(八)Python总结笔记:Numpy
Python总结笔记(八)Numpy
- 构建 ndarray
- numpy 数据类型及转换
- ndarray 基本属性
- NDArray 读取
- NDArray 赋值
- NDArray 维度(行列)操作
- Numpy 运算
- ndarray 对象内部运算
- 高级的 ndarray 处理
- ndarray 对象的输入与输出
- 附:Numpy 常用函数
Numpy:
标准安装的 Python 中用列表(list)保存一组值,可以用来当作数组使用,不过由于列表的元素可以是任何对 象,因此列表中所保存的是对象的指针。这样为了保存一个简单的[1,2,3],需要有 3 个指针和三个整数对象。 对于数值运算来说这种结构显然比较浪费内存和 CPU 计算时间。
虽然 Python 还提供了一个 array 模块,array 对象和列表不同,它直接保存数值,和 C 语言的一维数组比较类 似。但是由于它不支持多维,也没有各种运算函数,因此也不适合做数值运算。
NumPy 的诞生弥补了这些不足,NumPy 提供了两种基本的对象:ndarray(N-dimensional array object)和 ufunc(universal function object)。ndarray 是存储单一数据类型的多维数组,而 ufunc 则是能够对数组进行处理的函数。
Numpy 是 Python 下的一个 library。numpy 最主要的是支持矩阵操作与运算,非常高效是 numpy 的优势,core为 C 编写。提升了 python 的处理效率,同时 numpy 也是一些与比较流行的机器学习框架的基础。
- 构建 ndarray
- 构建一维数组 :n1=np.array([1,2,3])
- 构建二维数组:n2= np.array([[1,2,3],[4,5,6]])
- 从 Python 数组构建:l1=[1,2,3,4,5] l2=np.array(l1)
- ndarray 转为 list:l3=list(l2) # ndarray 转为 Python list
快速构建 ndarray
- 序列创建:np.arange(15)#类似于 python 中的 range,创建一个第一个维度为 15 的 ndarray 对象。
np.arange(2,3,0.1) #起点,终点,步长值。含起点值,不含终点值。
np.linspace(1,10,10) #起点,终点,区间内点数。起点终点均包括在内。
np.arange(0,1,0.1) #0 到 1 之间步长为 0.1 的数组, 数组中不包含 1
np.linspace(0, 1, 5) # 开始:0, 结束 1, 元素数 5。 - 空矩阵:np.empty((6,6))#空的 ndarray,指定其 shape 即可,注意:空不意味着值为 0,而是任何的 value,内存中没有被初始化的。
- 对角线矩阵:np.eye(3)# 对角线矩阵
- 随机数矩阵:np.random.rand(3,2) #随机数矩阵。
关于随机数方法:rand:返回均匀分布随机数 randn:返回服从正态分布的随机数 - 指定数字矩阵: a = np.random.rand(5,5)#指定数字矩阵 fill()函数 a.fill(7)
- 随机打乱矩阵:np.random.shuffle(a)
- 0,1 矩阵:z= np.zeros((2,3)) #建立 23 的 0 值矩阵, 注意:传入参数是一个 tuple,因此别忘了() z= np.ones((5,7)) #建立 57 的 1 值矩阵,注意:传入参数是一个 tuple,因此别忘了()
- 根据某个矩阵的形态创建一个矩阵np.ones_like()
- np.c_[arr1,arr2]或者np.r_[arr1,arr2]用于按行按列堆叠。c 即 column,r即row。Eg:np.c_[1:6,-5:0]
- numpy 数据类型及转换
- 判断数据类型:a.dtype # Numpy 会自动根据 ndarray 对象中的值判定数据类型,这里为整型。
- 转换数据类型:d1.astype(np.float32)# 如果想把它强制转为浮点型,可以用 astype 函数转换。
- 指定数据类型:np.array([1,2,3,4],dtype=np.float32)# 也可以在创建 ndarray 时,即指定其数据类型
- ndarray 基本属性
- ndarray.ndim 查看 ndarray 的 dimension 维度数。
- ndarray.shape 查看ndarray的shape形状,返回值 是一个tuple,当维数为2维时,返回的是行数、列数、…数组的各个维 (注意和维和维数要区分开)。它是一个数组各个维的长度构成的整数元组。对 n 行 m 列矩阵而言,shape 将是 (n,m)。因此,shape 元组的长度也就是 rank,也是维数 ndim。
- ndarray.dtype 查看 ndarray 对象的数据类型
- ndarray.size 查看 ndarray 对象中元素的数量
- NDArray 读取
读取:
- 切片读取:在 numpy 中是按行,列两个维度进行切片。(如果 ndarray 的 ndim 超过 2,也是遵循同时的方式进行访问)
a[:,:]#第一个冒号代表所有的行,第二个冒号代表所有的列。这样会比较容易理解。
a[2:,2:]
a[:,1:3]#第一个冒号代表选中所有行,第二个参数 1:3 代表从第2列到第 3 列。同样遵循 python 的左闭右开的切片访问规则。 - 索引访问
a[[2],[0,2]]#第一个参数[2]代表先选中第 3 行。第二个参数[0,2],代表选中了第一个和第三个元素。#注意,使用索引访问时,索引值要放进[]或者() 中,代表传入一个列表。
a[(0,1),(0,1)]# 访问(0,0)和(1,1)两个数
用布尔类型的数组做为索引传入,对下标进行过滤。
bool_a=a>2
bool_a #输出满足上述条件的,由True和Flase构成的数组
a[bool_a]#输出满足条件的值
- 切片与索引混合访问
访问 ndarray 的方式非常灵活,可以使用切片与索引可以混合进行访问。 a[[1,2],:]
遍历读取:
对于 ndarray,也可以像对待 Python 中的可迭代对象一样,对它进行遍历。
for i in a:
print(i)
- NDArray 赋值
赋值:取出元素后,加=即可。
- NDArray 维度(行列)操作
-
ndarray 对象维度变换 --reshape 变换:
np.arange(16).reshape(2,8).shape这里先用 arange 生成了从 0 到 15 的一维数组,然后使用 reshape,将这个数组的形态改变为有行与列两个维度 (2 行 8 列)#注意这个形状的乘积必须和总的元素个数相同,否则将会报错。
np.arange(16).reshape(1,16)代表有两个维度。
np.arange(16).reshape(2,2,4)代表有 3 个维度,也可以这样去理解:2块2行2列。 -
增维操作 np.newaxis
import numpy as np
x=np.linspace(-1,1,100)
x.shape#(100,)有100个元素
x[:,np.newaxis].shape #(100,1)加一列
x[np.newaxis,:].shape#(1,100)加一行
-
维度转置 np.transpose
np.transpose(a)或者a.T #将行列转置
若shape 为(100,)这种 ndarray 是无法进行转维,因为它的 ndim 为 1 x=x[np.newaxis,:]#先增维 np.transpose(x).shape#然后可以维度转置了#一维的 vector 转置后还是自己。 -
全降维为一维数组:
x.flatten()
- Numpy 运算
逐元素运算:就是两个 shape 一致的矩阵,相同位置上的元素的运算。numpy ufunc 运算:ufunc 是 universal function 的缩写,它是一种能对数组的每个元素进行操作的函数。numPy 内置的许多 ufunc 函数都在 C 语言级别实现的,因此它们的计算速度非常快。以下讲到的 add,subtract 等都是 numpy 提供 的 ufunc 函数。
- 加法求和
x+y或者np.add(x,y) - 减法求差
x-y或者np.subtract(x,y) - 乘法
x*y 或者 np.multiply(x,y) - 除法
x/y 或者 np.divide(x,y) - 矩阵乘法
x.dot(y)#或者是 np.dot(x,y) 但是对于一维数组,它计算的是其点积。
- ndarray 对象内部运算
- 求和、平均值、最大值、最小值: np.sum、np.mean()、np.max()、np.min()。其中, 可以按矩阵的维度进行运算:np.sum(x,axis=0) #维度数为 2 的时候(即一个矩阵),第一个维度就是行,第二个维度就是列。将 axis 设置为 0,即表示消除了行维度,保留列的维度。axis 设置为 1,代表消除了列的维度,保留行的维度。
- 排序
一维数组的排序:a.sort()
多维数组排序:如果 ndarray 对象的 ndim 是 2(也就是一个矩阵)那么排序就可以在不同的维度上进行。
arr=np.random.randn(5,3)*10
np.sort(arr,axis=0)#按维度 0,即行进行排序np.sort(arr,axis=1)#按维度 1,即列进行排序
#sort 指定 axis=0,即是排序的时候,依据的维度是第一维(即列),于是我们可以观察到排序后矩阵,在列的方向上,是从小到大的。
- 广播算法
当我们使用 ufunc 函数对两个数组进行计算时,ufunc 函数会对这两个数组的对应元素进行计算因此它要求这两个数组有相同的大小(shape 相同)。如果两个数组的 shape 不同的话会进行如下的广播(broadcasting)处理。即:在第一个维度扩展、第二维度扩展,直到两个对象shape一致,就可以进行运算了。
什么时候会进行广播呢?
当操作两个array时,numpy会比较它们的shape,当出现下面两种情况时,两array会兼容和输出 broadcasting 结果: 1. 相等2. 其中一个为1。
- 高级的 ndarray 处理
- 变形 ndarray 对象 :
reshape 可以轻松将数组转换为二维,三维,甚至更高维度的数组 如果在某个维度指定-1,则 numpy 会自动推导出正确的形状。
a1=np.arange(16)#含有 16 个元素的一维数组
np.reshape(a1,(2,-1))#把一个矩阵 reshape 为另一个矩阵,0 维度为 2,1 维度为-1(numpy 会自动推导出为 8)
- 拉平 ndarray 对象:
使用 ravel()或 flatten()函数都可以把高维的 ndarray 对象拉平为一维。a.ravel()或者a.flatten()
- 拼接 ndarray 对象:
左右拼(横向拼接)horizontal
使用 np.hstack([arr1,arr2])或者np.concatenate([arr1,arr2],axis=0)或者np.c_[arr1,arr2]。这里的 c,指 column 列。其中np.c_[]还有生成矩阵的用法,c 即 column,np.c_[1:6,-5:0]。
垂直拼(纵向拼接)vertical
使用 np.vstack([arr1,arr2])或者 np.r_[arr1,arr2]。这里的 r,指 row 行。
- 拆分 ndarray 对象
水平分割——竖着切
a,b,c=np.hsplit(arr1,3)
垂直分割——横着切
np.vsplit(arr1,2)
- 重复 ndarray 对象
按元素重复
arr=np.arange(3)
arr.repeat(3)每个元素统一重复 3 次
arr.repeat([2,3,4]) 指定每个元素,重复的次数[2,3,4]次
按轴(维度)进行重复
arr.repeat(3,axis=0) 按列重复
按 ndarray 对象重复:
np.tile(arr,(2,3)) :0维复制2次(倍)。
np.tile(arr,(2,3)) :0维复制2次,1维复制3次。可以理解为以传入的 ndarray 对象为模板,生产出一块瓷砖,就可以像贴瓷砖一样,横向,纵向进行复制。 对 arr 对象的复制两次,默认按 0 维进行。
- ndarray 对象的输入与输出
- 保存
np.save(‘d:/a1’,arr1数组名字) 保存好的数组,默认后缀为 数组名字.npy。
多个数组保存使用 savez 方法。np.save(“array_archive.npz”,a=arr1,b=arr2,c=arr3) 多个数组可以一起压缩存储。
- 读取
np.load(‘d:/a1.npy’)。load 方法载入 numpy 格式的数据,savetxt,loadtxt 方法载入文本格式的数据同理。
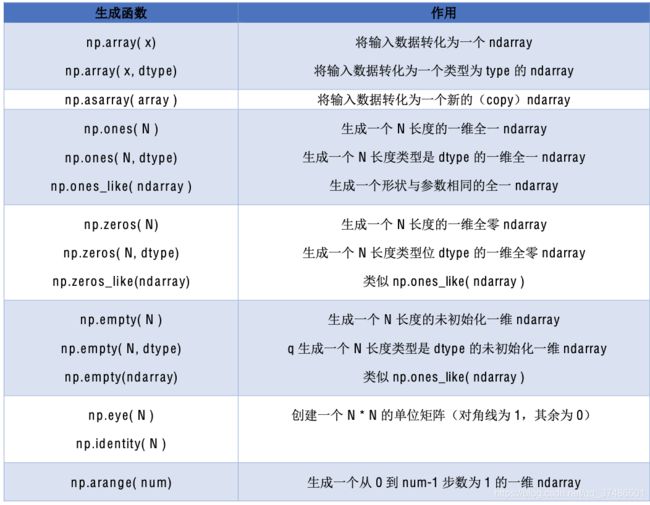
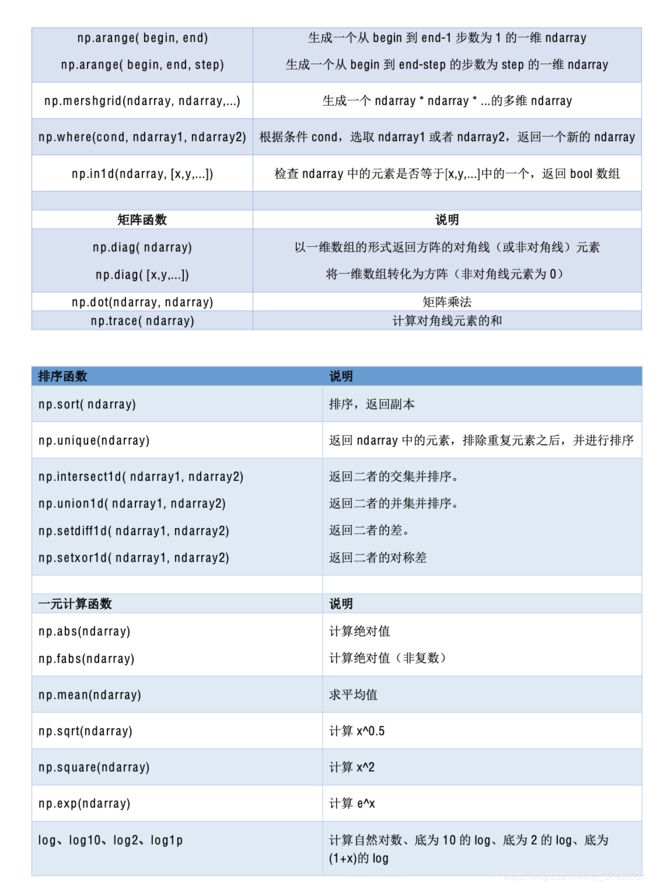
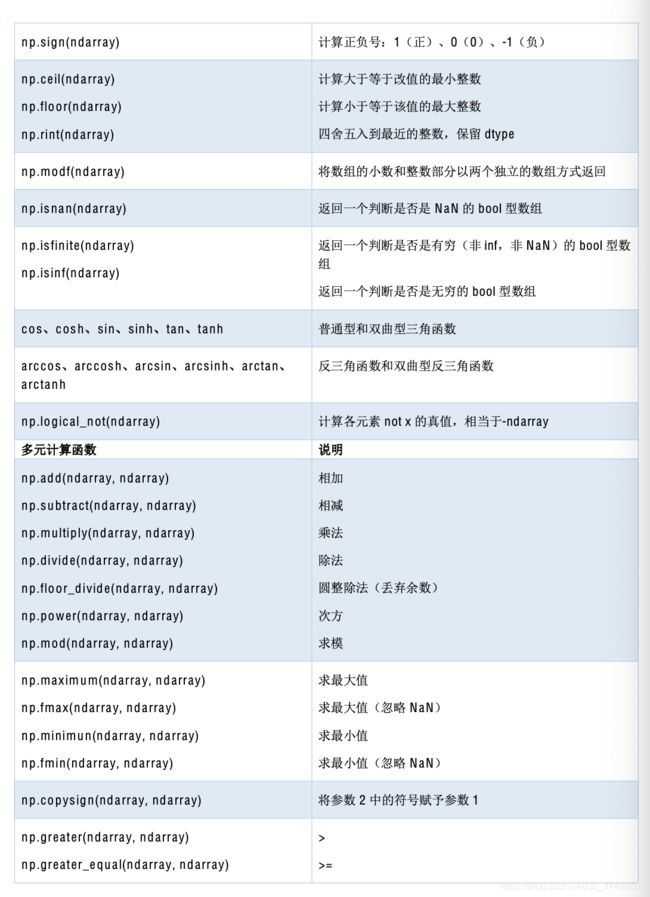
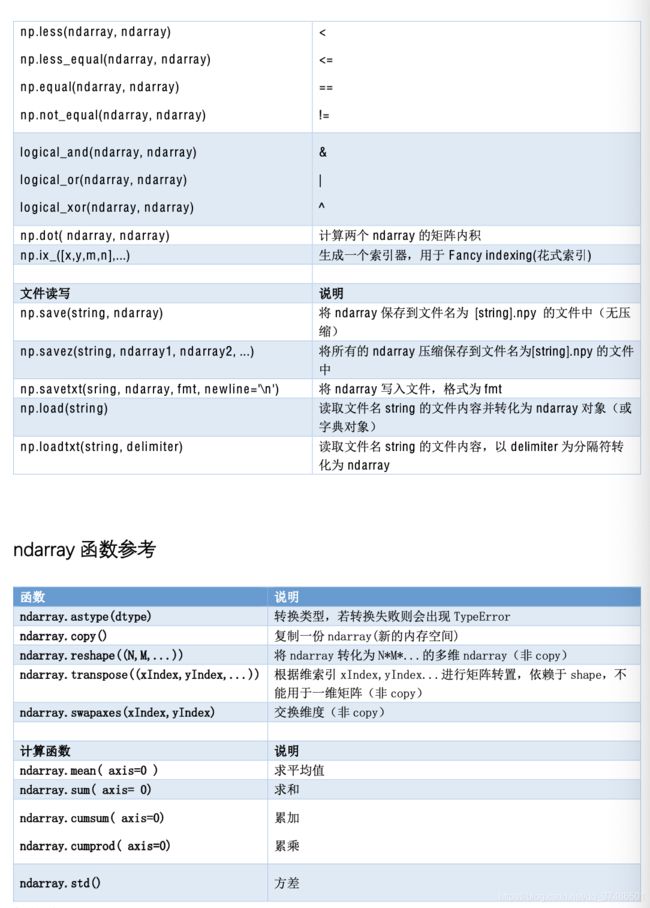
- 附:Numpy 常用函数