Text to image论文精读 MirrorGAN: Learning Text-to-image Generation by Redescription(通过重新描述学习从文本到图像的生成)
MirrorGAN: Learning Text-to-image Generation by Redescription
- 一、原文摘要
- 二、为什么提出MirrorGAN
- 三、MirrorGAN整体框架
-
- 3.1、STEM: 语义嵌入模块
- 3.2、GLAM:级联图像生成器中的全局-局部协作注意力模块
- 3.3、STREAM:语义文本重建与对齐模块
- 四、损失函数
- 五、实验
-
- 5.1、数据集
- 5.2、评价标准
- 5.3、实验结果
- 5.4、定量分析
- 5.5、定性分析
- 5.6、消融研究
- 总结
MirrorGAN通过学习文本-图像-文本,试图从生成的图像中重新生成文本描述,从而加强保证文本描述和视觉内容的一致性。文章被2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)会议录用。
论文地址:https://arxiv.org/abs/1903.05854
代码地址:https://github.com/qiaott/MirrorGAN

其基本原理是如果T2I生成的图像在语义上与给定的文本描述一致,那么I2T对其的重新描述应该与给定的文本描述具有完全相同的语义。
本博客是精读这篇论文的报告,包含一些个人理解、知识拓展和总结。
一、原文摘要
从给定的文本描述生成图像有两个目标:视觉真实性和语义一致性。尽管在使用生成性对抗网络生成高质量、视觉逼真的图像方面取得了重大进展,但保证文本描述和视觉内容之间的语义一致性仍然非常具有挑战性。在本文中,我们提出了一种新的全局-局部关注和语义保持的文本-图像-文本框架MirrorGAN来解决这个问题。MirrorGAN利用了通过重新描述学习文本到图像生成的思想,由三个模块组成:语义文本嵌入模块(STEM)、用于级联图像生成的全局-局部协作关注模块(GLAM)和语义文本再生和对齐模块(STREAM)。STEM生成单词和句子级别的嵌入。GLAM有一个级联架构,用于从粗到细生成目标图像,利用局部单词注意和全局句子注意,逐步增强生成图像的多样性和语义一致性。STREAM试图从生成的图像中重新生成文本描述,该图像在语义上与给定的文本描述一致。在两个公共基准数据集上进行的深入实验表明,MirrorGAN方法优于其他具有代表性的最新方法。
二、为什么提出MirrorGAN
尽管使用生成性对抗网络(GAN)生成视觉逼真的图像方面取得了重大进展,但由于文本和图像之间的领域差异,仅仅依赖鉴别器,很难且低效地对语义一致性进行建模,加入注意力机制虽有所改善,但是单词级注意并不能确保全局语义一致性,最终难以保证 生成的图像 与 输入文本的语义对齐。
三、MirrorGAN整体框架
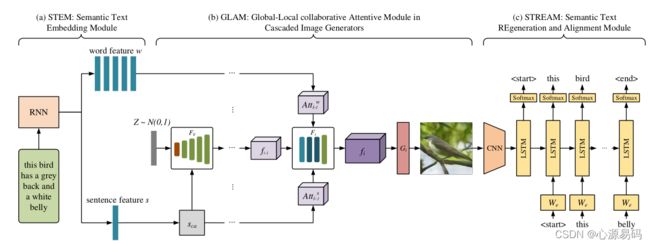
MirrorGAN通过集成T2I和I2T实现了镜像结构。它利用了通过重新描述来学习T2I生成的思想。生成图像后,MirrorGAN会重新生成其描述,从而使其底层语义与给定的文本描述保持一致。从技术上讲,MirrorGAN由三个模块组成:STEM、GLAM和STREAM。下面将介绍该模型的详细信息。
3.1、STEM: 语义嵌入模块
在STEM模块中,使用递归神经网络(RNN)从给定的文本描述T中提取语义嵌入,包括单词嵌入w和句子嵌入s :
w , s = R N N ( T ) w, s=RNN(T) w,s=RNN(T)
其中,文本描述 T = { T l ∣ l = 0 , … , L − 1 } T=\left\{T_{l} \mid l=0, \ldots, L-1\right\} T={Tl∣l=0,…,L−1},L表示句子的长度,句子嵌入 w = { w l ∣ l = 0 , … , L − 1 } ∈ R D × L w=\left\{w^{l} \mid l=0, \ldots, L-1\right\} \in \mathbb{R}^{D \times L} w={wl∣l=0,…,L−1}∈RD×L
3.2、GLAM:级联图像生成器中的全局-局部协作注意力模块

这一部分同样采用了多个图像生成网络构建多级级联生成器,其基本结构与AttnGAN中的级联结构相似。
首先是单词层面的注意力机制:通过感知网络层将单词嵌入转化到可视特征的语义空间中,再乘以可视特征以获得注意力分数,然后通过前两步结果的内积得到融合注意力的单词特征(attentive
word-context feature)。
其次是句子层面的注意力机制,步骤与单词层面差不多,也是将句子嵌入通过感知网络层转化到可视特征的语义空间,然后与可视特征进行点乘获得注意力得分,最后通过两个结果点乘内积获得最终特征。
该部分在attnGAN 的基础上再次引进global attention,与之前的attnGAN中的local attention相结合,不仅关注局部的细节和语义的生成,更关注全局的细节和语义的生成。
在公式推理上,使用{F0,F1,…,Fm−1} 表示m个视觉特征变换器,{G0,G1,…,Gm−1} 表示m个图像生成器(一般为三层)。
f 0 = F 0 ( z , s c a ) f i = F i ( f i − 1 , F a t t i ( f i − 1 , w , s c a ) ) , i ∈ { 1 , 2 , … , m − 1 } I i = G i ( f i ) , i ∈ { 0 , 1 , 2 , … , m − 1 } \begin{array}{l} f_{0}=F_{0}\left(z, s_{c a}\right) \\ f_{i}=F_{i}\left(f_{i-1}, F_{a t t_{i}}\left(f_{i-1}, w, s_{c a}\right)\right), i \in\{1,2, \ldots, m-1\} \\ I_{i}=G_{i}\left(f_{i}\right), i \in\{0,1,2, \ldots, m-1\} \end{array} f0=F0(z,sca)fi=Fi(fi−1,Fatti(fi−1,w,sca)),i∈{1,2,…,m−1}Ii=Gi(fi),i∈{0,1,2,…,m−1}其中 f i ∈ R M i × N i 而 I i ∈ R q i × q i f_{i} \in \mathbb{R}^{M_{i} \times N_{i}} \text { 而 } I_{i} \in \mathbb{R}^{q_{i} \times q_{i}} fi∈RMi×Ni 而 Ii∈Rqi×qi
A t t i − 1 w = ∑ l = 0 L − 1 ( U i − 1 w l ) ( softmax ( f i − 1 T ( U i − 1 w l ) ) ) T A t t_{i-1}^{w}=\sum_{l=0}^{L-1}\left(U_{i-1} w^{l}\right)\left(\text { softmax }\left(f_{i-1}^{T}\left(U_{i-1} w^{l}\right)\right)\right)^{T} Atti−1w=∑l=0L−1(Ui−1wl)( softmax (fi−1T(Ui−1wl)))T
其中 U i − 1 ∈ R M i − 1 × D 而 A t t i − 1 w ∈ R M i − 1 × N i − 1 U_{i-1} \in \mathbb{R}^{M_{i-1} \times D} \text { 而 } A t t_{i-1}^{w} \in \mathbb{R}^{M_{i-1} \times N_{i-1}} Ui−1∈RMi−1×D 而 Atti−1w∈RMi−1×Ni−1
A t t i − 1 s = ( V i − 1 s c a ) ∘ ( softmax ( f i − 1 ∘ ( V i − 1 s c a ) ) ) A t t_{i-1}^{s}=\left(V_{i-1} s_{c a}\right) \circ\left(\operatorname{softmax}\left(f_{i-1} \circ\left(V_{i-1} s_{c a}\right)\right)\right) Atti−1s=(Vi−1sca)∘(softmax(fi−1∘(Vi−1sca)))
其中 A t t i − 1 s ∈ R M i − 1 × N i − 1 A t t_{i-1}^{s} \in \mathbb{R}^{M_{i-1} \times N_{i-1}} Atti−1s∈RMi−1×Ni−1, V i ∈ R M i × D ′ V_i ∈\mathbb{R}^{M_{i} \times D^{\prime}} Vi∈RMi×D′
3.3、STREAM:语义文本重建与对齐模块

语义文本重建和对齐模块用于从生成的图像中重新生成文本描述,使文本描述尽量在语义上与给定的文本描述对齐。首先将生成的图像输入到图像编码器,然后经过循环神经网络进行解码生成文本。
图像编码器是在ImageNet上预训练的卷积神经网络(CNN),解码器是RNN。
x − 1 = C N N ( I m − 1 ) x t = W e T t , t ∈ { 0 , … L − 1 } p t + 1 = R N N ( x t ) , t ∈ { 0 , … L − 1 } \begin{array}{l} x_{-1}=C N N\left(I_{m-1}\right) \\ x_{t}=W_{e} T_{t}, t \in\{0, \ldots L-1\} \\ p_{t+1}=R N N\left(x_{t}\right), t \in\{0, \ldots L-1\} \end{array} x−1=CNN(Im−1)xt=WeTt,t∈{0,…L−1}pt+1=RNN(xt),t∈{0,…L−1}
其中 x − 1 ∈ R M m − 1 x_{-1} \in \mathbb{R}^{M_{m-1}} x−1∈RMm−1表示编码后的图像形成的视觉特征, W e ∈ R M m − 1 × D W_{e} \in \mathbb{R}^{M_{m-1} \times D} We∈RMm−1×D表示单词嵌入矩阵,它将单词特征映射到视觉特征空间, p t + 1 p_{t+1} pt+1是单词的预测概率分布 ,
四、损失函数
损失函数的第一部分是生成对抗网络的损失
与StackGAN++和AttnGAN中的损失函数类似,MirrorGAN同样采用多级生成器和判别器交替训练,同样采用无条件损失(视觉真实性)+有条件损失(文本-图像配对语义一致性):
L G i = − 1 2 E I i ∼ p I i [ log ( D i ( I i ) ) ] − 1 2 E I i ∼ p I i [ log ( D i ( I i , s ) ) ] , \begin{array}{c} \mathcal{L}_{G_{i}}=-\frac{1}{2} E_{I_{i} \sim p_{I_{i}}}\left[\log \left(D_{i}\left(I_{i}\right)\right)\right] \\ \quad-\frac{1}{2} \mathbb{E}_{I_{i} \sim p_{I_{i}}}\left[\log \left(D_{i}\left(I_{i}, s\right)\right)\right], \end{array} LGi=−21EIi∼pIi[log(Di(Ii))]−21EIi∼pIi[log(Di(Ii,s))],
其中, I i I_i Ii是第i层从 p I i p_{Ii} pIi分布中采样生成的图像,其中第一部分为无条件损失,用于区分图像在视觉上是真实的还是虚假的,第二部分为有条件损失,用于确定图像是否符合语义。
与生成器类似,判别器的损失同样采用无条件损失(视觉真实性)+有条件损失(文本-图像配对语义一致性):
L D i = − 1 2 E I i G T ∼ p I i G T [ log ( D i ( I i G T ) ) ] − 1 2 E I i ∼ p I i [ log ( 1 − D i ( I i ) ) ] − 1 2 E I i G T ∼ p I i G T [ log ( D i ( I i G T , s ) ) ] − 1 2 E I i ∼ p I i [ log ( 1 − D i ( I i , s ) ) ] \begin{array}{c} \mathcal{L}_{D_{i}}=-\frac{1}{2} \mathbb{E}_{I_{i}^{G T} \sim p_{I_{i} G T}}\left[\log \left(D_{i}\left(I_{i}^{G T}\right)\right)\right] \\ -\frac{1}{2} \mathbb{E}_{I_{i} \sim p_{I_{i}}}\left[\log \left(1-D_{i}\left(I_{i}\right)\right)\right] \\ -\frac{1}{2} \mathbb{E}_{I_{i}^{G T} \sim p_{I_{i} G T}}\left[\log \left(D_{i}\left(I_{i}^{G T}, s\right)\right)\right] \\ -\frac{1}{2} \mathbb{E}_{I_{i} \sim p_{I_{i}}}\left[\log \left(1-D_{i}\left(I_{i}, s\right)\right)\right] \end{array} LDi=−21EIiGT∼pIiGT[log(Di(IiGT))]−21EIi∼pIi[log(1−Di(Ii))]−21EIiGT∼pIiGT[log(Di(IiGT,s))]−21EIi∼pIi[log(1−Di(Ii,s))]
其中 I i G T I_{i}^{G T} IiGT是从第i层真实图像分布 p I i G T p_{I_{i}^{G T}} pIiGT的采样
损失函数的第二部分是基于CE的文本语义重建损失,其使重建的文本描述与给定的文本描述尽量一致:
L stream = − ∑ t = 0 L − 1 log p t ( T t ) \mathcal{L}_{\text {stream }}=-\sum_{t=0}^{L-1} \log p_{t}\left(T_{t}\right) Lstream =−∑t=0L−1logpt(Tt)
将其两项相加,通过λ调节权重,最终得出的损失函数为:
L G = ∑ i = 0 m − 1 L G i + λ L stream \mathcal{L}_{G}=\sum_{i=0}^{m-1} \mathcal{L}_{G_{i}}+\lambda \mathcal{L}_{\text {stream }} LG=∑i=0m−1LGi+λLstream
五、实验
5.1、数据集
CUB bird:包含8855个训练图像和2933个测试图像,属于200个类别,每个鸟类图像有10个文本描述 。
MS COCO:包含82783个训练图像和40504个测试图像,每个图像有5个文本描述。
5.2、评价标准
Inception Score:IS分数衡量生成图像的客观性和多样性
R-precision:评估生成的图像及其相应文本描述之间的视觉语义相似性。
5.3、实验结果
5.4、定量分析
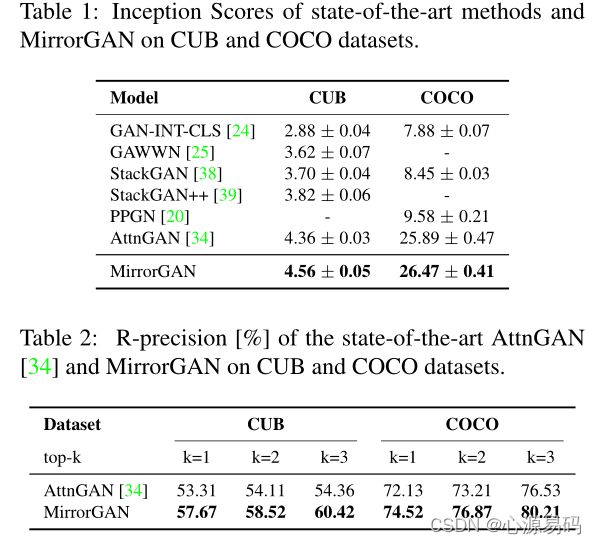
MirrorGAN在CUB和COCO数据集上都获得了最高的IS得分,且和AttnGAN相比,获得了更高的R-precision分数。
5.5、定性分析
主观视觉比较和人类知觉测试,作者将各个GAN生成的图像对比进行了分析,然后收集了若干志愿者的视觉调查,暂略,有兴趣可以看原文。
5.6、消融研究
1、MirrorGAN元件的消融实验
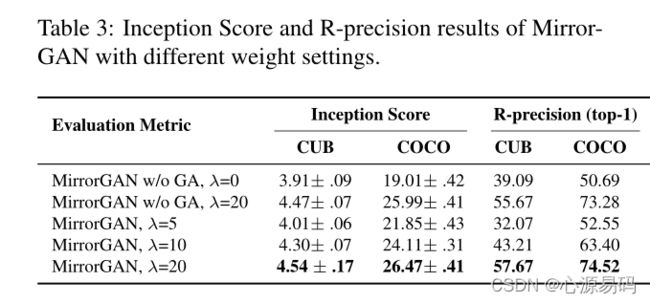
结果表明,GLAM中的全局和局部注意力能够协同帮助生成器生成视觉上真实的、语义上一致的图像,并告诉生成器应该关注哪里。
2、级联结构的视觉研究
为了更好地理解MirrorGAN的级联生成过程,作者可视化了中间图像和每个阶段的注意图,如下图所示
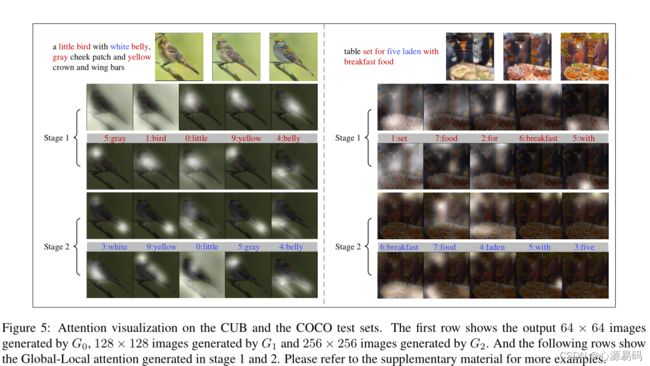
可以看出,在第一阶段,低分辨率图像生成原始的形状和颜色,缺乏细节。在GLAM在阶段的指导下,MirrorGAN通过聚焦最相关和最重要的区域生成图像,逐渐提高生成的图像的质量。
1)在早期阶段,全局注意力更多地集中在全局语境上,然后在后期阶段集中在特定区域周围的语境上;
2)局部注意力通过引导生成者关注最相关的单词,帮助生成具有细粒度细节的图像,
3)全局关注与局部关注是互补的,它们共同促进网络的进步。
另外,MirrorGAN还能够捕捉到文本描述之间微小的差异(如颜色),生成对应图像:

总结
这篇文章的贡献总结如下
1、提出了一个新的文本生成图像框架 MirrorGAN,用于将T2I和I2T一起建模,通过体现通过重新描述学习T2I生成的思想,专门针对T2I生成。
2、 提出了一个全局-局部协作注意模型,该模型无缝嵌入到级联生成器中,以保持跨域语义一致性并平滑生成过程。
3、除了常用的生成器的损失外,还提出了一种基于交叉熵(CE)的文本语义重建损失,以监督生成器生成视觉上真实且语义一致的图像。
扩展:2016~2021 文字生成图像 Text to image(T2I)论文整理 阅读路线和阅读指南
下一篇:Text to image论文精读 DM-GAN: