关于提高PaddleOCR识别准确率的一些优化(二)
关于提高PaddleOCR识别准确率的一些优化(二)
- 前言
- 一、为什么要判断方向?
- 二、paddleocr方向分类器
-
- 1.方法介绍
- 2、实际效果测试
- 3、文本框检测实际效果
- 4、结果分析
- 5、解决办法
- 6、方向检测测试结果
- 三、paddlex图像分类
-
- 1.训练
- 2.测试结果分析
- 四、后续优化方向
- 总结
前言
本文基于关于提高OCR识别准确率的一些优化做出了一些改进和尝试,主要分为以下两点:
1、使用paddleocr方向分类器判断文本方向
2、用paddlex训练一个方向分类器判断文本方向
一、为什么要判断方向?
在我们的数据集中,有很多用户上传的图片,但这些图片有些是颠倒过来的,这种图片如果不经过预处理的话,识别效果会很差,比如:识别结果顺序不对、漏识率很高。经过测试发现将图片转正之后,识别效果会好很多。因此,判断方向并矫正是很有必要的
二、paddleocr方向分类器
1.方法介绍
引用paddleocr官方的介绍:
文字角度分类主要用于图片非0度的场景下,在这种场景下需要对图片里检测到的文本行进行一个转正的操作。在PaddleOCR系统内, 文字检测之后得到的文本行图片经过仿射变换之后送入识别模型,此时只需要对文字进行一个0和180度的角度分类,因此PaddleOCR内置的 文字角度分类器只支持了0和180度的分类。如果想支持更多角度,可以自己修改算法进行支持。
0和180度数据样本例子:
2、实际效果测试



3、文本框检测实际效果
4、结果分析
1、虽然paddle只支持 0度 和 180度 的文本方向检测,但通过观察图5和图6可以发现,虽然两者均被检测为180度,但二者的矩形框是不一样的
2、通过观察图1和图三可以发现,虽然二者的矩形框是一样的,但是paddleocr完全可以检测出二者的方向是不同的
3、结合以上分析结果,我们可以利用矩形框的长宽比来确定文本的方向。
5、解决办法
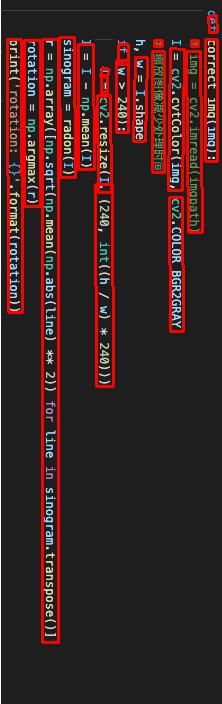
咱们结合代码来看吧,都在注释里,如下:
def get_real_rotation(rect_list):
w_div_h_sum = 0
count = 0
for rect in rect_list:
p0 = rect[0] #p0,p1,p2,p3为矩形框的四个角点坐标
p1 = rect[1]
p2 = rect[2]
p3 = rect[3]
width = abs(p1[0] - p0[0])
height = abs(p3[1] - p0[1])
w_div_h = width / height #计算长款比
if abs(w_div_h - 1.0) < 0.5: #过滤长宽比差距接近1的矩形框,以免影响检测准确度
count +=1
continue
w_div_h_sum += w_div_h
if w_div_h_sum / (len(rect_list) - count) >= 1.5: #长宽比大于1.5的,则paddleocr的检测结果是可信的
return 1
else:
return 0
def get_img_real_angle(img_path):
ocr = PaddleOCR(use_angle_cls=True)
angle_cls = ocr.ocr(img_path, det=False, rec=False, cls=True) #得到paddleocr检测角度
print(angle_cls)
rect_list = ocr.ocr(img_path, rec=False) #得到所有矩形框的角点坐标
real_angle_flag = get_real_rotation_new(rect_list)
if angle_cls[0][0] == '0':
if real_angle_flag:
ret_angle = 0
else:
ret_angle = 270
if angle_cls[0][0] == '180':
if real_angle_flag:
ret_angle = 180
else:
ret_angle = 90
return ret_angle
6、方向检测测试结果
1、跑了几十张图片测试了一下,发现只有60%的准确率,效果不怎么好。
2、可能的原因:
- 我们的数据比较特殊,需要重新训练paddleocr的方向分类器
- paddleocr的方向分类器就是不准,跟我们的数据没关系
三、paddlex图像分类
1.训练
1、不得不说说paddlex:能够在一分钟内完成一个图像多分类任务,上手简单
2、于是我马上拿官方例子试了一下,代码如下:
#%%
# 设置使用0号GPU卡(如无GPU,执行此代码后仍然会使用CPU训练模型)
import matplotlib
matplotlib.use('Agg')
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import paddlex as pdx
# %%
from paddlex.cls import transforms
train_transforms = transforms.Compose([
transforms.RandomCrop(crop_size=224),
transforms.RandomHorizontalFlip(),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.ResizeByShort(short_size=256),
transforms.CenterCrop(crop_size=224),
transforms.Normalize()
])
# %%
train_dataset = pdx.datasets.ImageNet(
data_dir='train_paddlex',
file_list='train_paddlex/train_list.txt',
label_list='train_paddlex/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir='train_paddlex',
file_list='train_paddlex/val_list.txt',
label_list='train_paddlex/labels.txt',
shuffle=True,
transforms=eval_transforms)
# %%
num_classes = len(train_dataset.labels)
model = pdx.cls.MobileNetV3_small_ssld(num_classes=num_classes)
#%%
model.train(num_epochs=20,
train_dataset=train_dataset,
train_batch_size=32,
eval_dataset=eval_dataset,
lr_decay_epochs=[4, 6, 8],
save_dir='output/mobilenetv3_small_ssld',
use_vdl=True)
# %%
import paddlex as pdx
model = pdx.load_model('output/mobilenetv3_small_ssld/best_model')
result = model.predict('train_paddlex/0/img_0.PNG')
print("Predict Result: ", result)
3、运行之后。。。。。。。。。。。。。。。。。
报错如下:

4、于是跑到paddlex交流群询问了一下报错原因,给出的结果是输入的数据路径有问题。
5、经过一番排查,发现路径完全是对的。我的机器是mac,所以我想有没有可能是系统的原因,于是我把代码拿到linux运行。
6、在linux上是完美运行的,于是可以确定是paddlex对mac不太友好,导致报错
2.测试结果分析
1、每个类别使用200条数据训练,训练集准确率为24%
2、每个类别使用2000条数据训练,训练集准确率为40%
3、测试集准确率为10%
可能的原因:
直接使用文本图片训练文本方向分类器是不对的
四、后续优化方向
1、经过一周的各种优化测试,都没有对ocr识别准确率有大的提升,但目前可以确定的是,转正后的图片识别效果是远高于未转正图片的,因此,后期还是会从方向去突破。
2、考虑用自己的数据训练paddleocr
总结
虽然这一周没有提升ocr的识别效果,但明确了提升ocr识别效果的优化方向,踩了一些坑,也算是一些收获吧。
相关文章:
关于提高PaddleOCR识别准确率的一些优化(一)
关于提高PaddleOCR识别准确率的一些优化(三)