前端状态管理的工具库纷杂,在开启一个新项目的时候不禁让人纠结,该用哪个?其实每个都能达到我的目的,我们想要的无非就是管理好系统内的状态,使代码利于维护和拓展,尽可能降低系统的复杂度。
使用 Vue 的同学可能更愿意相信其官方的生态,直接上 vuex/pinia,不用过多纠结。由于我平常使用 React 较多,故就当前应用较广泛的 Redux、Mobx 俩工具库为例,研读了一番,记录下自己的一些闲言碎语。
注意:以下不会涉及到各个库的具体用法,多是探讨各自的设计理念、推崇的模式(patterns),提前说明,以免耽误大家时间。
Redux、Mobx 或多或少都借鉴了 Flux 理念,比如大家经常听到的 “单向数据流” 这项原则最开始就是由 Flux 带入前端领域的,所以我们先来聊聊 Flux。
Flux
Flux 是由 facebook 团队推出的一种架构理念,并给出一份代码实现。
为什么会有 Flux 的诞生?
Facebook 一开始是采用传统的 MVC 范式进行系统的开发
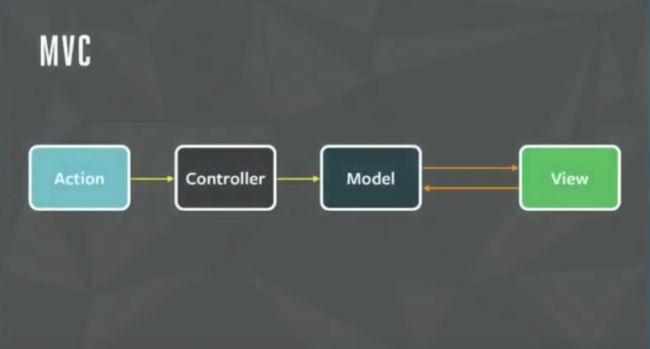
但随着业务逻辑的复杂,渐渐地发现代码里越来越难去加入新功能,很多状态耦合在了一起,对于状态的处理也耦合在了一起
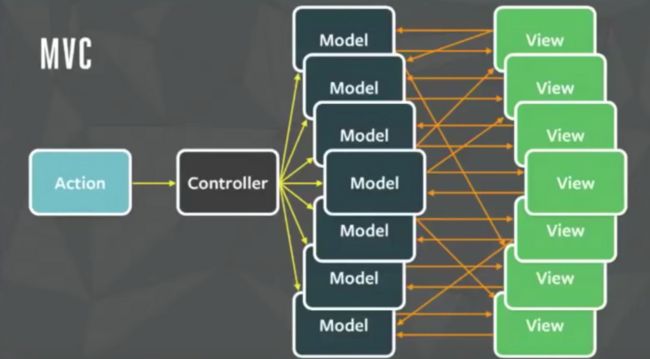
造成了 FB 团队对 MVC 吐槽最深的两个点:
- Controller 的中心化不利于扩展,核心是因为 Controller 里需要处理大量复杂的对于 Model 更改的逻辑
- 对于 Model 的更改可能来源于各个方向。 可能是开发者本身想对 Model 进行更改、可能是 View 上的某个回调想对 Model 进行更改,可能是一个 Model 的更改引发了另一个 Model 的更改。
我们可以大概总结出,基于 MVC 的数据流向就有三种:
- Controller -> Model -> View
- Controller -> Model -> View -> Model -> View ... (loop)
- Controller -> Model1 -> Model2 -> View1 -> view2 ...
并且这三种数据流向在实际业务中还很有可能是交织在一起。
为了改善以上 MVC 在复杂应用中的缺陷,降低系统整体复杂度,FB 团队推出了 Flux 架构,结合 React 重构了他们的代码,这就是 Flux 架构诞生的原因。
Flux 具体是什么
Flux 由几个部分组成:
- Store
- Action
- View
- Dispatcher
Store 就是存放 Model 的地方,View 和 MVC 的 View 一样就是视图,Action 可以理解为操作 Model 的行为,Dispatcher 可以理解为找到 Action 对应 Store 并执行操作的分发执行者。
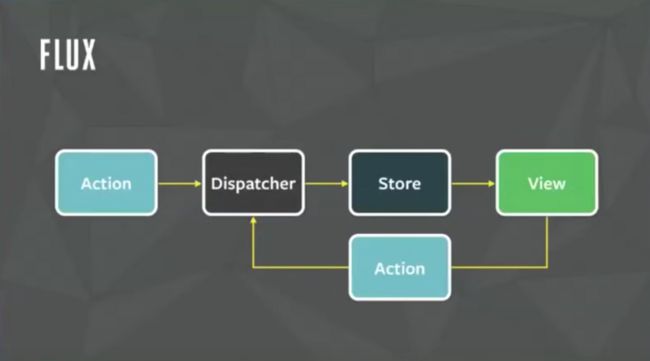
Dispatcher 是 Flux 的核心,它把对 Model 的操作给统一了起来,在 Flux 里,Dispatcher 与 View 可以视为 Model 的唯一输入输出。
那么相对于 MVC 带来的变化或者说好处是什么呢?
首先,数据流统一了,无论谁想要操作 Model,必须通过 disptacher ,同时 dispatcher 与 Action 配合,等同于是给 Model 约定了有限的、分离开的几种操作。对比 MVC 里中心化的 Controller 中对大量复杂的 Model 逻辑的操作,在 Flux 中就是被抽象分离到一个个 Action 里去了。所以状态在整个系统里的流向就是:
Action -> dispatcher -> Model -> View -> Action -> dispatcher -> Model -> View ...
这就是所谓的 “单向数据流”。 相对于 MVC 中多种数据流交叉,单向数据流明显降低了系统的复杂度。
又因为 Action 给 Model 约定了有限的几种操作,仅根据 Action 的输入,开发者就知道会发生怎样的变更,提高了代码的可预测性。
基于 MVC 范式的代码,项目的长期维护者可能清楚各个地方状态变更会引发什么操作,但是若团队来了新人,想搞清楚这些肯定需要费不少劲,假如基于 Flux 架构,开发者只需要追踪一个 Action 是怎样在整个系统中流动的,就知道系统的其余部分是怎样工作的了。因为 Flux 的数据流动是单向的且一致的。比如通过 Action 就知道要对状态做怎样的变更,再搜一下哪里用了变更的状态就知道这里的视图会 rerender,同样的搜一下哪个地方 disptach 了这个 action,就知道谁想对状态做出改变。
另外,还可以结合纯函数的概念来感受下 Dispatcher 的设计
这在 Redux 的实现中体现地尤为明显,就是在找到 Action 对应的 Store 后,单纯只负责根据 Action 处理对 Model 的改动逻辑,不会改变入参或外部变量,相同的输入始终对应相同的 Store 更改。意味着之后任意一个时间点做出一个之前时间点的 Action,得到的更改后的状态与之前得到的是一致的。这就是所谓的 “时间旅行” 功能的原理,“时间旅行” 本质就是记录下每一次数据修改,只要每次修改都是无状态的,那么我们理论上就可以通过修改记录还原之前任意时刻的数据。
结合纯函数的设计至少可以带来两点好处:
- 方便开发者调试。我们可以利用 “时间旅行” 复现之前任意时间点的状态,可以统一地在 dispatcher 里加日志看到何时做了什么改变。
- 基于纯函数构建的代码更容易写单测
Redux
Redux 就是基于 Flux 架构理念的一种函数式地实现,并做出了一些优化,所以 Redux 拥有 Flux 架构的所有优点。
上图是 Redux 官网给的展示 Redux 工作原理的 gif 图,朴素一点展示 Redux 的核心组成就是:

其中,Reducer 就是 Flux Dispatcher 的纯函数式实现,找到 Action 对应的 Model,返回一个更改后的对象给 Redux,Redux 在 Store 上应用更改。
据以上俩图,可以明显感知到 Redux 数据流动是单向的:
action -> middleware -> reducer -> store -> view -> action -> middleware -> reducer -> store -> view ...
解释 Redux 三个基本原则
Redux 官方表明可以用三个基本原则描述 Redux :“单一数据源“、“只读的 state“、“使用纯函数来执行修改“。
“单一数据源“相对于分散数据源肯定是优势的,除非各个数据源之间毫无联系。但只要是有联系的多个数据源,你始终要通过某些操作把各个数据源给联系起来,无疑增加了复杂度。
“只读的 state”也就是不允许直接修改 Model,必须创建个 action ,交给 reducer 处理,保证 Model 只有唯一输入,这是践行单向数据流的基本要求。
“使用纯函数来执行修改”就是要求用户编写的 reducer 必须得是纯函数,方便方便开发者调试也易于写单测。
另外,要求开发者编写纯函数的 reducer 还有个想突出点就是 Redux 推崇的 Immutable 特性。
Immutable 与 Mutable
什么是 Immutable ,什么是 Mutable ?
Immutable 意为「不可变的」。在编程领域,Immutable Data 是指一种一旦创建就不能更改的数据结构。它的理念是:在更改时,产生一个与原对象完全一样的新对象,指向不同的内存地址,互不影响。
Mutable 意为 「可变的」。与 Immutable 相反,Mutable Data 就是指一种创建后可以直接更改的数据结构。
对于 JS 而言,所有原始类型 (Undefined, Null, Boolean, Number, BigInt, String, Symbol) 都是 Immutable 的,但是引用类型的值都是 Mutable 的。
举两个例子直观感受下:
例一:
let a = { x: 1 };
let b = a;
b.x = 6;
a.x // 6例二:
function doSomething(x) { /* 在此处改变 x 会影响到 str 和 obj 吗? */ };
var str = 'a string';
var obj = { an: 'object' };
doSomething(str); // 基础类型都是 immutable 的, function 得到的是一个副本
doSomething(obj); // 对象传递的是引用,在 function 内是 mutable 的
doAnotherThing(str, obj); // `str` 没有被改变, 但是 `obj` 可能已经变化了。js 中其实有几种方式可以让值变为 Immutable 的,为了不跑题,大家可以去 wikipedia 拓展阅读。要注意的是,无论是writeable: false 或 Object.freeze 或 const,其修饰/冻结/声明的属性/值都只在第一层生效,假如属性/值嵌套了引用类型值,则需要递归去修饰/冻结/声明才能达到整体 Immutable 的目的。
Immutable 与 Mutable 的优缺
Mutable
其实比较显而易见,Mutable 的数据,开发者可以直接更改,但是要负担更改后副作用的思考。
优点:操作便利。
缺点:开发者内心要知道更改了 Mutable 数据后,会导致哪些副作用,会怎样影响到其他用到该数据的地方。
Immutable
其实就是 Mutable 的相反,不过可以基于 Immutable 特性做一些额外的功能。
优点:
避免了数据更改的副作用 (在多线程语言中就是有了所谓 “线程安全性”)
JS 虽然没有多线程的概念,但有竞态的概念。 JS 中引用类型的值都是按引用传递的,在一个复杂应用中会有多个变量指向同一个内存地址的情况,如果有多个代码块同时更改这个引用,就会产生竞态。你需要关心这个对象会在哪个对方被修改,你对它的修改会不会影响其他代码的运行。使用 Immutable Data 就不会产生这个问题——因为每当状态更新时,都会产生一个新的对象。
状态可追溯
由于每次修改都会创建一个新对象,且对象不会被修改,那么变更的记录就能够被保存下来,应用的状态变得可控、可追溯。Redux Dev Tool 和 Git 这两个能够实现「时间旅行」的工具就是秉承了 Immutable 的哲学。
缺点也是相对于 Mutable 方式的:
- 额外的CPU、内存开销
- 达到修改值的目的要做额外的操作
尽管生态内有如 Immutable.js、Immer.js 等库帮助我们更便捷地操作 Immutable 更改,但是这两个缺点也是无法避免的,只是尽可能地做优化。
至于是采用 Immutable 还是 Mutable 的方案去写代码,个人觉得还是得 case by case 地去聊,显然 Redux 推崇 Immutable,基于此提供了时间旅行的功能,React 推荐开发者使用 Immutable ,是因为 React 的 UI = fn(states) 模型中,React 对 state 是 shallowMerge 的,如果 mutable state 没改变引用,React 会认为不需要去 diff,自然不会 rerender 。但是 Mobx 就是推崇 Mutable 的,开发者使用体验很好。
Mobx
Mobx 是一个推崇自动收集依赖与执行副作用的响应式状态管理库,推荐开发者使用 Mutable 直接更改状态,框架内部帮我们管理(派生)每个 Mutable 的副作用并实现最优处理。
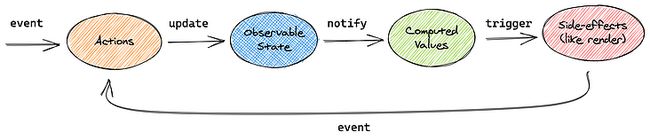
由上图可感知 Mobx 也是践行单向数据流的理念:
Action -> State -> Computed Value -> Reaction(like render) -> Action ...
这里引入了新的概念是 Computed Value 和 Reaction 。Mobx 是多 Store 的,联系多个数据源的数据可以用 Computed Value ,同一个数据源想要多个数据派生出一个新数据也可以用 Computed Value。Reaction 的话就是 state 的所有副作用,可以是 render 方法,可以是 Mobx 自带的 autorun、when 等。
Mobx 想要达到的目的其实就是开发者能自由地管理状态、让修改状态的行为简单直接,其余交给 Mobx。
想要达到这一目的,Mobx 内部就要做更多的事情,其作者 Michel Weststrate 有在一篇推文中阐述过 Mobx 设计原则,但是有点过于细节,不熟悉 Mobx 底层机制的同学可能不太看得懂。以下,在基于这篇推文结合对源码的探究,我提炼一下,感兴趣可以去看原文。
自荐对 Mobx 源码的解析文章: Mobx 源码与设计思想。文章较长,建议专门找时间安静地一口气看完。
对状态改变作出反应永远好过于对状态改变作出动作
针对这点其实与 Vue 响应式传递的理念相同,就是数据驱动。
再分析这句话,“作出反应” 意味着状态与副作用的绑定关系由框架(库)给你做好,状态改变自动通知到副作用,不用使用者(开发者)人为地处理。
“作出动作”则是在使用者已知状态更改的情况下,手动去通知副作用更新。 这起码就有一个操作是使用者必做的:手动在副作用内订阅状态的变化,这至少带来两个缺陷:
- 无法保证订阅量的冗余性,可能订阅多了可能少了,导致应用出现不符合预期的情况。
- 会让业务代码变得更 dirty,不好组织
最小的、一致的订阅集
以 render 作为副作用举例,假如 render 里有条件语句:
render() {
if (依赖 A) {
return 组件 1;
}
return 依赖 B ? 组件 2 : 组件 3;
}首先,如果交给用户手动订阅,必须只能依赖 A、B 的状态一起订阅才行,如果订阅少了无法出现预期的 re-render。
然后交给框架去做处理怎样才好? 依赖 A、B 一起订阅当然没毛病,但是假设依赖 A、B 初始化时都有值,我们有必要让 render 订阅依赖 B 的状态吗?
没必要,为什么?想一想如果此时依赖 B 的状态变化了 re-render 呈现的效果会有什么不同吗?
所以在初始化时就订阅所有的状态是冗余的,假如应用程序复杂、状态多了,没必要的内存分配就会更多,对性能有损耗。
故 Mobx 实现了运行时处理依赖的机制,保证副作用绑定的是最小的、一致的订阅集。源码见Mobx 源码与设计思想 中 “getter 里干了啥?” 与 “处理依赖” 章节。
派生计算(副作用执行)的合理性
说人话就是:杜绝丢失计算、冗余计算。
丢失计算:Mobx 的策略是引入状态机的概念去管理依赖与派生,让数学的逻辑性保证不会丢失计算。
冗余计算:
- 对于非计算属性状态,引入事务概念,保证同一批次中所有对状态的同步更改,状态对应的派生只计算一次。
- 对于计算属性,计算属性作为派生时,当其依赖变化,计算属性不会立即重新计算,会等到计算属性自身作为状态所绑定的派生再次用到计算属性值时才去重新计算。并且计算出相同值会阻止派生继续处理。
Redux vs Mobx
如上面分析,Redux 是一个重思想轻代码的状态管理库,Mobx 则是相反,框架帮我们做了更多的事,用起来简单。
稍微总结下区别:
- Redux 要求开发者按它的模式(patterns)写代码,Mobx 则自由许多,用起来更简单。相对地,基于 Redux 开发的系统健壮性要强一些,使用 Mobx 却管理不好状态的话,会使系统更难维护(咦,这为啥没渲染?咦!这为啥渲染了这么多次??(逃 )。
- Redux 结合函数式与 Immutable 的特性提供了时间旅行功能,更方便开发者调试与回溯状态。 Mobx 则是有提供一个全局监听的钩子,监听每一个状态改变与副作用的触发,我们直接打日志调试,但是相对于 Redux 肯定是没那么方便的。
- Redux 推崇单 Store 管理状态,降低状态管理的复杂度。Mobx 则不给开发者设限,开发者可以以任一形式管理状态,如果是多 Store,提供了 Computed Value 作为多 Store 数据的联系桥梁。
- Mobx 框架内部会帮我们实现最优渲染(副作用执行),Redux 则需要我们编写各种 selector 或用 memo 手动去优化...
以上,欢迎有理有据地指正、补充。
参考: