基于深度学习的时间序列预测方法
之前对时间序列预测的方法大致梳理了一下,最近系统的学习了深度学习,同时也阅读了一些处理序列数据的文献,发现对于基于深度学习的时间序列预测的方法,还可以做进一步细分:RNN、Attention和TCN。
文章目录
- 1 简介
- 2 循环神经网络
-
- 2.1 RNN
- 2.2 LSTM
- 2.3 GRU
- 3 注意力机制
-
- 3.1 Transformer
- 3.2 Informer
- 3.3 Yformer
- 4 时间卷积网络
-
- 4.1 TCN
-
- 4.1.1 因果卷积
- 4.1.2 空洞卷积
- 4.1.3 残差链接
- 4.2 SCINet
- 5 总结
- 参考文献
1 简介
传统的时间序列预测方法如ARIMA模型和Holt-Winters季节性方法具有理论上的保证,但它们主要适用于单变量预测问题,并且要求时间序列是平稳的,这大大限制了它们在现实世界复杂时间序列数据中的应用。
在文献中,用于时间序列建模的深度神经网络主要有三种,它们都应用于时间序列预测:① 基于循环神经网络RNN,如长短期记忆LSTM和门控递归单元GRU;② 基于注意力机制Attention,如Transformer和Informer;③ 基于时间卷积网络TCN,如WaveNet和SCINet。总的来说,在这些模型中,TCN对时间序列数据的建模更为有效和高效。此外,它还可以与图神经网络GNN相结合来解决各种时空的序列预测问题。
2 循环神经网络
2.1 RNN
MLP是一个静态网络,信息的传递是单向的,网络的输出只依赖于当前的输入,不具备记忆能力。而RNN通过引入状态变量存储过去的信息和当前的输入,使得网络的输出不仅和当前的输入有关,还和上一时刻的输出相关,于是在处理时序数据时,就具有短期记忆能力。
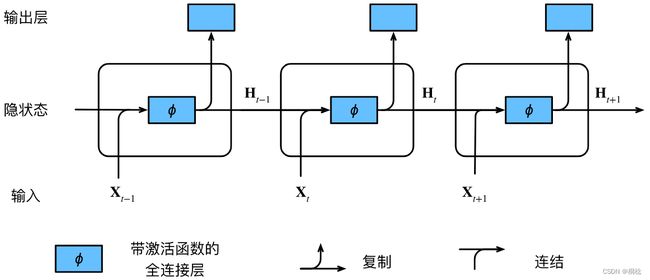
2.2 LSTM
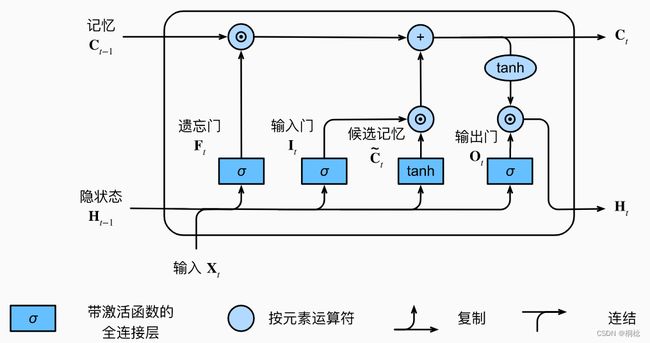
长期以来,RNN存在着长期信息保存和短期输入缺失的问题。 解决这一问题的最早方法之一是长短期记忆网络(long short-term memory,LSTM)。
长短期记忆网络的设计灵感来自于计算机的逻辑门。长短期记忆网络引入了记忆单元,或简称为单元。有些文献认为记忆单元是隐状态的一种特殊类型,它们与隐状态具有相同的形状,其设计目的是用于记录附加的信息。为了控制记忆元,需要许多门。其中一个门用来从单元中输出条目,将其称为输出门。另外一个门用来决定何时将数据读入单元,将其称为输入门。另外,还需要一种机制来重置单元的内容,由遗忘门来管理,这种设计能够通过专用机制决定什么时候记忆或忽略隐状态中的输入。
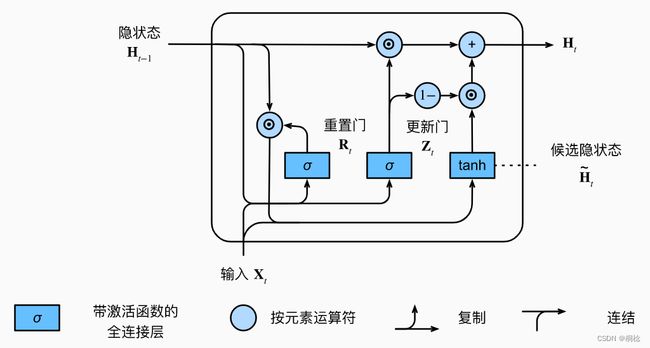
2.3 GRU
门控循环单元(gated recurrent unit,GRU)是一个比LSTM稍微简化的变体,通常能够提供同等的效果,并且计算的速度明显更快。LSTM有三个门 (遗忘门,输入门,输出门),而 GRU 只有两个门 (更新门,重置门)。另外,GRU没有LSTM中的记忆单元。
3 注意力机制
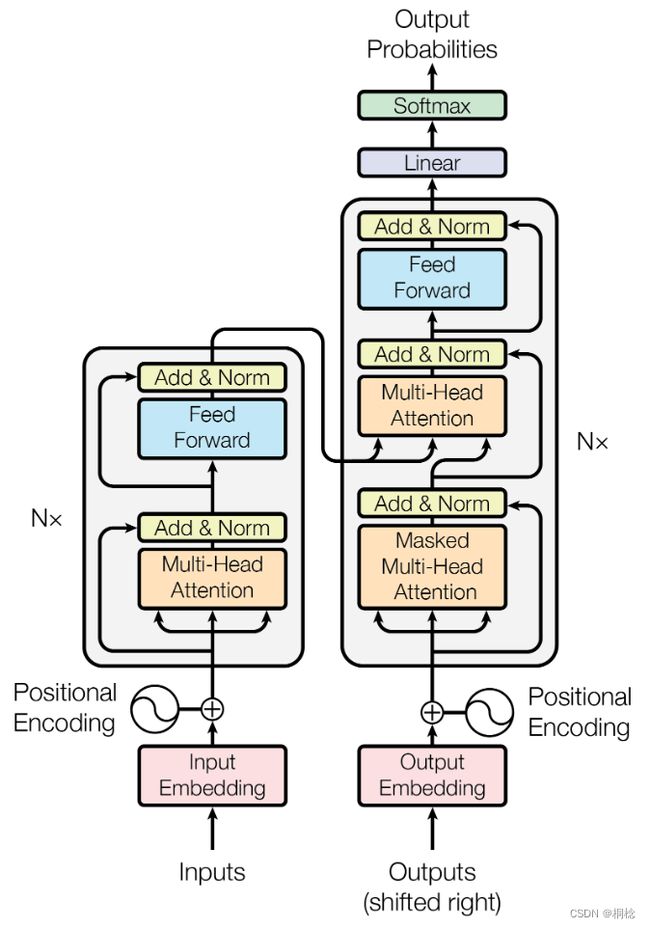
3.1 Transformer
Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。Transformer作为编码器-解码器架构的一个实例,整体是由编码器和解码器组成的。transformer的编码器和解码器是基于自注意力的模块叠加而成的,输入序列和输出序列的embedding表示将加上位置编码(positional encoding),再分别输入到编码器和解码器中。
3.2 Informer
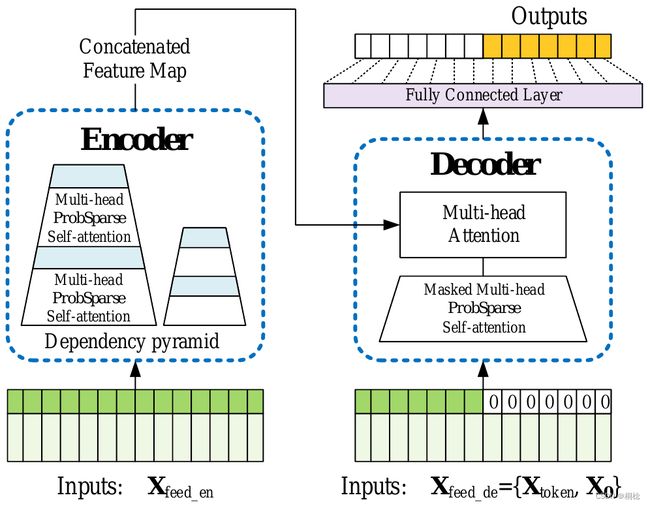
Transformer在长距离依赖的表达方面表现出了较高的潜力。然而,Transformer存在几个严重的问题:① 自注意力机制的计算复杂度问题;② 高内存使用量问题;③ 预测长期输出的效率问题。
Informer是一种基于改进Transformer的长序列时间序列预测模型。该模型具有三个显著特征:
① ProbSparse Self-Attention,在时间复杂度和内存使用率上达到了O(LlogL),在序列的依赖对齐上具有相当的性能。
② self-attention蒸馏机制,通过对每个attention层结果上套一个Conv1D,再加一个Maxpooling层,来对每层输出减半来突出主导注意,并有效地处理过长的输入序列。
③ 并行生成式解码器机制,对长时间序列进行一次前向计算输出所有预测结果而不是逐步的方式进行预测,这大大提高了长序列预测的推理速度。
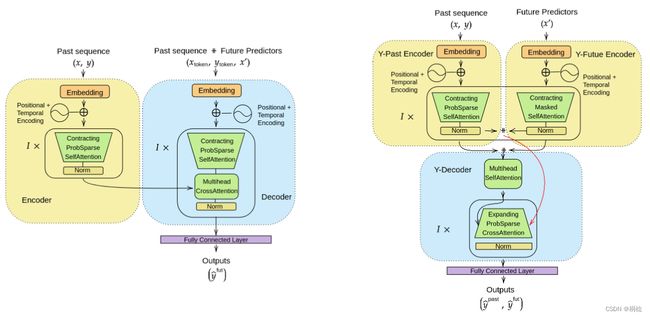
3.3 Yformer
Informer等基于Transformer的模型,不涉及耦合的降尺度和升尺度过程,不能产生与输入相同分辨率的预测。因此Yformer主要有一下几点改进:1.耦合降尺度/升尺度以利用粗粒度和细粒度特征进行时间序列预测;2.将耦合的尺度机制与稀疏注意模块相结合以捕捉所有尺度级别上的长程效应;3.通过重构最近的序列信息来稳定编码器和解码器。
4 时间卷积网络
4.1 TCN
TCN是时间卷积网络(Temporal Convolutional Network)的简称,它由具有相同输入和输出长度的空洞因果的一维卷积层组成。
关于TCN,以下几点是时间卷积中比较核心的概念。
4.1.1 因果卷积
因果卷积可以从图中很直观的看出来。 即对于上一层t时刻的值,只依赖于下一层t时刻及其之前的值。和传统的卷积神经网络的不同之处在于,因果卷积不能看到未来的数据,它是单向的结构,不是双向的。也就是说只有有了前面的因才有后面的果,是一种严格的时间约束模型,因此被称为因果卷积。

4.1.2 空洞卷积
单纯的因果卷积还是存在传统卷积神经网络的问题,即对时间的建模长度受限于卷积核大小的,如果要想抓去更长的依赖关系,就需要线性的堆叠很多的层。为了解决这个问题,研究人员提出了空洞卷积。
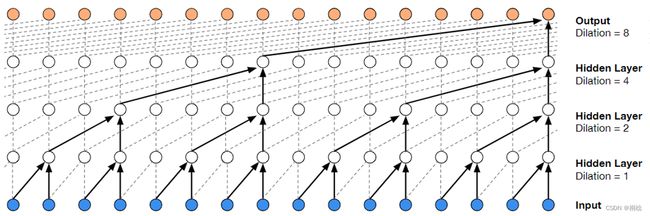
和传统卷积不同的是,空洞卷积允许卷积时的输入存在间隔采样。这使得有效窗口的大小随着层数呈指数型增长。这样卷积网络用比较少的层,就可以获得很大的感受野。
4.1.3 残差链接
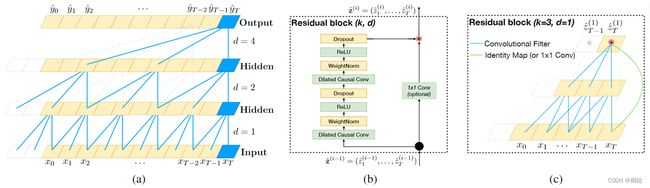
残差链接已多次被证明有益于非常深的网络,它使得网络可以跨层的方式传递信息。
由于TCN的感受野取决于网络深度以及卷积核大小和空洞因子,因此更深更大的TCN梯度的稳定性变得重要。更具体地说,每一层由多个用于特征提取的卷积核组成。因此,在TCN的设计中,使用通用残差模块来代替卷积层。
在TCN(和一般的卷积网络)中,输入和输出可能具有不同的宽度。为了解决输入输出宽度的差异,这里使用了额外的1x1卷积来确保元素加法⊕接收相同形状的张量。
4.2 SCINet
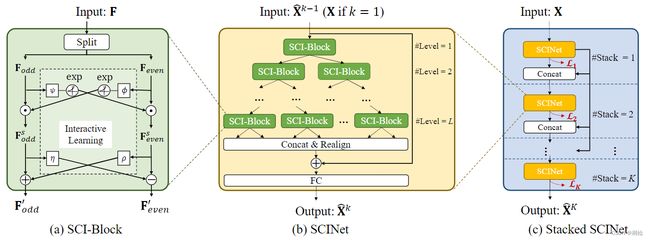
SCINet是基于时间卷积构造的模型,该模型采用层次化结构,以不同的时间分辨率迭代地提取和交换信息,并学习具有增强可预测性的有效表示。基本构建块SCI-Block对输入数据/特征进行下采样,并对两个子序列进行特征提取和交互,以保留每个子序列的异构信息,并补偿下采样过程中的信息损失。
相比于TCN,SCINet这篇论文证明了因果卷积不是必需的,通过去除约束可以获得更好的预测精度。
5 总结
如图11(a)所示,基于RNN的时间序列预测方法在用于预测的内部存储器状态中紧凑地总结过去的信息,其中存储器状态在每个时间步长用新的输入递归地更新。这些方法一般属于IMS估计方法,存在误差累积的问题。梯度消失/爆炸问题和内存约束也严重制约了应用场景。
由于其训练效率和自我注意机制的有效性,Transformer已经在几乎所有的序列建模任务中取代了RNN模型。因此,有学者提出了各种基于Transformer的时间序列预测方法(图11(b))。而且它们在预测长序列方面被证明是相当有效的。然而,基于Transformer的模型的开销是一个严重的问题,许多研究努力致力于解决这个问题。

时间卷积模型目前已经成为各种时间序列预测问题的流行选择。这是因为,与基于RNN和Transformer的方法相比,多个卷积核(图11©)的并行卷积运算允许在多变量时间序列内和多变量时间序列之间进行快速的数据处理和有效的相关性学习。
若有不对的地方,欢迎来评论区补充、讨论~
觉得有帮助的可以点赞支持一下哦~
参考文献
[1] 循环神经网络 — 动手学深度学习
[2] 循环神经网络 RNN、LSTM、GRU
[3] Transformer论文: Attention Is All You Need
[4] Self-Attention和Transformer - machine-learning-notes (gitbook.io)
[5] Informer论文: Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
[6] Yformer论文: Yformer: U-Net Inspired Transformer Architecture for Far Horizon Time Series Forecasting
[7] WaveNet论文: WAVENET: A GENERATIVE MODEL FOR RAW AUDIO
[8] TCN论文: An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
[9] SCINet论文: Time Series is a Special Sequence:
Forecasting with Sample Convolution and Interaction