DAB-DETR深入理解
论文链接:https://arxiv.org/abs/2201.12329
最大的贡献是把DETR的Object Query定义为可学习的Anchor
Anchor-based DETR来临了
(还有点争议,说是Anchor-based,这Anchor又不是预定义的,说是Anchor-free,这Anchor也不是由image feature end-to-end预测来的)
首先是一个实验,为啥DETR收敛这么慢?首先排除backbone的原因,因为是预训练好的,那就只能是Decoder的原因。
其中,Decoder包含好几个部分,包括输入,Decoder,输出的匈牙利匹配,本篇是在输入Query上下文章。
输入的可学习的Query,会不会是因为Query学的太慢了呢?于是干脆直接把Query固定为在COCO上预训练好的,看会不会收敛快一点,结果令人比较失望:
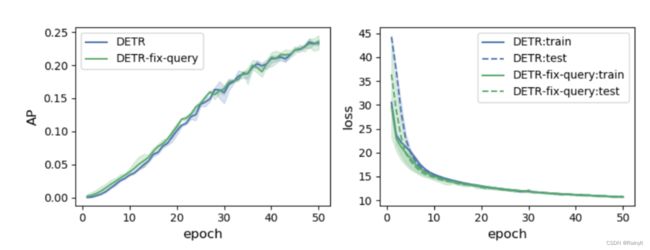
并没有提多少,这说明不是Query学的慢了,而是Decoder学的慢了,给他一样的好的Query,他也得不到好的输出结果,导致每次匈牙利算法匹配的结果都不一样。
因此加速收敛本质上是加速Decoder的学习
要加速Decoder,有几个方面,
一是使用更好的Decoder(如何定义更好,不得而知)
二是喂给它更好的sample与监督。
第二个方面就引申出了包括本篇在内的后面几个工作
如何定义“更好”?
首先得搞明白喂进去的输入是个啥?

(1)左边是Encoder,右边是Decoder,可以看到K是feature embedding + positional embedding ,Q是feature embedding + Queries,
(2)其中,Q的“feature embedding”实际上是上一层Decoder的输出,也就是Value(Encoder的Feature embedding)根据注意力取出来的一部分,是不是很像ROI pooling?只是这里取的不是一部分区域,而是这个区域经过全局注意力之后的结果,相当于是多了Context
从(1)的角度看,Query可以类比为Positional Embedding,从(2)的角度看,Query是否就是Proposal?或者说,Proposal的位置信息,也就是Anchor
综上所述,Query实际上就是Positional Embedding形式的Anchor,与Decoder Embedding相加后,相当于是给ROI pooling后的Feature上PE(positional
embedding),用于继续跟总Feature求注意力矩阵,拿ROI。
经过多层堆叠之后,拿到了最精确的ROI,就可以过FFN输出分类和回归结果(DETR的做法)
》》》》》》》》》》》》》》
有什么问题?
(1)凭什么多层堆叠就能拿到更精确的ROI?->这是由最后一层的监督决定的,不过可能也是导致其收敛慢的原因。
要想其收敛更快,显然的方法就是给它更多的监督==>每一个layer都给它一个gt的监督
这里又引出几个问题:
1、layer输出的并不是bbox,如何用gt的bbox去监督?
2、每个layer如何做正样本分配?
对于第一个问题,有几种方式可以解决:
1’ 在每个layer加个FFN检测头,输出分类和回归的结果
2还没想到
DAB-DETR就是采用的1’的做法
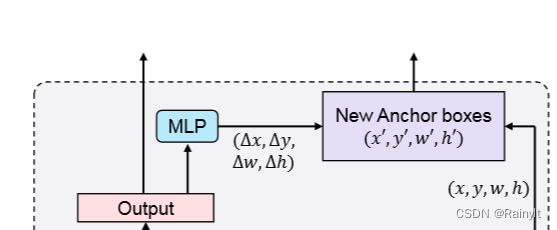
不同的是,只输出回归的结果,也就是 Δ x , Δ y , Δ w , Δ h \Delta{x},\Delta{y},\Delta{w},\Delta{h} Δx,Δy,Δw,Δh,同时,Query就是用sin与cos编码后的anchor

因此,可以拿编码前的结果与输出的回归系数相加,得到输出的proposal(用gt监督),同时,这个proposal又可以作为下一阶段的Query输入,相当于下一阶段又更精确的Proposal。很妙,也是很自然的想法
现在来解决第二个问题,每个layer输出的N个proposal用哪个gt来监督?
很自然的想法就是遵循常规OD,用IoU最大的来监督/
想多了,直接用DETR最后的匈牙利算法来分配样本算了。。
》》》》》》》》》》
插播一篇Conditional-DETR:
https://arxiv.org/pdf/2108.06152.pdf
是DAB-DETR里这条支路的由来:
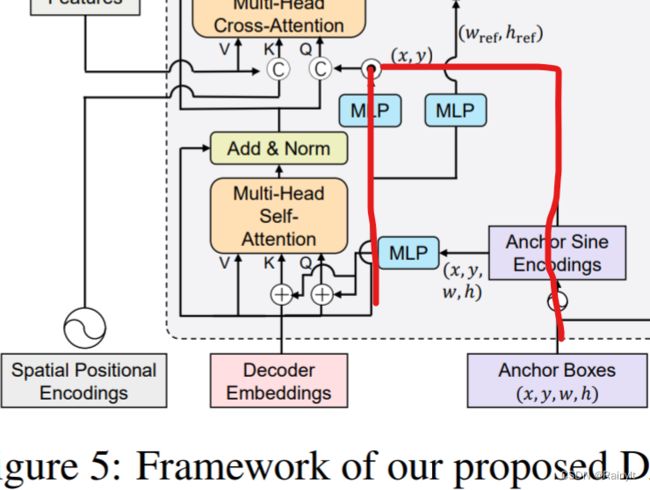
为啥这里decoder embedding要和anchor乘一下再作为positional
query呢?
答:因为最终decoder embedding是设计了用来预测anchor的中心位置偏移量的,也就是 Δ x , Δ y \Delta{x},\Delta{y} Δx,Δy,所以这里要把偏移量给它乘上去,相当于得到一个refine的anchor。
(为什么用乘不用加:个人猜测因为这是在128维的positional embedding上做的操作,不比x,y的直接数值加减,因此用transform向量来element-wise改变每个维度的数值可能更好)
问题是你这**是用在DAB-DETR上的啊???
DAB的anchor都已经是用decoder embedding refine过的anchor了,你这里再来一遍有啥意义?
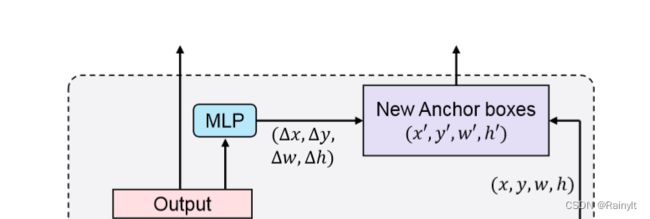
nnd,合着DAB的贡献就是在Conditional的基础上做了个多级refine,positional query显式设置为可学习anchor,加了个不知道有没有用的h,w限制(好像是有0.7个点的作用)(看了一天这系列的论文有点烦躁了。。)
》》》》
接下来就是这条分支
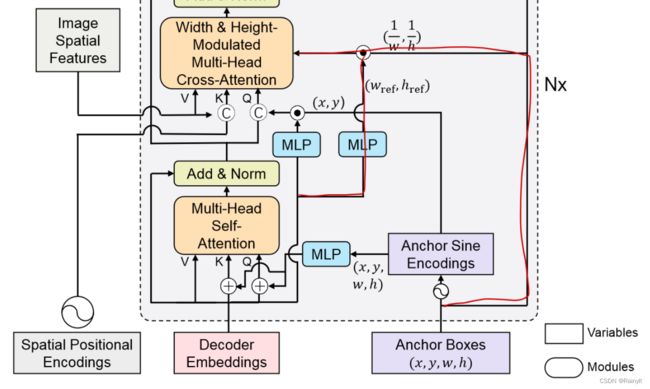
咋一看还挺唬人的
其实如果不看红色线路,实际上就是Query作为positional embedding分别加或者concat到feature上。因为每层Decoder都有self-attn和cross-attn,所以用了两次
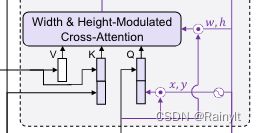
至于红色的线路,就是在anchor的Embedding上乘个系数,来调整anchor的宽高
![]()
to:![]()
也就是anchor的w和偏移量的w的比值(因为从Conditional的设定上decoder embedding是预测偏移量的)
有什么说法?
我们先看看原始的attn矩阵:
假设anchor就一个x坐标,经过pe得到PE(x),与key的Positional embedding矩阵的每个向量相乘,求相似度,得到一行数据假设为(0.1, 0.1, 0.4, 0.6, 0.9, 0.6, 0.4, 0.1, 0.1),这里给它乘上一个数n,如果>1,相当于把原始attn扩大n倍,假设我们认为>0.5的部分是anchor关注的位置,这里就相当于给它扩大了。
如果anchor是二维坐标(x, y),经过PE得到PE(x)和PE(y),concat在一起得到[PE(x), PE(y)]
,与key的Positional embedding相乘,得到这个点与对应点的相似度,与所有点相乘,就得到一行数据(0.1, 0.1, 0.4, 0.6, 0.9, 0.6, 0.4, 0.1, 0.1),其中第一个数,
0.1 = P E ( x ) ∗ P E ( x r e f ) + P E ( y ) ∗ P E ( y r e f ) 0.1=PE(x)*PE(x_{ref})+PE(y)*PE(y_{ref}) 0.1=PE(x)∗PE(xref)+PE(y)∗PE(yref),如果只给前者乘上一个数会将这个数变大(若n>1),给后者乘上n,会变更大。。
然后呢?
仔细看,attn map:

这确实是1个query和所有positional embedding的attn矩阵
为什么还是个矩阵?
设query: [channels,]
positional embedding: [n, channels],
向量和矩阵相乘应该还是一个向量啊,表示query和n个embedding的中的每个的相似度
实际上,我们仔细想想,这是图片啊,所以[n, channels]实际上可以先拉成[h, w, channels]的3维矩阵
这样求相似度,就能得到一个二维的attn-map。
再想想在x,y上加权重对attn-map的影响
麻了,想了半天,凭啥加权重影响attn-map的形状啊?根据那个公式,权重>1的情况,加了之后,会增加所有点的值,凭啥让它依据w,h的形状变化。
另外:
实现上是这样的,先把 w r e f / w w_{ref}/w wref/w求出来,乘上 P E ( x r e f ) PE(x_{ref}) PE(xref),后面再直接当作k,做cross-attn

关键一点是,在做cross-attn之前,还对这个embedding过了一个MLP
![]()
这意味着啥?
w和h信息没有线性地作用在corss-attention上,而是过了一个未知的MLP
相当于是把w和h信息给它送进去,至于它怎么用,看它自己了
只是最终训好后的可视化效果确实达到了预期目标:
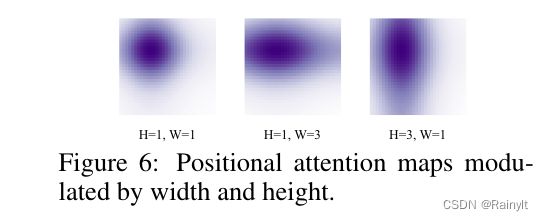
补充一点,那个concat是横着concat的
也就是说, ( n 1 , 128 ) (n_1, 128) (n1,128)和 ( n 2 , 128 ) (n_2, 128) (n2,128)concat在一起变成 ( n 1 , 256 ) (n_1, 256) (n1,256)。 ( n 1 = n 2 ) (n_1=n_2) (n1=n2)
所以在Q和K求内积的时候,content和content做内积,position和position做内积,不会有content和position做内积的情况,相当于减少了一部分attn-map中的噪声。
如果用加法的话,就会是这样:
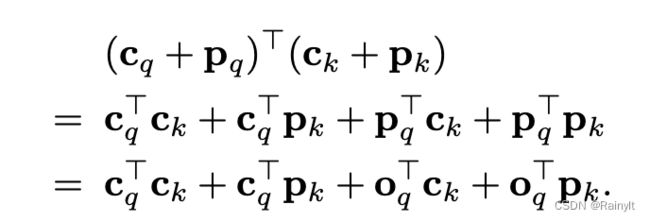
用concat就是这样:
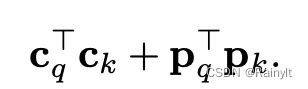
不过这是Conditional-DETR的工作