Linux中一个网络包的发送/接收流程
如果你对Linux是如何实现 对用户原始的网络包进行协议头封装与解析,为什么会粘包拆包,期间网络包经历了哪些缓冲区、经历了几次拷贝(CPU、DMA),TCP又是如何实现滑动/拥塞窗口 这几个话题感兴趣的话,不妨看下去吧~
1. Linux发送HTTP网络包图像
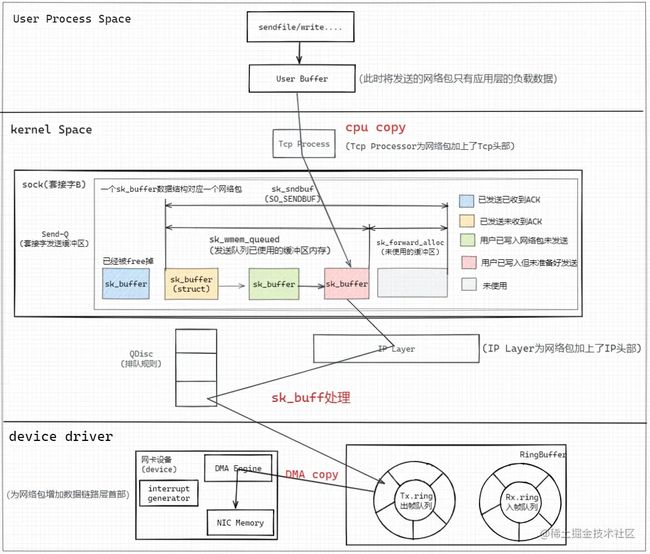
图像解析
写入套接字缓冲区(添加TcpHeader)
用户态进程通过write()系统调用切到内核态将用户进程缓冲区中的HTTP报文数据通过Tcp Process处理程序为HTTP报文添加TcpHeader,并进行CPU copy写入套接字发送缓冲区,每个套接字会分别对应一个Send-Q(发送缓冲区队列)、Recv-Q(接收缓冲区队列),可以通过ss -nt语句获取当前的套接字缓冲区的状态;
# ss -nt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 0 192.168.183.130:52454 192.168.183.130:14465
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 1024 192.168.183.130:52454 192.168.183.130:14465
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 2048 192.168.183.130:52454 192.168.183.130:14465
......
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 13312 192.168.183.130:52454 192.168.183.130:14465
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 14336 192.168.183.130:52454 192.168.183.130:14465
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 14480 192.168.183.130:52454 192.168.183.130:14465套接字缓冲区发送队列由一个个struct sk_buff 结构体的链表组成,其中一个sk_buff数据结构对应一个网络包;这个结构体后面会详细讲,是Linux实现网络协议栈的核心数据结构。
IP层
接着对TCP包在IP Layer层进行网络包IpHeader的组装,并经由QDisc(排队规则)进行转发;
数据链路层/物理层
接着网卡设备通过DMA Engine将内存中RingBuffer的Tx.ring块中的IP包(sk_buff)copy到网卡自身的内存中,并生成CRC等校验数据形成数据链路包头部并进行网络传输。
2. sk_buff数据结构解析
通过对sk_buff数据结构解析的过程中,我们回答文章头部的几个问题,以及窥见Linux中的一些设计思想;

进行协议头的增添
我们知道,按照网络栈的设定,发送网络包时,每经过一层,都会增加对应协议层的协议首部,因此Linux采用在sk_buff中的一个Union结构体进行标识:
struct sk_buff {
union {
struct tcphdr *th; // TCP Header
struct udphdr *uh; // UDP Header
struct icmphdr *icmph; // ICMP Header
struct igmphdr *igmph;
struct iphdr *ipiph; // IPv4 Header
struct ipv6hdr *ipv6h; // IPv6 Header
unsigned char *raw; // MAC Header
} h;
}结构体中存储的是指向内存中各种协议的首部地址的指针,而在发送数据包的过程中,sk_buff中的data指针指向最外层的协议头;
网络包的大小占用
考虑一个包含2bytes的网络包,需要包括 预留头(64 bytes) + Mac头(14bytes) + IP头(20bytes) + Tcp头(32bytes) + 有效负载为2bytes(len) + skb_shared_info(320bytes) = 452bytes,向上取整后为512bytes;sk_buff这个存储结构占用256bytes;则一个2bytes的网络包需要占用512+256=768bytes(truesize) 的内存空间;
因此当发送这个网络包时:
- Case1:不存在缓冲区积压,则新建一个sk_buff进行网络包的发送;
skb->truesize = 768
skb->datalen = 0 skb_shared_info 结构有效负载 (非线性区域)
skb->len = 2 有效负载 (线性区域 + 非线性区域(datalen),这里暂时不考虑协议头部)- Case2:如果缓冲区积压(存在未被ACK的已经发送的网络包-即SEND-Q中存在sk_buff结构),Linux会尝试将当前包合并到SEND-Q的最后一个sk_buff结构中 (粘包) ; 考虑我们上述的768bytes的结构体为SEND-Q的最后一个sk_buff,当用户进程继续调用write系统调用写入2kb的数据时,前一个数据包还未达到MSS/MTU的限制、整个缓冲区的大小未达到SO_SENDBUF指定的限制,会进行包的合并,packet data = 2 + 2,头部的相关信息都可以进行复用,因为套接字缓冲区与套接字是一一对应的;
tail_skb->truesize = 768
tail_skb->datalen = 0
tail_skb->len = 4 (2 + 2)
发送窗口
我们在创建套接字的时候,通过SO_SENDBUF指定了发送缓冲区的大小,如果设置了大小为2048KB,则Linux在真实创建的时候会设置大小2048*2=4096,因为linux除了要考虑用户的应用层数据,还需要考虑linux自身数据结构的开销-协议头部、指针、非线性内存区域结构等...
sk_buff结构中通过sk_wmem_queued标识发送缓冲区已经使用的内存大小,并在发包时检查当前缓冲区大小是否小于SO_SENDBUF指定的大小,如果不满足则阻塞当前线程,进行睡眠,等待发送窗口中有包被ACK后触发内存free的回调函数唤醒后继续尝试发送;
接收窗口(拥塞窗口)
|<---------- RCV.BUFF ---------------->|
1 2 3
|<-RCV.USER->|<--- RCV.WND ---->|
----|------------|------------------|------|----
RCV.NXT
接收窗口主要分为3部分:
- RCV.USER 为积压的已经收到但尚未被用户进程通过read等系统调用获取的网络数据包;当用户进程获取后窗口的左端会向右移动,并触发回调函数将该数据包的内存free掉;
- RCV.WND 为未使用的,推荐返回给该套接字的客户端发送方当前剩余的可发送的bytes数,即拥塞窗口的大小;
- 第三部分为未使用的,尚未预先内存分配的,并不计算在拥塞窗口的大小中;
进入网卡驱动层
NIC (network interface card) 在系统启动过程中会向系统注册自己的各种信息,系统会分配 RingBuffer队列及一块专门的内核内存区用于存放传输上来的数据包。每个 NIC 对应一个R x.ring 和一个 Tx.ring。一个 RingBuffer 上同一个时刻只有一个 CPU 处理数据。
每个网络包对应的网卡存储在sk_buff结构的dev_input中;
RingBuffer队列内存放的是一个个描述符(Descriptor),其有两种状态:ready 和 used。
- 初始时 Descriptor 是空的,指向一个空的 sk_buff,处在 ready 状态。
- 网卡收到网络包:当NIC有网络数据包传入时,DMA负责从NIC取数据,并在Rx.ring上按顺序找到下一个ready的Descriptor,将数据存入该 Descriptor指向的sk_buff中,并标记槽为used。
- 网卡发送网络包:当sk_buff已经在内核空间被写入完成时,网卡的DMA Engine检测到Tx.ring有数据包完成时,触发DMA Copy将数据传输到网卡内存中,并封装MAC帧。
不同的网络包发送函数有几次拷贝?
read then write
常见的场景中,当我们要在网络中发送一个文件,那么首先需要通过read系统调用陷入内核态读取 PageCache 通过 CPU Copy 数据页到用户态内存中,接着将数据页封装成对应的应用层协议报文,并通过write系统调用陷入内核态将应用层报文 CPU Copy 到套接字缓冲区中,经过TCP/IP处理后形成IP包,最后通过网卡的DMA Engine 将 RingBuffer Tx.ring 中的sk_buff进行 DMA Copy 到网卡的内存中,并将IP包封装为帧并对外发送。
PS:如果PageCache中不存在对应的数据页缓存,则需要通过磁盘DMA Copy到内存中。
因此read then write 需要两次系统调用(4次上下文切换,因为系统调用需要将用户态线程切换到内核态线程进行执行),两次CPU Copy、两次DMA Copy。
sendFile
用户线程调用sendFile系统调用陷入内核态,sendFile无需拷贝PageCache中的数据页到用户态内存中中,而是通过内核线程将 PageCache 中的数据页直接通过CPU Copy 拷贝到套接字缓冲区中,再经由相同的步骤经过一次网卡DMA对外传输。
因此sendFile 需要一次系统调用,一次CPU Copy;
相比于write,sendFile少了一次PageCache拷贝到内存的开销,但是需要限制在网络传输的是文件页,而不是用户缓冲区中的匿名页,并且因为完全在内核态进行数据copy,因此无法添加用户态的协议数据;
Kafka因为基于操作系统文件系统进行数据存储,并且文件量比较大,因此比较适合通过sendFile进行网络传输的实现;
但是sendFile仍然需要一次内核线程的CPU Copy,因此零拷贝更偏向于无需拷贝用户态空间中的数据。
mmap + write
相比于sendFile直接在内核态进行文件传输,mmap则是通过在进程的虚拟地址空间中映射PageCache,再经过write进行网络写入;比较适用于小文件的传输,因为mmap并没有立即将数据拷贝到用户态空间中,所以较大文件会导致频繁触发虚拟内存的 page fault 缺页异常;
RocketMQ 选择了 mmap+write 这种零拷贝方式,适用于消息这种小块文件的数据持久化和传输。