Text to image论文精读DF-GAN:A Simple and Effective Baseline for Text-to-Image Synthesis一种简单有效的文本生成图像基准模型
目录
- 一、原文摘要
- 二、为什么提出DF-GAN?
- 三、DF-GAN
- 3.1、模型结构
- 3.2、鉴别器(Target-Aware Discriminator)
- 3.2.1、匹配感知梯度惩罚 (Matching-Aware Gradient Penalty)
- 3.2.2、单向输出 (One-Way Output)
- 3.3、生成器
- 3.3.1、Affine仿射块
- 3.3.2、DFBlock结构
- 四、实验
- 4.1、实验设置
- 4.2、实验结果
- 4.3、消融实验
- 五、创新与不足
- 最后
DF-GAN是南京邮电大学、苏黎世联邦理工学院、武汉大学等学者共同研究开发的一款简单且有效的文本生成图像模型。该论文已被CVPR 2022 Oral录用,文章最初发表于2020年8月,最后v3版本修订于22年3月 。
论文地址:https://arxiv.org/abs/2008.05865
代码地址:https://github.com/tobran/DF-GAN
本博客是精读这篇论文的报告,包含一些个人理解、知识拓展和总结。
一、原文摘要
从文本描述中合成高质量的真实图像是一项具有挑战性的任务。现有的文本到图像生成对抗性网络通常采用堆叠式架构作为主干,但仍然存在三个缺陷。首先,堆叠结构引入了不同图像尺度的生成器之间的纠缠。第二,现有研究倾向于在训练中修复额外的网络,以实现文本-图像语义一致性,但是这限制了这些网络的监控能力。第三,以往研究中广泛采用的基于跨模态注意的文本图像融合由于计算量大而局限于几种特殊的图像尺度。为此,我们提出了一种更简单但更有效的深度融合生成性对抗网络(DF-GAN)。具体来说,我们提出:(i)一种新的单级文本到图像主干,它直接合成高分辨率图像,而不同生成器之间没有纠缠;(ii)一种由匹配软件梯度惩罚和单向输出组成的新的目标感知鉴别器,它在不引入额外网络的情况下增强了文本图像的语义一致性,(iii)一种新的深文本图像融合块,它深化了融合过程,使文本和视觉特征完全融合。与目前最先进的方法相比,我们提出的DFGAN在合成真实感和文本匹配图像方面更简单但效率更高,并且在广泛使用的数据集上实现了更好的性能
二、为什么提出DF-GAN?
文本到图像合成的两个主要挑战是生成图像的真实性,以及给定文本和生成图像之间的语义一致性。
为了解决GAN模型的不稳定性,以往的模型都采用堆叠结构(一般三层)作为主干,然后使用DAMSM(AttnGAN)、循环结构(MirrorGAN)、孪生结构(SD-GAN)这些额外的网络保持文本图像的语义一致性。
但是仍存在三个问题:
- 堆叠结构引发了不同生成器之间的纠缠,使得最终优化的图像看起来像是模糊形状和一些细节的简单组合。
- 现有研究通常在训练期间不断调整额外的网络,使其更被生成器愚弄,从而合成对抗性特征,但是这会削弱它们对语义一致性的监督能力。(换句话说就是,现有研究通常会牺牲额外网络的文本对齐部分性能去达到图像合成效果)
- 由于计算量大,跨模态注意力(比如AttnGAN的注意力机制)往往只能在64×64或者128×128的尺度上应用,限制了文本与图像融合的有效性。
三、DF-GAN
3.1、模型结构
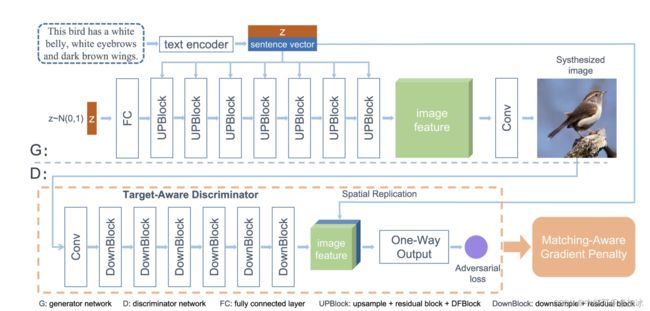
模型抛弃了以往的堆叠结构,只使用一个生成器、一个鉴别器、一个预训练过的文本编码器。
首先,从生成器开始看,生成器有两个输入:文本编码器(LSTM,用的是AttnGAN的那套)编码过后的sentence vector和从正态分布中采用的随机噪声。首先将噪声送入一个全连接层并重塑成需要的尺寸,然后经过一系列UPBlock块生成图像特征,UPBlock块包括:上采样层、残差块和DF-Block(DF-Block用于融合文本和图像特征),最后卷积层将图像特征转换为图像。
然后,分析鉴别器,鉴别器使用一系列DownBlock将图像转换为图像特征,然后把图像特征与sentence vector相连接,然后经过OneWay Output块计算对抗损失(包括视觉真实性和语义一致性)
在计算损失时,DF-GAN使用了 hinge loss:
L D = − E x ∼ P r [ min ( 0 , − 1 + D ( x , e ) ) ] − ( 1 / 2 ) E G ( z ) ∼ P g [ min ( 0 , − 1 − D ( G ( z ) , e ) ) ] − ( 1 / 2 ) E x ∼ P m i s [ min ( 0 , − 1 − D ( x , e ) ) ] L G = − E G ( z ) ∼ P g [ D ( G ( z ) , e ) ] \begin{aligned} L_{D}=&-\mathbb{E}_{x \sim \mathbb{P}_{r}}[\min (0,-1+D(x, e))] \\ &-(1 / 2) \mathbb{E}_{G(z) \sim \mathbb{P}_{g}}[\min (0,-1-D(G(z), e))] \\ &-(1 / 2) \mathbb{E}_{x \sim \mathbb{P}_{m i s}}[\min (0,-1-D(x, e))] \\ L_{G}=&-\mathbb{E}_{G(z) \sim \mathbb{P}_{g}}[D(G(z), e)] \end{aligned} LD=LG=−Ex∼Pr[min(0,−1+D(x,e))]−(1/2)EG(z)∼Pg[min(0,−1−D(G(z),e))]−(1/2)Ex∼Pmis[min(0,−1−D(x,e))]−EG(z)∼Pg[D(G(z),e)]
3.2、鉴别器(Target-Aware Discriminator)
作者设计的鉴别器叫Target-Aware Discriminator,由匹配感知梯度惩罚(MA-GP)和单向输出(One-Way Output)组成,主要作用就是促使生成器合成更真实更符合语义一致性的图像。
3.2.1、匹配感知梯度惩罚 (Matching-Aware Gradient Penalty)
匹配感知梯度惩罚是增强语义一致性的一种策略。

梯度惩罚(Gradient Penalty)是WGAN-gp曾提出的一种梯度变化方法,如上图所示,首先使用hinge loss将鉴别器损失范围限制在-1和1之间,梯度越大,惩罚越大,即改变梯度的程度越大。损失函数的计算公式如下:
L D = − E x ∼ P r [ min ( 0 , − 1 + D ( x , e ) ) ] − ( 1 / 2 ) E G ( z ) ∼ P g [ min ( 0 , − 1 − D ( G ( z ) , e ) ) ] − ( 1 / 2 ) E x ∼ P m i s [ min ( 0 , − 1 − D ( x , e ) ) ] + k E x ∼ P r [ ( ∥ ∇ x D ( x , e ) ∥ + ∥ ∇ e D ( x , e ) ∥ ) p ] L G = − E G ( z ) ∼ P g [ D ( G ( z ) , e ) ] \begin{aligned} L_{D}=&-\mathbb{E}_{x \sim \mathbb{P}_{r}}[\min (0,-1+D(x, e))] \\ &-(1 / 2) \mathbb{E}_{G(z) \sim \mathbb{P}_{g}}[\min (0,-1-D(G(z), e))] \\ &-(1 / 2) \mathbb{E}_{x \sim \mathbb{P}_{m i s}}[\min (0,-1-D(x, e))] \\ &+k \mathbb{E}_{x \sim \mathbb{P}_{r}}\left[\left(\left\|\nabla_{x} D(x, e)\right\|+\left\|\nabla_{e} D(x, e)\right\|\right)^{p}\right] \\ L_{G}=&-\mathbb{E}_{G(z) \sim \mathbb{P}_{g}}[D(G(z), e)] \end{aligned} LD=LG=−Ex∼Pr[min(0,−1+D(x,e))]−(1/2)EG(z)∼Pg[min(0,−1−D(G(z),e))]−(1/2)Ex∼Pmis[min(0,−1−D(x,e))]+kEx∼Pr[(∥∇xD(x,e)∥+∥∇eD(x,e)∥)p]−EG(z)∼Pg[D(G(z),e)]
其中:k和p是平衡梯度的两个参数,使用匹配感知梯度惩罚(MA-GP)主要是为鉴别器附加一个正则化,使其能够更好收敛到文本匹配的真实数据
3.2.2、单向输出 (One-Way Output)
在以往的T2I任务中,鉴别器以两种方式来进行判断,一是判断图像是真是假(无条件损失),二是将图像特征与句子向量连接起来,判断图像与文本是否语义一致(有条件损失)。这个被作者称Two-Way Output。
研究表明,这种Two-Way Output其实减慢了生成器的收敛速度。

如图所示,条件损失给出的梯度α指向图像与匹配文本的方向,无条件损失的梯度β仅指向真实图像的方向,最终的梯度方向只是简单的求和α+β,并不像预期那样指向(真实,匹配)的方向,这样的过程会减慢图像与文本的一致性。
故作者提出了单向输出(One-Way Output),其鉴别器将图像特征和句子向量连接起来,然后通过两个卷积层仅输出一个对抗性损失。这样设计可以使单个梯度γ直接指向目标数据点(真实和匹配),从而优化和加速生成器的收敛。

上图表明了Two-Way Output和One-Way Ouput的区别,Two-Way Output首先根据图像特征计算无条件损失,然后将图像特征连接文本特征再计算有条件损失,再将两个损失连接。而One-Way Output将图像特征与文本特征直接连接后经过两个卷积层直接计算总损失。
通过结合MA-GP和单向输出,目标感知鉴别器可以引导生成器合成更多真实和文本匹配的图像。
3.3、生成器

生成器由七个UPBlocks组成,UPBlocks包括上采样、残差块和DFBlock,DFBlock是作者提出的一种深度文本图像融合块,其在融合块中叠加了多个仿射变换和ReLU层。如下图所示:

a图为UPBlock,其由两个DFBlock组成,而DFBlock又由Affine仿射块和一些其他层组成。
3.3.1、Affine仿射块
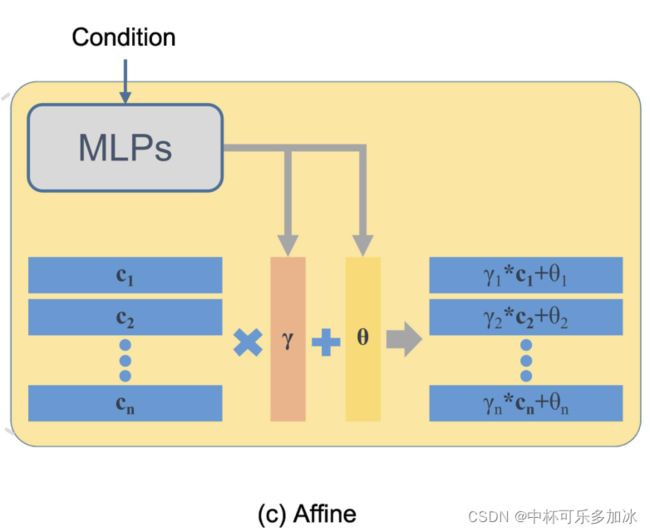
如图所示,Affine仿射块由两个MLP(多层感知器)组成,一个MLP预测语言条件下的通道尺度参数γ,另一个预测其移位参数θ,即:
γ = M L P 1 ( e ) , θ = M L P 2 ( e ) \gamma=M L P_{1}(\boldsymbol{e}), \quad \boldsymbol{\theta}=M L P_{2}(\boldsymbol{e}) γ=MLP1(e),θ=MLP2(e)
而Affine仿射块先使用参数γ对X进行通道方向的标度运算,然后使用移位参数θ进行通道方向的移位运算,即:
A F F ( x i ∣ e ) = γ i ⋅ x i + θ i A F F\left(\boldsymbol{x}_{\boldsymbol{i}} \mid \boldsymbol{e}\right)=\gamma_{i} \cdot \boldsymbol{x}_{\boldsymbol{i}}+\theta_{i} AFF(xi∣e)=γi⋅xi+θi
其中, x i x_i xi是视觉特征图的第i个通道信息,e是句子向量, γ i γ_i γi和 θ i θ_i θi是视觉特征图第i通道的缩放参数和移位参数。
3.3.2、DFBlock结构
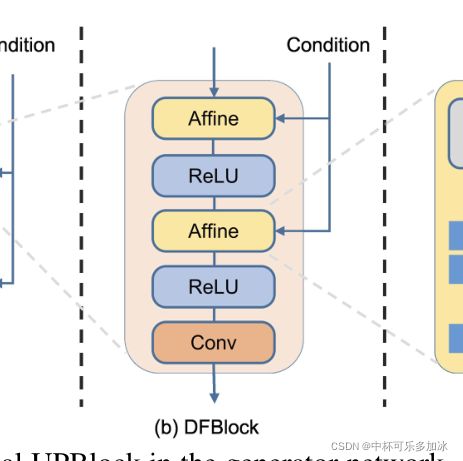
如图所示,DFBlock按顺序由:Affine仿射块=>ReLU=>Affine仿射块=>ReLU=>卷积Conv构成。
该方法受到包含仿射变换的条件批量规范化(CBN)和自适应实例规范化(AdaIN)的启发。
其在两个仿射块之间添加一个ReLU层,将非线性引入融合过程,扩大了条件表示空间,而更大的表示空间有助于生成器根据文本描述将不同的图像映射到不同的表示。即促进了视觉特征的多样性,扩大了表现空间 。
DFBlock为文本到图像的生成带来了三个好处:
- 它使生成器在融合文本和图像特征时能够更充分地利用文本信息;
- 加深融合过程,从而扩大了融合模块的表示空间,有利于从不同的文本描述中生成语义一致的图像;
- 融合文本与图像时不需要再考虑图像尺度的局限性。
四、实验
4.1、实验设置
数据集:CUB birds、COCO
优化器:Adam(β1=0.0,β2=0.9)
学习率:根据双时间刻度更新规则(TTUR)生成器设置为0.0001,鉴别器设置为0.0004
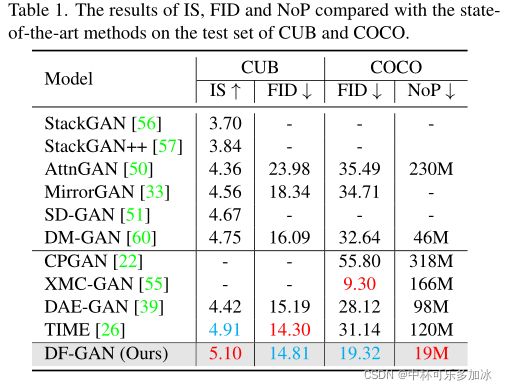
评价指标:在CUB上使用IS、FID,在COCO上使用FID、NoP
4.2、实验结果
4.3、消融实验
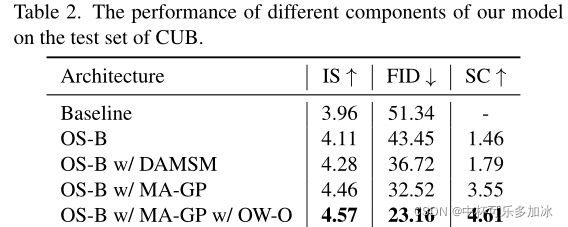
Baseline:采用堆叠框架和双向输出,与StackGAN具有相同的对抗性损失
在经过消融实验后发现,不采用堆叠框架,指标有明显提升,匹配感知梯度惩罚、One-Way Output、DFBlock都使模型有显著优化。详情可见论文原文。
五、创新与不足
创新:
- 提出了一种新的单级文本到图像主干,可以直接合成高分辨率图像,而不需要不同生成器之间的纠缠。
- 提出了一种由匹配感知梯度惩罚(MA-GP)和单向输出组成的目标感知鉴别器。它在不引入额外网络的情况下显著增强了文本图像的语义一致性。
- 提出了一种新的深度文本图像融合块(DFBlock),它能更有效、更深入地融合文本和视觉特征。
不足:
- 模型抛弃了AttnGAN以来提出的单词级信息,只引入了句子级的文本信息,这限制了细粒度视觉特征合成的能力
- 模型使用的text encoder仍然是AttnGAN中的encoder。若引入预先训练过的大型语言模型来提供额外的知识可能会进一步提高性能。
最后
个人简介:人工智能领域研究生,目前主攻文本生成图像(text to image)方向
个人主页:中杯可乐多加冰
限时免费订阅:文本生成图像T2I专栏
支持我:点赞+收藏⭐️+留言