卷积神经网络(原理与代码实现)
卷积神经网络
- 1、卷积的概念
- 2、感受野的概念
- 3、全零填充(padding)
- 4、Tensorflow描述卷积层
-
- 4.1 卷积(Convolutional)
- 4.2 批标准化(Batch Normalization,BN)
- 4.3 池化
- 4.4 Dropout
- 5、简单CNN实现CIFAR10数据集分类
-
- 5.1 cifar10 数据集介绍
- 5.2 网络结构
- 5.3 网络搭建示例代码
- 6、神经网络搭建总结
1、卷积的概念
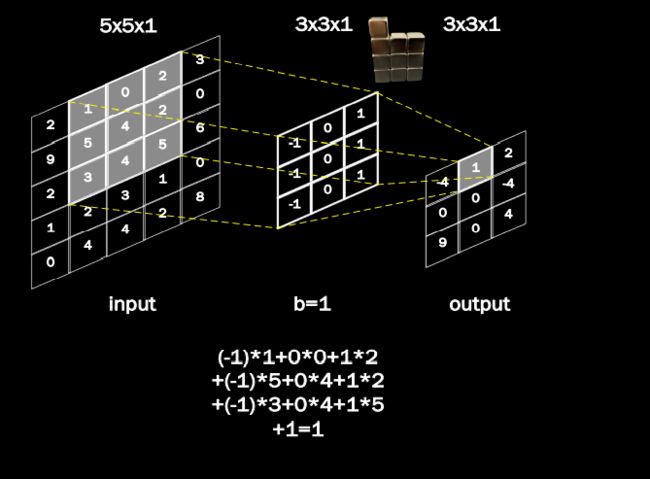
卷积的概念:卷积可以认为是一种有效提取图像特征的方法。一般会用一个正方形的卷积核,按指定步长,在输入特征图上滑动,遍历输入特征图中的每个像素点。每一个步长, 卷积核会与输入特征图出现重合区域,重合区域对应元素相乘、求和再加上偏置项得到输出特征的一个像素点,如下图所示。
对于彩色图像(多通道)来说,卷积核通道数与输入特征一致,套接后在对应位置上 进行乘加和操作,如图 所示,利用三通道卷积核对三通道的彩色特征图做卷积计算。
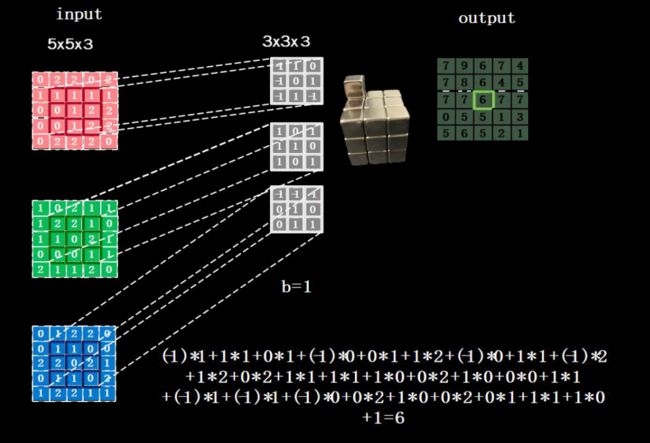
用多个卷积核可实现对同一层输入特征的多次特征提取,卷积核的个数决定输出层的通道(channels)数,即输出特征图的深度。
2、感受野的概念
感受野(Receptive Field)的概念:卷积神经网络各输出层每个像素点在原始图像上的映射区域大小。如下图所示。
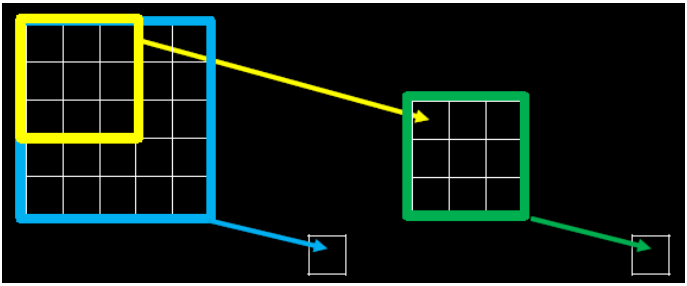
当我们采用尺寸不同的卷积核时,最大的区别就是感受野的大小不同,所以经常会采用 多层小卷积核来替换一层大卷积核,在保持感受野相同的情况下减少参数量和计算量,例如 十分常见的用 2 层 3 * 3 卷积核来替换 1 层 5 * 5 卷积核的方法,如下图所示。
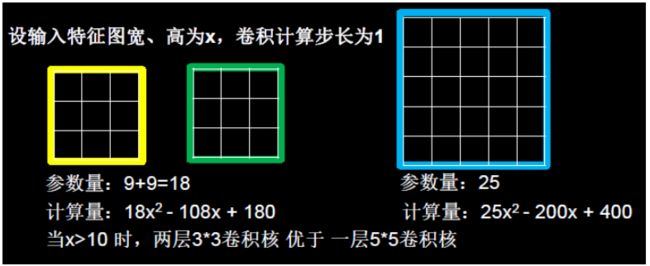
这是采用两层 3 ∗ 3 3*3 3∗3卷积核与一层 5 ∗ 5 5*5 5∗5卷积核的对比
不妨设输入特征图的宽、高均为 x,卷积计算的步长为 1,显然, 两个 3 * 3 卷积核的参数量为 9 + 9 = 18,小于 5 * 5 卷积核的 25,前者的参数量更少。
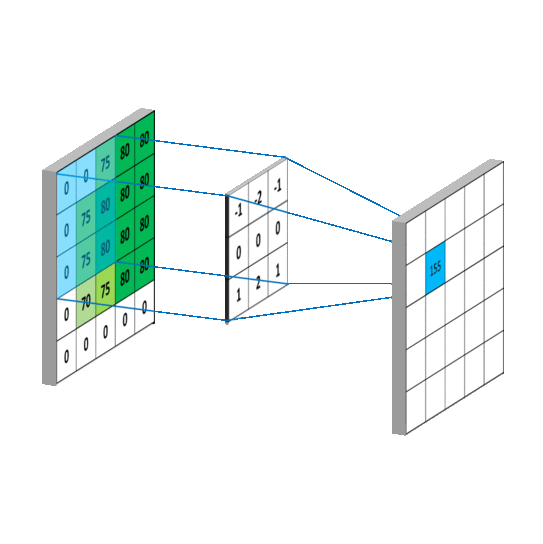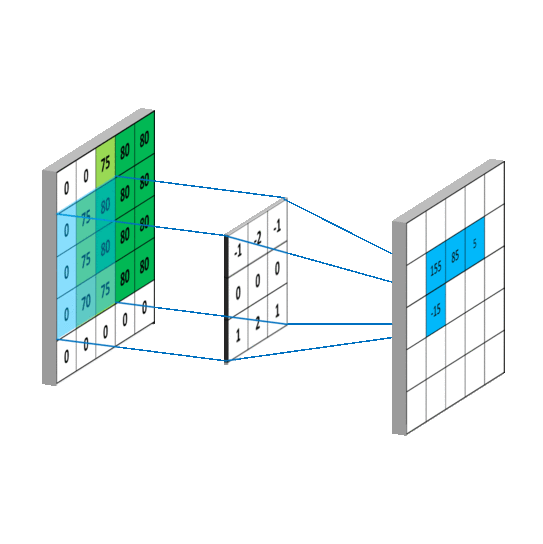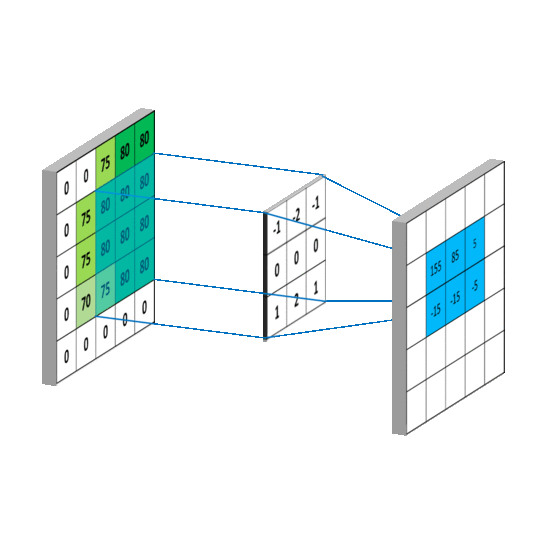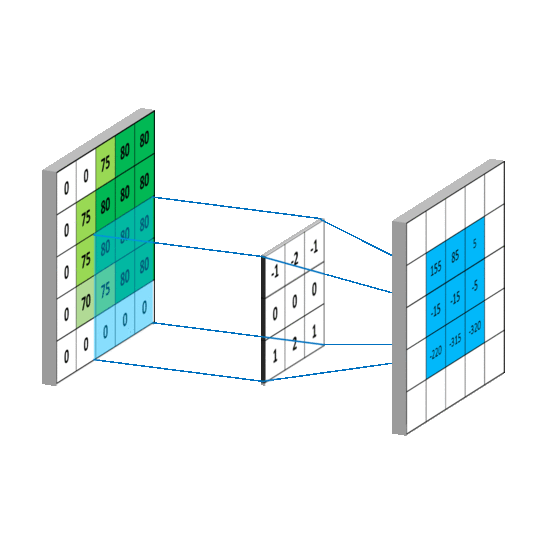
在计算量上,根据上图所示的输出特征尺寸计算公式,对于 5 * 5 卷积核来说,输出 特征图共有(x – 5 + 1)^2 个像素点,每个像素点需要进行 5 * 5 = 25 次乘加运算,则总计算量 为 25 * (x – 5 + 1)^2 = 25x^2 – 200x + 400;
对于两个 3 * 3 卷积核来说,第一个 3 * 3 卷积核输出特征图共有(x – 3 + 1)^2 个像素点, 每个像素点需要进行 3 * 3 = 9 次乘加运算,第二个 3 * 3 卷积核输出特征图共有(x – 3 + 1 – 3 + 1)^2 个像素点,每个像素点同样需要进行 9 次乘加运算,则总计算量为 9 * (x – 3 + 1)^2 + 9 * (x – 3 + 1 – 3 + 1)^2 = 18 x^2 – 108x + 180;
对二者的总计算量(乘加运算的次数)进行对比,18 x^2 – 200x + 400 < 25x^2 – 200x + 400,经过简单数学运算可得 x < 22/7 or x > 10,x 作为特征图的边长,在大多数情况下显然 会是一个大于 10 的值(非常简单的 MNIST 数据集的尺寸也达到了 28 * 28),所以两层 3 * 3 卷积核的参数量和计算量,在通常情况下都优于一层 5 * 5 卷积核,尤其是当特征图尺寸比较大的情况下,两层 3 * 3 卷积核在计算量上的优势会更加明显。
3、全零填充(padding)
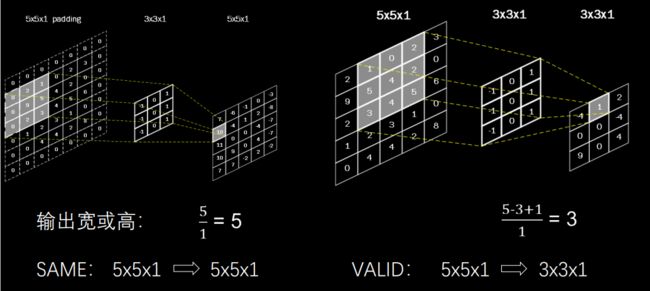
为了保持输出图像尺寸与输入图像一致,经常会在输入图像周围进行全零填充,如下图所示,在 5×5 的输入图像周围填 0,则输出特征尺寸同为 5×5。

在 Tensorflow 框架中,用参数 padding = ‘SAME’或 padding = ‘VALID’表示是否进行全 零填充,其对输出特征尺寸大小的影响如下:
-
SAME(全零填充):
输 出 特 征 图 边 长 = ⌈ 输 入 特 征 图 边 长 卷 积 步 长 ⌉ 输出特征图边长=\left \lceil \frac{输入特征图边长}{卷积步长} \right \rceil 输出特征图边长=⌈卷积步长输入特征图边长⌉ -
Valid(不全零填充):
输 出 特 征 图 边 长 = ⌈ 输 入 特 征 图 边 长 − 卷 积 核 边 长 + 1 卷 积 步 长 ⌉ 输出特征图边长=\left \lceil \frac{输入特征图边长-卷积核边长+1}{卷积步长} \right \rceil 输出特征图边长=⌈卷积步长输入特征图边长−卷积核边长+1⌉
对于 5×5×1 的图像来说, 当 padding = ‘SAME’时,输出图像边长为 5;当 padding = ‘VALID’时,输出图像边长为 3。
4、Tensorflow描述卷积层
4.1 卷积(Convolutional)
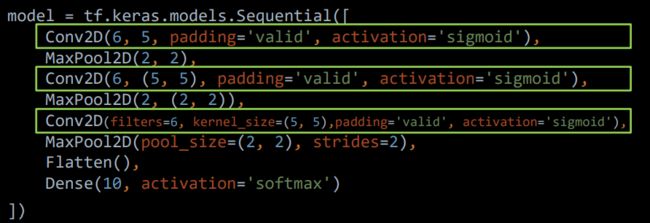
在 Tensorflow 框架下利用 Keras 来构建 CNN 中的卷积层,使用的是 tf.keras.layers.Conv2D 函数,具体的使用方法如下:
tf.keras.layers.Conv2D(
input_shape = (高, 宽, 通道数), #仅在第一层有
filters = 卷积核个数,
kernel_size = 卷积核尺寸,
strides = 卷积步长,
padding = ‘SAME’ or ‘VALID’,
activation = ‘relu’ or ‘sigmoid’ or ‘tanh’ or ‘softmax’等 #如有 BN 则此处不用写
)
使用此函数构建卷积层时,需要给出的信息有:
-
输入图像的信息,即宽高和通道数;
-
卷积核的个数以及尺寸,如
filters = 16, kernel_size = (3, 3)代表采用 16 个大小为 3×3 的 卷积核; -
卷积步长,即卷积核在输入图像上滑动的步长,纵向步长与横向步长通常是相同的,默 认值为 1;
-
是否进行全零填充,全零填充的具体作用上文有描述;
-
采用哪种激活函数,例如
relu、softmax等;
例如可以做如下定义:
4.2 批标准化(Batch Normalization,BN)
Batch Normalization(批标准化):对一小批数据在网络各层的输出做标准化处理,其具体实现方式如下图所示。(标准化:使数据符合 0 均值,1 为标准差的分布。)
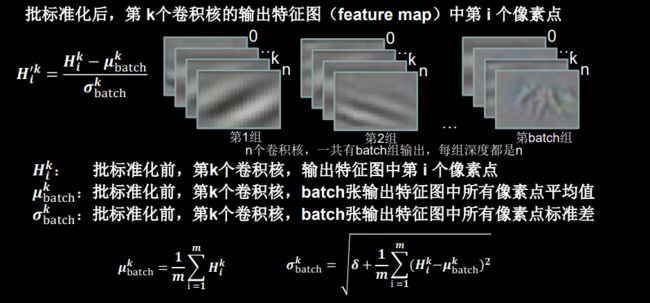
Batch Normalization 将神经网络每层的输入都调整到均值为 0,方差为 1 的标准正态分 布,其目的是解决神经网络中梯度消失的问题,如图所示。

BN 操作的另一个重要步骤是缩放和偏移,值得注意的是,缩放因子 γ 以及偏移因子 β 都是可训练参数,其作用如下图所示。

BN 操作通常位于卷积层之后,激活层之前,在 Tensorflow 框架中,通常使用 Keras 中 的 tf.keras.layers.BatchNormalization 函数来构建 BN 层。
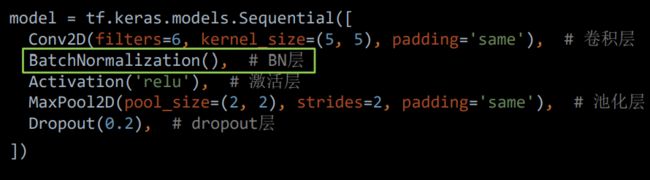
在调用此函数时,需要注意的一个参数是 training,此参数只在调用时指定,在模型进行前向推理时产生作用,当 training = True 时,BN 操作采用当前 batch 的均值和标准差;当 training = False 时,BN 操作采用滑动平均(running)的均值和标准差**。在 Tensorflow 中, 通常会指定 training = False,可以更好地反映模型在测试集上的真实效果。**
滑动平均(running)的解释:滑动平均,即通过一个个 batch 历史的叠加,最终趋向数据集整体分布的过程,在测试集上进行推理时,滑动平均的参数也就是最终保存的参数。
4.3 池化
池化(pooling):池化的作用是减少特征数量(降维)。最大值池化可提取图片纹理,均值池化可保留背景特征,如下图所示。

在 Tensorflow 框架下,可以利用 Keras 来构建池化层,使用的是 tf.keras.layers.MaxPool2D 函数和 tf.keras.layers.AveragePooling2D 函数,具体的使用方法如下:
tf.keras.layers.MaxPool2D(
pool_size=池化核尺寸,#正方形写核长整数,或(核高h,核宽w)
strides=池化步长,#步长整数, 或(纵向步长h,横向步长w),默认为pool_size
padding=‘valid’or‘same’ #使用全零填充是“same”,不使用是“valid”(默认)
)
tf.keras.layers.AveragePooling2D(
pool_size=池化核尺寸,#正方形写核长整数,或(核高h,核宽w)
strides=池化步长,#步长整数, 或(纵向步长h,横向步长w),默认为pool_size
padding=‘valid’or‘same’ #使用全零填充是“same”,不使用是“valid”(默认)
)
例如如下代码:
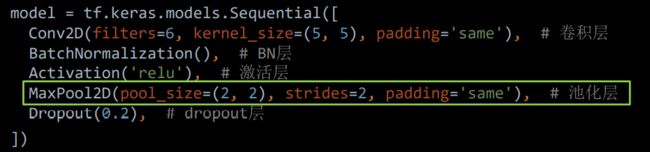
4.4 Dropout
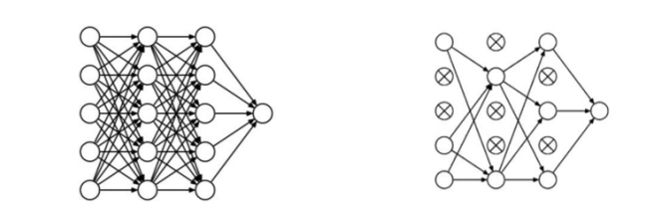
舍弃(Dropout):在神经网络的训练过程中,将一部分神经元按照一定概率从神经网络中暂时舍弃,使用时被舍弃的神经元恢复链接,如下图所示。
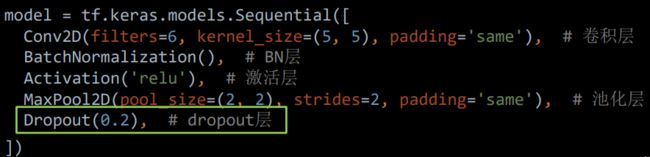
在 Tensorflow 框架下,利用 tf.keras.layers.Dropout 函数构建 Dropout 层,参数为舍弃的概率(大于 0 小于 1)。
到此,运用上面的知识就可以构建出基本的卷积神经网络(CNN)了,其核心思路为在CNN中利用卷积核(kernel)提取特征后,送入全连接网络。
CNN 模型的主要模块:一般包括上述的卷积层、BN 层、激活函数、池化层以及全连接层,如下图所示。

5、简单CNN实现CIFAR10数据集分类
5.1 cifar10 数据集介绍
该数据集共有 60000 张彩色图像,每张尺寸为 32 * 32,分为 10 类, 每类 6000 张。训练集 50000 张,分为 5 个训练批,每批 10000 张;从每一类随机取 1000 张构成测试集,共 10000 张,剩下的随机排列组成训练集,如图 所示。

cifar10 数据集的读取:
-
数据集的下载:
cifar10 = tf.keras.datasets.cifar10 -
导入训练集和测试集:
(x_train, y_train), (x_test, y_test) = cifar10.load_data() -
打印训练集与测试集的数据维度,打印结果为:
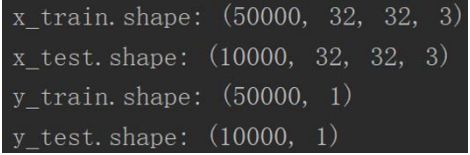
显然,cifar10 是一个用于图像分类的数据集,共分 10 类,相较于 mnist 数据集会更复杂一些,训练难度也更大,但是图像尺寸较小,仅为 32 * 32,仍然属于比较基础的数据集, 利用一些 CNN 经典网络结构(如 VGGNet、ResNet 等)进行训练的 话准确率很容易就能超过 90%,很适合初学者用来练习。
5.2 网络结构
掌握了利用 tf.keras 来搭建神经网络的八股之后,就可以搭建自己的神经网络来对数据 集进行训练了,这里提供一个实例,利用一个结构简单的基础卷积神经网络(CNN)来对 cifar10 数据集进行训练,网络结构如下图所示。

5.3 网络搭建示例代码
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# 模型定义
model=tf.keras.models.Sequential([
Conv2D(filters=6, kernel_size=(5, 5), padding='same'), # 卷积层
BatchNormalization(), # BN层
Activation('relu'), # 激活层
MaxPool2D(pool_size=(2, 2), strides=2, padding='same'), # 池化层
Dropout(0.2),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.2),
Dense(10, activation='softmax')
])
#编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
# 读取模型
checkpoint_save_path = "./checkpoint/Baseline.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
# 保存模型
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
# 训练模型
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
# 查看模型摘要
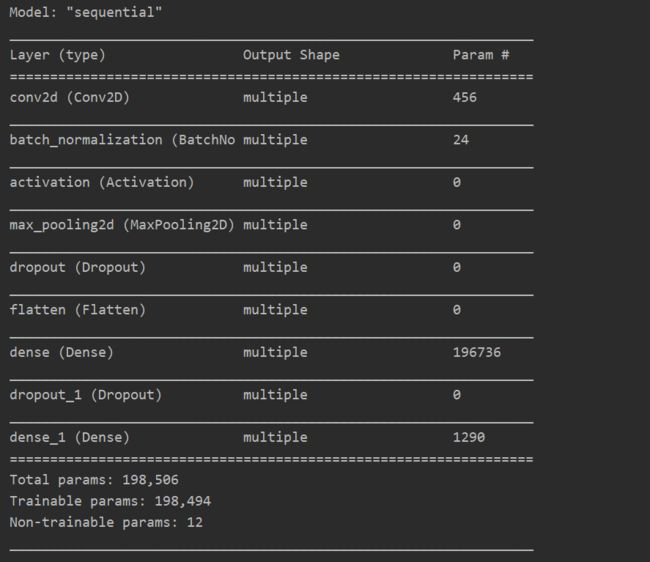
model.summary()
# 将模型参数存入文本
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
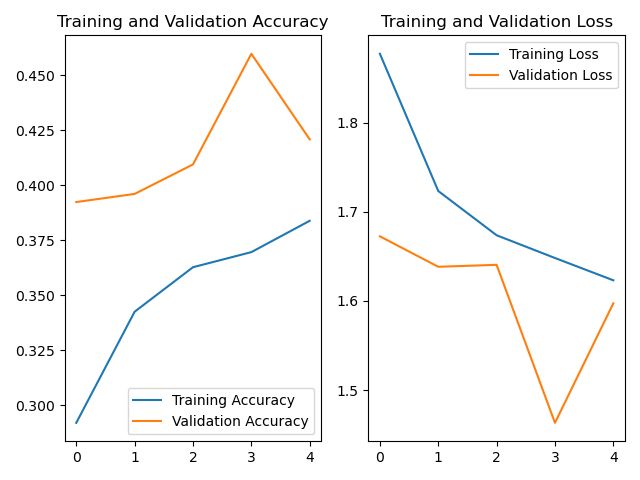
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
#绘制acc和loss曲线
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
acc和loss曲线
模型摘要:
6、神经网络搭建总结
在 Tensorflow 框架下,利用 Keras 来搭建神经网络的“八股”套 路,在主干的基础上,还可以添加其他内容,来完善神经网络的功能,如利用自己的图片和 标签文件来自制数据集;通过旋转、缩放、平移等操作对数据集进行数据增强;保存模型文件进行断点续训;提取训练后得到的模型参数以及准确率曲线,实现可视化等。
构建神经网络的“八股”套路:
import引入tensorflow及keras、numpy等所需模块。- 读取数据集,课程中所利用的
MNIST、cifar10等数据集比较基础,可以直接从 sklearn 等模块中引入,但是在实际应用中,大多需要从图片和标签文件中读取所需的数据集。 - 搭建所需的网络结构,当网络结构比较简单时,可以利用
keras模块中的tf.keras.Sequential来搭建顺序网络模型;但是当网络不再是简单的顺序结构,而是有其它特 殊结构出现时(例如ResNet中的跳连结构),便需要利用class来定义自己的网络结构。前 者使用起来更加方便,但实际应用中往往需要利用后者来搭建网络。 - 对搭建好的网络进行编译(
compile),通常在这一步指定所采用的优化器(如Adam、 sgd、RMSdrop等)以及损失函数(如交叉熵函数、均方差函数等),选择哪种优化器和损失函数往往对训练的速度和效果有很大的影响。 - 将数据输入编译好的网络来进行训练(
model.fit),在这一步中指定训练轮数epochs以 及batch_size等信息,由于神经网络的参数量和计算量一般都比较大,训练所需的时间也会比较长,尤其是在硬件条件受限的情况下,所以在这一步中通常会加入断点续训以及模型参数保存等功能,使训练更加方便,同时防止程序意外停止导致数据丢失的情况发生。 - 将神经网络模型的具体信息打印出来(
model.summary),包括网络结构、网络各层的参 数等,便于对网络进行浏览和检查。
到此,简单的神经网络搭建过程就介绍完了,后面我再搞一搞一些经典的CNN模型。