官方论文还没出,刷爆AI圈的DALL·E刚发布就被复现?两天800 star!
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达
萧箫 发自 凹非寺
来源:量子位(QbitAI)
没想到,OpenAI刚公布DALL·E,就已经有人在复现了。

虽然还是个半成品,不过大体框架已经搭建好了,一位第三方作者Philip Wang正在施工中。
DALL·E是前两天刚公布的文字转图像网络框架,目前只公布了项目结果,甚至连官方论文都还没出。
论文还没出,就开始复现了
论文复现的依据,来自一位叫做Yannic Kilcher的博主制作的油管视频。
他在视频中,对DALL·E的原理结构进行了猜测。
他表示,这些猜测并不代表真实情况,也许DALL·E的论文出来后,会颠覆他的预想。
Yannic认为,DALL·E应该是VQ-VAE模型、和类似于GPT-3的语言模型的结合。
GPT-3这类语言模型,有着非常强大的语言建模能力,可以对输入的文字描述进行很好的拆分理解。

而VAE模型,则是一种强大的图像生成Transformer,在训练完成后,模型会去掉编码器(encoder)的部分,只留下解码器,用于生成图像。
将二者结合的话,就能像下图中的那个小方块一样,将输入的各种物体,根据理解的文字,结合成具有实际意义的一幅画面。
例如,输入人、太阳和树,模型就能输出“太阳下,树底坐着一个人”所描绘的图像。

要怎么实现?
先简单分析一下VQ-VAE的模型原理。
与VAE相似,这也是一个Transformer结构的模型,编码器对图像进行编码后,将编码数据送入隐空间,解码器再从隐空间中,对图像进行重构。
相比于VAE,VQ-VAE隐变量的每一维都是离散整数,也就是说,它的隐空间其实是一个编码簿(codebook),包含提取出的各种向量信息。
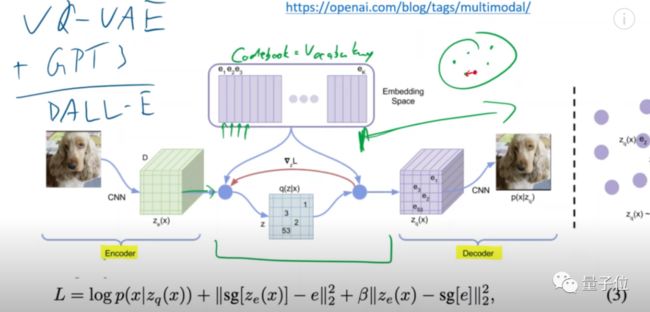
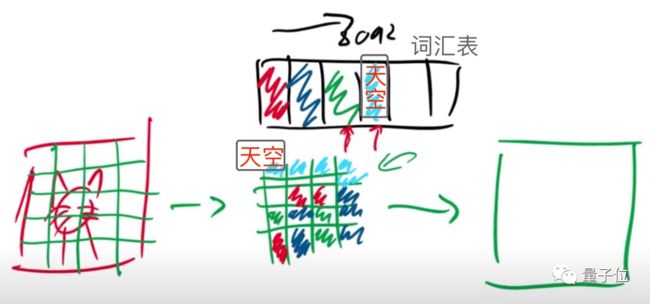
在DALL·E里,这个编码簿,本质上可以等价为一个词汇表(vocabulary)。
这个词汇表,专门用来存储对图像的各种描述。
对输入图像进行编码时,本质上是将图像分成各种像素块。
期间,会产生各种各样的图像信息。
假设天蓝色的格子,包含“天空”的描述信息,那么在重建时,解码器读取到“天空”信息,就会分配顶端的一系列像素,用来生成天空。
在完成VQ-VAE的训练后,模型就得到了一个只有解码器看得懂的编码簿。
届时,将由类似于GPT-3的语言模型,对输入的文字进行解码,转换成只有编码簿才能看懂的向量信息。
然后,编码簿会将这些信息进行排序,依次列出每个像素块应该生成的数据,并告诉解码器。
解码器会合成这些像素数据,得到最终的图像。
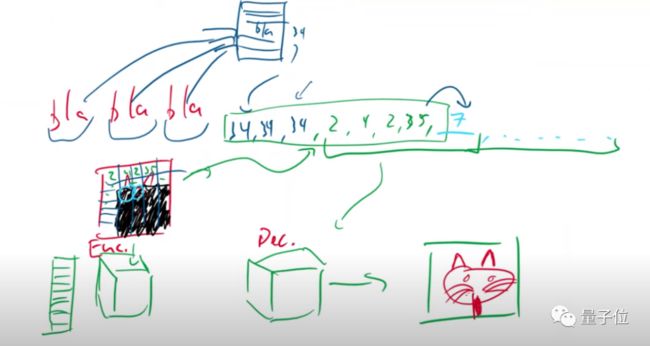
为了实现这样的目标,既要对类似于GPT-3的语言模型进行训练,也要提前对VQ-VAE模型进行预训练。
而且,还需要对二者融合后的模型进行训练。
这位作者复现的DALL·E,也是依据这个视频解析的原理复现的。
有关项目本身
目前,DALL·E的复现项目还没有完成,作者仍然在加工中(WIP),不过已经有700多个Star。
作者希望写出一个PyTorch版本的DALL·E,现在的框架中,已经包含了VAE的训练、CLIP的训练,以及VAE和CLIP融合后的模型预训练。
此外,还包括DALL·E的训练、和将预训练VAE模型融合进DALL·E模型中的部分。
上述模块训练完成后,就能用DALL·E来做文字生成图像了。
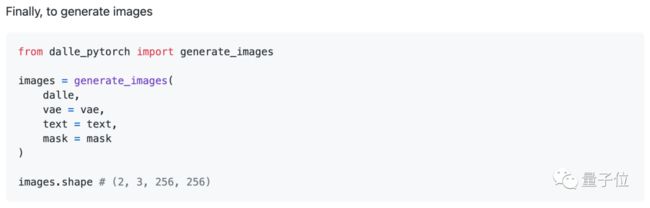
目前,作者正在进行DALL·E模块部分的代码复现。
作者承诺,完成DALL·E的部分后,会把CLIP模型也一起补上。
作者介绍

Philip Wang,本硕毕业于康奈尔大学,博士毕业于密歇根大学医学院。
他的研究兴趣是AI(深度学习方向),以及医疗健康,目前GitHub上已有1.7k个followers。
关于DALL·E本身,视频解析博主Yannic也表示,之所以能取得这么好的效果,并不全是因为模型设计。

DALL·E,极可能也像GPT-3一样,用了样本量庞大的数据集,来对模型进行训练。
网友表示,难以想象训练这个玩意所用的GPU数量,气候又要变暖了。

所以要想完全复现这个项目,最难的其实是硬件部分?(手动狗头)
项目地址:
https://github.com/lucidrains/DALLE-pytorch
DALL·E视频解析:
https://www.youtube.com/watch?v=j4xgkjWlfL4
CV资源下载
后台回复:CVPR2020,即可下载代码开源的论文合集
后台回复:ECCV2020,即可下载代码开源的论文合集
后台回复:YOLO,即可下载YOLOv4论文和代码
后台回复:Trasnformer综述,即可下载两个最新的视觉Transformer综述PDF,肝起来!
重磅!CVer-细分垂直交流群成立
扫码添加CVer助手,可申请加入CVer-细分垂直方向 微信交流群,也可申请加入CVer大群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、Transformer、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,才能通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!