SparkSQL初级(聚合,Parquet,JSON,JDBC,Hive表)
紧接着系列博客上一篇Spark05-SparkSQL入门 的学习,这篇博客 主要讲解一些SparkSQL初级使用。
聚合(Aggregations)
内置的DataFrames函数提供常见的聚合,如count()、countDistinct()、avg()、max()、min()等。此外,用户并不局限于预定义的聚合函数,还可以创建自己的聚合函数。
无用户定义的聚合函数(Untyped User-Defined Aggregate Functions)
用户必须扩展UserDefinedAggregateFunction 抽象类以实现自定义无类型聚合函数。案例:用户定义的平均值
import org.apache.spark.SparkConf
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
/**
* 非类型用户定义的聚合函数
* @author xjh 2018.11.28
* 本案例是用户必须扩展UserDefinedAggregateFunction 抽象类以实现自定义无类型聚合函数。
* 得到用户定义的平均值
*/
object MyAverage extends UserDefinedAggregateFunction{
//此聚合函数的输入参数的数据类型
def inputSchema:StructType=StructType(StructField("inputColumn",LongType)::Nil)
//聚合缓冲区中值的数据类型
override def bufferSchema: StructType = {
StructType(StructField("sum",LongType)::StructField("count",LongType)::Nil)
}
//返回值的数据类型
def dataType:DataType=DoubleType
//这个函数是否总是对相同的输入返回相同的输出
override def deterministic: Boolean = true
//初始化给定的聚合缓冲区。缓冲区本身是一个“行”,除了
// 检索索引值(如get()、getBoolean())等标准方法之外,还提供
// 更新其值的机会。注意,缓冲区中的数组和映射仍然是不可变的。
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0)=0L
buffer(1)=0L
}
//使用来自“input”的新输入数据更新给定的聚合缓冲区“缓冲区”
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if(!input.isNullAt(0)){
buffer(0)=buffer.getLong(0)+input.getLong(0)
buffer(1)=buffer.getLong(1)+1
}
}
//合并两个聚合缓冲区,并将更新后的缓冲区值存储回“buffer1”
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0)=buffer1.getLong(0)+buffer2.getLong(0)
buffer1(1)=buffer1.getLong(1)+buffer2.getLong(1)
}
//计算得到最后结果
override def evaluate(buffer: Row): Double = buffer.getLong(0).toDouble/buffer.getLong(1)
}
object Aggregations{
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("Aggregations").setMaster("local")
val spark=SparkSession.builder().appName("Aggregations").config(conf).getOrCreate()
//注册函数来访问它
spark.udf.register("myAverage",MyAverage)
val df=spark.read
.json("file:///D:\\softInstall\\BigData\\spark-2.3.1-bin-hadoop2.6\\spark-2.3.1-bin-hadoop2.6\\examples\\src\\main\\resources\\employees.json")
df.createOrReplaceTempView("employees")
df.show() //输出表格中的数据
/**
+-------+------+
| name|salary|
+-------+------+
|Michael| 3000|
| Andy| 4500|
| Justin| 3500|
| Berta| 4000|
+-------+------+
**/
val result=spark.sql("SELECT myAverage(salary) as average_salary FROM employees")
result.show() //输出平均分
/**
* +--------------+
|average_salary|
+--------------+
| 3750.0|
+--------------+
*/
}
}
类型安全的用户定义聚合函数(Type-Safe User-Defined Aggregate Functions)
强类型数据集的用户定义聚合围绕Aggregator抽象类。案例:类型安全的用户定义平均值
import org.apache.spark.SparkConf
import org.apache.spark.sql.{Encoder, Encoders, SparkSession}
import org.apache.spark.sql.expressions.Aggregator
/**
* 类型安全的用户定义聚合函数
* @author xjh 2018.11.29
*/
case class Employee(name: String,salary:Long)
case class Average(var sum:Long,var count:Long)
object MyAverage2 extends Aggregator[Employee,Average,Double]{
//此聚合的值为零。是否满足任意b0 = b的性质
def zero:Average=Average(0L,0)
//将两个值组合生成一个新值。为了提高性能,函数可以修改‘buffer’
// 并返回它,而不是构造一个新的对象
override def reduce(b: Average, a: Employee): Average = {
b.sum+=a.salary
b.count+=1
b
}
//合并两个中间值
override def merge(b1: Average, b2: Average): Average = {
b1.sum+=b2.sum
b1.count+=b2.count
b1
}
//转换reduction输出
override def finish(reduction: Average): Double = reduction.sum.toDouble/reduction.count
//指定中间值类型的编码器
override def bufferEncoder: Encoder[Average] = Encoders.product
//指定最终输出值类型的编码器
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
object Aggregations2 {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("Aggregations2").setMaster("local")
val spark=SparkSession.builder().appName("Aggregations2").config(conf).getOrCreate()
import spark.implicits._
val df=spark.read.json("file:///D:\\softInstall\\BigData\\spark-2.3.1-bin-hadoop2.6\\" +
"spark-2.3.1-bin-hadoop2.6\\examples\\src\\main\\resources\\employees.json")
val ds=df.as[Employee] //运行这一句时 一定记得加上import spark.implicits._ 使其支持类型隐式转换
ds.show()
/**
* +-------+------+
| name|salary|
+-------+------+
|Michael| 3000|
| Andy| 4500|
| Justin| 3500|
| Berta| 4000|
+-------+------+
*/
//将函数转换为' TypedColumn '并为其命名
val averageSalary=MyAverage2.toColumn.name("average_salary")
val result=ds.select(averageSalary)
result.show()
/**
* +--------------+
|average_salary|
+--------------+
| 3750.0|
+--------------+
*/
}
}
Parquet数据
Parquet是一种流行的列式存储格式,可以高效的存储具有桥套字段的记录。Spark SQL支持读取和写入Parquet文件,这些文件自动保留原始数据的模式。在编写Parquet文件时,出于兼容性原因,所有列都会自动转换为可为空。据南国了解,Parquet也是现在SparkSQL进行数据分析用的最常见的数据源之一,另外常见的时Hive中的数据。
Parquet是语言无关的,而且不与任何一种数据处理框架绑定在一起,适配多种语言和组件,能够与Parquet配合的组件有:
- 查询引擎: Hive, Impala, Pig, Presto, Drill, Tajo, HAWQ, IBM Big SQL
- 计算框架: MapReduce, Spark, Cascading, Crunch, Scalding, Kite
- 数据模型: Avro, Thrift, Protocol Buffers, POJOs
1.以编程方式加载Parquet数据
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* 以编程方式加载Parquet数据
* @author xjh 2018.11.29
*/
object Parquet {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("Parquet").setMaster("local")
val spark=SparkSession.builder().appName("Parquet").config(conf).getOrCreate()
import spark.implicits._
val peopleDF=spark.read.json("file:///D:\\softInstall\\BigData\\spark-2.3.1-bin-hadoop2.6\\" +
"spark-2.3.1-bin-hadoop2.6\\examples\\src\\main\\resources\\people.json")
//数据框可以保存为Parquet文件,以维护模式信息
peopleDF.write.parquet("people.parquet")
//读取上面创建的parquet文件
// parquet文件是自描述的,所以模式是保留的
// 加载parquet文件的结果也是一个DataFrame
val parquetFileDF=spark.read.parquet("people.parquet")
//Parquet文件还可以用于创建临时视图,然后在SQL语句中使用
parquetFileDF.createOrReplaceTempView("parquetFile")
val nameDF=spark.sql("SELECT name FROM parquetFile WHERE age BETWEEN 13 AND 19")
nameDF.map(attribute=>"Name: "+attribute(0)).show()
// +------------+
// | value|
// +------------+
// |Name: Justin|
// +------------+
peopleDF.write.parquet("file:///D:\\softInstall\\BigData\\spark-2.3.1-bin-hadoop2.6\\" +
"spark-2.3.1-bin-hadoop2.6\\examples\\src\\main\\resources\\newpeople.parquet")
}
}
2.Parquet分区发现
表分区是一种常见的优化方式,比如Hive中就提供了表分区的特性。在一个分区表中,不同分区的数据通常存储在不同的目录中,分区列的值通常就包含在了分区目录的目录名中。Spark SQL中的Parquet数据源,支持自动根据目录名推断出分区信息。
3.模式合并
如同ProtocolBuffer,Avro,Thrift一样,Parquet也是支持元数据合并的。用户可以在一开始就定义一个简单的元数据,然后随着业务需要,逐渐往元数据中添加更多的列。在这种情况下,用户可能会创建多个Parquet文件,有着多个不同的但是却互相兼容的元数据。Parquet数据源支持自动推断出这种情况,并且进行多个Parquet文件的元数据的合并。
因为元数据合并是一种相对耗时的操作,而且在大多数情况下不是一种必要的特性,从Spark 1.5.0版本开始,默认是关闭Parquet文件的自动合并元数据的特性的。可以通过以下两种方式开启Parquet数据源的自动合并元数据的特性:
1、读取Parquet文件时,将数据源的选项,mergeSchema设置为true
2、将全局SQL选项spark.sql.parquet.mergeSchema参数设置为true
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{SaveMode, SparkSession}
/**
* Parquet模式合并(官网案例)
* @author xjh 2018.12.01
*/
object Parquet3 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Parquet3").setMaster("local")
// val sc = new SparkContext(conf)
val spark = SparkSession.builder().appName("Parquet3").config(conf).getOrCreate()
import spark.implicits._
//用于隐式的将RDD转换为DataFrame
//创建一个简单的DataFrame,存储到分区目录
val squaresDF = spark.sparkContext.makeRDD(1 to 5).map(i => (i, i * i)).toDF("value", "square")
squaresDF.show()
// squaresDF.write.parquet("hdfs://m1:9000/spark/sparkSQL/Parquet3/test_table/key=1")
//在新的分区目录中创建另一个DataFrame 添加新列并删除现有列
val cubesDF = spark.sparkContext.makeRDD(6 to 10).map(i => (i, i * i * i)).toDF("value", "cube")
// cubesDF.write.parquet("hdfs://m1:9000/spark/sparkSQL/Parquet3/test_table/key=2")
cubesDF.show()
//读取分区表
val mergeDF=spark.read.option("mergeSchema","true").parquet("hdfs://m1:9000/spark/sparkSQL/Parquet3/test_table")
//读取Parquet文件时,将数据源的选项,mergeSchema设置为true
mergeDF.printSchema()
// root
// |-- value: int (nullable = true)
// |-- square: int (nullable = true)
// |-- cube: int (nullable = true)
// |-- key: int (nullable = true)
}
}
JSON数据
Spark SQL可以自动推断JSON数据集的模式,并将其作为数据集[Row]加载。这个转换可以在数据集[String]或JSON文件上使用SparkSession.read.json()来完成。
注意,作为json文件提供的文件不是典型的json文件。每行必须包含一个单独的、自包含的有效JSON对象。它也称为换行分隔JSON。
对于常规的多行JSON文件,将multiLine选项设置为true。
关于数据源是JSON数据,我在上一篇博客中的代码就是利用JSON数据源输入的,这里不再过多累赘。
JDBC连接到其他数据库
Spark SQL还包括一个数据源,可以使用JDBC从其他数据库读取数据。与使用JdbcRDD相比,应该更喜欢这种功能。这是因为结果是作为一个DataFrame返回的,并且它们可以很容易地在Spark SQL中处理或与其他数据源连接。
这里连接其他数据库,我们在日常应用的最多是MySQL Oracel,所以在进行这部分学习之前,我们需要在搭建Spark集群的机器上安装配置数据库,例如MySQL
这部分的学习:
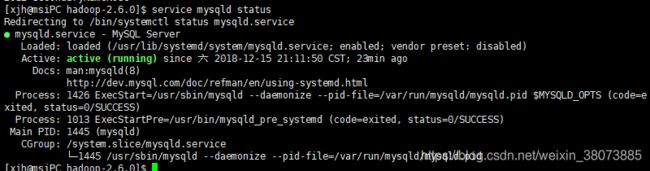
- Spark集群上成功安装MySQL,并创建相关数据库和数据表。为了应用方便,我们把MySQL设置为开机启动。MySQL5.7的状态查看可参考南国下面这张截图:
- 下载一个MySQL的JDBC驱动,例如mysql-connector-java-5.1.40-bin.jar
- 启动一个spark-shell,而且启动的时候,要附加一些参数。启动Spark Shell时,必须指定mysql连接驱动jar包。
bin/spark-shell --driver-class-path mysql-connector-java-5.1.40-bin.jar --jars mysql-connector-java-5.1.40-bin.jar
接着 就可以在spark-shell中根据自己的数据表单实现自己想要的功能。因为涉及到数据库的用户和密码以及数据表单。这里给出官网提供的代码:
// Note: JDBC loading and saving can be achieved via either the load/save or jdbc methods
// Loading data from a JDBC source
val jdbcDF = spark.read
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", "schema.tablename")
.option("user", "username")
.option("password", "password")
.load()
val connectionProperties = new Properties()
connectionProperties.put("user", "username")
connectionProperties.put("password", "password")
val jdbcDF2 = spark.read
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties)
// Specifying the custom data types of the read schema
connectionProperties.put("customSchema", "id DECIMAL(38, 0), name STRING")
val jdbcDF3 = spark.read
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties)
// Saving data to a JDBC source
jdbcDF.write
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", "schema.tablename")
.option("user", "username")
.option("password", "password")
.save()
jdbcDF2.write
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties)
// Specifying create table column data types on write
jdbcDF.write
.option("createTableColumnTypes", "name CHAR(64), comments VARCHAR(1024)")
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties)
如果这里还有不太清楚的,可参考厦大林子语老师的通过JDBC连接数据库(DataFrame)
Hive 表
Spark SQL还支持读取和写入存储在Apache Hive中的数据。但是,由于Hive具有大量依赖项,因此这些依赖项不包含在默认的Spark分发中。如果可以在类路径上找到Hive依赖项,Spark将自动加载它们。请注意,这些Hive依赖项也必须存在于所有工作节点上,因为它们需要访问Hive序列化和反序列化库(SerDes)才能访问存储在Hive中的数据。
Hive的配置是通过hive-site.xml,core-site.xml(安全性配置),以及hdfs-site.xml(对于HDFS配置)文件中conf/。
在使用Hive时,必须SparkSession使用Hive支持进行实例化,包括连接到持久性Hive Metastore,支持Hive serdes和Hive用户定义函数。没有现有Hive部署的用户仍可以启用Hive支持。如果未配置hive-site.xml,则上下文会自动metastore_db在当前目录中创建并创建由其配置spark.sql.warehouse.dir的目录spark-warehouse,该目录默认为 当前目录中启动Spark应用程序的目录。
请注意,自Spark 2.0.0以来,该hive.metastore.warehouse.dir属性hive-site.xml已被弃用。而是spark.sql.warehouse.dir用于指定仓库中数据库的默认位置。您可能需要向启动Spark应用程序的用户授予写入权限。
spark读取Hive中的数据
scala> import org.apache.spark.sql.Row
import org.apache.spark.sql.Row
scala> import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.SparkSession
scala> case class Record(key: Int, value: String)
defined class Record
scala> val warehouseLocation = "spark-warehouse"
warehouseLocation: String = spark-warehouse
scala> val spark = SparkSession.builder().appName("Spark Hive Example").config("spark.sql.warehouse.dir", warehouseLocation).enableHiveSupport().getOrCreate()
2018-09-28 09:23:19 WARN SparkSession$Builder:66 - Using an existing SparkSession; some configuration may not take effect.
spark: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@6ea48ca1
scala> import spark.implicits._
import spark.implicits._
scala> import spark.sql
import spark.sql
scala> sql("SELECT * FROM sparktest.student").show()
+---+--------+------+---+
| id| name|gender|age|
+---+--------+------+---+
| 1| Xueqian| F| 23|
| 2|Weiliang| M| 24|
+---+--------+------+---+
向hive数据库中的数据表中插入数据
scala> import java.util.Properties
scala> import org.apache.spark.sql.types._
scala> import org.apache.spark.sql.Row
//下面我们设置两条数据表示两个学生信息
scala> val studentRDD = spark.sparkContext.parallelize(Array("3 Rongcheng M 26","4 Guanhua M 27")).map(_.split(" "))
//下面要设置模式信息
scala> val schema = StructType(List(StructField("id", IntegerType, true),StructField("name", StringType, true),StructField("gender", StringType, true),StructField("age", IntegerType, true)))
//下面创建Row对象,每个Row对象都是rowRDD中的一行
scala> val rowRDD = studentRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).trim, p(3).toInt))
//建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来
scala> val studentDF = spark.createDataFrame(rowRDD, schema)
//查看studentDF
scala> studentDF.show()
+---+---------+------+---+
| id| name|gender|age|
+---+---------+------+---+
| 3|Rongcheng| M| 26|
| 4| Guanhua| M| 27|
+---+---------+------+---+
//下面注册临时表
scala> studentDF.registerTempTable("tempTable")
scala> sql("insert into sparktest.student select * from tempTable")
//查看数据表中的数据
scala> spark.sql("select * from sparktest.student").show
+---+---------+------+---+
| id| name|gender|age|
+---+---------+------+---+
| 1| Xueqian| F| 23|
| 2| weixin| M| 23|
| 3|Rongcheng| M| 26|
| 4| Guanhua| M| 27|
+---+---------+------+---+