对于强化学习的梳理
强化学习(增强学习)
概述
知识联系
强化学习是属于机器学习的一种,机器学习主要分监督学习、非监督学习、半监督学习、增强学习。
强化学习的核心逻辑,那就是智能体(Agent)可以在环境(Environment)中根据奖励(Reward)的不同来判断自己在什么状态(State)下采用什么行动(Action),从而最大限度地提高累积奖励。
定义及意义、目的
描述:
强化学习任务通常用马尔可夫决策过程(Markov Decision Process, 简称MDP)来描述:机器处于环境E中,状态空间为X,其中每个状态x∈x是机器感知到的环境的描述,如在种瓜任务上这就是当前瓜苗长势的描述;机器能采取的动作构成了动作空间A,如种瓜过程中有浇水、施不同的肥、使用不同的农药等多种可供选择的动作;若某个动作a∈A作用在当前状态x.上,则潜在的转移函数P将使得环境从当前状态按某种概率转移到另一个状态,如瓜苗状态为缺水,若选择动作浇水,则瓜苗长势会发生变化,瓜苗有一定的概率恢复健康,也有- -定的概率无法恢复;在转移到另–个状态的同时,环境会根据潜在的**“奖赏”(reward)函数R**反馈给机器- -个奖赏,如保持瓜苗健康对应奖赏+1,瓜苗凋零对应奖赏- -10,最终种出了好瓜对应奖赏+100.综合起来,强化学习任务对应了四元组E= (X,A,P, R>,其中P:Xx AxXr + R指定了状态转移概率, R:X xAxXHR指定了奖赏;在有的应用中,奖赏函数可能仅与状态转移有关,即R:Xx XHR.
状态空间 动作空间导致状态空间依转移函数改变 状态空间改变会产生奖赏
机器要做的是通过在环境中不断尝试而学得一个策略,根据这个策略在状态x下就知道要执行的动作a。在强化学习任务中,学习的目的就是要找到使长期积累奖赏最大化的策略
策略的优劣取决于长期执行这一策略后得到的累计奖赏
强化学习与监督学习的对比中:状态对应实例,动作对应标记 策略相当于分类器(离散)或回归器(连续),因此,在某种意义上,强化学习可以看做具有“延迟标记信息”的样本
from:周志华《机器学习》
学习目的:针对一些问题更好的进行决策
1.强化学习是什么?与其它机器学习方法有什么关系?
强化学习是一种机器学习方法,它使Agent能够在交互式环境中年通过试验并根据自己的行动和经验反馈的错误来进行学习。虽然监督学习和强化学习都使用输入和输出之间的映射关系,但强化学习与监督学习不同,监督学习提供给Agent的反馈是执行任务的正确行为,而强化学习使用奖励和惩罚作为积极和消极行为的信号。
与无监督学习相比而言,强化学习在目标方面有所不同。虽然无监督学习的目标是找出数据点之间的相似性和不同性,但是在强化学习中,其目标是找到一个合适的动作模型,能够最大化Agent的累积奖励总额。下图表示了强化学习模型中涉及的基本思想和要素。
原文链接:https://www.jianshu.com/p/9526f944ca6f
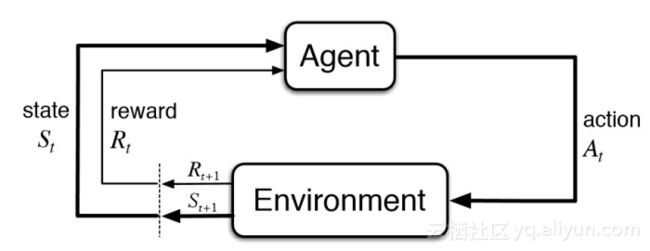
强化学习要素
智能体
策略函数
值函数
值函数表示智能体在某一特定状态下的程度,等价于智能体从初始状态开始所获得的总的期望奖励。
模型
模型是指智能体对环境的表示,学习可分为基于模型的学习和无模型学习两种。
强化学习的分类
强化学习中有两种重要的方法:Policy Gradients和Q-learning。其中Policy Gradients方法直接预测在某个环境下应该采取的Action,而Q-learning方法预测某个环境下所有Action的期望值(即Q值),选择概率最大的那一个。一般来说,Q-learning方法只适合有少量离散取值的Action环境,而Policy Gradients方法适合有连续取值的Action环境。在与深度学习方法结合后,这两种算法就变成了Policy Network和DQN(Deep Q-learning Network)。
基于模式(Model Based)/无模式(Model free)
按给定条件,强化学习可分为基于模式的强化学习(model-based RL)和无模式强化学习(model-free RL),其中基于模式的强化学习需要有一个环境产生反馈的模型,无模式强化学习则不需要。我们想象, 我们的机器人正在这个世界里玩耍, 他不理解这个世界是怎样构成的, 也不理解世界对于他的行为会怎么样反馈. 举个例子, 他决定丢颗原子弹去真实的世界, 结果把自己给炸死了, 所有结果都是那么现实. 不过如果采取的是 model-based RL, 机器人会通过过往的经验, 先理解真实世界是怎样的, 并建立一个模型来模拟现实世界的反馈, 最后他不仅可以在现实世界中玩耍, 也能在模拟的世界中玩耍 , 这样就没必要去炸真实世界, 连自己也炸死了, 他可以像玩游戏一样炸炸游戏里的世界, 也保住了自己的小命。
Model-free 的方法有很多, 像 Q learning, Sarsa, Policy Gradients 都是从环境中得到反馈然后从中学习. Model-free 中, 机器人只能按部就班, 一步一步等待真实世界的反馈, 再根据反馈采取下一步行动.。
而 model-based RL 只是多了一道程序, 为真实世界建模, 也可以说他们都是 model-free 的强化学习, 只是 model-based 多出了一个虚拟环境, 我们不仅可以像 model-free 那样在现实中玩耍,还能在游戏中玩耍, 而玩耍的方式也都是 model-free 中那些玩耍方式, 最终 model-based 还有一个杀手锏是 model-free 超级羡慕的. 那就是想象力。他能通过想象来预判断接下来将要发生的所有情况. 然后选择这些想象情况中最好的那种. 并依据这种情况来采取下一步的策略, 这也就是 围棋场上 AlphaGo 能够超越人类的原因。
基于概率(policy)/价值(value)
基于概率是强化学习中最直接的一种, 他能通过感官分析所处的环境, 直接输出下一步要采取的各种动作的概率, 然后根据概率采取行动, 所以每种动作都有可能被选中, 只是可能性不同. 在基于概率这边, 有 Policy Gradients 。
基于价值的方法输出是所有动作的价值, 我们会根据最高价值来选着动作, 相比基于概率的方法, 基于价值的决策部分更为铁定, 毫不留情, 就选价值最高的, 而基于概率的, 即使某个动作的概率最高, 但是还是不一定会选到他.在基于价值这边有 Q learning, Sarsa 等.
而且我们还能结合这两类方法的优势之处, 创造更牛逼的一种方法, 叫做 Actor-Critic, actor 会基于概率做出动作, 而 critic 会对做出的动作给出动作的价值, 这样就在原有的 policy gradients 上加速了学习过程.
主动强化学习(active RL)和被动强化学习(passive RL)
强化学习的变体包括逆向强化学习、阶层强化学习和部分可观测系统的强化学习。
求解强化学习问题所使用的算法可分为策略搜索算法和值函数(value function)算法两类。
回合更新/单步更新
强化学习还能用另外一种方式分类, 回合更新和单步更新, 想象强化学习就是在玩游戏, 游戏回合有开始和结束. 回合更新指的是游戏开始后, 我们要等待游戏结束, 然后再总结这一回合中的所有转折点, 再更新我们的行为准则. 而单步更新则是在游戏进行中每一步都在更新, 不用等待游戏的结束, 这样我们就能边玩边学习了.
再来说说方法, Monte-carlo learning 和基础版的 policy gradients 等 都是回合更新制, Qlearning, Sarsa, 升级版的 policy gradients 等都是单步更新制. 因为单步更新更有效率, 所以现在大多方法都是基于单步更新. 比如有的强化学习问题并不属于回合问题.
在线(on Policy)/离线(off Policy)学习
在线学习, 就是指我必须本人在场, 并且一定是本人边玩边学习, 而离线学习是你可以选择自己玩, 也可以选择看着别人玩, 通过看别人玩来学习别人的行为准则, 离线学习 同样是从过往的经验中学习, 但是这些过往的经历没必要是自己的经历, 任何人的经历都能被学习. 或者我也不必要边玩边学习, 我可以白天先存储下来玩耍时的记忆, 然后晚上通过离线学习来学习白天的记忆.
最典型的在线学习就是 Sarsa 了, 还有一种优化 Sarsa 的算法, 叫做 Sarsa lambda, 最典型的离线学习就是 Q learning, 后来人也根据离线学习的属性, 开发了更强大的算法, 比如让计算机学会玩电动的 Deep-Q-Network.
举例分析
强化学习有哪些实际应用?
适用于决策性的问题
由于增强学习需要大量的数据,因此它最适用于模拟数据领域,比如游戏、机器人等。
在电脑游戏中,增强学习被广泛地应用于人工智能的构建中。AlphaGo Zero是围棋界第一个击败世界冠军的计算机程序,类似的还有ATARI游戏、西洋双陆棋等。
在机器人和工业自动化领域,增强学习被用于使机器人为其自身创建一个高效的自适应控制系统,从而能够从自己的经验和行为中学习。DeepMind在深度增强学习上的成果也是一个很好的例子。
增强学习的其它应用包括文本摘要引擎、对话代理(文本、语言),它们可以从用户交互中学习,并随着时间的推移而不断改进。此外,对于医疗保健和在线股票交易而言,基于增强学习的性能也是最佳的。
强化学习算法简介
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2uOHONpr-1588481788035)(…/…/…/…/AppData/Roaming/Typora/typora-user-images/image-20200416175910399.png)]
1. 基于价值(Value)
Q-learning算法
莫烦教程
Q learning 算法是基于表格的学习算法,
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Mhdi9kwC-1588481788044)(https://morvanzhou.github.io/static/results/ML-intro/q4.png)]
这一张图概括了所有的内容. 这也是 Q learning 的算法, 每次更新我们都用到了 Q 现实和 Q 估计, 而且 Q learning 的迷人之处就是 在 Q(s1, a2) 现实 中, 也包含了一个 Q(s2) 的最大估计值, 将对下一步的衰减的最大估计和当前所得到的奖励当成这一步的现实, 很奇妙吧.
最后我们来说说这套算法中一些参数的意义:
- Epsilon greedy是用在决策上的一种策略, 比如 epsilon = 0.9 时, 就说明有90% 的情况我会按照 Q 表的最优值选择行为, 10% 的时间使用随机选行为.
- alpha是学习率, 来决定这次的误差有多少是要被学习的, alpha是一个小于1 的数.
- gamma 是对未来 reward 的衰减值.
Sarsa
Sarsa 的决策部分和 Q learning 一模一样, 因为我们使用的是 Q 表的形式决策, 所以我们会在 Q 表中挑选值较大的动作值施加在环境中来换取奖惩. 但是不同的地方在于 Sarsa 的更新方式是不一样的.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lHiYGRMy-1588481788050)(https://morvanzhou.github.io/static/results/ML-intro/s3.png)]
同样, 我们会经历正在写作业的状态 s1, 然后再挑选一个带来最大潜在奖励的动作 a2, 这样我们就到达了 继续写作业状态 s2, 而在这一步, 如果你用的是 Q learning, 你会观看一下在 s2 上选取哪一个动作会带来最大的奖励, 但是在真正要做决定时, 却不一定会选取到那个带来最大奖励的动作, Q-learning 在这一步只是估计了一下接下来的动作值. 而 Sarsa 是实践派, 他说到做到, 在 s2 这一步估算的动作也是接下来要做的动作. 所以 Q(s1, a2) 现实的计算值, 我们也会稍稍改动, 去掉maxQ, 取而代之的是在 s2 上我们实实在在选取的 a2 的 Q 值. 最后像 Q learning 一样, 求出现实和估计的差距 并更新 Q 表里的 Q(s1, a2).
对比 Sarsa 和 Q-learning
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-S0eFks60-1588481788053)(https://morvanzhou.github.io/static/results/ML-intro/s4.png)]
从算法来看, 这就是他们两最大的不同之处了. 因为 Sarsa 是说到做到型, 所以我们也叫他 on-policy, 在线学习, 学着自己在做的事情. 而 Q learning 是说到但并不一定做到, 所以它也叫作 Off-policy, 离线学习. 而因为有了 maxQ, Q-learning 也是一个特别勇敢的算法,因为 Q learning 机器人 永远都会选择最近的一条通往成功的道路, 不管这条路会有多危险. 而 Sarsa 则是相当保守, 他会选择离危险远远的, 拿到宝藏是次要的, 保住自己的小命才是王道. 这就是使用 Sarsa 方法的不同之处.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rqaVT6Ea-1588481788055)(https://morvanzhou.github.io/static/results/ML-intro/s5.png)]
DQN(Deep Q-learning)
什么是DQN:一种融合了神经网络和 Q learning 的方法。
为什么提出DQN:传统的表格形式的强化学习有这样一个瓶颈,用表格来存储每一个状态 state, 和在这个 state 每个行为 action 所拥有的 Q 值. 而当今问题是在太复杂, 状态可以多到比天上的星星还多(比如下围棋). 如果全用表格来存储它们, 恐怕我们的计算机有再大的内存都不够, 而且每次在这么大的表格中搜索对应的状态也是一件很耗时的事.
DQN的输入形式:可以将状态和动作当成神经网络的输入, 然后经过神经网络分析后得到动作的 Q 值, 这样我们就没必要在表格中记录 Q 值, 而是直接使用神经网络生成 Q 值.也能只输入状态值, 输出所有的动作值, 然后按照 Q learning 的原则, 直接选择拥有最大值的动作当做下一步要做的动作.
神经网络的更新方式:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-46KeSlkv-1588481788056)(https://morvanzhou.github.io/static/results/ML-intro/DQN3.png)]
接下来我们基于第二种神经网络来分析, 我们知道, 神经网络是要被训练才能预测出准确的值. 那在强化学习中, 神经网络是如何被训练的呢? 首先, 我们需要 a1, a2 正确的Q值, 这个 Q 值我们就用之前在 Q learning 中的 Q 现实来代替. 同样我们还需要一个 Q 估计 来实现神经网络的更新. 所以神经网络的的参数就是老的 NN 参数 加学习率 alpha 乘以 Q 现实 和 Q 估计 的差距. 我们整理一下.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IcoZs9Iz-1588481788058)(https://morvanzhou.github.io/static/results/ML-intro/DQN4.png)]
我们通过 NN 预测出Q(s2, a1) 和 Q(s2,a2) 的值, 这就是 Q 估计. 然后我们选取 Q 估计中最大值的动作来换取环境中的奖励 reward. 而 Q 现实中也包含从神经网络分析出来的两个 Q 估计值, 不过这个 Q 估计是针对于下一步在 s’ 的估计. 最后再通过刚刚所说的算法更新神经网络中的参数. 但是这并不是 DQN 会玩电动的根本原因. 还有两大因素支撑着 DQN 使得它变得无比强大. 这两大因素就是 Experience replay 和 Fixed Q-targets.
DQN两大利器
Experience replay :DQN 有一个记忆库用于学习之前的经历,Q learning 是一种 off-policy 离线学习法, 它能学习当前经历着的, 也能学习过去经历过的, 甚至是学习别人的经历. 所以每次 DQN 更新的时候, 我们都可以随机抽取一些之前的经历进行学习. 随机抽取这种做法打乱了经历之间的相关性, 也使得神经网络更新更有效率.。
Fixed Q-targets:是一种打乱相关性的机理, 如果使用 fixed Q-targets, 我们就会在 DQN 中使用到两个结构相同但参数不同的神经网络, 预测 Q 估计 的神经网络具备最新的参数, 而预测 Q 现实 的神经网络使用的参数则是很久以前的。
DQN算法:

D3QN PER算法
2. 基于概率(Policy)
Policy Gradients
(可以直接预测出一个连续的动作值,而不是像value-based那样给出若干离散动作的值或者概率)
强化学习是一个通过奖惩来学习正确行为的机制. 家族中有很多种不一样的成员, 有学习奖惩值, 根据自己认为的高价值选行为, 比如 Q learning, Deep Q Network, 也有不通过分析奖励值, 直接输出行为的方法, 这就是今天要说的 Policy Gradients 了. 甚至我们可以为 Policy Gradients 加上一个神经网络来输出预测的动作. 对比起以值为基础的方法, Policy Gradients 直接输出动作的最大好处就是, 它能在一个连续区间内挑选动作, 而基于值的, 比如 Q-learning, 它如果在无穷多的动作中计算价值, 从而选择行为, 这, 它可吃不消.
更新方法
Policy Gradients 的误差又是什么呢? 答案是! 哈哈, 没有误差! 但是他的确是在进行某一种的反向传递. 这种反向传递的目的是让这次被选中的行为更有可能在下次发生. 但是我们要怎么确定这个行为是不是应当被增加被选的概率呢? 这时候我们的老朋友, reward 奖惩正可以在这时候派上用场。
现在我们来演示一遍, 观测的信息通过神经网络分析, 选出了左边的行为, 我们直接进行反向传递, 使之下次被选的可能性增加, 但是奖惩信息却告诉我们, 这次的行为是不好的, 那我们的动作可能性增加的幅度 随之被减低. 这样就能靠奖励来左右我们的神经网络反向传递. 我们再来举个例子, 假如这次的观测信息让神经网络选择了右边的行为, 右边的行为随之想要进行反向传递, 使右边的行为下次被多选一点, 这时, 奖惩信息也来了, 告诉我们这是好行为, 那我们就在这次反向传递的时候加大力度, 让它下次被多选的幅度更猛烈! 这就是 Policy Gradients 的核心思想了. 很简单吧.
Actor Critic(演员评判家)
参考文章:一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm)
Actor-Critic算法详解(附代码)
强化学习——策略梯度与Actor-Critic算法(详细)
强化学习中的一种结合体 Actor Critic (演员评判家), 它合并了 以值为基础 (比如 Q learning) 和 以动作概率为基础 (比如 Policy Gradients) 两类强化学习算法.
起源:我们有了像 Q-learning 这么伟大的算法, 为什么还要瞎折腾出一个 Actor-Critic? 原来 Actor-Critic 的 Actor 的前生是 Policy Gradients, 这能让它毫不费力地在连续动作中选取合适的动作, 而 Q-learning 做这件事会瘫痪. 那为什么不直接用 Policy Gradients 呢? 原来 Actor Critic 中的 Critic 的前生是 Q-learning 或者其他的 以值为基础的学习法 , 能进行单步更新, 而传统的 Policy Gradients 则是回合更新, 这降低了学习效率.(所以Actor-Critic就是结合了以值为基础算法的学习效率和以概率为基础算法的能输出连续动作优点)
作用:现在我们有两套不同的体系, Actor 和 Critic, 他们都能用不同的神经网络来代替 . 在 Policy Gradients 的影片中提到过, 现实中的奖惩会左右 Actor 的更新情况. Policy Gradients 也是靠着这个来获取适宜的更新. 那么何时会有奖惩这种信息能不能被学习呢? 这看起来不就是 以值为基础的强化学习方法做过的事吗. 那我们就拿一个 Critic 去学习这些奖惩机制, 学习完了以后. 由 Actor 来指手画脚, 由 Critic 来告诉 Actor 你的那些指手画脚哪些指得好, 哪些指得差, Critic 通过学习环境和奖励之间的关系, 能看到现在所处状态的潜在奖励, 所以用它来指点 Actor 便能使 Actor 每一步都在更新, 如果使用单纯的 Policy Gradients, Actor 只能等到回合结束才能开始更新.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-O8x012kF-1588481788060)(https://morvanzhou.github.io/static/results/ML-intro/AC3.png)]
但是事物终有它坏的一面, Actor-Critic 涉及到了两个神经网络, 而且每次都是在连续状态中更新参数, 每次参数更新前后都存在相关性, 导致神经网络只能片面的看待问题, 甚至导致神经网络学不到东西. Google DeepMind 为了解决这个问题, 修改了 Actor Critic 的算法,(DDPG)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zbwuCpFa-1588481788063)(https://morvanzhou.github.io/static/results/ML-intro/AC4.png)]
将之前在电动游戏 Atari 上获得成功的 DQN 网络加入进 Actor Critic 系统中, 这种新算法叫做 Deep Deterministic Policy Gradient, 成功的解决的在连续动作预测上的学不到东西问题. 所以之后, 我们再来说说什么是这种高级版本的 Deep Deterministic Policy Gradient 吧.
A3C
A3C是Google DeepMind 提出的一种解决Actor-Critic不收敛问题的算法。我们知道DQN中很重要的一点是他具有经验池,可以降低数据之间的相关性,而A3C则提出降低数据之间的相关性的另一种方法:异步。
简单来说:A3C会创建多个并行的环境, 让多个拥有副结构的 agent 同时在这些并行环境上更新主结构中的参数. 并行中的 agent 们互不干扰, 而主结构的参数更新受到副结构提交更新的不连续性干扰, 所以更新的相关性被降低, 收敛性提高.
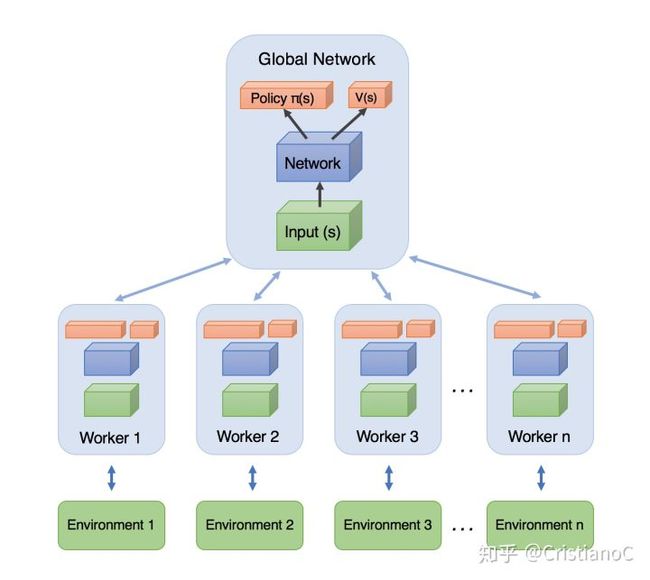
A3C的算法实际上就是将Actor-Critic放在了多个线程中进行同步训练. 可以想象成几个人同时在玩一样的游戏, 而他们玩游戏的经验都会同步上传到一个中央大脑. 然后他们又从中央大脑中获取最新的玩游戏方法。
这样, 对于这几个人, 他们的好处是: 中央大脑汇集了所有人的经验, 是最会玩游戏的一个, 他们能时不时获取到中央大脑的必杀招, 用在自己的场景中.
对于中央大脑的好处是: 中央大脑最怕一个人的连续性更新, 不只基于一个人推送更新这种方式能打消这种连续性. 使中央大脑不必像DQN,DDPG那样的记忆库也能很好的更新。

为了达到这个目的,我们要有两套体系, 可以看作中央大脑拥有global net和他的参数, 每位玩家有一个global net的副本local net, 可以定时向global net推送更新, 然后定时从global net那获取综合版的更新.
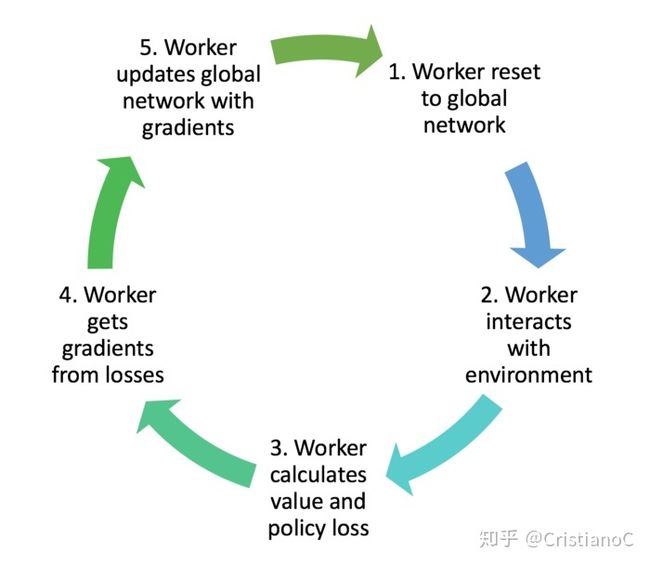
如果在 tensorboard 中查看我们今天要建立的体系, 这就是你会看到的。
强化学习的问题
来源
对于制约强化学习在业界应用的痛点也有点感悟,跟大家分享下:
- **学习的稳定性问题:**众所周知,强化学习通过探索和利用学习,探索不免会带来劣化,有些场景对劣化容忍度很低。这就要求强化学习策略能够不进入严重劣化区间,那么算法就需要能够每一步学习都不会变差,TRPO和PPO等系列算法对这个问题有一定解决方案。
- **学习的收敛性问题:**最基础的策略迭代或者q-learning之类的算法可以理论证明其收敛性。而由于状态和动作空间太大引入值函数之后,收敛性以及收敛速度的证明就有点玄乎了,尤其是引入了神经网络之后。有些工业场景是希望能够快速收敛的,收敛慢或者震荡收敛都是不能接受的,比如网络参数的调整要能够快速收敛,不能让用户觉得网络一会好一会差。
- **回报函数的确定问题:**如果上面两点还是技术性问题的话,这个问题就有点哲学味道了。Alphago能够成功应用,就是因为输赢这种回报是明确的。而真正的工业问题,很多时候回报是多选且难以综合的,片面的回报只会带来负增益。当前的一种解决方案是逆强化学习,人脑是很奇妙的,很多复杂场景下你的大脑会给出有价值的判断,但你自己没法用公式表达出来。逆强化学习的一个目标就是学习一个策略能够逼近人类专家的行为策略,逆向出回报的表达形式。
- **多智能体协同问题:**很多工业场景涉及的智能主体有多个,比如企业场景下wlan的部署,每个AP也就是类似于家用路由器需要在不同的功率、信道参数之间进行选择,期望整体用户体验最佳。而每个AP的回报以及它能感知的环境都是局部的,如果同步整体环境以及其他的局部回报是需要有明确的有效策略来保证的,这其中涉及到分布式学习以及如何权衡局部和全局回报问题。前面三个问题在此场景下都依然存在且变得更为复杂。
要解决以上等问题,还需要学届和业界通力配合,一旦解决,应用场景真的是非常广阔。
强化学习的部署
作者:田子宸
链接:https://www.zhihu.com/question/329372124/answer/743251971
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
先说结论:部署的方式取决于需求
需求一:简单的demo演示,只要看看效果的,像是学校里面的demo展示这种
caffe、tf、pytorch等框架随便选一个,切到test模式,拿python跑一跑就好,顺手写个简单的GUI展示结果
高级一点,可以用CPython包一层接口,然后用C++工程去调用
需求二:要放到服务器上去跑,但一不要求吞吐二不要求时延的那种,说白了还是有点玩玩的意思
caffe、tf、pytorch等框架随便选一个,按照官方的部署教程,老老实实用C++部署,例如pytorch模型用工具导到libtorch下跑(官方有教程,很简单)
这种还是没有脱离框架,有很多为训练方便保留的特性没有去除,性能并不是最优的;
另外,这些框架要么CPU,要么NVIDIA GPU,对硬件平台有要求,不灵活;
还有,框架是真心大,占内存(tf还占显存),占磁盘
需求三:放到服务器上跑,要求吞吐和时延(重点是吞吐)
这种应用在互联网企业居多,一般是互联网产品的后端AI计算,例如人脸验证、语音服务、应用了深度学习的智能推荐等。
由于一般是大规模部署,这时不仅仅要考虑吞吐和时延,还要考虑功耗和成本。所以除了软件外,硬件也会下功夫,比如使用推理专用的NVIDIA P4、寒武纪MLU100等。这些推理卡比桌面级显卡功耗低,单位能耗下计算效率更高,且硬件结构更适合高吞吐量的情况
软件上,一般都不会直接上深度学习框架。对于NVIDIA的产品,一般都会使用TensorRT来加速(我记得NVIDIA好像还有TensorRT inference server什么的,名字记不清了,反正是不仅可以加速前传,还顺手帮忙调度了)。TensorRT用了CUDA、CUDNN,而且还有图优化、fp16、int8量化等。反正用NVIDIA的一套硬软件就对了
需求四:放在NVIDIA嵌入式平台上跑,注重时延
比如PX2、TX2、Xavier等,参考上面(用全家桶就对了),也就是贵一点嘛
需求五:放在其他嵌入式平台上跑,注重时延
硬件方面,要根据模型计算量和时延要求,结合成本和功耗要求,选合适的嵌入式平台。
比如模型计算量大的,可能就要选择带GPU的SoC,用opencl/opengl/vulkan编程;也可以试试NPU,不过现在NPU支持的算子不多,一些自定义Op多的网络可能部署不上去
对于小模型,或者帧率要求不高的,可能用CPU就够了,不过一般需要做点优化(剪枝、量化、SIMD、汇编、Winograd等)
顺带一提,在手机上部署深度学习模型也可以归在此列,只不过硬件没得选,用户用什么手机你就得部署在什么手机上23333。为老旧手机部署才是最为头疼的
上述部署和优化的软件工作,在一些移动端开源框架都有人做掉了,一般拿来改改就可以用了,性能都不错。
需求六:上述部署方案不满足我的需求
比如开源移动端框架速度不够——自己写一套。比如像商汤、旷世、Momenta都有自己的前传框架,性能应该都比开源框架好。只不过自己写一套比较费时费力,且如果没有经验的话,很有可能费半天劲写不好
Gym
Gym 是 OpenAI 发布的用于开发和比较强化学习算法的工具包。使用它我们可以让 AI 智能体做很多事情,比如行走、跑动,以及进行多种游戏。提供强化学习所需要的环境
的
我的理解
我觉得强化学习是提供了一种学习思路,使得agent能够根据环境的反馈形成一种自发的学习模式,为了一定的目标而做出最优决策。