论文研究5:A Speaker-Independent Audio-Visual Model for Speech Separation
论文研究5:Looking to Listen at the Cocktail Party:A Speaker-Independent Audio-Visual Model for Speech Separation
abstract
我们提出了一种联合视听模型,用于从诸如其他说话人和背景噪声之类的声音混合中分离出单个语音信号。仅使用音频作为输入来解决该任务非常具有挑战性,并且不能提供分离的语音信号与视频中的说话人的关联。在本文中,我们提出了一个基于深度网络的模型,该模型结合了视觉和听觉信号来解决此任务。视觉功能用于将音频“聚焦”到场景中所需的说话人上并改善语音分离质量。为了训练我们的联合视听模型,我们引入了AVSpeech,这是一个新的数据集,包含来自网络的数千小时的视频片段。我们展示了我们的方法适用于经典语音分离任务以及涉及激烈采访,嘈杂酒吧和尖叫儿童的现实世界场景的情况,仅要求用户在视频中指定他们想要讲话的人的脸隔离。在混合语音的情况下,我们的方法显示出优于现有的纯音频语音分离的明显优势。另外,我们的模型是独立于说话者的(训练过一次,适用于任何说话者),其效果要比最近依赖于说话者的视听语音分离方法(要求为每个感兴趣的说话者训练一个单独的模型)产生更好的结果。
1 INTRODUCTION
人类能够在嘈杂的环境中将听觉注意力集中在单个声音源上,同时不强调(“静音”)所有其他声音和声音。 神经系统实现这一壮举的方式,即鸡尾酒会效应[Cherry 1953],目前尚不清楚。 但是,研究表明,观看说话者的脸可以增强人在嘈杂环境中解决感知歧义的能力[Golumbic等。 2013; Ma等。 2009]。在本文中,我们通过计算实现了此功能.
在音频处理文献中,对自动语音分离(将输入音频信号分离成其各个语音源)进行了深入研究。 由于此问题天生是不适的,因此需要预先的知识或特殊的麦克风配置,以获得合理的解决方案[McDermott 2009]。 另外,纯音频语音分离的基本问题是标签置换问题[Hershey等。 2016]:没有简单的方法将视频中的每个单独的音频源与其对应说话者关联起来[Hershey等。 2016; Yu等。 2017]。
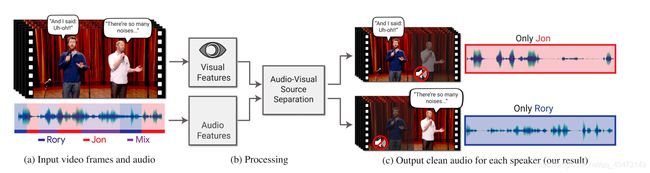
在这项工作中,我们提出了一种联合视听方法,用于将音频“聚焦”在视频中所需的说话人上。 然后可以重新组合输入视频,从而增强与特定人群相对应的音频,同时抑制所有其他声音(图1)。 更具体地说,我们设计和训练了一个基于神经网络的模型,该模型将记录的声音混合以及视频中每个帧中检测到的面部的紧密裁剪作为输入,并将混合后的内容分成每个检测到的说话者的单独音频流。 该模型将视觉信息用作提高信号源分离质量的方法(与仅音频结果相比),并将分离的语音轨道与视频中的可见说话人相关联。 用户所需要做的就是指定他们想听视频的人的哪些面孔。
为了训练我们的模型,我们从YouTube收集了290,000个高质量的演讲,TED演讲和操作视频,然后从这些视频中自动提取大约4700个小时的视频片段,其中包含清晰的讲话者和清晰的语音,没有干扰的声音(图2) 。 我们称新数据集为AVSpeech。 有了这个数据集,我们然后生成了“合成鸡尾酒会”的训练集-面部视频与清晰语音的混合,以及其他语音音轨和背景噪音。
我们以两种方式证明了我们的方法相对于最近的语音分离方法的好处。 首先,与纯语音混合的最先进的纯音频方法相比,我们显示出优异的结果。 其次,我们演示了模型在现实世界中从包含重叠语音和背景噪声的混合物中产生增强的声音流的能力。
总而言之,我们的论文有两个主要贡献:(a)视听语音分离模型在经典的语音分离任务上优于纯视听模型,适用于具有挑战性的自然场景。 据我们所知,我们的论文是第一个提出独立于说话者的视听模型以进行语音分离的论文。 (b)经过仔细收集和处理的新的大规模视听数据集AVSpeech,由视频片段组成,其中可听声音属于单个人,在视频中可见,没有音频背景干扰。 该数据集使我们能够获得语音分离方面的最新成果,并且可能对研究社区进行进一步的研究很有用。 我们的数据集,输入和输出视频以及其他补充材料都可以在项目网页上找到:http://looking-to-listen.github.io/。
2 RELATED WORK
我们简要回顾了语音分离和视听信号处理领域的相关工作。
语音分离: 语音分离是音频处理中的基本问题之一,并且在过去的几十年中一直是广泛研究的主题。 Wang和Chen [2017]全面概述了基于深度学习的最新纯音频方法,该方法可同时解决语音降噪[Erdogan等.2015; Weninger等.2015]和语音分离任务。
已经出现了两个最近的工作,它们解决了上述标签排列问题,从而在单声道情况下执行了独立于说话者的,超说话者分离。 Hershey等[2016]提出了一种称为深度聚类的方法,其中使用经过区别训练的语音嵌入来聚类和分离不同的来源。 Hershey等[2016]也引入了无置换或置换不变损失函数的想法,但他们没有发现它运作良好。 Isik等[2016]和Yu等[2017]随后介绍了成功使用置换不变损失函数训练DNN的方法。
我们的方法相对于此类纯音频方法具有三方面的优势:首先,我们证明了音像模型的分离结果比最新的纯音频模型具有更高的质量。 其次,我们的方法在设置多个说话人并混有背景噪声的情况下表现良好,据我们所知,没有一种仅音频方法能够令人满意地解决。 第三,我们共同解决了两个语音处理问题:语音分离和将语音信号分配给其对应的面孔,到目前为止,这些问题已经分别解决了[Hoover et al 2017; Hu等 2015; 蒙纳西2011]。
音视频: 人们对于将神经网络用于听觉和视觉信号的多模式融合以解决各种与语音相关的问题越来越感兴趣。 这些包括视听语音识别[Feng等。 2017; Mroueh等。 2015; Ngiam等。 [2011年],通过无声视频(唇读)预测语音或文本[Chung等。 2016; Ephrat等2017],以及通过视觉和语音信号进行无监督的语言学习[Harwath等2016]。 这些方法利用了同时记录的视觉和听觉信号之间的自然同步。
视听(AV)方法也已用于语音分离和增强[Hershey等 2004; Hershey and Casey 2002; 汗2016; Rivet等 2014]。 Casanovas等。 [2010]使用稀疏表示来执行AV源分离,由于依赖主动区域来学习源特性,并且假设所有音频源都可以在屏幕上看到,因此该方法受到限制。 最近的方法已经使用神经网络来执行任务。 侯等人[2018]提出了一个基于多任务CNN的模型,该模型输出去噪语音频谱图以及输入唇部区域的重构。 Gabbay等[2017]在视频中训练语音增强模型,其中目标说话者的其他语音样本用作背景噪声,这被他们称为“噪声不变训练”。 在并发工作中,Gabbay等人[2018]使用视频到声音的合成方法来过滤嘈杂的音频。
这些AV语音分离方法的主要局限性在于它们取决于说话者,这意味着必须分别为每个说话者训练专用的模型。 尽管这些作品做出了特定的设计选择,仅将其适用性限制在与说话者相关的情况下,但我们推测,到目前为止,尚未广泛追求与说话者无关的AV模型的主要原因是缺少足够大且多样化的数据集 训练此类模型-类似于我们在本工作中构建和提供的数据集。 据我们所知,我们的论文是第一个解决与说话者无关的AV语音分离问题的论文。
我们的模型能够分离和增强从未见过的说话者,他们使用的语言不是训练集的一部分。 此外,我们的工作是独一无二的,因为我们在现实世界中的示例中显示了高质量的语音分离,而在以前的纯音频和视听语音分离工作中却没有涉及到这种设置。
最近出现了许多独立且并行的工作,这些工作解决了使用深度神经网络进行视听声源分离的问题。 [Owens and Efros 2018]训练网络以预测音频和视频流是否在时间上受限制。 然后,将从此自我监督模型中提取的学习功能用于调节开/关屏幕扬声器源分离模型。 Afouras等[2018]通过使用网络来预测去噪语音频谱图的幅度和相位来执行语音增强。 赵等[2018]和Gao等[2018]解决了分离多个屏幕上物体(例如乐器)的声音这一紧密相关的问题。
视听数据集: 大多数现有的AV数据集都包含仅带有少量主题的视频,这些单词来自有限的词汇。 例如,CUAVE数据集[Patterson等。 [2002年]包含36个主题,每个数字从0到9分别表示五次,每个数字共有180个示例。 另一个例子是Hou等人介绍的普通话句子数据集。 [2018],其中包含由母语人士说的320普通话句子的视频记录。 每个句子包含10个汉字,音素分布均匀。 TCD-TIMIT数据集[Harte and Gillen 2015]由60位自愿讲者组成,每人约有200个视频。 演讲者背诵TIMIT数据集中的各种句子[S Garofolo et al 1992],并使用前置摄像头和30度摄像头进行录音。 我们在这三个数据集上评估我们的结果,以便与以前的工作进行比较。
最近,Chung等人引入了大规模的口语朗诵句子(LRS)数据集[2016],其中包括各种各样的说话者和较大词汇量的单词。 但是,不仅数据集不是公开可用的,而且不能保证LRS视频中的语音清晰,这对于训练语音分离和增强模型至关重要。
3 AVSPEECH DATASET
我们引入了一个新的大规模视听数据集,该数据集包含没有干扰背景信号的语音剪辑。 这些段的长度是可变的,介于3到10秒之间,并且在每个剪辑中,视频中唯一可见的面孔和音轨中的可听声音属于单个讲话者。 总体而言,数据集包含大约4700个小时的视频片段,大约有15万名不同的演讲者,涵盖了各种各样的人物,语言和面部姿势。 代表性的帧,音频波形和一些数据集统计数据如图2所示。
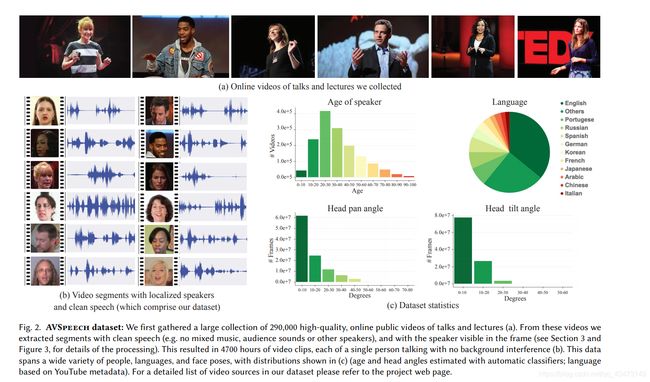
我们自动收集了数据集,因为要组装如此规模的语料库,重要的是不要依赖大量的人工反馈。 我们的数据集创建流程从大约290,000个YouTube演讲视频(例如TED演讲)和操作视频中收集了剪辑。 对于这样的频道,大多数视频包括单个说话者,并且视频和音频通常都是高质量的。
数据集创建通道: 我们的数据集收集过程有两个主要阶段,如图3所示。首先,我们使用了Hoover等人的说话人跟踪方法。 [2017]检测一个活跃的人的视频片段,使其面部可见。 从片段中丢弃了模糊,照明不足或具有极端姿势的脸部框架。 如果丢失了超过15%的部分面部框,则将其完全丢弃。 在此阶段,我们将Google Cloud Vision API1用于分类器,并计算图2中的统计信息。
建立数据集的第二步是将语音片段细化为仅包含干净,无干扰的语音。 这是至关重要的组成部分,因为这样的片段在训练过程中充当了基础事实。 我们通过如下估算每个段的语音SNR(主要语音信号与其余音频信号的对数比)自动执行此优化步骤。
我们使用经过预训练的纯音频语音降噪网络,使用降噪后的输出作为纯信号的估计值来预测给定段的SNR。 该网络的体系结构与第5节中针对纯音频语音增强基线实现的体系结构相同,并且是根据来自公共领域有声读物的LibriVox集合中的语音进行训练的。 估计SNR低于阈值的段将被拒绝。 使用不同的已知SNR级别的纯净语音和非语音干扰噪声的合成混合物,凭经验设置阈值。 这些合成的混合物被送入去噪网络,并将估计的(去噪的)SNR与真实SNR进行比较(见图3(b))。
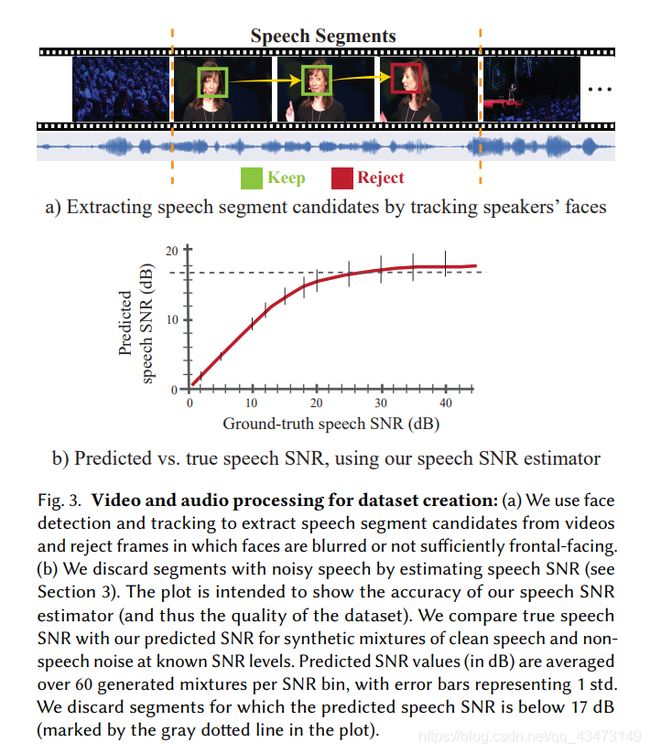
我们发现,在低SNR时,平均而言,估计的SNR非常准确,因此可以认为是原始噪声水平的良好预测指标。 在较高的SNR(即对原始语音信号几乎没有干扰的段)下,此估计器的精度会降低,因为噪声信号很微弱。 如图3(b)所示,发生这种情况的阈值约为17 dB。 我们听取了100个剪辑的随机样本,这些样本通过了此过滤,结果发现其中没有一个包含明显的背景噪声。 我们在补充资料中提供了来自我们的数据集的样本视频剪辑。
4 AUDIO-VISUAL SPEECH SEPARATION MODEL
从高层次上讲,我们的模型由多流体系结构组成,该体系以检测到的面部的可视流和嘈杂的音频作为输入,并输出复杂的频谱图掩码,视频中每个检测到的面部都使用一个掩码(图4)。 然后将带噪声的输入频谱图乘以掩码,以得到每个说话人的分离的语音信号,同时抑制所有其他干扰信号。
4.1 Video and Audio Representation
输入功能: 我们的模型将视觉和听觉特征作为输入。 给定一个包含多个说话人的视频片段,我们使用现成的面部检测器(例如Google Cloud Vision API)在每个帧中查找面部(假设每个说话者以25 FPS播放3秒,则每个说话者总共包含75张面部缩略图)。 我们使用预训练的人脸识别模型为每个检测到的人脸缩略图提取每帧一个人脸嵌入。 我们使用网络中没有空间变化的最低层,类似于Cole等人使用的最低层 [2016]。用于合成人脸。 这样做的基本原理是,这些嵌入保留了识别数百万张脸部所需的信息,同时丢弃了图像之间不相关的变化(例如照明)。 实际上,最近的工作还表明,可以从这种嵌入中恢复面部表情[Rudd et al.2016]。 我们还对面部图像的原始像素进行了实验,但这并未导致性能提高。
至于音频功能,我们计算了3秒音频片段的短时傅立叶变换(STFT)。 每个时频(TF)箱包含复数的实部和虚部,我们将两者都用作输入。 我们执行幂律压缩,以防止响亮的音频压倒弱的音频。 对噪声信号和纯净参考信号都进行相同的处理。
在推论时,我们的分离模型可以应用于任意长的视频片段。 当在一帧中检测到多个说话的脸时,我们的模型可以接受多个脸部流作为输入,我们将在稍后讨论。
输出: 我们模型的输出是一个乘法频谱图掩码,它描述了干净语音与背景干扰的时频关系。 在以前的工作中[Wang and Chen 2017; Wang等。 [2014年],观察到乘法掩模比其他方法(例如,频谱图幅度的直接预测或时域波形的直接预测)效果更好。 源分离文献[Wang and Chen 2017]中存在基于掩蔽的训练目标的许多类型,其中我们尝试了两种:比率掩蔽(RM)和复杂比率掩蔽(cRM)。
理想比率掩码定义为干净频谱图和噪声频谱图之间的比率,并且假定介于0和1之间。复频域理想比率掩膜(cRM)定义为干净频谱图和噪声频谱图的比率。 cRM具有实部和虚部,它们分别在实域中被激励。 复杂掩码的实部和虚部通常在-1和1之间,但是,我们使用Sigmoid型压缩将这些复杂掩码值限制在0和1之间[Wang等2016]。
使用cRM进行掩膜时,通过对预测的cRM和噪声频谱图进行复数乘法,可以通过执行逆STFT(ISTFT)获得降噪波形。 当使用RM时,我们对预测的RM和有噪声的频谱图幅值与有噪声的原始相位进行点对乘以执行ISTFT [Wang and Chen 2017]。
给定多个检测到的发言人的面部流作为输入,网络将为每个发言人输出一个单独的掩码,并为背景干扰提供一个掩码。 我们使用cRM进行了大多数实验,因为我们发现使用cRM的输出语音质量明显优于RM。 两种方法的定量比较请参见表6。
4.2 Network architecture
图4提供了我们网络中各个模块的概述,现在我们将对其进行详细描述。

音频和视频流:我们模型的音频流部分由膨胀的卷积层组成,其参数在表1中指定。
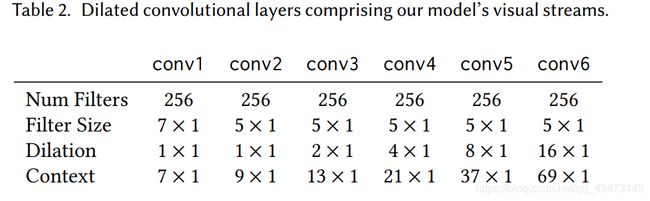
我们模型的视觉流用于处理输入人脸嵌入(请参阅第4.1节),并且由扩张卷积组成,如表2所示。请注意,视觉流中的“空间”卷积和扩张是在时间轴上执行的( (不超过1024-D人脸嵌入通道)。
为了补偿音频和视频信号之间的采样率差异,我们对视觉流的输出进行上采样,以匹配频谱图采样率(100 Hz)。 这是通过在每个视觉特征的时间维度上使用简单的最近邻插值来完成的。
AV融合: 通过串联每个流的特征图来组合音频和视频流,然后将这些特征图馈入BLSTM和三个FC层。 最终输出包含每个输入说话者的复数掩码(实数和虚数两个通道)。 相应的频谱图是通过将有噪声的输入频谱图和输出掩码进行复数乘法来计算的。 幂律压缩后的原始频谱图和增强频谱图之间的平方误差(L2)被用作损失函数来训练网络。 如第4.1节所述,使用ISTFT获得最终输出波形。
多个说话者:我们的模型支持隔离视频中的多个可见说话者,每个说话者由一个可视流表示,如图4所示。一个单独的专用模型针对每种可见说话者的数量进行训练,例如, 一个模型,其中一个视觉流用于一个可视说话者,两个视觉流模型用于两个可视说话者,等等。所有视觉流在卷积层上共享相同的权重。 在这种情况下,在继续进行BLSTM之前,将从每个视觉流中学习到的特征与学习到的音频特征连接在一起。 应当注意的是,实际上,在发言人数量未知或专用多说话者模型不可用的一般情况下,可以使用以单个视觉流作为输入的模型。
4.3 Implementation details
我们的网络是在TensorFlow中实现的,其包含的perations用于执行波形和STFT转换。 ReLU激活遵循除最后一个(掩码)外的所有网络层,在最后一个(掩码)中采用了Sigmoid。 在所有卷积层之后执行批归一化[Ioffe and Szegedy 2015]。 由于我们训练大量数据且不会遭受过度拟合的困扰,因此未使用Dropout。 我们使用6个样本的批次大小,并使用Adam优化器训练500万步(批次),学习率为3·10-5,每180万步减少一半。
将所有音频重新采样到16kHz,并且仅通过左声道将立体声音频转换为单声道。 使用长度为25ms的Hann窗口,10ms的跳长和512的FFT大小来计算STFT,从而得到257×298×2标量的输入音频特征。 幂律压缩以p = 0.3(A ^ 0.3,其中A是输入/输出音频频谱图)执行。
在训练和推理之前,我们通过移除或复制嵌入将所有视频中的面部嵌入重新采样到25帧/秒(FPS)。 这将产生75个面部嵌入的输入视觉流。 使用Cole等人描述的工具进行面部检测,对准和质量评估[2016]。 当在特定样本中遇到丢失的帧时,我们将使用零向量来代替人脸嵌入。
5 EXPERIMENTS AND RESULTS
我们在各种条件下测试了我们的方法,并且将我们的结果与最先进的纯音频(AO)和视听(AV)语音分离和增强(定量和定性)进行了比较。
与仅音频的比较。没有公开可用的最先进的纯音频语音增强/分离系统,并且相对较少的公开可用的数据集用于训练和评估纯音频语音增强。尽管有大量文献报道“盲源分离”用于纯语音的增强和分离[Comon and Jutten 2010],但这些技术大多数都需要多个音频通道(多个麦克风),因此不适用于我们的任务。由于这些原因,我们实现了用于语音增强的AO基准,该基准与我们的视听模型中的音频流具有相似的体系结构(当去除可视流时,图4)。在CHiME-2数据集上进行训练和评估时[Vincent等。 [2013年]被广泛用于语音增强工作,我们的AO基线实现了14.6 dB的信噪比,几乎与Erdogan等人报告的最新单通道结果14.75 dB一样好。 [2015]。因此,我们的AO增强模型被认为是最先进的基线。
为了将我们的分离结果与最先进的AO模型的分离结果进行比较,我们实施了Yu等人介绍的置换不变训练。 [2017]。 请注意,使用此方法进行语音分离需要先验知识,以了解录制中存在的音源数量,还需要将每个输出通道手动分配给视频中相应扬声器的脸部(我们的AV方法会自动执行)。
我们将在第5.1节的所有合成实验中使用这些AO方法,并在第5.2节的真实视频中对其进行定性比较.
与最近的视听方法的比较。 由于现有的AV语音分离和增强方法取决于说话者,因此我们无法轻松地在合成混合物的实验(第5.1节)中将它们与它们进行比较,也无法在自然视频中运行它们(第5.2节)。 但是,通过在这些论文的视频上运行我们的模型,我们可以在现有数据集上显示与这些方法的定量比较。 我们将在5.3节中详细讨论这种比较。 此外,我们在补充材料中显示了定性比较。
5.1 Quantitative Analysis on Synthetic Mixtures
我们为几个不同的单通道语音分离任务生成了数据。 每个任务都需要自己独特的语音和非语音背景噪声混合配置。 我们在下面描述了每种训练数据变体的生成过程,以及从头开始训练的每种任务的相关模型。
在所有情况下,干净的语音剪辑和相应的面孔都来自我们的AVSpeech(AVS)数据集。 非语音背景噪声可从AudioSet获得[Gemmeke等。 2017],这是YouTube视频中带有手动注释的细分受众群的大规模数据集。 使用BSS Eval工具箱中的信号失真比(SDR)改进来评估分离的语音质量[Vincent等。 [2006年],这是评估语音分离质量的常用指标(请参见附录A部分)。
我们从数据集中不同长度的片段中提取了3秒的非重叠片段(例如,一个10秒的片段将贡献3个3秒的片段)。 我们为所有模型和实验生成了150万种合成混合物。 对于每个实验,将生成的数据的90%用作训练集,其余的10%用作测试集。 我们未使用任何验证集,因为未执行任何参数调整或提早停止操作。
一个说话者+噪音(1S +噪音)。 这是经典的语音增强任务,其训练数据是通过非标准化的干净语音和AudioSet噪声的线性组合生成的:Mixi = AV Sj + 0.3 * AudioSetk,其中AV Sj是来自AVS的一种发音,AudioSetk是AudioSet的一个片段,其幅度乘以0.3,并且Mixi是生成的合成混合物数据集中的样本。 在这种情况下,我们的纯音频模型表现很好,因为噪声的特征频率通常与语音的特征频率很好地分开。 我们的视听(AV)模型的性能与纯音频(AO)基线相同,SDR为16 dB(表3的第一列)。
两个纯净的说话者(纯净2S)。 此两扬声器分离方案的数据集是通过将AVS数据集中两个不同讲话者的清晰语音混合而生成的:Mixi = AV Sj + AV Sk,其中AV Sj和AV Sk是来自我们数据集中不同源视频的清晰语音样本, Mixi是生成的合成混合物数据集中的样本。 除了AO基准外,我们还针对此任务训练了两种不同的AV模型:
(i)仅采用一个视觉流作为输入,并且仅输出其对应的降噪信号的模型。 在这种情况下,可以推断出,每个说话人的降噪信号是通过网络中的两个前向通过(每个语音者一个)获得的。 将这个模型的SDR结果平均可以比我们的AO基准提高1.3 dB(表3的第二列)。
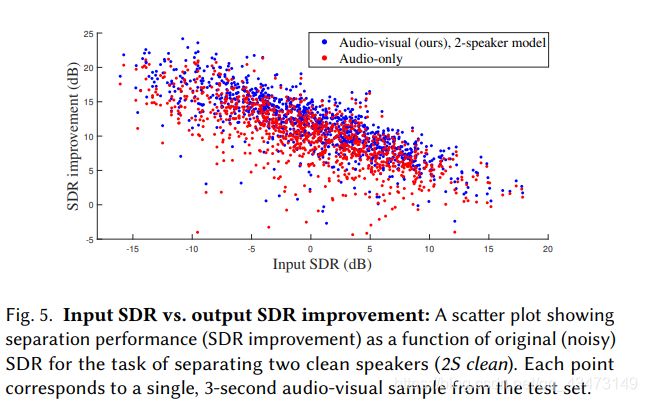
(ii)一个模型,该模型以两个单独的流(来自第4节中的解释)为基础,将来自两个讲话者的视觉信息作为输入。 在这种情况下,输出包括两个掩码,每个说话人一个,并且通过一次前向通过来进行推断。 使用此模型可获得0.4 dB的额外增强,从而使总SDR改善10.3 dB。 直观上,联合处理两个可视流将为网络提供更多信息,并对分离任务施加更多约束,从而改善结果。 图5显示了针对纯音频基准和我们的两个扬声器的视听模型,针对此任务的SDR改进与输入SDR的关系。
图5显示了针对纯音频基准和我们的两个扬声器的视听模型,针对此任务的SDR改进与输入SDR的关系。
两个扬声器+噪音(2S +噪音)。 在这里,我们考虑的任务是将一个说话者的声音与两个说话者的声音和非语音背景噪声混合在一起。 就我们所知,此视听任务以前从未解决过。 训练数据是通过将两个不同说话者的清晰语音(为2S干净任务生成的)与AudioSet的背景噪声混合而生成的:Mixi = AV Sj + AV Sk + 0.3 * AudioSetl
在这种情况下,我们用三个输出来训练AO网络,一个用于每个说话者,一个用于背景噪声。 此外,我们训练了模型的两种不同配置,并接收了一个和两个视觉流作为输入。 单流AV模型的配置与先前实验中的模型(i)相同。 两流AV输出三个信号,每个说话者一个,背景噪声一个。 如表3(第三列)所示,我们的单流AV模型在仅音频基线上的SDR增益为0.1 dB,对于两个流为0.5 dB,使总SDR改善为10.6 dB。 图6显示了从该任务中提取的样本片段的掩码和输出频谱图,以及其嘈杂的输入和地面真实频谱图。
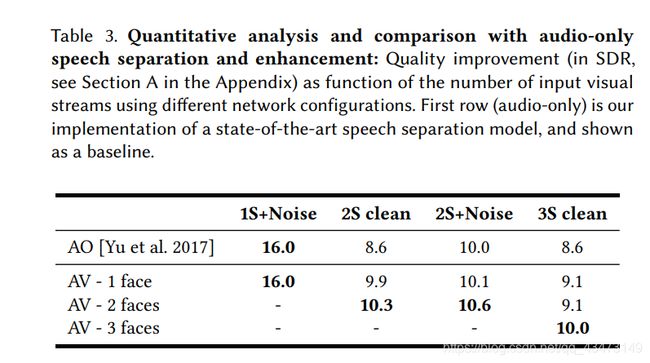
三个干净的说话者(3S干净)。 通过混合来自三个不同说话者的清晰语音来创建此任务的数据集:Mixi = AV Sj + AV Sk + AV Sl。 与以前的任务类似,我们使用一个,两个和三个视觉流作为输入来训练我们的AV模型,分别输出一个,两个和三个信号。 我们发现,即使使用单个视觉流,AV模型的性能也比AO模型更好,并且比AO模型提高了0.5 dB。 两种视觉流配置与AO模型相比具有相同的改进,而使用三种视觉流则带来1.4 dB的增益,总共实现了10 dB的SDR改进(表3的第四列)。
同性分离。 尝试分离包含相同性别语音的混合语音时,许多以前的语音分离方法均会降低性能[Delfarah and Wang 2017; 好时等。 2016]。 表4显示了按性别划分的分离质量细分。 有趣的是,我们的模型在男女混合物上表现最佳(略有提高),但在其他组合上也表现良好,证明了其性别稳健性。

5.2 Real-World Speech Separation
为了在现实世界中展示我们模型的语音分离功能,我们在各种视频中对其进行了测试,其中包含激烈的辩论和访谈,嘈杂的酒吧和尖叫的孩子(图7)。在每种情况下,我们都使用经过训练的模型,该模型的视觉输入流数量与视频中可见说话者的数量相匹配。例如,对于具有两个可见说话者的视频,使用了两个说话者模型。由于我们的网络体系结构从不执行特定的时间长度,因此我们使用模型支持的每个视频单个前向通过来执行分离。这样一来,我们就无需对视频的较短块进行后处理和合并结果。由于这些示例没有清晰的参考音频,因此将对这些结果以及它们与其他方法的比较进行定性评估。它们在我们的补充材料中介绍。应当指出,我们的方法不能实时运行,而以当前形式,我们的语音增强功能更适合视频编辑的后处理阶段。
在我们的补充材料中,合成的“ Double Brady”视频突出了我们模型对视觉信息的利用,因为在这种情况下仅使用音频中包含的特征性语音频率很难进行语音分离。
“ Noisy Bar”场景显示了我们从低SNR的混合物中分离语音的方法的局限性。(我认为这是当前所有模型存在的最大的问题) 在这种情况下,背景噪声几乎被完全抑制,但是输出语音质量明显下降。 Sun等 [2017]观察到此限制源于使用基于掩码的分离方法,在这种情况下,直接预测去噪的频谱图可以帮助克服此问题。 在经典语音增强的情况下,即一位具有非语音背景噪声的说话人,我们的AV模型获得的结果与强AO基线的结果相似。 我们怀疑这是因为噪声的特征频率通常与语音的特征频率很好地分开,因此合并视觉信息不会提供额外的辨别能力。
5.3 Comparison with Previous Work in Audio-Visual Speech Separation and Enhancement
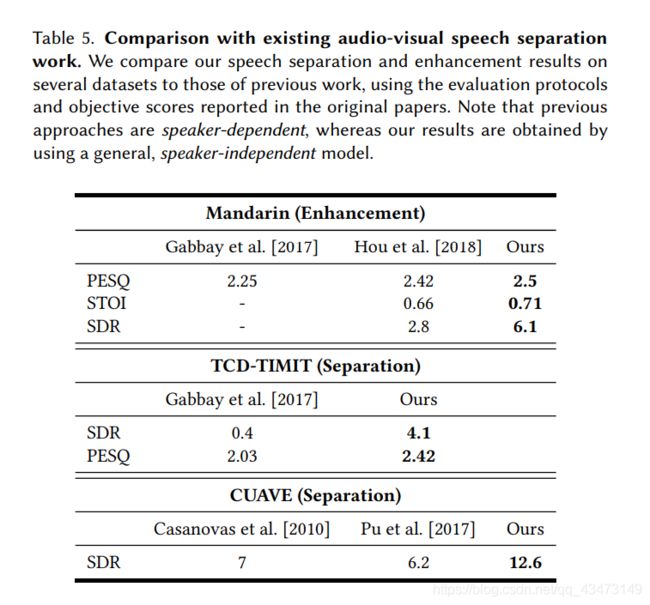
如果不将我们的结果与先前在AV语音分离和增强方面的工作进行比较,我们的评估将是不完整的。 表5包含了在第2节中提到的三个不同AV数据集(普通话,TCD-TIMIT和CUAVE)的比较,并使用了相应论文中介绍的评估协议和指标。 报告的客观质量得分为PESQ [Rix等。 2001],STOI [Taal et al BSS eval工具箱中的SDR [Vincent et al 2010] 2006]。 这些比较的定性结果可在我们的项目页面上找到。
重要的是要注意,这些现有方法需要为其数据集中的每个说话者训练一个专用模型(取决于说话者),而我们对其数据的评估是使用在我们的一般AVS数据集(与说话者无关)上训练的模型完成的。 尽管以前从未遇到过这些特定的发言人,但我们的结果比原始论文中报告的结果要好得多,这表明我们的模型具有强大的泛化能力。
5.4 Application to Video Transcription
虽然我们在本文中的重点是语音分离和增强,但我们的方法也可用于自动语音识别(ASR)和视频转录。 作为概念的证明,我们进行了以下定性实验。 我们将“站立式”视频的语音分隔结果上传到了YouTube,并将YouTube自动字幕3产生的字幕与相应的混合语音源视频所产生的字幕进行了比较。 对于原始“站立”视频的一部分,ASR系统无法在视频的混合语音段中生成任何字幕。 结果包括两位演讲者的讲话,导致句子难以阅读。 但是,在我们分开的语音结果上产生的字幕明显更准确。 我们会在补充材料中显示完整字幕的视频。
5.5 Additional Analysis
我们还进行了广泛的实验,以更好地了解模型的行为以及模型的不同组成部分如何影响结果。
消融研究: 为了更好地理解模型的不同部分的作用,我们对从两个干净的说话人(2S Clean)的混合中分离语音的任务进行了消融研究。 除了消除网络模块的几种组合(视觉和音频流,BLSTM和FC层)之外,我们还研究了更高级的更改,例如不同的输出掩码(幅度),以及将学习到的视觉特征减少到每个标量一个标量的效果 时间步长和其他融合方法(早期融合)。
在早期融合模型中,我们没有单独的视觉和音频流,而是在输入处组合了两种模式。 首先,使用两个完全连接的层来减少每个视觉嵌入的维数,以在每个时间步上匹配光谱图尺寸,然后将视觉特征堆叠为第三光谱图“通道”,并在整个模型中对其进行联合处理。
表6显示了我们的消融研究结果。 该表包括使用SDR和ViSQOL进行的评估[Hines等[2015],这是一种旨在逼近人类听众语音质量平均意见得分(MOS)的客观指标。 ViSQOL分数是根据我们测试数据的随机2000个样本子集计算得出的。 我们发现SDR与分离的音频中残留的噪声量相关性很好,ViSQOL是输出语音质量的更好指标。 有关这些分数的更多详细信息,请参见附录中的A节。 “ Oracle” RM和cRM是分别通过使用地面实数实值谱和复值谱图按第4.1节所述获得的掩码。

这项研究最有趣的发现是使用实值幅度掩码而不是复杂的掩码时MOS的下降,以及每个时间步将视觉信息压缩为一个标量的惊人效果,如下所述。
瓶颈功能。 在我们的消融分析中,我们发现,将视觉信息压缩到每个时间步长一个标量的瓶颈(“ Bottleneck(cRM)”)的网络的性能几乎与完整模型(“ Full model(cRM )”),每个时间步使用64个标量。
模型如何利用视觉信号?我们的模型使用面部嵌入作为输入的视觉表示(第4.1节)。我们想了解这些高级功能中捕获的信息,并确定模型使用输入帧的哪些区域来分离语音。为此,我们遵循与[Zeiler and Fergus 2014;周等。 [2014]用于可视化深层网络的接受域。我们将该协议从2D图像扩展到3D(时空)视频。更具体地说,我们以滑动窗口方式使用时空补丁遮挡器(11px×11px×200ms patch4)。对于每个时空遮挡物,我们将遮挡的视频前馈到模型中,并将语音分离结果Socc与在原始(非遮挡)视频Soriд上获得的结果进行比较。为了量化网络输出之间的差异,我们使用SNR,将没有阻塞器的结果视为“信号” 。也就是说,对于每个时空补丁,我们计算:

对视频中的所有时空补丁重复此过程会导致每一帧的热图。 为了可视化的目的,我们通过视频的最大SNR对热图进行归一化:E^ = Emax-E。在E^中,高值对应于对语音分离结果有高影响的音色。
在图8中,我们显示了几个视频中代表帧的最终热图(完整的热图视频可在我们的项目页面上找到)。 正如预期的那样,贡献最大的面部区域位于嘴周围,但可视化显示其他区域(如眼睛和脸颊)也有贡献。

缺少视觉信息的影响。 通过逐步消除视觉嵌入,我们进一步测试了视觉信息对模型的贡献。 具体来说,我们首先运行模型并使用完整3秒视频的视觉信息评估语音分离质量。 然后,我们逐渐从该段的两端丢弃嵌入,并以2、1、0.5和0.2秒的可视持续时间重新评估分离质量。 结果如图9所示。有趣的是,当在片段中减少多达2/3的视觉嵌入时,语音分离质量平均仅降低0.8 dB。 这显示了模型对于缺少视觉信息的鲁棒性,在现实世界中,由于头部运动或闭塞,视觉信息可能会丢失。
6 CONCLUSION
我们提出了一个基于视听神经网络的模型,用于单通道,独立于说话者的语音分离。 我们的模型在具有挑战性的场景中效果很好,包括具有背景噪声的多扬声器混合。 为了训练模型,我们创建了一个新的视听数据集,其中包含数千小时的视频片段,其中包含从网络中收集的可见说话者和清晰语音。 我们展示了有关语音分离的最新结果以及在视频字幕和语音识别方面的潜在应用。 我们还进行了广泛的实验,以分析模型及其组件的行为。