昇思25天学习打卡
@[TOC]《昇思25天学习打卡营第02天|lulul》
张量Tensor
张量tensor是在机器学习和深度学习中广泛应用的数据概念,张量是多维数组的泛化,能够表示标量(0维张量)、向量(1维张量)、矩阵(2维张量)及更高维的数组。
张量基本用法(mindspore)
data = [1, 0, 1, 0]
x_data = Tensor(data)
print(x_data, x_data.shape, x_data.dtype)
这里使用**Tensor()**将传统的一维数组转换为张量的形式
tensor.shape表示查看张量的维度信息
tensor.dtype表示查看张量的数据类型
from mindspore.common.initializer import One, Normal
# Initialize a tensor with ones
tensor1 = mindspore.Tensor(shape=(2, 2), dtype=mindspore.float32, init=One())
# Initialize a tensor from normal distribution
tensor2 = mindspore.Tensor(shape=(2, 2), dtype=mindspore.float32, init=Normal())
print("tensor1:\n", tensor1)
print("tensor2:\n", tensor2)
mindspore可以使用init方法构建张量。
init: 支持传入initializer的子类。如:示例中的 One() 和 Normal()。
shape: 支持传入 list、tuple、 int。
dtype: 支持传入mindspore.dtype。
张量的属性
张量的属性包括形状、数据类型、转置张量、单个元素大小、占用字节数量、维数、元素个数和每一维步长。
x = Tensor(np.array([[1, 2], [3, 4]]), mindspore.int32)
print("x_shape:", x.shape)
print("x_dtype:", x.dtype)
print("x_itemsize:", x.itemsize)
print("x_nbytes:", x.nbytes)
print("x_ndim:", x.ndim)
print("x_size:", x.size)
print("x_strides:", x.strides)
# x_shape: (2, 2)
# x_dtype: Int32
# x_itemsize: 4
# x_nbytes: 16
# x_ndim: 2
# x_size: 4
# x_strides: (8, 4)
形状(shape):Tensor的shape,是一个tuple。
数据类型(dtype):Tensor的dtype,是MindSpore的一个数据类型。
单个元素大小(itemsize): Tensor中每一个元素占用字节数,是一个整数。
占用字节数量(nbytes): Tensor占用的总字节数,是一个整数。
维数(ndim): Tensor的秩,也就是len(tensor.shape),是一个整数。
元素个数(size): Tensor中所有元素的个数,是一个整数。
每一维步长(strides): Tensor每一维所需要的字节数,是一个tuple。
张量运算
张量之间有很多运算,包括算术、线性代数、矩阵处理(转置、标引、切片)、采样等,张量运算和NumPy的使用方式类似,下面介绍其中几种操作。
普通算术运算有:加(+)、减(-)、乘(*)、除(/)、取模(%)、整除(//)。
x = Tensor(np.array([1, 2, 3]), mindspore.float32)
y = Tensor(np.array([4, 5, 6]), mindspore.float32)
output_add = x + y
output_sub = x - y
output_mul = x * y
output_div = y / x
output_mod = y % x
output_floordiv = y // x
print("add:", output_add)
print("sub:", output_sub)
print("mul:", output_mul)
print("div:", output_div)
print("mod:", output_mod)
print("floordiv:", output_floordiv)
# add: [5. 7. 9.]
# sub: [-3. -3. -3.]
# mul: [ 4. 10. 18.]
# div: [4. 2.5 2. ]
# mod: [0. 1. 0.]
# floordiv: [4. 2. 2.]
张量的拼接
可以使用tensor.concat; tensor.stack对张量从不同维度进行拼接
# 使用concat拼接
data1 = Tensor(np.array([[0, 1], [2, 3]]).astype(np.float32))
data2 = Tensor(np.array([[4, 5], [6, 7]]).astype(np.float32))
output = ops.concat((data1, data2), axis=0)
print(data1)
print(data2)
print(output)
print("shape:\n", output.shape)
output:
[[0. 1.]
[2. 3.]]
[[4. 5.]
[6. 7.]]
[[0. 1.]
[2. 3.]
[4. 5.]
[6. 7.]]
shape:
(4, 2)
# 使用stack拼接
data1 = Tensor(np.array([[0, 1], [2, 3]]).astype(np.float32))
data2 = Tensor(np.array([[4, 5], [6, 7]]).astype(np.float32))
output = ops.stack([data1, data2])
print(output)
print("shape:\n", output.shape)
output:
[[[0. 1.]
[2. 3.]]
[[4. 5.]
[6. 7.]]]
shape:
(2, 2, 2)
稀疏张量
这部分是我自己的一些理解把,如果有不对的大佬指正
举个例子稀疏张量可以理解为,假如我有一个一维张量
[1,2]
稀疏之后变成
[[1,0],
[0,2]]
类似变成这种
稀疏张量的主要优点:
节省内存:仅存储非零元素,减少了内存使用。
加速计算:在某些操作中,仅处理非零元素,可以显著提高计算效率。
提高数据存取效率:对于特定类型的操作,稀疏张量可以减少数据读取和写入的次数。
稀疏张量广泛应用于图神经网络、推荐系统、自然语言处理和科学计算等领域。
MindSpore现在已经支持最常用的CSR和COO两种稀疏数据格式。
# CSR格式
indptr = Tensor([0, 1, 2])
indices = Tensor([0, 1])
values = Tensor([1, 2], dtype=mindspore.float32)
shape = (2, 4)
# Make a CSRTensor
csr_tensor = CSRTensor(indptr, indices, values, shape)
print(csr_tensor.astype(mindspore.float64).dtype)
生成的稀疏化的张量:
[1 0 0 0 , 0 2 0 0]
indptr: 一维整数张量, 表示稀疏数据每一行的非零元素在values中的起始位置和终止位置, 索引数据类型支持int16、int32、int64。
indices: 一维整数张量,表示稀疏张量非零元素在列中的位置, 与values长度相等,索引数据类型支持int16、int32、int64。
values: 一维张量,表示CSRTensor相对应的非零元素的值,与indices长度相等。
shape: 表示被压缩的稀疏张量的形状,数据类型为Tuple,目前仅支持二维CSRTensor。
具体的参数细节建议阅读mindspore的官方文档。
# COO格式
indices = Tensor([[0, 1], [1, 2]], dtype=mindspore.int32)
values = Tensor([1, 2], dtype=mindspore.float32)
shape = (3, 4)
# Make a COOTensor
coo_tensor = COOTensor(indices, values, shape)
print(coo_tensor.values)
print(coo_tensor.indices)
print(coo_tensor.shape)
print(coo_tensor.astype(mindspore.float64).dtype) # COOTensor to float64
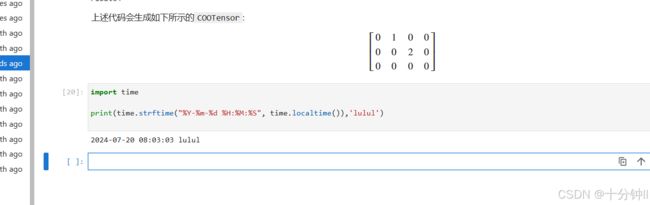
生成的张量:
[0 1 0 0 , 0 0 2 0 , 0 0 0 0]
indices: 二维整数张量,每行代表非零元素下标。形状:[N, ndims], 索引数据类型支持int16、int32、int64。
values: 一维张量,表示相对应的非零元素的值。形状:[N]。
shape: 表示被压缩的稀疏张量的形状,目前仅支持二维COOTensor。
最后附上打卡截图: