深度学习 --- 优化入门六(正则化、参数范数惩罚L0、L1、L2、Dropout)
前面几节分别从不同的角度对梯度的优化进行梳理,本节将进行正则化的梳理,所谓正则化,简单来说就是惩罚函数,在机器学习中的SVM中引入拉格朗日乘子法即引入惩罚项解决了约束问题,在稀疏自编码器中我们引入了惩罚因子去自动调整隐层的神经元的个数,以此达到压缩率和失真度的平衡,其实这些都是使用正则思想进行实现的,因此掌握正则化很重要,本节就系统的讲解正则化和数据扩充以及Dropout其实有些知识在前面的学习中都穿插了,这里在单独拿出来的原因就是整理成系统性的知识,以后遇到相似问题能够想到,因此多总结多思考就会进步很快,废话不多说,下面开始:
参数范数惩罚
机器学习中常使用的正则化措施是去限制模型的能力,最常用的方法就是L0,L1和L2范数惩罚。下面就详细的讲解这三个范数惩罚
L0范数惩罚:
假设我们要拟合一群二次函数分布的数据,但并不知道其真实的分布规律(知道也就不用学习了)。学习的本质其实就是不停地尝试,先从一次函数进行尝试,然后是五次函数,九次函数,三次函数,二次数等,然后选出其中效果最好的一个,便是那最
佳模型。以上方法有些令人失望,但未尝不是一个好方法。当然,为了显得“高端”些,我们需要将上面的内容粉饰一下。我们知道九次多项式包含了前八次多项式,那么为了节省力气,我们想要八次多项式时,只需要将九次项系数设置为0就可以了。有了这种想法,多项式函数的模型选择,其实就变成了高次多项式系数的限制。从高次多项式数一直到二次多项式函数的尝试,其实就是在限制参数的个数,如下式所示的九次多项式。
![]()
只保留前三阶的的多项式如下:
![]()
简单来说就是高阶的系数为零,使用数学表示即使用约束条件进行表示如下:
![]()
![]()
这是一个思路,但是实际使用中还是不实用,因为一个网络拥有上百万个参数,按照上面的还需要都标记,开销很大,因此在基础上需要继续简化,如何简化呢?从不为零的参数出发进行限制,即使不等于0的个数限制在一定的范围内以此达到限制模型的目的,而这种方法就称为L0范数惩罚,如下:
![]()
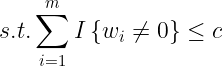
其中![]() 的英文不为零的个数状语从句:
的英文不为零的个数状语从句:
L1范数惩罚:
虽然我们简化了问题,但是上面的式子还是不太完美,对于实际问题的处理还是不友好,还需要继续简化,如何简化呢?这样简化,上面我们是使用参数不为零的个数做约束条件,这里改变的是要求参数数值的总和限制在某个范围内即参数的总和要小于某个值,这种对参数总和的限制就被称为L1范数惩罚,被也。称为参数稀疏性惩罚如下式:
![]()

虽然这样做会使得的高阶项的系数不为0了,但是如果下式的情况也是可以接受的,因为高阶项基本上可以被忽略了
![]()
L2范数惩罚:
上式虽然可以应用,同时把问题变为求极值的问题,但是还是不完美,因为约束条件带有绝对值,这在数学中不好处理,最简单的方法和损失函数一样就是加入平方项就避免正负抵消问题,这就是L2范数惩罚,也是我们非常熟悉的权重衰减惩罚,如下式:
![]()
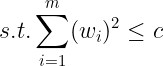
通过Ç值来控制学习算法的模型的能力,C越大模型能力越强,C越小模型能力越小。那么的上面的求解其实就可以按照SVM的求解进行即引入拉格朗日乘法(去除约束项),然后是转换成对偶问题,在通过SMO算法进行求解即可,这个需要大家对支持向量机有一个深入清晰的认识,下面我们在深入的探讨一下权重衰减正则化:
L2参数正则化:
下面的内容需要一些概念上的知识如等高线,不懂看的建议看我的这篇文章,那里详细介绍了什么是等高线,他的来龙去脉都讲的很详细,下面就不细说他是怎么来的,而是直接使用了。
代价函数的梯度如下图虚线等高线椭圆所示,而梯度的最小值为其中心点,如果没有任何限制,学习的过程就是每次沿着梯度等高线垂直的方向寻找极值。而图中的实线所示就是权重衰减项,虚线圆的半径便是权重衰减项中的常数C ^

这就如同一个带线的小球的一端被固定在原点,而我们拿着小球尽力的靠近椭圆的中心点。如果该小球的绳过长(C值过大),小球几乎就没被限制,轻易地就到达了最小值,但也造成了过度拟合现象。如果绳了过短,那我们距离训练数据的最优值处就很远,也就造成了欠拟合现象。我们假设一种状态,绳长适中,那该状态下的最优效果是什么呢?
有兴趣的读者可以自己动手画一画,做一下试验,但其实这并不难想象,最近的点就在椭圆中心与原点连线上。此时又是一个什么状态呢?非常巧,此时代价函数的负梯度与固定一端的带绳小球的法向量是平行的,我们用数学符号刻画,如下式所示:
![]()
需要说明的的英文带绳小球可以用向量![]() 表示,因此该圆的法向量就为向量
表示,因此该圆的法向量就为向量 ,其中常数2是我刻意添加的,只是为了构造函数方便,而
,其中常数2是我刻意添加的,只是为了构造函数方便,而![]() 为一个使得代价函数梯度与法向量平行的参数,而该参数便是大名鼎鼎的拉格朗日乘子,并且就如同绳长不能为负数,也需要大于0。现在问题似乎变得有些复杂了,以前我们只需求解代价函数的梯度,然后通过梯度下降法去慢慢接近梯度为零的区域,但现在引入新的参数又如何解决呢?
为一个使得代价函数梯度与法向量平行的参数,而该参数便是大名鼎鼎的拉格朗日乘子,并且就如同绳长不能为负数,也需要大于0。现在问题似乎变得有些复杂了,以前我们只需求解代价函数的梯度,然后通过梯度下降法去慢慢接近梯度为零的区域,但现在引入新的参数又如何解决呢?
在实际应用中,![]() 通常作为超参数,人为进行选择,其值需要通过具体的验证数据测试结果进行经验性选择。我们现在把
通常作为超参数,人为进行选择,其值需要通过具体的验证数据测试结果进行经验性选择。我们现在把![]() 当作一个常数处理,但是代价函数的梯度依然无法求解。我们不妨这样思考,最小化代价函数等价于代价函数的梯度为0。那代价函数梯度加上某个数为0,那也等价于原代价函数加上某个函数。那我们不妨将其积分,如下式 所示,这就是新的代价函数。
当作一个常数处理,但是代价函数的梯度依然无法求解。我们不妨这样思考,最小化代价函数等价于代价函数的梯度为0。那代价函数梯度加上某个数为0,那也等价于原代价函数加上某个函数。那我们不妨将其积分,如下式 所示,这就是新的代价函数。
![]()
如果使用最小均方误差函数作为代价函数,那么式子变为如下:
![]()
其中 控制关系着机器学习算法的能力,如果= 0,则退化成原模型。越大,则惩罚越严重,模型的能力越弱,越小,易发生过拟合,而过大以发生否拟合,计算梯度时,只需求偏导即可,如下:
控制关系着机器学习算法的能力,如果= 0,则退化成原模型。越大,则惩罚越严重,模型的能力越弱,越小,易发生过拟合,而过大以发生否拟合,计算梯度时,只需求偏导即可,如下:
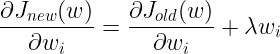
L1正则化
权重衰减是最常用的正则化措施,其优点在于可导并且容易优化。但正如开始时介绍范数惩罚方法时,我们一次一次放松限制推出了权重衰减,如果想要更加严格地限制,凵正则化便是一个不错的选择。如下式所示,便是加入L1惩罚的代价函数。
![]()
其中![]() 表示所有参数的绝对值求和,并不是求向量模长。如果不太习惯,我们也可以将上式写成下式所示的表达式。
表示所有参数的绝对值求和,并不是求向量模长。如果不太习惯,我们也可以将上式写成下式所示的表达式。
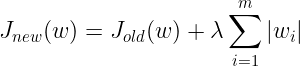
在计算参数梯度时,如下式所示,也非常简单,由于绝对值不可导,我们其实只是在原代价函数梯度的基础上再加上与参数本身的符号乘积。

其中符号(x)的表示取X的符号,比如符号(-5)= - 1,而登录(5)= 1需要注意的是,相比于权重衰减,L1正则化的限制更为严格,因此。也就更加的稀疏(稀疏),稀疏性也就是我们最终优化到的参数中有许多0稀疏性的一大好处是有利于特征(FeatureSelection,由于大多数参数都为0,而这些0参数对应的特征就没有被使用,实际上我们就选择出了一些重要特征对数据进行预测,并自动筛选掉一些无用的特征,这些无用特征很大程度上也有可能是噪声特征。
好,上面就是正则化方面的内容,下面我们看看参数绑定和参数共享。
绑定参数与参数共享
目前为止,我们讨论的正则化措施都是通过限制模型参数的方法来限制模型的能力,但这种通用的限制太过宽泛,这里再次提起“没免费午餐理论“,机器学习算法没有好坏之分,所谓的好坏只是针对的数据集与问题域而言,迁移到正则化措施中,如果我们在特定领域对参数进行特定的限制,可能效果会更好。因此,我们经常需要添加一些先验知识去限制模型参数。虽然我们并不能精确地知道参数需要什么值,但对于特定的领域与特定的模型结构,模型参数之间存在着某些依赖。
假设某个同学数学非常有大赋,那他学习物理,化学和计算机等内容也会变得非常轻松。
某个同学文学功底扎实,出口成章,那她在英语及艺术方面也可能高人一筹。在机器学习中,某个模型可以完美地识别“猫”,那通过训练,它也可以非常好地识别 “狗”。更具体些,识别“猫”使用的参数和识别“狗”使用的参数会比较接近。因此我们在训练其识别“狗”时,就可以利用识别“猫”的参数进行训练,多重任务学习
在图像识别领域,图像应该具有平移,旋转等空间不变性特征;而对于时间序列数据,数据与数据之间应该具有时间不变性特征例如,一幅图中有一只小猫,如果将该图中的每个像素都向右平移一个像素点,这只小猫依然在图中,对于人而言,平移一个像素点根本分辨不出区别,但对于机器学习算法而言,所有的像素特征对应的参数都发生了偏移,而机器学习算法很可能就认为这是两幅图像。为了提取到这种不变性特征,我们迫使相邻数据特征参数相同,而这种正则化方法也称为参数共享(ParameterSharing)。
卷积神经网络(Convolutional Neural Network,CNN)是目前最流行的一种神经网络,广泛应用于计算机视觉领域。而该网络的核心一一卷积操作,其实就是参数共享。参数共享使得卷积网络极大地降低了参数的规模,并且在不增加训练数据量的前提下,增加了网络的尺寸。前面几节我们详细地介绍卷积网络的各项工作原理,这里不再叙述。
注入噪声与数据扩充
在机器学习中,想要降低泛化错误率最好的方法是训练更多的数据,但在现实中,数据总是有限的,并且还需要大量的成本。那么问题就来了,更多的数据使得模型性能更好,但我们又没有更多的数据,那该怎么办呢?其中一个有用而高效的方法就是生成伪造数据(fakedata),然后将这些数据添加到训练集中进行数据扩充(DataAugmentation)。虽然听上去似乎在教大家“造假”,但对于某些机器学习任务而言,创造新的伪造数据是非常合理的。
在分类任务中,分类器需要使用复杂高维的输入数据X以及数据所对应的类标进行关联学习。这也意味着,分类器面临的主要任务是从各种变化的数据中获得某种稳定分布的不变性。既然平移,旋转后的图像都是同一个对象,那么在训练数据中扭曲一定程度的输入数据X,分类器也应该将该数据 进关联,但这一方法的应用范围还比较窄。例如在密度估计任务中,要生成新的伪造数据是非常困难的,因为生成新数据的前提是我们己经解决了密度估计问题。
生成伪造数据最佳的应用场景是一类特定的分类任务。 - 对象识别图片是一种高维复杂的数据“并且有着平移,旋转不变性等特点在上面,介绍了如果一幅图片全部向右平移一个像素,那对于机器学习算法来说,便彻底成了一幅新冬像,因此我们需要先验地加入参数共享等措施来学习网络。那我们不妨换个角度,我们将这些先验知识加入到数据中去,即平移,旋转,拉伸之后的图像数据依然是原数据对象。我们将这些生成的“新图像数据”加入训练集中训练,那训练数据就可能增加十余倍的数据量,这样训练出来的模型同样也可以其备这种空间不变性能力,但我们必须谨慎地去变换这些 。例如在字符识别中,将b,和d,水平翻转,旋转180°,那就都成了同一个数据。此时的伪造数据,就真的变成了错误数据。
比较机器学习基准结果时,需要注意数据扩充的影响。有时手工设计的数据扩充方法能够显着地降低泛化错误率,因此比较两种算法的性能时,执行控制试验就是非常有必要的。比较算法阿与算法乙时,我们需要确保这两种算法使用相同的手工设计数据扩充,假设算法甲在没有数据扩充时表现糟糕,而算法乙在加入人工合成数据后性能优越,这其实说明不了什么。在这样的例子中很有可能是合成数据造成了性能的提高,而不是算法乙本身拥有更好的性能。但是否在试验中注入噪声或扩充数据是一种非常主观的判断,例如,在机器学习算法的输入中注入高斯噪声被认为是机器学习算法的一部分,然而图片对随机进行剪裁却被认
为的英文单独地预处理步骤。
在输入中注入噪声
数据扩充也可以看作是在输入数据中注入噪声,从而迫使算法拥有更强的健壮性(也可以将注入噪声看作是一种数据扩充)。神经网络容易过拟合的原因之一就是对于噪声没有太好的抗噪能力。正所谓“你怕什么,就应该勇敢地去面对什么。”最简单的提高网络抗噪声能力方法,就是在训练时加入随机噪声一起训练。比如在非监督学习算法降噪自动编码器(DenoisingAutoencoder)中,在输入层进行噪声注入然后学习无噪声的冬片,便是一种很好的提高网络健壮性的方式。
隐藏在注入层噪声
对于某些模型,注入噪声也相当于对参数进行范数惩罚。通常而言,注入噪声要比简单地收缩参数更有效,尤其是将噪声注入到隐藏层中。而隐藏层注入噪声是一个重要的主题,我们将在差算法中重点介绍,该方法也可以看作是通过加入噪声重构新输入的一种正则化策略。
除了在数据以及隐藏层输入中注入噪声,在权重(参数)中注入噪声也是一种有效的正则化措施。这种方法在某种程度上可以等价地解释为传统的范数惩罚,该方法鼓励参数找到一个参数空间,而该空间对于微小的参数变化所引起的输出变化的影响很小。换而言之,就是将模型送进了一个对于微小变化不敏感的区域,我们不仅找到了最小值,我们还找到了一个宽扁的最小值区域。
类在标中注入噪声
数据集中或多或少都带有错误的类标,如果我们使用这些数据进行训练,那这就好比一个专心听讲且对老师十分尊敬的好学生,认真学习老师教给他的所有知识,但老师教给他的却是错误的知识。最不幸的是,学生还对老师深信不疑,即使发现了错误,也只会认为是自己愚钝,不断地否定自己,不断地在痛苦中挣扎。虽然我们竭尽全力地避免错误标记数据,但这并不如我们想象得那么美好,人为地添加错误在所难免。与其小心翼翼地标记数据做个完美的“老师”,还不如直接就告诉学生“老师”并不完美,“老师”也会犯错。而解决这种问题的具体措施就是在类标中加入一定的噪声,例如可以设置一个很小的常数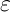 ,我们将训练数据的类标Y正确的概率设置为
,我们将训练数据的类标Y正确的概率设置为![]() 。
。
稀疏表征
在上面参数范数惩罚中,我们通过直接限制可用参数规模,如L1,L2参数惩罚,来限制模型的能力,从而降低过拟合风险。接下来,我们介绍一种通过作用在神经网络激活单元的惩罚策略,来提高隐藏层的稀疏性,该方法可算作是一种间接的模型参数惩罚。
生物进化的一个重要趋势就是尽可能地节约能源,而我们的大脑也符合节能的原则大脑。中每个神经元都连接着成千上万的神经元,但其实大部分神经元都是处于抑制状态,只有少部分的神经元接受刺激会处于激活状态,因此我们需要将特定的信息交给特定的神经元进行处理。受此启发,我们就期望使用某种惩罚措施来抑制大部分神经元。当信息输入进神经网络时,只有关键部分神经元才能够处于激活状态,这就是稀疏表征(稀疏表示)
我们已经讨论过凵范数如何致使参数稀疏化,这就意着大多 数都为零或接近于零,而表征稀疏化描述的其实就是隐藏层的输出大多数为零或接近零。为了简明地阐述这些区别我们以一个线性回归为例,如下图所示,是一个参数稀疏化的线性回归模型:一个是使用稀疏表征的线性回归。
虽然表征正则化与参数正则化(一个使得输出稀疏,一个使得参数稀疏)有些区别,但幸运的是它们都使用相同的机理来实现。如下式所示,表征范数惩罚也是通过在代价函数中一项添加惩罚表征项![]() 来实现表征稀疏化。
来实现表征稀疏化。
![]()
其中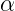 控制关系着惩罚项的惩罚力度,如果= 0,则相当于没有任何惩罚,越大,惩罚力度越大。就如同在参数中使用的L1惩罚,通过限制参数的总数值来诱使参数稀疏化一样。在表征惩罚中我们也使用和L1惩罚相同的方式:
控制关系着惩罚项的惩罚力度,如果= 0,则相当于没有任何惩罚,越大,惩罚力度越大。就如同在参数中使用的L1惩罚,通过限制参数的总数值来诱使参数稀疏化一样。在表征惩罚中我们也使用和L1惩罚相同的方式:![]() 。来诱使表征稀化表然的方法,其中KL散度(KLdivergence),又称相对熵(RelativeEntropy)也是一种十分常用的方法,这个我会在强化学习或者自然语言处理进行介绍,这里就不再介绍。
。来诱使表征稀化表然的方法,其中KL散度(KLdivergence),又称相对熵(RelativeEntropy)也是一种十分常用的方法,这个我会在强化学习或者自然语言处理进行介绍,这里就不再介绍。
早停
目前为止,我们针对过拟合现象所做的正则化措施总结起来有两点:一是限制模型的能力,就如同“孤已天下无敌(训练错误率很低),让你双手又如何(参数,表征惩罚)”。二是不断地加入噪声,给自己增加麻烦,就如同'放一碗水在头顶扎马步,穿着加沙的背心去奔跑,最终目的是使自己更强壮'。而下面,我们介绍的这种正则化方法就非常简单了,那就是“当个懒汉早些停下来“。这似乎和我们的哲学意境不太相符,在我们的思想中,我们接受的传统熏陶总是这样:?。?。“弟子勤奋看书,师傅问弟子懂否弟子挠头羞愧道不知师傅轻捻长须道,再看几日之后,再问弟子懂否弟子颤惊道,徒儿依旧愚昧师傅小叹,再看,,,。我们的哲学意境总是让我们在重复中自我醒悟,发觉渺茫的慧根。但我们介绍的深度学习正则化策略却恰恰相反,我们将 如何适可而止,我们不允许算法重复地学习太多次。
基于梯度下降的深度学习算法都存在一个训练周期的问题,训练的次数越多,训练错误率就越低。由于我们真正目的是降低测试错误率,因此我们期望验证错误率也与训练错误率有相似的曲线。但期望总是事与愿违,真实环境中的验证错误率并没有随着训练次数的增多而减少,而是形成了一种“U型“曲线,验证错误率先减小后上升。那很自然地,我们就期望能在验证错误率的最低点(或最低点附近)停止训练算法,这就是所谓的早停(EarlyStopping),这里就不细讲了,感兴趣的自行查阅资料。
Dropout在我的这篇文章详细讲了。
到这里优化系列就展示结束,因为还有很多我还不知道的优化策略,等以后遇到在持续更新优化系列,本次先到这里,这些优化策略,不能只看和只知道,需要我们实践去感受内涵,因为有些东西只有自己去做了才能感受的深,好,深度学习优化到此结束,下面就进入RNN学习,然后开始自然语言系列的更新。