tensorflow学习5 -- CNN 图像分类
这段代码是下面的博文里的源码。确实无脑复制就能用
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Flatten,Conv2D,MaxPool2D
from tensorflow.keras.datasets import mnist
#### read and preprocess data
(x_train,y_train),(x_test,y_test)=mnist.load_data()
# 所有图片整成28行28列单通道。再归一化
x_train,x_test=x_train.reshape([-1,28,28,1])/255.0,x_test.reshape([-1,28,28,1])/255.0
#### contruct the model
model=Sequential()
model.add(Conv2D(filters=32,kernel_size=(3,3),activation='relu',input_shape=(28,28,1)))
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Conv2D(filters=64,kernel_size=(3,3),activation='relu'))
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Flatten()) ##把卷积完之后的很多"小图片合并拉直"
model.add(Dense(10))# 标签有10类,所以输出是10类
#### compile ; fit ; evaluate
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam",
metrics=['accuracy'])
model.fit(x=x_train,y=y_train,batch_size=100,epochs=20,verbose=2)
model.evaluate(x=x_test,y=y_test,verbose=2)
TensorFlow2—20行代码实现CNN分类图片的例子
先要把数据换成自己的。
先按下面这个教程搞
基于Tensorflow + Opencv 实现CNN自定义图像分类
先看看别人的数据是啥样的
print(x_train[0,20]) #这样是看到数据,第0张的第20行
import matplotlib.pyplot as plt
plt.imshow(x_train[0])
plt.show()
显示图片的教程
创建文件夹
分成两类放在了桌面

读入文件夹
读入文件路径有点问题,所以搞一段代码测试一下
for i in os.listdir('C:/Users/WQuiet/Desktop/TFphoto/'):
fulldirct = os.path.join('C:/Users/WQuiet/Desktop/TFphoto/',i)
print(fulldirct)
listdir只能读取绝对路径,而且文件夹里复制来的路径是C:\Users\WQuiet\Desktop\TFphoto\1
斜杠要反一下,不反会报错。SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated \UXXXXXXXX escape
但是,C:/Users/WQuiet/Desktop/TFphoto/ 最后的斜杠去掉之后程序自动补上的却是 \
双标怪啊啊啊。
总之下面这个是能正确读入的
def read_img(path):
cate = [path + x for x in os.listdir(path) if os.path.isdir(path + x)]
print(cate)# ['C:/Users/WQuiet/Desktop/TFphoto/0', 'C:/Users/WQuiet/Desktop/TFphoto/1']
read_img('C:/Users/WQuiet/Desktop/TFphoto/')
python中os.path.isdir()等函数的作用和用法
然后看一下读入的图片
for idx,folder in enumerate(cate):
for im in glob.glob(folder + '/*.bmp'):
print('images: %s' % (im))
img=cv2.imread(im)
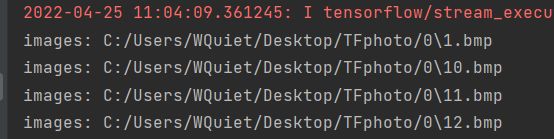
plt.imshow(img)
plt.show()
好消息,这样是自动暂停一个个展示给你的。
坏消息,RGB图像是按BGR来读取的,所以我的图变成蓝色了

而且你这个顺序让我很难做事啊大哥。。。算了,想了想好像没所谓。有空可以读下面这个链接处理一下顺序
python中os.listdir( )函数读取文件夹
img=cv2.imread(im,cv2.IMREAD_GRAYSCALE)
print(img)
plt.imshow(img)
plt.show()
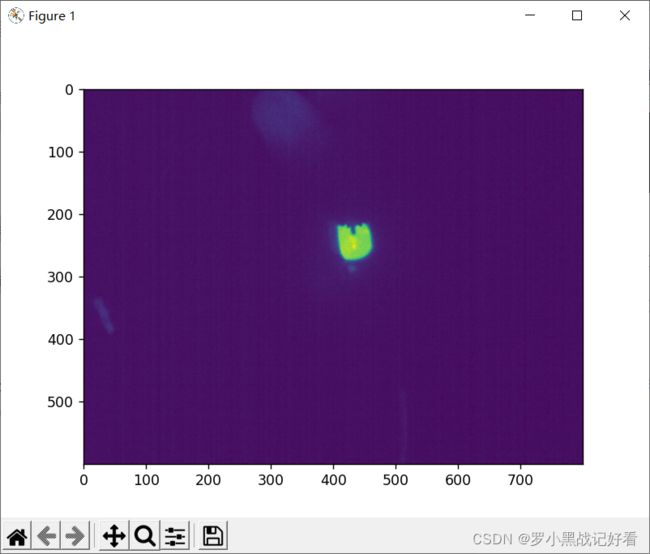
灰度化看起来没用,但是输出的纯数据的通道确实变成了1通道。我不太确定是不是plt这个显示的设置问题。
python3读取图片并灰度化图片的四种方法(OpenCV、PIL.Image、TensorFlow方法)总结
【一集罗小黑战记之后】
确实是plt的问题。
plt.imshow(img,cmap=“gray”)能设定为按灰度图显示,不过如果img本身不是灰度图而是三通道图片的话,显示的还是彩色图。
def read_img(path):
cate = [path + x for x in os.listdir(path) if os.path.isdir(path + x)]
# print(cate)# ['C:/Users/WQuiet/Desktop/TFphoto/0', 'C:/Users/WQuiet/Desktop/TFphoto/1']
for idx,folder in enumerate(cate):
for im in glob.glob(folder + '/*.bmp'):
print('images: %s' % (im))
img=cv2.imread(im,cv2.IMREAD_GRAYSCALE) # ,cv2.IMREAD_GRAYSCALE
# img = img[:, :, (2, 1, 0)] # RGB图像按BGR读入
print(img)
plt.imshow(img,cmap="gray")
plt.show()
Python读取图像并显示灰度图
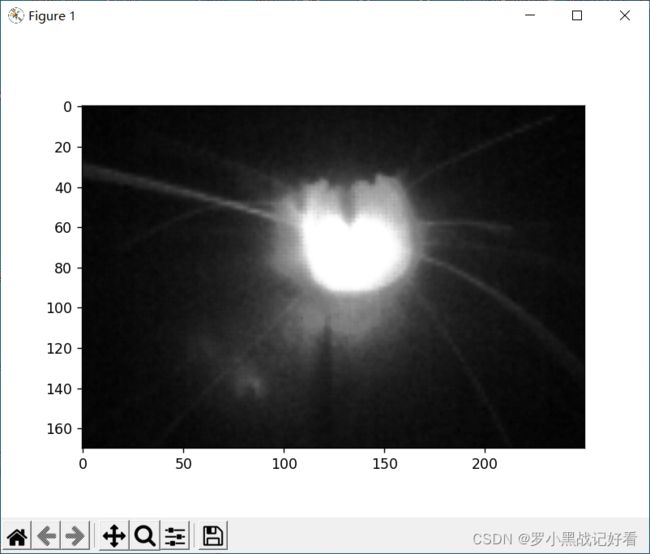
压缩图片大小
img=cv2.resize(img,(32,32))
毕竟800*600确实太大了。但这样压缩的话就。。。啧,得先搞出ROI区域了。。那不就偏题了嘛,先随便切片一下吧。
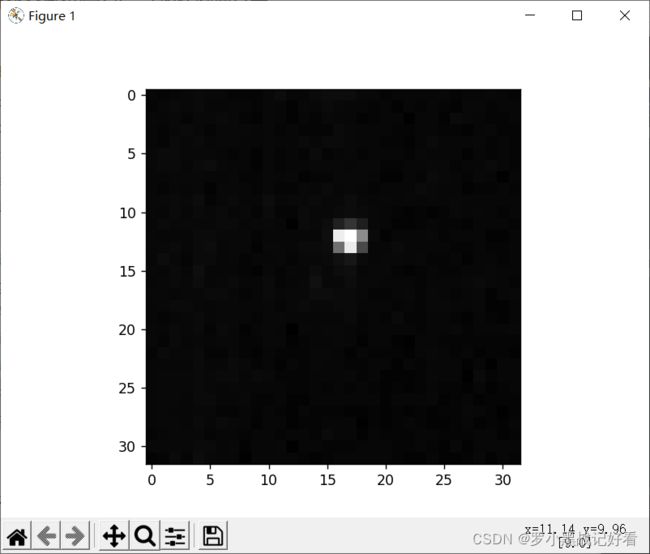
img=img[180:350 , 300:550]

可以,满意。
挨个保存并返回数据
def read_img(path):
imgs=[]
labels=[]
fpath=[]
cate = [path + x for x in os.listdir(path) if os.path.isdir(path + x)]
for idx,folder in enumerate(cate):
for im in glob.glob(folder + '/*.bmp'):
img=cv2.imread(im,cv2.IMREAD_GRAYSCALE) # ,cv2.IMREAD_GRAYSCALE
img=img[180:350 , 300:550]# 切出ROI区域
img=cv2.resize(img,(32,32))# 压缩图片
imgs.append(img)
labels.append(idx) # 文件夹名就是分类标记 我记为0和1
fpath.append( im)# C:/Users/WQuiet/Desktop/TFphoto/0\13.bmp
return np.asarray(fpath, np.string_), np.asarray(imgs, np.uint8), np.asarray(labels, np.int8)
fpaths, data, label = read_img('C:/Users/WQuiet/Desktop/TFphoto/')
划分数据
打乱图片顺序,然后二八分成
fpaths, data, label = read_img('C:/Users/WQuiet/Desktop/TFphoto/')
print(data.shape) # (122, 32, 32)
num_classes =2 # len(set(label))#计算有多少类图片: 一堆的0和1 放在set里,自动去重并且排序 但没必要,我知道只有两类,写个2省时间
num_example=data.shape[0]
arr = np.arange(num_example)# 把图片数量变成 [0,1……,总数]
np.random.shuffle(arr)# 打乱排序
data = data[arr]
label = label[arr]
fpaths = fpaths[arr]
# 80%训练集 20%测试集
ratio=0.8
s=np.int(num_example * ratio)
x_train = data[:s]
y_train = label[:s]
fpaths_train = fpaths[:s]
x_val = data[s:]
y_val = label[s:]
fpaths_test = fpaths[s:]
print(len(x_train),len(y_train),len(x_val),len(y_val))#97 97 25 25
可以移花接木了
x_train,y_train,x_test,y_test 数据换成自己的之后。再把构建网络的第一层输入形状改成自己的图片大小和最后一层输出的种类数量改掉就行。
import glob
import os
import numpy as np
import cv2
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Flatten,Conv2D,MaxPool2D
import matplotlib.pyplot as plt
def read_img(path):
imgs=[]
labels=[]
fpath=[]
cate = [path + x for x in os.listdir(path) if os.path.isdir(path + x)]
for idx,folder in enumerate(cate):
for im in glob.glob(folder + '/*.bmp'):
img=cv2.imread(im,cv2.IMREAD_GRAYSCALE) # ,cv2.IMREAD_GRAYSCALE
img=img[180:350 , 300:550]# 切出ROI区域
img=cv2.resize(img,(32,32))# 压缩图片
imgs.append(img)
labels.append(idx) #文件夹名就是分类标记 我记为0和1
fpath.append( im)# C:/Users/WQuiet/Desktop/TFphoto/0\13.bmp
return np.asarray(fpath, np.string_), np.asarray(imgs, np.uint8), np.asarray(labels, np.int8)
fpaths, data, label = read_img('C:/Users/WQuiet/Desktop/TFphoto/')
#print(data.shape) # (122, 32, 32)
num_classes =2 # len(set(label))#计算有多少类图片: 一堆的0和1 放在set里,自动去重并且排序 但没必要,我知道只有两类,写个2省时间
num_example=data.shape[0]
arr = np.arange(num_example)# 把图片数量变成 [0,1……,总数]
np.random.shuffle(arr)# 打乱排序
data = data[arr]
label = label[arr]
fpaths = fpaths[arr]
# 80%训练集 20%测试集
ratio=0.8
s=np.int(num_example * ratio)
x_train = data[:s]
y_train = label[:s]
fpaths_train = fpaths[:s]
x_test = data[s:]
y_test = label[s:]
fpaths_test = fpaths[s:]
#print(len(x_train),len(y_train),len(x_test),len(y_test))#97 97 25 25
x_train,x_test=x_train.reshape([-1,32, 32,1])/255.0,x_test.reshape([-1,32, 32,1])/255.0
#### contruct the model
model=Sequential()
model.add(Conv2D(filters=32,kernel_size=(3,3),activation='relu',input_shape=(32, 32,1)))
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Conv2D(filters=64,kernel_size=(3,3),activation='relu'))
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Flatten()) ##把卷积完之后的很多"小图片合并拉直"
model.add(Dense(2))# 标签有2类
#### compile ; fit ; evaluate
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam",
metrics=['accuracy'])
model.fit(x=x_train,y=y_train,batch_size=100,epochs=20,verbose=2)
model.evaluate(x=x_test,y=y_test,verbose=2)
Epoch 1/20
1/1 - 0s - loss: 0.7157 - accuracy: 0.4227
Epoch 2/20
1/1 - 0s - loss: 0.6620 - accuracy: 0.5773
Epoch 3/20
1/1 - 0s - loss: 0.6217 - accuracy: 0.5773
Epoch 4/20
1/1 - 0s - loss: 0.5918 - accuracy: 0.5773
Epoch 5/20
1/1 - 0s - loss: 0.5684 - accuracy: 0.5773
Epoch 6/20
1/1 - 0s - loss: 0.5491 - accuracy: 0.5773
Epoch 7/20
1/1 - 0s - loss: 0.5322 - accuracy: 0.5773
Epoch 8/20
1/1 - 0s - loss: 0.5159 - accuracy: 0.5773
Epoch 9/20
1/1 - 0s - loss: 0.4978 - accuracy: 0.5773
Epoch 10/20
1/1 - 0s - loss: 0.4771 - accuracy: 0.5773
Epoch 11/20
1/1 - 0s - loss: 0.4533 - accuracy: 0.5773
Epoch 12/20
1/1 - 0s - loss: 0.4274 - accuracy: 0.5979
Epoch 13/20
1/1 - 0s - loss: 0.4001 - accuracy: 0.7423
Epoch 14/20
1/1 - 0s - loss: 0.3725 - accuracy: 0.9175
Epoch 15/20
1/1 - 0s - loss: 0.3451 - accuracy: 0.9794
Epoch 16/20
1/1 - 0s - loss: 0.3180 - accuracy: 0.9794
Epoch 17/20
1/1 - 0s - loss: 0.2908 - accuracy: 0.9897
Epoch 18/20
1/1 - 0s - loss: 0.2630 - accuracy: 0.9794
Epoch 19/20
1/1 - 0s - loss: 0.2347 - accuracy: 0.9794
Epoch 20/20
1/1 - 0s - loss: 0.2070 - accuracy: 0.98971/1 - 0s - loss: 0.2029 - accuracy: 1.0000
速度超快欸
怎么看它识别的结果呢…
TF官网入门教程
照着改了改,效果不错
绘制可视化窗口
class_names = ['bright', 'extinguish']# 写俩标签代替0和1
#输入 序号,预测概率,真实标签,小图片
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array, true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
# 预测对了用蓝色,错了用红色
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
# 括号里是真实标签
进行预测
附加一个 softmax 层,将 logits 转换成更容易理解的概率。
probability_model = tf.keras.Sequential([model,
tf.keras.layers.Softmax()])
predictions = probability_model.predict(x_test)
predictions[0]是第一张图片的预测概率,print出来是[0.1353 0.8647]这样的
可视化
num_rows = 5
num_cols = 5
num_images = num_rows*num_cols
plt.figure(figsize=(2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, num_cols, i+1)
plot_image(i, predictions[i], y_test, x_test) # 子函数
plt.tight_layout()
plt.show()
效果不错
每次重新再运行一遍 它的预测概率都会变.是因为每次训练数据打乱排序的情况不一样吧.
class_names = ['bright', 'extinguish']
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array, true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
probability_model = tf.keras.Sequential([model,
tf.keras.layers.Softmax()])
predictions = probability_model.predict(x_test)
num_rows = 5
num_cols = 5
num_images = num_rows*num_cols
plt.figure(figsize=(2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, num_cols, i+1)
plot_image(i, predictions[i], y_test, x_test)
plt.tight_layout()
plt.show()
Epoch 20/20
1/1 - 0s - loss: 0.1488 - accuracy: 0.9897
1/1 - 0s - loss: 0.1388 - accuracy: 0.9600

保存模型
总不能每次都训练一遍吧.我接下来要拿没有标签的数据去预测了.要先保存模型.
保存
save()既保持了模型的图结构,又保存了模型的参数。
save_weights()只保存了模型的参数,但并没有保存模型的图结构。所以它的size小很多,但读取模型的时候不仅要自己再写一遍一模一样的模型结构,还要写一模一样的原始参数
keras保存模型中的save()和save_weights()
在model.fit()后面加上下文这句话就可以保存模型了,一运行就会在代码文件的目录下新建文件夹保存模型
model.save('saved_model/my_model')
加载
替代模型建立的部分就好
保留输入数据的部分,直到分好数据集和训练集都不要删
然后下面代码的第一句没问题,正常读入之后可以用new_model.summary()看出新模型的结构 它和训练完成后的模型数据是一样的
但是第二句运行报错了
new_model = tf.keras.models.load_model('saved_model/my_model')
loss, acc = new_model.evaluate(x=x_test,y=y_test,verbose=2)# 评估准确率
报错
ValueError: Input 0 of layer sequential is incompatible with the
layer: expected ndim=4, found ndim=3. Full shape received: [None, 32,
32]
Keras报错:ValueError: Input 0 is incompatible with layer sequential expected shape=(None, None, 22),
ValueError : 层 lstm 的输入 0 与层不兼容:预期 ndim=3,发现 ndim=2.收到的完整形状:[无,18]
总之报错意思就是,输入的数据维数不对,我的应该是4维(25, 32, 32, 1) 但是上面输入图片的时候是灰度图,没写这个通道数,形状是(25, 32, 32)
所以我
x_test=np.expand_dims(x_test, 3)# 在x_test的第三个位置插入一个维度
numpy中expand_dims()函数详解
能用了
额,这孩子怎么错得这么自信…是因为扩张了维度还是这个模型本身不对劲…

多运行了几次,有一次是
1/1 - 0s - loss: 0.0000e+00 - accuracy: 1.0000
这下出来是全对的.
不过主要问题还是
之前训练的时候识别错误的时候概率是在50%左右的,现在用这个模型识别错误的时候概率是90%+
不晓得怎么回事
总之再放上代码
import glob
import os
import numpy as np
import cv2
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Flatten,Conv2D,MaxPool2D
import matplotlib.pyplot as plt
def read_img(path):
imgs=[]
labels=[]
fpath=[]
cate = [path + x for x in os.listdir(path) if os.path.isdir(path + x)]
for idx,folder in enumerate(cate):
for im in glob.glob(folder + '/*.bmp'):
img=cv2.imread(im,cv2.IMREAD_GRAYSCALE) # ,cv2.IMREAD_GRAYSCALE
img=img[180:350 , 300:550]# 切出ROI区域
img=cv2.resize(img,(32,32))# 压缩图片
imgs.append(img)
labels.append(idx) #文件夹名就是分类标记 我记为0和1
fpath.append( im)# C:/Users/WQuiet/Desktop/TFphoto/0\13.bmp
return np.asarray(fpath, np.string_), np.asarray(imgs, np.uint8), np.asarray(labels, np.int8)
fpaths, data, label = read_img('C:/Users/WQuiet/Desktop/TFphoto/')
#print(data.shape) # (122, 32, 32)
num_classes =2 # len(set(label))#计算有多少类图片: 一堆的0和1 放在set里,自动去重并且排序 但没必要,我知道只有两类,写个2省时间
num_example=data.shape[0]
arr = np.arange(num_example)# 把图片数量变成 [0,1……,总数]
np.random.shuffle(arr)# 打乱排序
data = data[arr]
label = label[arr]
fpaths = fpaths[arr]
# 80%训练集 20%测试集
ratio=0.8
s=np.int(num_example * ratio)
x_train = data[:s]
y_train = label[:s]
fpaths_train = fpaths[:s]
x_test = data[s:]
y_test = label[s:]
fpaths_test = fpaths[s:]
x_test=np.expand_dims(x_test, 3)
print(x_test.shape , y_test.shape)
# x_train,x_test=x_train.reshape([-1,32, 32,1])/255.0,x_test.reshape([-1,32, 32,1])/255.0
# #### contruct the model
# model=Sequential()
# model.add(Conv2D(filters=32,kernel_size=(3,3),activation='relu',input_shape=(32, 32,1)))
# model.add(MaxPool2D(pool_size=(2,2)))
# model.add(Conv2D(filters=64,kernel_size=(3,3),activation='relu'))
# model.add(MaxPool2D(pool_size=(2,2)))
# model.add(Flatten()) ##把卷积完之后的很多"小图片合并拉直"
# model.add(Dense(2))# 标签有2类
# #### compile ; fit ; evaluate
# model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
# optimizer="adam",
# metrics=['accuracy'])
# model.fit(x=x_train,y=y_train,batch_size=100,epochs=20,verbose=2)
# model.evaluate(x=x_test,y=y_test,verbose=2)# 评估准确率
# model.save('saved_model/my_model')
#
new_model = tf.keras.models.load_model('saved_model/my_model')
loss, acc = new_model.evaluate(x=x_test,y=y_test,verbose=2)# 评估准确率
# print('Restored model, accuracy: {:5.2f}%'.format(100 * acc))
#
# print(new_model.predict(x_test).shape)
#
# 进行预测
class_names = ['bright', 'extinguish']
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array, true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
probability_model = tf.keras.Sequential([new_model,
tf.keras.layers.Softmax()])
predictions = probability_model.predict(x_test)
num_rows = 5
num_cols = 5
num_images = num_rows*num_cols
plt.figure(figsize=(2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, num_cols, i+1)
plot_image(i, predictions[i], y_test, x_test)
plt.tight_layout()
plt.show()
使用模型
现在使用的图片是没有分好类的图片,所以读取图片就删改了一些
因为要在识别完成后重新把图片分到别的文件夹,所以要先用source 存住原图
别的就不用细讲了吧。
import glob
import os
import numpy as np
import cv2
import tensorflow as tf
source = []
def read_img(path):
imgs=[]
fpath=[]
for im in glob.glob(path + '/*.bmp'):
img=cv2.imread(im,cv2.IMREAD_GRAYSCALE) # ,cv2.IMREAD_GRAYSCALE
source.append(img)
img=img[180:350 , 300:550]# 切出ROI区域
img=cv2.resize(img,(32,32))# 压缩图片
imgs.append(img)
fpath.append(im)# C:/Users/WQuiet/Desktop/TFphoto/0\13.bmp
return np.asarray(fpath, np.string_), np.asarray(imgs, np.uint8)
fpaths, data= read_img('C:/Users/WQuiet/Desktop/bk23_10z_feng/')
# print(fpaths)
data=np.expand_dims(data, 3)
new_model = tf.keras.models.load_model('saved_model/my_model')
class_names = ['bright', 'extinguish']
probability_model = tf.keras.Sequential([new_model,
tf.keras.layers.Softmax()])
figure_save_path = "bright" # 这里创建了一个文件夹,如果依次创建不同文件夹,可以用name_list[i]
if not os.path.exists(figure_save_path):
os.makedirs(figure_save_path) # 如果不存在目录figure_save_path,则创建
figure_save_path = "extinguish" # 这里创建了一个文件夹,如果依次创建不同文件夹,可以用name_list[i]
if not os.path.exists(figure_save_path):
os.makedirs(figure_save_path) # 如果不存在目录figure_save_path,则创建
predictions = probability_model.predict(data)
cunt = len(predictions[:, 0])
for i in range(cunt):
predicted_label = np.argmax(predictions[i])
# 指定图片保存路径
if predicted_label:
cv2.imwrite("E:/my_python_workplace/extinguish/"+str(i)+".bmp",source[i])
else:
cv2.imwrite("E:/my_python_workplace/bright/" + str(i) + ".bmp", source[i])