图像检索系列——利用深度学习实现以图搜图
转载自:图像检索系列——利用深度学习实现以图搜图 - 知乎
前言
在上一篇文章《图像检索系列——利用 Python 检测图像相似度》中,我们介绍了一个在图像检索领域非常常用的算法——感知哈希算法。这是一个很简单且快速的算法,其原理在于针对每一张图片都生成一个特定的“指纹”,然后采取一种相似度的度量方式得出两张图片的近似程度。
然而随着深度学习的崛起,极大的推动了图像领域的发展,在提取特征这方面而言,神经网络目前有着不可替代的优势。在上一篇文章中我们也介绍了图像检索往往是基于图像的特征比较,看特征匹配的程度有多少,从而检索出相似度高的图片。而检测图像特征,VGG16具有得天独厚的优势。
接下来本文将会通过一个简单的案例来实现一个基于深度学习的图像检索小工具。
准备工作
老样子,先来准备好我们此次需要使用到的工具:
- IDE:Pycharm
- Python:3.7
- Packages:Keras + TensorFlow + Pillow + Numpy
keras
Keras是一个高层神经网络API,Keras由纯Python编写而成并基Tensorflow、Theano以及CNTK后端。简单来说,keras就是对TF等框架的再一次封装,使得使用起来更加方便。
基于vgg16网络提取图像特征 我们都知道,vgg网络在图像领域有着广泛的应用,后续许多层次更深,网络更宽的模型都是基于此扩展的,vgg网络能很好的提取到图片的有用特征,本次实现是基于Keras实现的,提取的是最后一层卷积特征。
思路
主要思路是基于CVPR2015的论文《Deep Learning of Binary Hash Codes for Fast Image Retrieval》实现的海量数据下的基于内容图片检索系统。简单说来就是对图片数据库的每张图片抽取特征(一般形式为特征向量),存储于数据库中,对于待检索图片,抽取同样的特征向量,然后并对该向量和数据库中向量的距离(相似度计算),找出最接近的一些特征向量,其对应的图片即为检索结果。如下图所示:
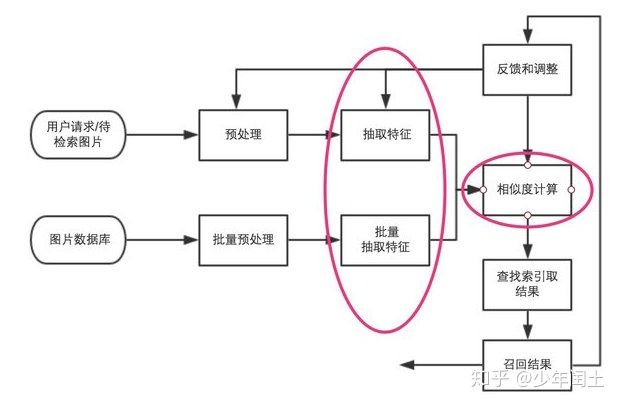
用户请求和预处理部分主要是Web服务端应该做的,这里不加以讨论,接下来我们主要进行红线标注部分的实现。
实操
提取图片特征
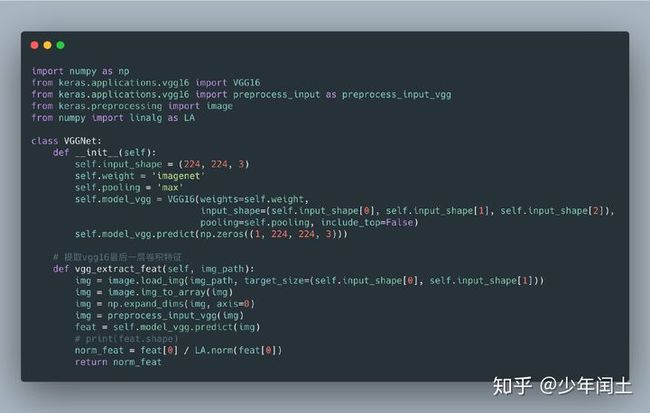
keras在其中文文档中提供了一个利用VGG16提取特征的demo
from keras.applications.vgg16 import VGG16
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input
import numpy as np
model = VGG16(weights='imagenet', include_top=False)
img_path = 'elephant.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
features = model.predict(x)这里我们需要对其进行简单修改,封装成一个类以便后期调用。如下图所示:
考虑到篇幅,文中代码图片已删除较多注释,如需了解详细注释信息,可在微信公众号「01二进制」后台回复「图像检索」获取源代码。下同
将特征以及对应的文件名保存为h5文件
什么是 h5 文件
h5文件是层次数据格式第5代的版本(Hierarchical Data Format,HDF5),用以存储和组织大规模数据。
H5将文件结构简化成两个主要的对象类型:
- 数据集dataset,就是同一类型数据的多维数组
- 组group,是一种容器结构,可以包含数据集和其他组,若一个文件中存放了不同种类的数据集,这些数据集的管理就用到了group
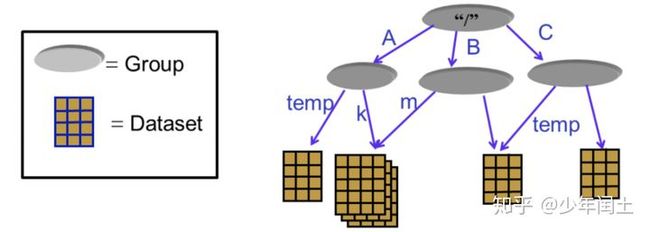
直观的理解,可以参考我们的文件系统,不同的文件存放在不同的目录下:
目录就是 hdf5 文件中的 group,描述了数据集 DataSet 的分类信息,通过 group 有效的将多种 dataset 进行管理和划分。文件就是 hdf5 文件中的 dataset,表示具体的数据
下图就是数据集和组的关系:
在 Python 中,我们通常使用 h5py 库对 .h5 文件进行操作,具体的读写方法自行百度,这里不在演示。
抽取数据集中的图像特征保存到 h5 文件中
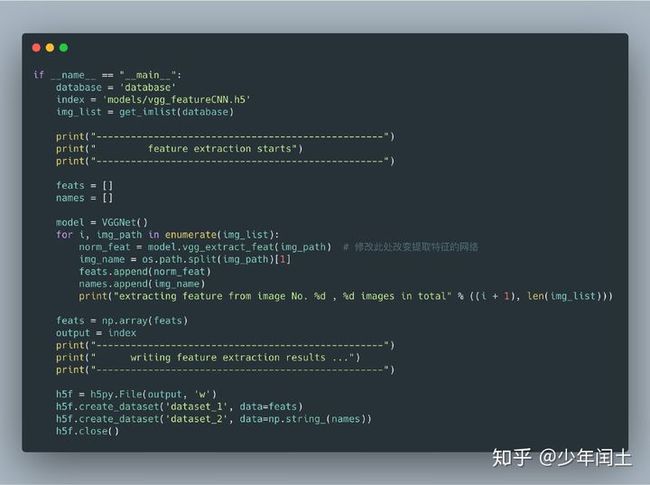
我们在项目根目录下命名一个database文件夹作为数据集,然后编写一个获取文件夹内图片的方法:
def get_imlist(path):
return [os.path.join(path, f) for f in os.listdir(path) if f.endswith('.jpg')]随后我们便可以依次读取数据然后,一一提取其特征保存到文件中了。如下图:
至此,我们就已经算是完成了模型的训练了。
选一张测试图片测试检索效果
经过上述操作,我们已经将数据集中的所有图片的特征保存到模型中了,剩下的就是抽取待测图片的特征,然后和特征集中的特征一一比较向量间的相似度(余弦相似度),然后按照相似度排序返回给用户即可。
Tips:各种相似度的 Python 表示可以参考 Python Numpy计算各类距离

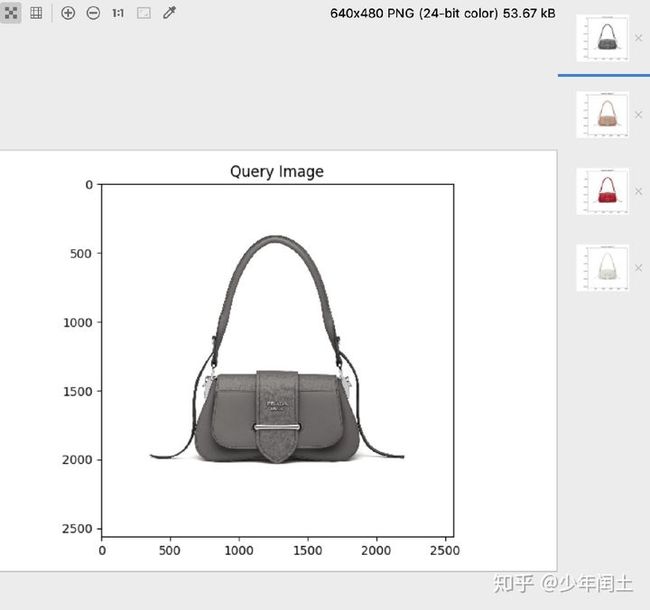
以某一个包包为测试图片,输出结果如下所示:

在PyCharm中可以很方便的查看matplotlib生成的图片,第一张为测试图片,后面三张为检索图片,可以看出效果相当好了。
Tips:如果想用Resnet或者Densenet提取特征,只需针对上述代码做出相应的修改,去掉注释修改部分代码即可。详见源码。
最后
至此我们已经利用深度学习实现了一个图片检索的小工具了,如何将其和web/app结合到一起就不在本文的讨论范围了,有兴趣可以下载本文源码自行更改,也可扫描下方二维码关注微信公众号「01二进制」与我取得联系。
参考
- 深度学习与计算机视觉(11)_基于deep learning的快速图像检索系统
- 基于VGG-16的海量图像检索系统(以图搜图升级版)
- 基于深度学习实现以图搜图功能
- 各种相似度计算的python实现
- Application应用
- Python Numpy计算各类距离
- h5文件简介
附:对论文《Deep Learning of Binary Hash Codes for Fast Image Retrieval》的翻译,基于二进制哈希编码快速学习的快速图像检索。