击败GPT3,刷新50个SOTA!谷歌全面统一NLP范式

文 | ZenMoore
编 | 小轶
写在前面
一觉醒来,迷糊之中看到一条推特:

瞬间清醒!
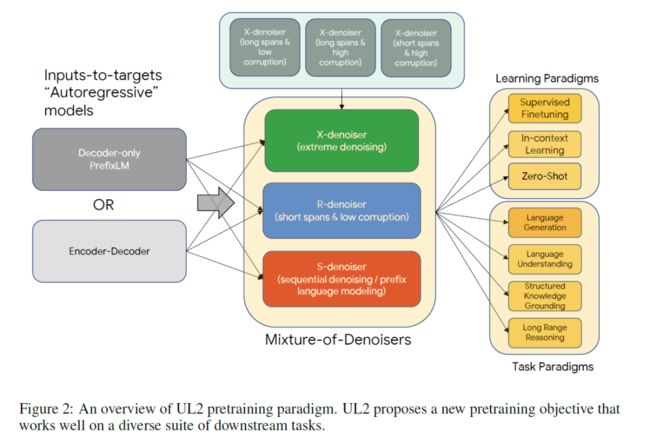
Google 的 Yi Tay (and Mostafa) 团队提出了一个新的策略 Mixture-of-Denoisers, 统一了各大预训练范式。
重新思考现在的预训练精调,我们有各种各样的预训练范式:decoder-only or encoder-decoder, span corruption or language model, 等等,不同的范式建模了不同的上下文关系,也正是因为如此,不同的预训练范式适配不同类型的下游任务。例如,基于双向上下文的预训练(span corruption,如T5)更加适用于 fact completion,基于单向上文(PrefixLM/LM,如GPT等)更加适用于 open ended. 也就是说,具体的下游任务类型需要选用特定的预训练策略...
准确地说,常见有三套范式:单向文本建模的CausalLM(i.e. LM),双向文本建模的 span corruption, 前缀文本建模的 PrefixLM.
这是大一统吗?感觉只能是小一统,总感觉还缺少一味菜!
今天,Google 把这道菜补上了!那就是:Mixture-of-Denoisers
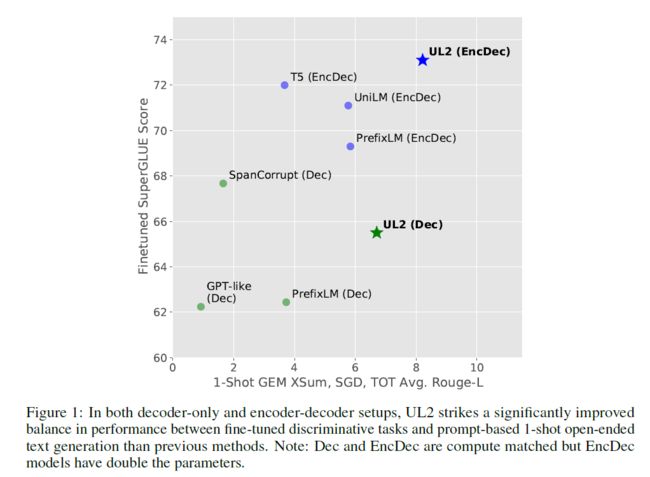
先来感受一下效果:
论文标题:Unifying Language Learning Paradigms
论文作者:Yi Tay, Mostafa Dehghani, etc. (Google)
论文链接:https://arxiv.org/pdf/2205.05131.pdf
方法 (UL2)
先说一下本文方法的目的:构建一种独立于模型架构以及下游任务类型的预训练策略,可以灵活地适配不同类型的下游任务。
整个方法的框架和 UniLM[1] 是很相似的,但是引入了稀疏化。
Mixture-of-Denoisers
首先回顾上文所说的三个预训练范式:CausalLM, PrefixLM, span corruption,其实都可以统一到 span corruption :
定义函数 , 这里 为平均 span 长度, 为 corruption rate, 为 corrupted span 的数量.定义输入序列长度为 ,经过正态分布或者均匀分布采样 corrputed span 后,训练模型学习恢复这些 span.
可见,对于 CausalLM,只需要设置 ; 对于 PrefixLM, 只需要设置 (为前缀长度)。
基于此,作者提出了 Mixture-of-Denoisers :

R-Denoiser : regular denoising. corrupted span 的长度为 2-5 个 tokens, 大约是 15% 的掩码率。通常用于获得知识而不是生成流畅文本的能力。
S-Denoiser : sequential denoising. 保留严格的序列顺序,通常用于 inputs-to-targets 任务,如 PrefixLM. 需要注意的是,可见的 Prefix 仍然是上下文建模方式,但是被掩码掉的长 span 是不可见的。
X-Denoiser : extreme denoising. 可以看作 R-denoiser 和 S-denoiser 的中间体,是一种极端的情况,也就是 span length 非常长,或者 masking rate 非常大。一般用于长文本生成任务,因为这类任务一般只有非常有限的上下文记忆信息。
最后,本文使用的七个 denoiser 设定如下:

Mode Switching
本文提出通过 mode-switching 来进行 paradigm-shifting. 首先在预训练的时候,新增三个 special tokens : ,分别指代三个 paradigms (i.e... denoiser). 然后在下游任务精调或者小样本学习时,也为特定任务的设定和需要,新增一个 paradigm token, 以触发模型学习更优的方案。
然后在主体模型架构上,使用 encoder-decoder 还是 decoder-only 是不重要的,因为本文方法的初衷就在于 architecture-agnostic (架构无关). 因此,作者基于 T5,对两种设定都进行了相关实验。
实验
消融实验
任务设定:
SuperGLUE (SG) :8 NLU sub-tasks
GEM benchmark : XSUM (summarization), ToTTo (table-to-text generation), Schema Guided Dialog (SGD)
C4 validation set
场景设定:
精调(fine-tuning)
基于提示的单样本学习
Baselines :
Causal Language Model (CLM) : GPT-style
Prefix LM (PLM)
Span Corruption (SC) : T5-style
Span Corruption + LM (SCLM)
UniLM (ULM)
Decoder v.s. Encoder-Decoder


结论:当不考虑存储时,encoder-decoder 比 decoder-only 更优;比起 backbone 架构,自监督目标更加重要。
Paradigm Prompt (mode switching)
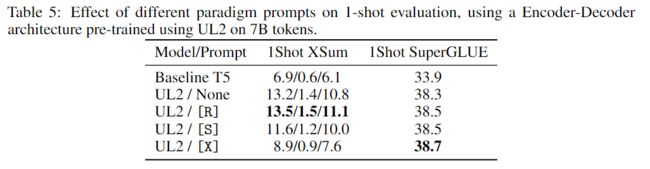
结论:在 one-shot 场景下,使用范式提示几乎总是更好,但是,选对 paradigm prompt 非常关键。
Mixture-of-Denoisers
 ▲SD% 表示 S-Denoisers 的占比
▲SD% 表示 S-Denoisers 的占比
结论:X-denoising 有补充性效果,但不能单用;只用一小部分 S-Denoisers () 更好。
小幅增加模型尺寸以及预训练数据量
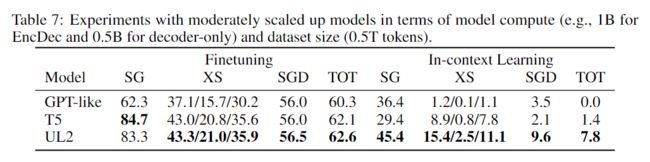
结论:本文方法在 SuperGLUE 上比 T5 差了一点,但是其他任务仍然领先。
200亿参数!
好了,现在开始壕起来:Scaling to 20B Parameters!
虽然这个方法是 architecture agnostic (架构无关)的,但基于上面的消融实验,我们 prefer Encoder-Decoder 架构,更重要的是:Encoder-Decoder 具备固有的稀疏特性(intrinsic sparsity)
任务设定:
文本生成:摘要和 data-to-text 生成。数据集:CNN/Dailymail,XSUM,MultiNews,SAMSum,WebNLG,E2E,CommonGen
人工评测的文本生成:aNLG, ARC-DA, WMT19, XSUM
理解、分类、问答:RACE, QASC, OpenBookQA, TweetQA, QuAIL, IMDB, Agnews, DocNLI, Adversarial NLI, VitaminC, Civil Comments and Wikipedia Toxicity detection
常识推理:HellaSwag, SocialIQA/SIQA, PhysicalIQA/PIQA, CosmosQA, AbductiveNLI, CommonsenseQA, CommonsenseQA2
长程推理:Scrolls benchmark (GovReport, SumScr, QMSUm, QASPER, NarrativeQA, QuaLITY, ContractNLI )
结构化知识 (Structured Knowledge Grounding): UnifiedSKG (WikiTQ, CompWQ, FetaQA, HybridQA, WikiSQL, TabFat, Feverous, SQA, MTOP, DART)
信息检索:Natural Questions
有意思的是:对于信息检索,作者使用的是 DSI[2] 进行的实验,简单说就是 text-to-docid 进行检索。
评测结果:
Tradeoffs between Finetuning and Prompt-based Zero-shot Learning (SuperGLUE)
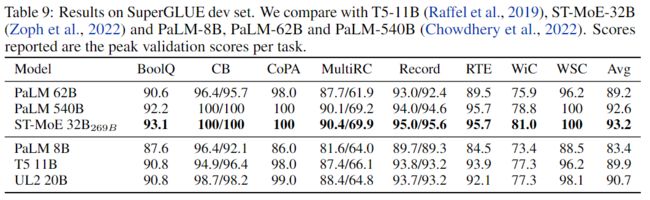

Generative Few-shot: XSUM Summarization
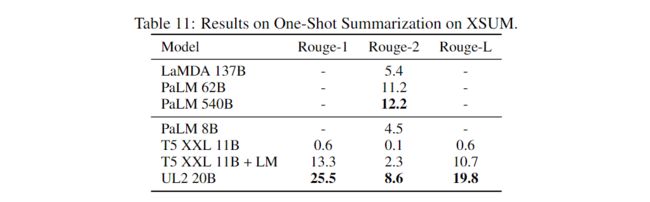
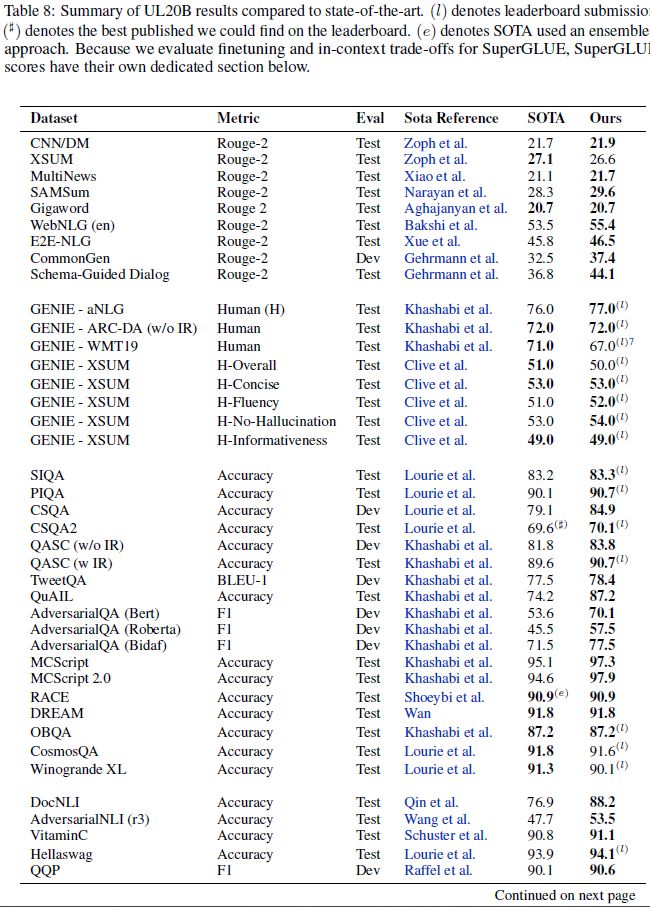
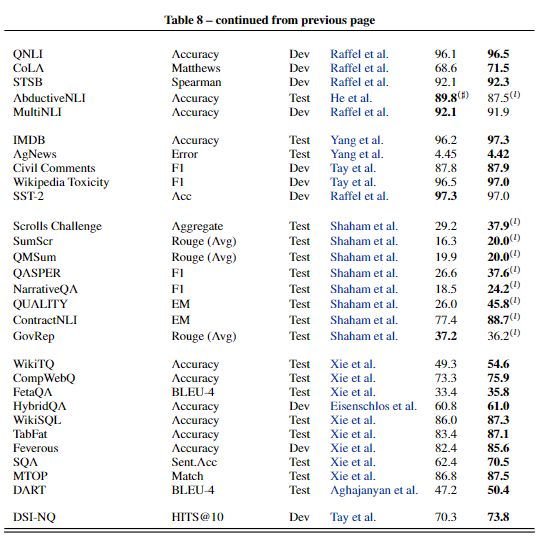
Summary of UL20B results compared to state-of-the-art
写在最后
看完这篇之后,总的感觉并没有第一眼看到推特时那样激动,或者说,也没有当初学习 UniLM[1] 时的感觉强烈。
我在之前的文章也提到过,Prompt 主要适用于三个场景:低资源、低算力、统一场景。也曾在知乎上发表过想法:Prompt 在某种程度上可以进行模型的专家化(expertization)或者模块化(modularization),需要和 Mixture-of-Experts 进行沟通。这篇文章使用 paradigm prompt 进行 denoiser 的 mode switching,有进一步的启发意义。脱离 denoiser 的 mixture,可能会有更加宏大的 picture.
另外,一直来说,为不同的下游任务部署特定的模型,是一个很消耗资源的方式,因此,一个统一的 black box 是必然的。虽然 GPT-3/T0[3] 等通过 instruction/prompt 或 in-context learning 等方式,为解决这个问题提供了思路,但是要真正 beat task-specific finetuning, 仍然有一段路要走。希望从这篇文章出发,能够彻底解决这个关键的部署问题。
萌屋作者:ZenMoore
北航本科生,爱数学爱物理爱 AI 想从 NLP 出发探索人工认知人工情感的奥秘!个人主页 zenmoore.github.io 知乎 ZenMoore, 微信 zen1057398161 嘤其鸣矣,求其友声✨!
作品推荐
一文跟进Prompt进展!综述+15篇最新论文逐一梳理
图灵奖大佬+谷歌团队,为通用人工智能背书!CV 任务也能用 LM 建模!
以4%参数量比肩GPT-3!Deepmind 发布检索型 LM,或将成为 LM 发展新趋势!?
后台回复关键词【入群】
加入卖萌屋NLP、CV与搜推广与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!

[1] UniLM : https://arxiv.org/pdf/1905.03197.pdf
[2] DSI : https://arxiv.org/pdf/2202.06991.pdf
[3] T0 : https://arxiv.org/pdf/2110.08207.pdf
