getObject(remoteName);
object.uploadObject(new File(filepath));
}
/**
* 上传文件对象(字节数组形式)
* @param remoteName
* @param inputStream
*/
public void createObject(String remoteName, byte[] inputStream) {
StoredObject object = container.getObject(remoteName);
object.uploadObject(inputStream);
}
/**
* 获取指定对象
* @param containerName
* @param objectName
* @param outpath
*/
public void retrieveObject(String objectName,String outpath){
StoredObject object = container.getObject(objectName);
object.downloadObject(new File(outpath));
}
/**
* 下载文件, 转为文件流形式
* @param objectName
* @return
*/
public InputStream retrieveObject(String objectName){
StoredObject object = container.getObject(objectName);
return object.downloadObjectAsInputStream();
}
/**
* 删除指定文件对象
* @param containerName
* @param objectName
* @return
*/
public boolean deleteObject(String objectName){
try {
StoredObject object = container.getObject(objectName);
object.delete();
return !object.exists();
}catch(Exception e) {
log.error("Ceph删除文件失败: " + e.getMessage());
}
return false;
}
/**
* 获取所有容器
* @return
*/
public List listContainer() {
List list = new ArrayList();
Collection<Container> containers = account.list();
for (Container currentContainer : containers) {
list.add(currentContainer.getName());
System.out.println(currentContainer.getName());
}
return list;
}
}
AutoCephSwiftConfiguration自动化配置类:
@Configuration
@EnableAutoConfiguration
@ConditionalOnProperty(name = "ceph.authUrl")
public class AutoCephSwiftConfiguration {
@Value("${ceph.username}")
private String username;
@Value("${ceph.password}")
private String password;
@Value("${ceph.authUrl}")
private String authUrl;
@Value("${ceph.defaultContainerName}")
private String defaultContainerName;
@Bean
public CephSwiftOperator cephSwiftOperator() {
return new CephSwiftOperator(username, password, authUrl, defaultContainerName);
}
}
ConditionalOnProperty根据ceph.authUrl属性来决定是否加载配置,如果配置文件中没有设置Ceph相关属性, 即使maven中引用, 启动也不会报错。 该自动化配置, 负责初始化一个CephSwift 接口操作实例。
4. 自动化配置:
要让自定义Ceph Starter真正生效, 必须遵循Spring boot 的SPI扩展机制, 在resources环境中,META-INF目录下, 创建spring.factories文件:

# Auto Configure
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
cn.itcast.ceph.starter.AutoCephSwiftConfiguration
指定我们上面所写的自动化配置类。
5.2 创建用户管理工程
- 工程结构:

- 工程配置
application.yml
server:
port: 10692
spring:
application:
name: user-manager
# 模板配置
thymeleaf:
prefix: classpath:/templates/
suffix: .html
mode: HTML
encoding: utf-8
servlet:
content-type: text/html
# 文件上传大小限制
servlet:
multipart:
max-file-size: 100MB
max-request-size: 100MB
# ceph swift 认证信息配置
ceph:
username: cephtester:subtester
password: 654321
authUrl: http://192.168.116.141:7480/auth/1.0
defaultContainerName: user_datainfo
5.3 Ceph文件上传实现

- 实现文件上传接口:
/**
* 上传用户文件
* @return
*/
public String uploadUserFile(MultipartFile file) throws Exception {
// 获取唯一文件ID标识
String remoteFileId = globalIDGenerator.nextStrId();
// 上传文件至CEPH
cephSwiftOperator.createObject(remoteFileId, file.getBytes());
return remoteFileId;
}
- Controller层实现:
在UserManagerController下面, 增加上传接口:
/**
* 用户文件上传
* @param file
* @return
*/
@PostMapping("/upload")
@ResponseBody
public String upload(@RequestParam("file") MultipartFile file) {
String result = null;
try {
// 通过Ceph Swift上传文件
String userFileId = userManagerService.uploadUserFile(file);
result = "上传的文件ID: " + userFileId;
}catch(Exception e) {
e.printStackTrace();
result = "出现异常:" + e.getMessage();
}
return result;
}
5.4 Ceph文件下载实现
新增一个接口, 根据上传的文件ID标识下载文件。
- Service层:
实现下载用户文件接口:
/**
* 下载用户文件
* @param fileId
* @return
* @throws Exception
*/
public InputStream downloadUserFile(String fileId) throws Exception {
return cephSwiftOperator.retrieveObject(fileId);
}
- Controller层:
/**
* 根据文件ID下载用户文件信息
* @param filename
* @return
*/
@RequestMapping(value = "/download")
public String downloadFile(@NotBlank(message = "文件ID不能为空!") String filename, HttpServletResponse response){
String result = null;
// 文件流缓存
BufferedInputStream bis = null;
// 文件输出流
OutputStream os = null;
try {
// 1. 从Ceph服务器上获取文件流
InputStream inputStream = userManagerService.downloadUserFile(filename);
// 2.设置强制下载, 不直接打开
response.setContentType("application/x-msdownload");
// 3. 设置下载的文件名称
response.addHeader("Content-disposition", "attachment; fileName=" + filename);
// 4. 输出文件流
byte[] buffer = new byte[1024];
bis = new BufferedInputStream(inputStream);
os = response.getOutputStream();
int i = bis.read(buffer);
while(i != -1) {
os.write(buffer, 0, i);
i = bis.read(buffer);
}
os.flush();
return null;
}catch(Exception e) {
e.printStackTrace();
result = "出现异常:" + e.getMessage();
}finally {
// 最后, 要记住关闭文件流
if(bis != null ) {
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return result;
}
还有一个页面在templates
DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml"xmlns:th="http://www.thymeleaf.org"
xmlns:sec="http://www.thymeleaf.org/thymeleaf-extras-springsecurity3" >
<head>
<title>User File Manager!title>
<meta http-equiv="Cache-Control" content="no-cache, no-store, must-revalidate" />
<meta http-equiv="Pragma" content="no-cache" />
<meta http-equiv="Expires" content="0" />
head>
<body>
<div style="text-align: center;margin-top: 50px">
<form action="upload" method="post" enctype="multipart/form-data">
<p align="left"><input type="file" name="file"/>p>
<p align="left"><input type="submit" value="上传文件"/>p>
form>
<form action="download" >
<p align="left"><input type="input" name="filename"/>p>
<p align="left"><input type="submit" value="下载文件"/>p>
form>
div>
body>
html>
5.5 功能验证
-
访问上传页面
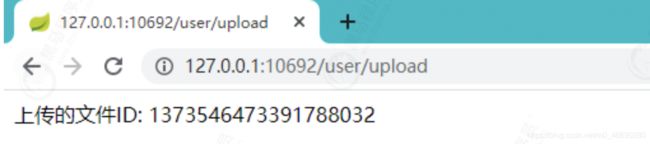
地址: http://127.0.0.1:10692/user/file -
上传成功后, 会返回文件ID:
-
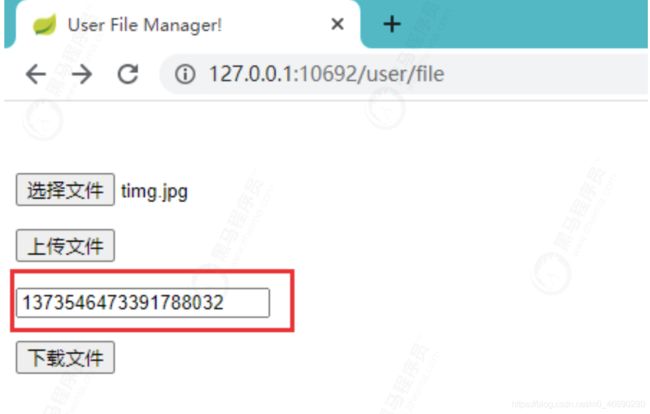
下载文件:
输入文件ID进行下载:
6. 深入Ceph原理
6.1 Crush算法与作用
CRUSH算法,全称Controlled Replication Under Scalable Hashing (可扩展哈希下的受控复制),它是一个可控的、可扩展的、分布式的副本数据放置算法, 通过CRUSH算法来计算数据存储位置来确定如何存储和检索数据。
- 保障数据分布的均衡性
- 集群的灵活伸缩性
- 支持更大规模的集群
6.2 Crush算法说明
PG到OSD的映射的过程算法称为CRUSH 算法,它是一个伪随机的过程,可以从所有的OSD中,随机性选择一个OSD集合。
Crush Map将系统的所有硬件资源描述成一个树状结构,然后再基于这个结构按照一定的容错规则生成一个逻辑上的树形结构,树的末级叶子节点device也就是OSD,其他节点称为bucket节点,根据物理结构抽象的虚拟节点,包含数据中心抽象、机房抽象、机架抽象、主机抽象。
6.3 Crush算法原理
-
Ceph的存储结构
Ceph为了保存对象,会先构建一个池(pool),把pool可以比喻成一个仓库,一个新对象的保存就类似于把一个包裹放到仓库里面。 -
PG的分配存储
对象是如何保存至哪个PG上?假设Pool名称为rbd,共有256个PG,每个PG编个号分别叫做0x0,0x1, 0x2,... 0xFF。 具体该如何分配?这里可以采用Hash方式计算。
假设有两个对象名, 分别为bar和foo的,根据对象名做Hash计算:
HASH(‘bar’) = 0x3E0A4162
HASH(‘foo’) = 0x7FE391A0
通过Hash得到一串随机的十六进制的值, 对于同样的对象名,计算出的结果能够永远保持一致,但我们预分配的是256个PG,这就需要再进行取模处理, 所得的结果会落在【0x0,0xFF】区间:
0x3E0A4162 % 0xFF ===> 0x62
0x7FE391A0 % 0xFF ===> 0xA0
实际在Ceph中, 存在很多个Pool,每个Pool里面存在若干个PG,如果两个Pool里面的PG编号相同,该如何标识区分?Ceph会对每个pool再进行编号,一个PG的实际编号是由pool_id + . + pg_id组成。 -
OSD的分配存储
Ceph的物理层,对应的是服务器上的磁盘,Ceph将一个磁盘或分区作为OSD,在逻辑层面,对象是保存至PG内,现在需要打通PG与OSD之间的联系, Ceph当中会存在较多的PG数量,如何将PG平均分布各个OSD上面,这就是Crush算法主要做的事情: 计算PG -> OSD的映射关系。
上述所知, 主要两个计算步骤:
POOL_ID(对象池) + HASH(‘对象名称’) % pg_num(归置组)==> PG_ID (完整的归置组编号)
CRUSH(PG_ID)==> OSD (对象存储设备位置) -
为什么需要采用Crush算法
如果把CRUSH(PG_ID)改成 HASH(PG_ID)% OSD_NUM 能否适用? 是会存在一些问题。
1)如果挂掉一个OSD,所有的OSD_NUM 余数就会发生变化,之前的数据就可能需要重新打乱整理, 一个优秀的存储架构应当在出现故障时, 能够将数据迁移成本降到最低,CRUSH则可以做到。
2)如果增加一个OSD, OSD_NUM数量增大, 同样会导致数据重新打乱整理,但是通过CRUSH可以保障数据向新增机器均匀的扩散, 且不需要重新打乱整理。
3)如果保存多个副本,就需要能够获取多个OSD结果的输出, 但是HASH方式只能获取一个, 但是通过CEPH的CRUSH算法可以做到获取多个结果。 -
Crush算法如何实现
每个OSD有不同的容量,比如是4T还是800G的容量,可以根据每个OSD的容量定义它的权重,以T为单位, 比如4T权重设为4,800G则设为0.8。
那么如何将PG映射到不同权重的OSD上面?这里可以直接采用CRUSH里面的Straw抽签算法,这里面的抽签是指挑取一个最长的签,而这个签值就是OSD的权重。
主要步骤: -
计算HASH: CRUSH_HASH( PG_ID, OSD_ID, r ) ==> draw 把r当做一个常数,将PG_IDOSD_ID一起作为输入,得到一个HASH值。
-
增加OSD权重: ( draw &0xffff ) * osd_weight ==> osd_straw将计算出的HASH值与OSD的权重放置一起,这样就能够得到每个OSD的签长, 权重越大的,数值越大。
-
遍历选取最高的权重:high_draw
Crush目的是随机跳出一个OSD,并且要满足权重越大的OSD,挑中的概率越大。如果样本容量足够大, 随机数对选中的结果影响逐渐变小, 起决定性的是OSD的权重,OSD的权重越大, 被挑选的概率也就越大。
Crush所计算出的随机数,是通过HASH得出来,可以保障相同的输入会得出同样的输出结果。 所 以Crush并不是真正的随机算法, 而是一个伪随机算法。
这里只是计算得出了一个OSD,在Ceph集群中是会存在多个副本,如何解决一个PG映射到多个OSD的问题?
将之前的常量r加1, 再去计算一遍,如果和之前的OSD编号不一样, 那么就选取它;如果一样的话,那么再把r+2,再重新计算,直到选出三个不一样的OSD编号。

假设常数r=0,根据算法(CRUSH_HASH & 0xFFFF) * weight 计算最大的一个OSD,结果为osd.1的0x39A00,也就是选出的第一个OSD,然后再让r=1, 生成新的CRUSH_HASH随机值,取得第二个OSD,依次得到第三个OSD。
6.4 IO流程图

步骤:
- client连接monitor获取集群map信息。
- 同时新主osd1由于没有pg数据会主动上报monitor告知让osd2临时接替为主。
- 临时主osd2会把数据全量同步给新主osd1。
- client IO读写直接连接临时主osd2进行读写。
- osd2收到读写io,同时写入另外两副本节点。
- 等待osd2以及另外两副本写入成功。
- osd2三份数据都写入成功返回给client, 此时client io读写完毕。
- 如果osd1数据同步完毕,临时主osd2会交出主角色。
- osd1成为主节点,osd2变成副本。
6.5 Ceph 通信机制
网络通信框架三种不同的实现方式:
- Simple线程模式
特点:每一个网络链接,都会创建两个线程,一个用于接收,一个用于发送。
缺点:大量的链接会产生大量的线程,会消耗CPU资源,影响性能。
- Async事件的I/O多路复用模式
特点:这种是目前网络通信中广泛采用的方式。新版默认已经使用Asnyc异步方式了。
- XIO方式使用了开源的网络通信库accelio来实现
特点:这种方式需要依赖第三方的库accelio稳定性,目前处于试验阶段。
消息的内容主要分为三部分:
header //消息头类型消息的信封
-
user data //需要发送的实际数据
payload //操作保存元数据
middle //预留字段
data //读写数据 -
footer //消息的结束标记
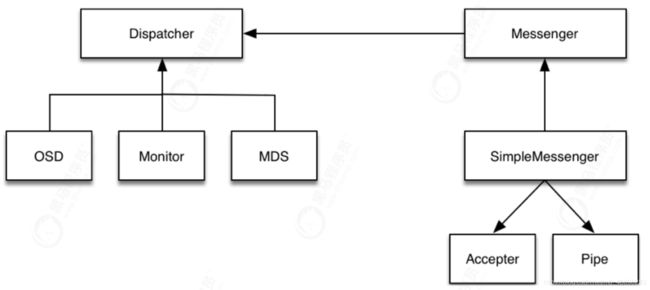
步骤: -
Accepter监听peer的请求, 调用 SimpleMessenger::add_accept_pipe() 创建新的 Pipe,给SimpleMessenger::pipes 来处理该请求。
-
Pipe用于消息的读取和发送。该类主要有两个组件,Pipe::Reader,Pipe::Writer用来处理消息读取和发送。
-
Messenger作为消息的发布者, 各个 Dispatcher 子类作为消息的订阅者, Messenger 收到消息之后, 通过 Pipe 读取消息,然后转给 Dispatcher 处理。
Dispatcher是订阅者的基类,具体的订阅后端继承该类,初始化的时候通过
Messenger::add_dispatcher_tail/head 注册到 Messenger::dispatchers. 收到消息后,通知该类处理。
DispatchQueue该类用来缓存收到的消息, 然后唤醒 DispatchQueue::dispatch_thread 线程找到后端的 Dispatch 处理消息。
6.6 Ceph RBD 块存储 IO流程图
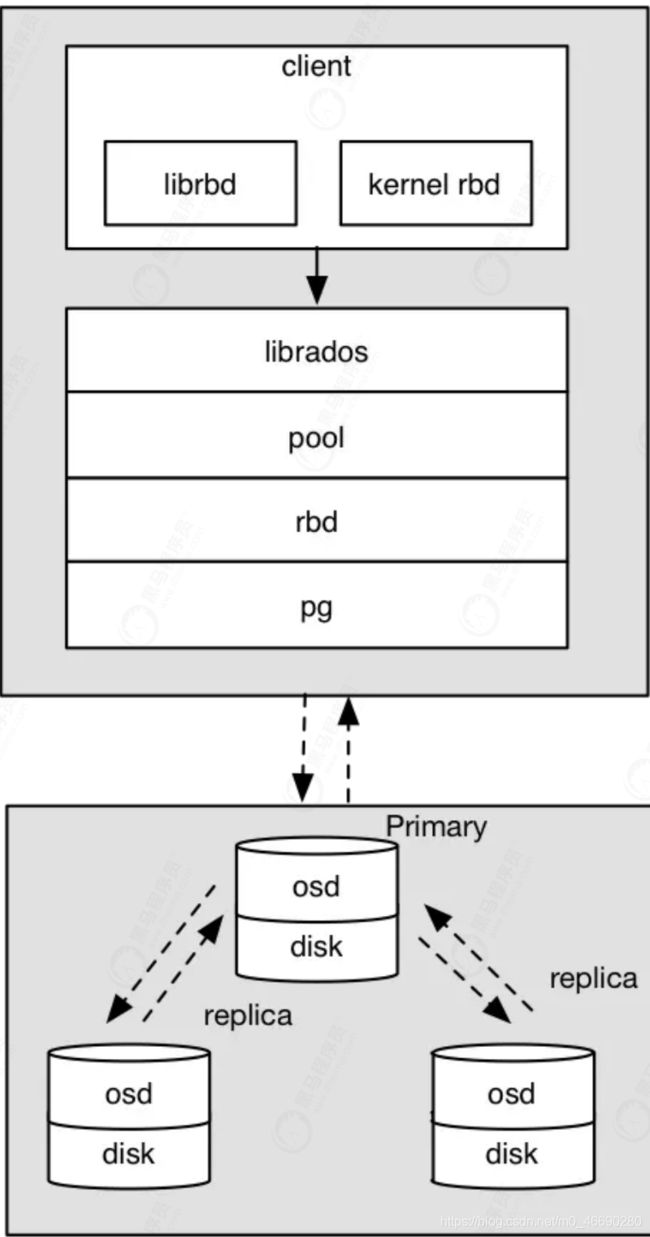
osd写入过程:
- 采用的是librbd的形式,使用librbd创建一个块设备,向这个块设备中写入数据。
- 在客户端本地通过调用librados接口,然后经过pool,rbd,object、pg进行层层映射,在PG这一层中,可以知道数据是保存在哪三个OSD上,这三个OSD分别为主从的关系。
- 客户端与primary OSD建立SOCKET 通信,将要写入的数据传给primary OSD,由primary OSD再将数据发送给其他replica OSD数据节点。
6.7 Ceph 心跳和故障检测机制
问题:
故障检测时间和心跳报文带来的负载, 如何权衡降低压力?
- 心跳频率太高则过多的心跳报文会影响系统性能。
- 心跳频率过低则会延长发现故障节点的时间,从而影响系统的可用性。
故障检测策略应该能够做到:
及时性:节点发生异常如宕机或网络中断时,集群可以在可接受的时间范围内感知。
适当的压力:包括对节点的压力,和对网络的压力。
容忍网络抖动:网络偶尔延迟。
扩散机制:节点存活状态改变导致的元信息变化需要通过某种机制扩散到整个集群。

OSD节点会监听public、cluster、front和back四个端口
- public端口:监听来自Monitor和Client的连接。
- cluster端口:监听来自OSD Peer的连接。
- front端口:客户端连接集群使用的网卡, 这里临时给集群内部之间进行心跳。
- back端口:在集群内部使用的网卡。集群内部之间进行心跳。
- hbclient:发送ping心跳的messenger(送信者)。

7. Ceph性能调优
7.1 系统配置调优
- 设置磁盘的预读缓存
echo "8192" > /sys/block/sda/queue/read_ahead_kb
- 设置系统的进程数量
echo 4194303 > /proc/sys/kernel/pid_max
- 调整CPU性能
注意: 虚拟机和部分硬件CPU可能不支持调整。
1) 确保安装了内核调整工具:
yum -y install kernel-tools
2)调整为性能模式
可以针对每个核心做调整:
echo performance > /sys/devices/system/cpu/cpu${i}/cpufreq/scaling_governor
或者通过CPU工具进行调整:
cpupower frequency-set -g performance
支持五种运行模式调整:
performance :只注重效率,将CPU频率固定工作在其支持的最高运行频率上,该模式是对系统高性能的最大追求。
powersave:将CPU频率设置为最低的所谓“省电”模式,CPU会固定工作在其支持的最低运行频率上,该模式是对系统低功耗的最大追求。
userspace:系统将变频策略的决策权交给了用户态应用程序,并提供相应接口供用户态应用程序调节CPU 运行频率使用。
ondemand: 按需快速动态调整CPU频率, 一有cpu计算量的任务,就会立即达到最大频率
运行,等执行完毕就立即回到最低频率。
conservative: 它是平滑地调整CPU频率,频率的升降是渐变式的, 会自动在频率上下限调整,和ondemand模式的主要区别在于它会按需渐进式分配频率,而不是一味追求最高频率.。
- 部分硬件可能不支持,调整会出现如下错误:
[root@CENTOS7-1 ~]# cpupower frequency-set -g performance
Setting cpu: 0
Error setting new values. Common errors:
- Do you have proper administration rights? (super-user?)
- Is the governor you requested available and modprobed?
- Trying to set an invalid policy?
- Trying to set a specific frequency, but userspace governor is not
available,
for example because of hardware which cannot be set to a specific
frequency
or because the userspace governor isn't loaded?
- 优化网络参数
修改配置文件:
vi /etc/sysctl.d/ceph.conf
配置内容:
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
执行生效:
sysctl -p /etc/sysctl.d/ceph.conf
7.2 Ceph集群优化配置
- Ceph的主要配置参数
FILESTORE配置参数
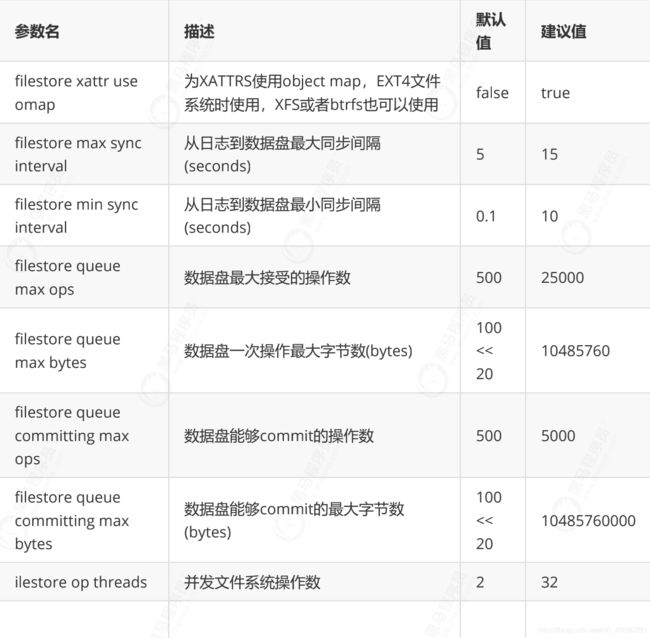
journal 配置参数:

osd config tuning 配置参数:

osd - recovery tuning 配置参数:

osd - client tuning 配置参数:

- 优化配置示例
[global]#全局设置
fsid = xxxxxxxxxxxxxxx #集群标识ID
mon initial members = CENTOS7-1, CENTOS7-2, CENTOS7-3 #初始monitor (由创建 monitor命令而定)
mon host = 10.10.20.11,10.10.20.12,10.10.20.13 #monitor IP 地址
auth cluster required = cephx #集群认证
auth service required = cephx #服务认证
auth client required = cephx #客户端认证
osd pool default size = 2 #默认副本数设置 默认是3
osd pool default min size = 1 #PG 处于 degraded 状态
不影响其 IO 能力,min_size是一个PG能接受IO的最小副本数
public network = 10.10.20.0/24 #公共网络(monitorIP 段)
cluster network = 10.10.20.0/24 #集群网络
max open files = 131072 #默认0#如果设置了该选 项,Ceph会设置系统的max open fds
##############################################################
[mon]
mon data = /var/lib/ceph/mon/ceph-$id
mon clock drift allowed = 1 #默认值0.05 #monitor间 的clock drift
mon osd min down reporters = 13 #默认值1 #向monitor报 告down的最小OSD数
mon osd down out interval = 600 #默认值300 #标记一个OSD状态为down和out之前 ceph等待的秒数
##############################################################
[osd]
osd data = /var/lib/ceph/osd/ceph-$id
osd journal size = 20000 #默认5120 #osd journal大小
osd journal = /var/lib/ceph/osd/$cluster-$id/journal #osd journal 位置
osd mkfs type = xfs #格式化系统类型
osd max write size = 512 #默认值90 #OSD一次可写入的最大值(MB)
osd client message size cap = 2147483648 #默认值100 #客户端允许在内存中的最 大数据(bytes)
osd deep scrub stride = 131072 #默认值524288 #在Deep Scrub时候允许读取的字节数(bytes)
osd op threads = 16 #默认值2 #并发文件 系统操作数
osd disk threads = 4 #默认值1 #OSD密集 型操作例如恢复和Scrubbing时的线程
osd map cache size = 1024 #默认值500 #保留OSD Map的缓存(MB)
osd map cache bl size = 128 #默认值50
#OSD进程在内存中的OSD Map缓存(MB)
osd mount options xfs = "rw,noexec,nodev,noatime,nodiratime,nobarrier" #默 认值rw,noatime,inode64 #Ceph OSD xfs Mount选项 osd recovery op priority = 2 #默认值10 #恢复操作优 先级,取值1-63,值越高占用资源越高
osd recovery max active = 10 #默认值15 #同一时间内活跃 的恢复请求数
osd max backfills = 4 #默认值10 #一 个OSD允许的最大backfills数
osd min pg log entries = 30000 #默认值3000 #修建PGLog是保留 的最大PGLog数
osd max pg log entries = 100000 #默认值10000 #修建PGLog是保留的 最大PGLog数
osd mon heartbeat interval = 40 #默认值30 #OSD ping一个 monitor的时间间隔(默认30s)
ms dispatch throttle bytes = 1048576000 #默认值 104857600 #等待派遣的最大消息数
objecter inflight ops = 819200 #默认值1024 #客户端 流控,允许的最大未发送io请求数,超过阀值会堵塞应用io,为0表示不受限
osd op log threshold = 50 #默认值5
#一次显示多少操作的log
osd crush chooseleaf type = 0 #默认值为1
#CRUSH规则用到chooseleaf时的bucket的类型
filestore xattr use omap = true #默认false#为XATTRS使 用object map,EXT4文件系统时使用,XFS或者btrfs也可以使用
filestore min sync interval = 10 #默认0.1#从日志到数据 盘最小同步间隔(seconds)
filestore max sync interval = 15 #默认5#从日志到数据盘 最大同步间隔(seconds)
filestore queue max ops = 25000 #默认500#数据盘最大接受的 操作数
filestore queue max bytes = 1048576000 #默认100 #数据盘一次操作最大 字节数(bytes
filestore queue committing max ops = 50000 #默认500 #数据盘能够commit 的操作数
filestore queue committing max bytes = 10485760000 #默认100 #数据盘能够commit的 最大字节数(bytes)
filestore split multiple = 8 # 默认值2 #前一个子目录分裂成子目录中的文件的最大数量
filestore merge threshold = 40 #默认值 10 #前一个子类目录中的文件合并到父类的最小数量
filestore fd cache size = 1024 #默认 值128 #对象文件句柄缓存大小
filestore op threads = 32 # 默认值2 #并发文件系统操作数
journal max write bytes = 1073714824 #默认值1048560
#journal一次性写入的最大字节数(bytes)
journal max write entries = 10000 #默认值 100 #journal一次性写入的最大记录数
journal queue max ops = 50000 #默认值50 #journal一次性最大在队列中的操作数
journal queue max bytes = 10485760000 #默认值33554432
#journal一次性最大在队列中的字节数(bytes)
##############################################################
[client]
rbd cache = true #默认值 true #RBD缓存
rbd cache size = 335544320 #默认值33554432 #RBD缓存大小(bytes)
rbd cache max dirty = 134217728 #默认值25165824 #缓存为write-back时允 许的最大dirty字节数(bytes),如果为0,使用write-through
rbd cache max dirty age = 30 #默认值1 #在被刷新到存储盘前 dirty数据存在缓存的时间(seconds)
rbd cache writethrough until flush = false #默认值true #该选项是为了兼容 linux-2.6.32之前的virtio驱动,避免因为不发送flush请求,数据不回写
#设置该参数后,librbd会以writethrough的方式执行io,直到收到第一个flush请求,才切换为 writeback方式。
rbd cache max dirty object = 2 #默认值0 #最大的Object对象数,默 认为0,表示通过rbd cache size计算得到,librbd默认以4MB为单位对磁盘Image进行逻辑切分
#每个chunk对象抽象为一个Object;librbd中以Object为单位来管理缓存,增大该值可以提升性能
rbd cache target dirty = 235544320 #默认值16777216 #开始执行回写过程的脏数据 大小,不能超过 rbd_cache_max_dirty
7.3 调优最佳实践
- MON建议
Ceph 集群的部署必须要正确规划,MON 性能对集群总体性能至关重要。MON 通常应位于专用节点上。为确保正确仲裁,MON 的数量应当为奇数。 - OSD建议
每一 个Ceph OSD 都具有日志。OSD 的日志和数据可能会放置于同一存储设备上。当写操作提交至 PG 中所有 OSD 的日志后,标志写操作已经完成。因此,更快的日志性能可以改进响应时间。
在典型的部署中,OSD 使用延迟较高的传统机械硬盘。为最大化效率,Ceph 建议将单独的低延迟SSD 或 NVMe 设备用于 OSD 日志。 管理员必须谨慎,不可将过多 OSD 日志放在同一设备上,因为这可能会成为性能瓶颈。应考虑以下SSD规格的影响: - 受支持写入次数的平均故障间隔时间 (MTBF)
- IOPS 能力 (Input/Output Operations Per Second),每秒的读写次数
- 数据传输速率
- 总线/SSD 耦合能力
Red Hat 建议每个 SATA SSD 设备不超过 6 个 OSD 日志,或者每个 NVMe 设备不超过 12 个 OSD日志。
-
RBD建议
RBD块设备上的工作负载通常是 I/O 密集型负载,例如在 OpenStack 中虚拟机上运行的数据库。对于 RBD,OSD 日志应当位于 SSD 或 NVMe 设备上。对于后端存储,可以根据用于支持 OSD 的存储技术(即 NVMe SSD、SATA SSD 或 HDD),提供不同的服务级别。 -
对象网关建议
Ceph 对象网关上的工作负载通常是吞吐密集型负载。如果是音频和视频资料,可能会非常大。不过,bucket 索引池可能会显示更多的 I/O 密集型工作负载模式。管理员应当将这个池存储在 SSD设备上。
Ceph 对象网关为每个 bucket 维护一个索引,Ceph 将这一索引存储在一个 RADOS 对象中。当bucket 不断增长, 数量巨大时(超过 100,000 个),索引性能会降低(因为只有一个 RADOS 对象参与所有索引操作)。
为此, Ceph 可以在多个 RADOS 对象或者是分片 中保存大型索引。管理员可以通过在ceph.conf 配置文件中设置 rgw_override_bucket_index_max_shards 配置参数来启用这项功能。此参数的建议值是 bucket 中预计对象数量除以 100,000。 -
CephFs建议
存放目录结构和其他索引的元数据池可能会成为 CephFS 的瓶颈。可以将 SSD 设备用于这个池。
每一个CephFS 元数据服务器 (MDS) 会维护一个内存中缓存,用于索引节点等不同种类的项目。Ceph 使用 mds_cache_memory_limit 配置参数限制这一缓存的大小。其默认值以绝对字节数表示,等于 1 GB,可以在需要时调优。
ceph osd map cephfs_data test_ceph
ceph osd lspools
rados ls -p default.rgw.buckets.data