机器学习——正则化
前言:大多数模型都是直接给出公式,其实自己私下有推导,涉及好多自己不懂的数学知识,会一点点补充的
机器学习专栏:机器学习专栏
文章目录
- 正则化
-
- 1、过拟合问题
- 2、正则化
-
- 2.1正则化原理
- 2.2L2正则化线性回归
- 2.3L2正则化逻辑回归
- 3、sklearn实现L2正则化
正则化
1、过拟合问题
什么是过拟合?顾名思义,过度拟合,对训练集的学习过于充分,以至于一些影响很小的属性都学到了,但是这并不是我们需要的特征,导致在测试集上的拟合效果很差,比如我们想区分猫和狗,最重要的特征应该是鼻子、耳朵等特征,但是我们学习的时候把颜色也作为重要特征学习进去了,但是颜色这个属性并不是区分的重要特征!(图片插的好违和)

与过拟合相对的是欠拟合,对训练集的学习不充分,很多特征都没有学习到,导致模型的效果不佳。
2、正则化
2.1正则化原理
正则化的思想是通过代价函数对参数进行惩罚,但是我们不知道要对那些参数进行惩罚,所以我们通过将所有参数纳入代价函数中,通过实现最小化代价函数的最优化的问题,来实现对不同参数的惩罚程度。
正则化主要有以下两种:
- L1范数
L1范数作为正则化项,会让模型参数θ稀疏话,就是让模型参数向量里为0的元素尽量多。L1就是在成本函数后加入:
λ ∑ j = 1 n θ j \lambda\sum_{j=1}^{n}\theta_j λj=1∑nθj - L2范数
L2范数作为正则化项,则是让模型参数尽量小,但不会为0,即尽量让每个特征对预测值都有一些小的贡献。L2就是在成本函数后加入:
λ ∑ j = 1 n θ j 2 \lambda\sum_{j=1}^{n}\theta_j^2 λj=1∑nθj2
为什么会造成这样的结果?梯度下降法的参数迭代实际上是在代价函数的等高线上跳跃,最终收敛在误差最小的点,L1的下降速度比L2的下降速度要快,所以会非常快得降到0。
对单变量线性回归,对参数 θ 0 \theta_0 θ0和 θ 1 \theta_1 θ1他们构成一个二维向量 θ = [ θ 0 , θ 1 ] \theta=[\theta_0,\theta_1] θ=[θ0,θ1]
L1范数:向量里元素的绝对值之和
∣ ∣ θ ∣ ∣ 1 = ∣ θ 0 ∣ + ∣ θ 1 ∣ ||\theta||_1=|\theta_0|+|\theta_1| ∣∣θ∣∣1=∣θ0∣+∣θ1∣
L2范数:元素平方和
∣ ∣ θ ∣ ∣ 2 = ∣ θ 0 ∣ 2 + ∣ θ 1 ∣ 2 ||\theta||_2=|\theta_0|^2+|\theta_1|^2 ∣∣θ∣∣2=∣θ0∣2+∣θ1∣2
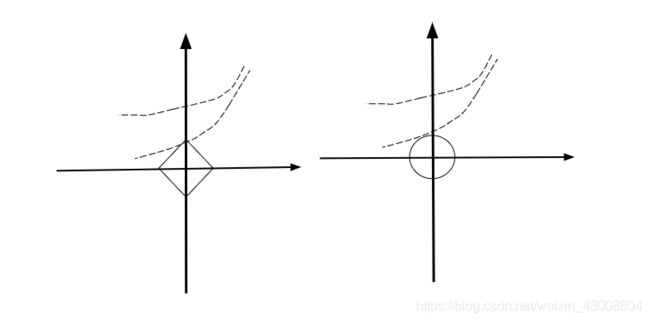
通过观察上图可以看出,误差等高线和L1范数等值线相切于坐标轴上的点,而和L2范数等值线相切的点往往不在坐标轴上。正则化的目的主要是为了防止过拟合,一般选择L2正则化就够啦,但是如果选择L2正则化还是过拟合,就可以选择使用L1正则化。如果模型的特征变量很多,我们希望做一些特征选择(即把一些不重要的特征过滤掉),这种情况下也可以选择用L1正则化。
2.2L2正则化线性回归
对于线性回归的求解,我们之前推导了两种学习算法:一种基于梯度下降,一种基于正规方程。
正则化线性回归的代价函数为:
J ( θ ) = 1 2 m [ ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 + λ ∑ j = 1 n θ j 2 ] J(\theta)=\frac {1}{2m}[\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})^2+\lambda \sum_{j=1}^{n}\theta^2_j] J(θ)=2m1[i=1∑m(hθ(x(i))−y(i))2+λj=1∑nθj2]
如果我们要使用梯度下降法令这个代价函数最小化,因为我们未对 θ0 进行正则化,所
- 以梯度下降算法将分两种情形:
{ θ 0 : = θ 0 − α m ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) x 0 ( i ) θ j : = θ j − α m ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) + λ m θ j ) \left\{\begin{matrix} \theta_0:=\theta_0-\frac{\alpha}{m}\sum_{i=1}^{m}((h_\theta(x^{(i)})-y^{(i)})x_0^{(i)} & & \\ \theta_j:=\theta_j-\frac{\alpha}{m}\sum_{i=1}^{m} ((h_\theta(x^{(i)})-y^{(i)})x_j^{(i)}+\frac{\lambda}{m}\theta_j) & & \end{matrix}\right. {θ0:=θ0−mα∑i=1m((hθ(x(i))−y(i))x0(i)θj:=θj−mα∑i=1m((hθ(x(i))−y(i))xj(i)+mλθj) - 利用正规方程法得:
θ = ( X T X + λ [ 0 1 : : 1 ] ) − 1 X T Y \theta=(X^TX+\lambda\begin{bmatrix} 0 & \\ &1\\ &&:\\ &&&:\\ &&&&1 \end{bmatrix})^{-1}X^TY θ=(XTX+λ⎣⎢⎢⎢⎢⎡01::1⎦⎥⎥⎥⎥⎤)−1XTY
图中矩阵尺寸为 ( n + 1 ) ∗ ( n + 1 ) (n+1)*(n+1) (n+1)∗(n+1)
(怎么推导的我也不懂呜呜呜T^T)
2.3L2正则化逻辑回归
对逻辑回归的代价函数增加一个正则化的表达式:
J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) l o g ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) ) ] + λ 2 m ∑ j = 1 n θ j 2 J(\theta)=-\frac{1}{m}\sum_{i=1}^{m}[y^{(i)}log(h_\theta(x^{(i)}))+(1-y^{(i)})log(1-h_\theta(x^{(i)}))]+\frac{\lambda}{2m}\sum_{j=1}^{n}\theta_j^2 J(θ)=−m1i=1∑m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]+2mλj=1∑nθj2
得梯度下降公式为:
{ θ 0 : = θ 0 − α m ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) x 0 ( i ) θ j : = θ j − α m ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) + λ m θ j ) \left\{\begin{matrix} \theta_0:=\theta_0-\frac{\alpha}{m}\sum_{i=1}^{m}((h_\theta(x^{(i)})-y^{(i)})x_0^{(i)} & & \\ \theta_j:=\theta_j-\frac{\alpha}{m}\sum_{i=1}{m} ((h_\theta(x^{(i)})-y^{(i)})x_j^{(i)}+\frac{\lambda}{m}\theta_j) & & \end{matrix}\right. {θ0:=θ0−mα∑i=1m((hθ(x(i))−y(i))x0(i)θj:=θj−mα∑i=1m((hθ(x(i))−y(i))xj(i)+mλθj)
[注]公式看上去和线性回归一样,但是逻辑回归中 h θ ( x ( i ) ) = g ( θ T x ( i ) ) h_\theta(x^{(i)})=g(\theta^Tx^{(i)}) hθ(x(i))=g(θTx(i)),线性回归中 h θ ( x ( i ) ) = θ T x ( i ) h_\theta(x^{(i)})=\theta^Tx^{(i)} hθ(x(i))=θTx(i)
3、sklearn实现L2正则化
sklearn通过penalty参数实现正则化
- p e n a l t y = ′ l 2 ′ penalty='l2'\quad penalty=′l2′#表示L2正则化
- p e n a l t y = ′ l 1 ′ penalty='l1'\quad penalty=′l1′#表示L1正则化
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 13 20:10:51 2019
@author: 1
"""
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import pandas as pd
df=pd.read_csv('D:\\workspace\\python\machine learning\\data\\breast_cancer.csv',sep=',',header=None)
X = df.iloc[:,0:29]
y = df.iloc[:,30]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=33)
model = LogisticRegression()
model.fit(X_train, y_train)
print('无正则化R2值:',model.score(X_test, y_test))
print('无正则化Coefficients:\n',model.coef_)
#L2正则化
model2 = LogisticRegression(penalty='l2')
model2.fit(X_train, y_train)
print('R2值:',model2.score(X_test, y_test))
print('正则化Coefficients:\n',model2.coef_)