【迁移学习】Prototypical Cross-domain Self-supervised Learning for Few-shot Unsupervised Domain Adaptation
摘要
无监督域适应(UDA)将预测模型从完全标记的源域转移到无标记的目标域。然而,在某些应用程序中,甚至在源域中收集标签都很昂贵,这使得以前的大多数工作都不切实际。为了解决这个问题,最近的工作执行了基于实例的跨领域自我监督学习,然后是一个额外的微调阶段。然而,实例自监督学习只学习和对齐低层次的判别特征。在本文中,我们提出了一个端到端原型跨域自监督学习(PCS)框架用于小样本无监督域适应(FUDA)。PCS不仅对跨域低级特征对齐,而且对跨域共享嵌入空间中的语义结构进行编码和对齐。我们的框架通过域内原型对比学习捕捉数据的类别语义结构;并通过跨领域的原型自我监督进行特征对齐。与目前最先进的方法相比,PCS在FUDA上对不同域对的平均分类精度分别提高了10.5%、3.5%、9.0%和13.2%。
1. Introduction
无监督域自适应(UDA)将预测模型从一个完全标记的源域转移到一个未标记的目标域。虽然在目标域中没有标签信息的情况下具有挑战性,但许多UDA方法利用源域中丰富的显式监督,以及未标记的目标样本进行域对齐,可以在目标域上实现较高的精度。
然而,在一些实际的应用程序中,由于注释的高成本和难度,即使在源域中提供大规模注释也常常具有挑战性。以医学成像为例,糖尿病视网膜病变数据集的每一张图像都由一个由7或8名美国委员会认证眼科医生组成的小组注释,该小组共有54名医生。因此,在实际操作中,假定源数据具有丰富的标签是过于严格的。
在本文中,为了应对源域的标记成本,我们考虑了小样本无监督域自适应(FUDA)设置,其中只有极小部分源样本被标记,而其余的源和目标样本保持未标记。大多数最先进的UDA方法通过最小化某种形式的分布距离来对齐源特征和目标特征,并通过最小化对全标记源域数据的监督损失来学习判别表示。然而,在FUDA中,由于我们的标记源样本数量非常有限,因此很难学习源域中的鉴别特征,更不用说在目标域中了。
最近的几篇关于自监督学习 (SSL) 的论文展示了对来自单个域的图像的有希望的表征学习结果,[39] 进一步扩展到跨两个域执行 SSL,以获得更好的域适应性能。尽管提高了性能,[39] 中的基于实例的方法有一些根本的弱点。首先,数据的语义结构不是由学习到的结构编码的。这是因为 [39] 中的域内自监督将两个实例视为负对,只要它们来自不同的样本,而不管语义相似性如何。因此,许多共享相同语义的实例在特征空间中被不受欢迎地推开。其次,[39] 中的跨域实例到实例匹配对异常样本非常敏感。想象一种情况,其中源样本和目标样本的嵌入相距很远(即域差距很大),并且一个异常源样本比任何其他源样本更靠近所有目标样本。然后 [39] 中的方法会将所有目标样本与相同的源样本匹配(参见图 3)。对于给定的样本,其他域中的匹配样本在训练过程中可能会发生剧烈变化,从而使优化更难收敛。第三,两阶段管道(即 SSL 后跟域适应)很复杂,实验表明不同数据集的最佳 DA 方法是不同的。因此,训练相当繁琐,并且不清楚如何在第二阶段针对不同的数据集选择最优的 DA 方法。
在本文中,我们提出了典型的跨域自监督学习,这是一种新颖的FUDA的单阶段框架,它将表示学习和域对齐与小样本标记的源样本统一起来。PCS包含三个主要组成部分,用于学习区分性特征和域不变特征。首先,PCS执行域内典型自监督,将数据的语义结构隐式编码到嵌入空间中,这是基于[41]的动机,但我们进一步利用任务的已知语义信息,在每个域中学习更好的语义结构。其次,PCS执行跨域实例到原型的匹配,以更健壮的方式将知识从源传输到目标。将一个样本与原型匹配(即对一组语义相似的实例的代表性嵌入)更稳健,使优化收敛速度更快,而不是实例对实例的匹配。第三,PCS将原型学习与余弦分类器相结合,并与源原型和目标原型自适应地更新余弦分类器。从源原型转移到目标原型,以在目标域上获得更好的性能。为了进一步减轻跨域不匹配的影响,我们采用熵最大化的方法来获得更多样化的输出。我们证明,结合熵最小化,这相当于最大化输入图像和网络预测之间的互信息(MI)。贡献:
(1)我们提出了一种新颖的原型跨域自监督学习框架 (PCS),用于少样本无监督域适应。
(2)我们建议利用原型以统一、无监督和自适应的方式执行更好的语义结构学习、判别特征学习和跨域对齐。
(3)虽然很难在复杂的两阶段框架中选择最优域适配方法,但PCS可以很容易地在端到端问题上进行训练,并且在多个基准数据集上以较大的幅度超过所有最先进的方法。
2. Related Work
域自适应。 无监督域自适应(UDA)解决了将知识从一个完全标记的源域转移到一个未标记的目标域的问题。大多数UDA方法都集中在特征分布对齐上。基于差异的方法显式地计算源和目标之间的最大平均差异(MMD),以对齐两个域。[47]提出使用联合MMD准则来对齐联合分布。[63]和[79]进一步提出了对齐源特征和目标特征的二阶统计数据。随着生成对抗网络的发展,还提出了利用对抗学习在特征空间中进行域对齐的方法。最近,已经采用图像平移方法,通过执行像素级对齐来进一步改进域自适应。[60]没有明确的特征调整,提出了适应的极小极大熵。这些方法对源域具有完全的监督,但是我们关注的是一种新的少源标签的自适应设置。
自监督学习。 自监督学习 (SSL) 是无监督学习方法的一个子集,其中监督是从数据中自动生成的。 SSL 最常见的策略之一是手工制作辅助辅助任务来预测未来、缺失或上下文信息。特别是,图像着色、补丁位置预测 、图像拼图 、图像修复和几何变换 已被证明是有帮助的。目前,对比学习在表征学习上取得了最先进的性能。大多数对比方法都是基于实例的,旨在学习一个嵌入空间,其中来自同一实例的样本被拉得更近,而来自不同实例的样本被推开。最近,基于原型的对比学习在表征学习中显示出有希望的结果。
域适应的自监督学习。 基于自监督的方法将 SSL 损失纳入原始任务网络。在一些早期工作中,重建首先被用作自监督任务 ,其中源和目标共享相同的编码器以提取域不变特征。为了同时捕获域特定和共享属性,[5] 明确地将图像表示提取到两个空间中,一个是每个域私有的,另一个是跨域共享的。在 [6] 中,解决拼图游戏 [51] 被用作自监督任务来解决域适应和泛化问题。[64]进一步提出通过联合学习多个自我监督任务来执行适应。特征编码器由源图像和目标图像共享,然后将提取的特征输入到不同的自监督任务头中。最近,基于实例歧视 [72],[39] 提出了一种跨域 SSL 方法,用于适应几乎没有源标签的情况。 SSL 也被用于其他领域的适应,包括点云识别 [1]、医学成像 [33]、动作分割 [9]、机器人 [34]、面部跟踪 [74] 等。
3. Approach
在小样本无监督域适应中,我们得到非常有限数量的标记源图像 D s = { ( x i s , y i s ) } i = 1 N s D_s=\{(x^s_i,y^s_i)\}^{N_s}_{i=1} Ds={(xis,yis)}i=1Ns,以及未标记源图像 D s u = { ( x s u ) } i = 1 N s u D_{su}=\{(x^{su})\}^{N_{su}}_{i=1} Dsu={(xsu)}i=1Nsu。在目标域中,我们只得到未标记的目标图像 D t u = { ( x t u ) } i = 1 N t u D_{tu}=\{(x^{tu})\}^{N_{tu}}_{i=1} Dtu={(xtu)}i=1Ntu。目标是在 D s , D s u , D t u D_s,D_{su},D_{tu} Ds,Dsu,Dtu上训练模型;并在 D t u D_{tu} Dtu上进行评估。
基模型由特征编码器 F F F、 ℓ 2 ℓ_2 ℓ2归一化层,输出归一化特征向量 f ∈ R d f∈\R^d f∈Rd和基于余弦相似度的分类器 C C C组成。

3.1.域内原型对比学习
我们学习了一个共享特征编码器 F F F,它可以在两个域中提取判别特征。在[39]中使用实例判别[72]来学习判别特征。作为一种逐实例对比学习方法,它会产生一个嵌入空间,其中所有实例都很好地分离。尽管取得了可喜的结果,但实例区分有一个根本的弱点:数据的语义结构不是由学习到的表征编码的。这是因为两个实例只要来自不同的样本就被视为负对,而不管它们的语义如何。对于单个域,ProtoNCE提议通过执行迭代聚类和表示学习来学习数据的语义结构。目标是推动同一集群中的特征变得更加聚合,而不同集群中的特征变得更远。
然而,在我们的域自适应设置中,朴素的将ProtoNCE应用于 D s ∪ D s u ∪ D t u D_s \cup D_{su} \cup D_{tu} Ds∪Dsu∪Dtu会导致潜在的问题。主要由于域的转移,来自不同域的不同类的图像可能会被错误地聚合到同一个集群中,而来自不同域的同一类的图像可以被映射到相距很远的集群中。为了缓解这些问题,我们建议在 D s ∪ D s u D_s \cup D_{su} Ds∪Dsu和 D t u D_{tu} Dtu中分别执行原型对比学习。这是防止跨领域的图像聚类和不加区分的特征学习。
具体来说,分别为源和目标维护两个存储 V s V^s Vs和 V t V^t Vt:
![]()
其中 v i v_i vi是 x i x_i xi的存储特征向量,用 f i f_i fi初始化并在每批后用动量 m 更新:

为了进行域内原型对比学习,对 V s V^s Vs和 V t V^t Vt进行 k-means 聚类,得到源集群 C s = { C 1 ( s ) , C 2 ( s ) , … C k ( s ) } C^s=\{C^{(s)}_1, C^{(s)}_2,…C^{(s)}_k\} Cs={C1(s),C2(s),…Ck(s)}和相似的有着正则化源原型 { μ j s } j = 1 k \{{\mu}^s_j\}^k_{j=1} {μjs}j=1k和正则化目标原型 { μ j t } j = 1 k \{{\mu}^t_j\}^k_{j=1} {μjt}j=1k的 C t C^t Ct。具体来说, μ j s = u j s ∣ ∣ u j s ∣ ∣ {\mu}^s_j=\frac{u^s_j}{||u^s_j||} μjs=∣∣ujs∣∣ujs,其中 u j s = 1 ∣ C j ( s ) ∣ ∑ v i s ∈ C j ( s ) v i s u^s_j=\frac{1}{|C^{(s)}_j|}\sum_{v_i^s \in C^{(s)}_j}v_i^s ujs=∣Cj(s)∣1∑vis∈Cj(s)vis。我们只在源j域上解释简洁表示,所有操作都在目标上执行。
在训练过程中,用特征编码器 F F F计算特征向量 f i s = F ( x i s ) f^s_i=F(x^s_i) fis=F(xis)。为了进行域内原型对比学习,我们计算 f i s f^s_i fis和 { μ j s } j = 1 k \{{\mu}^s_j\}^k_{j=1} {μjs}j=1k之间的相似分布向量,公式为 P i s = [ P i , 1 s , P i , 2 s , . . . , P i , k s ] P_i^s=[P_{i,1}^s,P_{i,2}^s,...,P_{i,k}^s] Pis=[Pi,1s,Pi,2s,...,Pi,ks],其中:
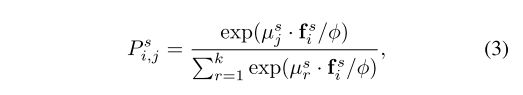
其中φ是确定浓度水平的温度值。则域内原型对比损失可以写为

其中 c s ( ⋅ ) c_s(·) cs(⋅)和 c t ( ⋅ ) c_t(·) ct(⋅)返回实例的集群索引。由于聚类的随机性,我们对不同聚类数量 { k m } m = 1 M \{k_m\}^M_{m=1} {km}m=1M的样本执行M次k-means。此外,在FUDA设置中,由于类 n c n_c nc的数量是已知的,所以我们为大多数m设置了 k m = n c k_m=n_c km=nc。域内部自监督的总体损失为:

3.2. Cross-domain Instance-Prototype SSL
为了在源域和目标域中明确地强制执行学习域对齐和更具区别性的特征,我们执行了跨域实例-原型自监督学习。
许多以前的工作都集中在通过差异最小化或对抗性学习来进行的领域对齐上。然而,这些方法的表现较差或训练不稳定。此外,它们大多集中于分布匹配,而没有考虑跨域的语义相似性匹配。提出了实例-实例匹配[39]来将一个实例 i 与另一个域中的另一个实例 j 进行匹配。但是,由于域间隙,实例可以很容易地映射到其他域中的不同类的实例。在某些情况下,如果一个域中的一个异常值非常接近另一个域,那么它将与另一个域中的所有实例相匹配,如图3所示。
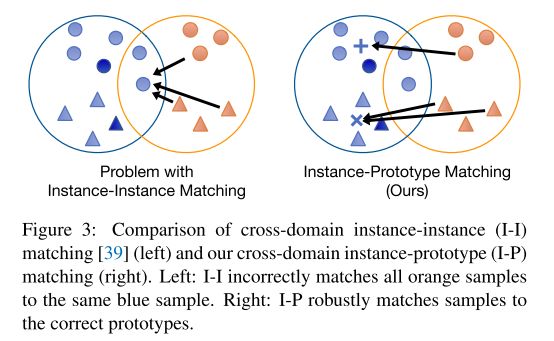
相反,我们的方法发现了不同域中实例和集群原型之间的正匹配和负匹配。为了找到实例 i 的匹配,我们对其表示之间的相似性分布向量执行熵最小化,例如 f i s f^s_i fis和另一个域的质心 { μ j t } j = 1 k \{{\mu}^t_j\}^k_{j=1} {μjt}j=1k。
具体来说,给定源域的特征向量 f i s f^s_i fis,目标域的质心 { μ j t } j = 1 k \{{\mu}^t_j\}^k_{j=1} {μjt}j=1k,首先计算目标域的相似度分布向量 P i s → t = [ P i , 1 s → t , … , P i , k s → t ] P^{s→t}_i=[P^{s→t}_{i,1},…,P^{s→t}_{i,k}] Pis→t=[Pi,1s→t,…,Pi,ks→t],其中

然后我们最小化 P i s → t P^{s→t}_i Pis→t的熵,即:

类似地,我们可以计算 H ( P i t → s ) H(P^{t→s}_i) H(Pit→s),跨域实例-原型SSL的最终损失是:

3.3. Adaptive Prototypical Classifier Learning
本节的目标是学习一个更好的域对齐、判别性特征编码器 F F F,更重要的是,学习一个可以在目标域上实现高精度的余弦分类器 C C C。
余弦分类器 C 由权重向量 W = [ w 1 , w 2 , . . . , w n c ] W = [w_1,w_2, . . . ,w_{n_c}] W=[w1,w2,...,wnc],其中 n c n_c nc表示类别总数和温度T。C的输出, 1 T W T f \frac{1}{T}W^Tf T1WTf被送入 softmax 层 σ σ σ 以获得最终概率输出 p ( x ) = σ ( 1 T W T f ) p(x) = σ(\frac{1}{T}W^Tf) p(x)=σ(T1WTf)。随着标记集 D s D_s Ds的可用性,使用标准交叉熵损失训练 F F F和 C C C进行分类很简单:
![]()
然而,由于 D s D_s Ds在FUDA设置下规模相当小,只有 L c l s L_{cls} Lcls训练很难在目标上获得高性能的分类器 C C C。
自适应原型分类器更新 (APCU)。 请注意,为了让 C 正确分类样本,权重向量 w i w_i wi的方向需要代表相应类别 i i i的特征。这表明 w i w_i wi的含义与类 i i i的理想集群原型一致。我们建议使用对理想集群原型的估计来更新 W W W。 然而,计算出的 { u j s } \{u^s_j\} {ujs}和 { u j t } \{u^t_j\} {ujt}不能直接地用于此目的,不仅因为 { w i } \{w_i\} {wi}和 { u j } \{u_j\} {uj}之间的对应关系是未知的,而且 k-means 结果可能包含非常不纯的集群,导致不具有代表性的原型。
我们使用小样本标记的数据以及具有高置信度预测的样本来估计每个类的原型。正式上,我们定义 D s ( i ) = { x ∣ ( x , y ) ∈ D s , y = i } D^{(i)}_s=\{x|(x,y)∈D_s,y=i\} Ds(i)={x∣(x,y)∈Ds,y=i},并用 D s u ( i ) D^{(i)}_{su} Dsu(i)和 D t u ( i ) D^{(i)}_{tu} Dtu(i)分别表示在源和目标上具有高置信标签 i 的样本集。 p ( x ) = [ p ( x ) 1 , … , p ( x ) n c ] , D s u ( i ) = { x ∣ ( x , y ) ∈ D s u , p ( x ) i > t } p(x)=[p(x)_1,…,p(x)_{n_c}],D^{(i)}_{su}=\{x|(x,y)∈D_{su},p(x)_i > t\} p(x)=[p(x)1,…,p(x)nc],Dsu(i)={x∣(x,y)∈Dsu,p(x)i>t},其中 t t t是一个置信阈值, D t u ( i ) D^{(i)}_{tu} Dtu(i)相似。然后从源域和目标域的 w i w_i wi估计可以计算为:

其中, D s + ( i ) = D s ( i ) ∪ D s u ( i ) D^{(i)}_{s+}=D^{(i)}_s \cup D^{(i)}_{su} Ds+(i)=Ds(i)∪Dsu(i)和 V ( x ) V(x) V(x)返回内存库中对应于 x x x的表示形式。
由于源中只有很少的标记样本,因此很难学习跨域共享的代表性原型。我们没有直接为类 i i i使用全局原型,而是进一步建议以域自适应方式更新 w i w_i wi,在早期训练阶段使用 w ^ i s \hat{w}^s_i w^is,在后期使用 w ^ i t \hat{w}^t_i w^it。这是因为 w ^ i s \hat{w}^s_i w^is在早期训练阶段更加稳健,因为标记的源样本很少,而 w ^ i t \hat{w}^t_i w^it将在以后更能代表目标域以获得更好的适应性能。具体来说,我们使用 ∣ D t u ( i ) ∣ |D^{(i)}_{tu}| ∣Dtu(i)∣确定 w ^ i t \hat{w}^t_i w^it是否稳健使用:

其中, u n i t ( ⋅ ) unit(\cdot) unit(⋅)将输入向量归一化, t w t_w tw是一个阈值超参数。
互信息最大化。 为了使上述统一原型分类器学习范式能够正常工作,网络需要有足够可靠的预测,例如 ∣ D ( i ) ∣ > t w |D^{(i)}| > t_w ∣D(i)∣>tw,对于所有类,获得稳健的 w ^ i s \hat{w}^s_i w^is和 w ^ i t \hat{w}^t_i w^it, i = 1 , . . . , n c i=1,...,n_c i=1,...,nc。首先,为了促进网络在数据集上的多样化输出,我们最大化了预期网络预测 H ( E x ∈ D [ p ( y ∣ x ; θ ) ] ) \mathcal{H}(E_{x∈D}[p(y|x;θ)]) H(Ex∈D[p(y∣x;θ)])的熵,其中 θ θ θ表示 F F F和 C C C中的可学习参数,以及 D = D s ∪ D s u ∪ D t u D=D_s \cup D_{su} \cup D_{tu} D=Ds∪Dsu∪Dtu。其次,为了对每个样本进行高置信的预测,我们利用了网络输出的熵最小化,这在标签稀缺的场景中显示出了有效性。这两种期望的行为等价于最大化输入和输出之间的互信息:
![]()
其中,先验分布 p 0 p_0 p0由 H ( E x ∈ D [ p ( y ∣ x ; θ ) ] ) \mathcal{H}(E_{x∈D}[p(y|x;θ)]) H(Ex∈D[p(y∣x;θ)])给出,详细的推导结果见补充材料。我们可以实现以下目标:

3.4. PCS Learning for FUDA
PCS学习框架执行域内原型对比学习、跨域实例原型自监督学习和统一的自适应原型分类器学习。连同Eq.11中的APCU,总体学习目标是:

4. Experiments
4.1. Experimental Setting
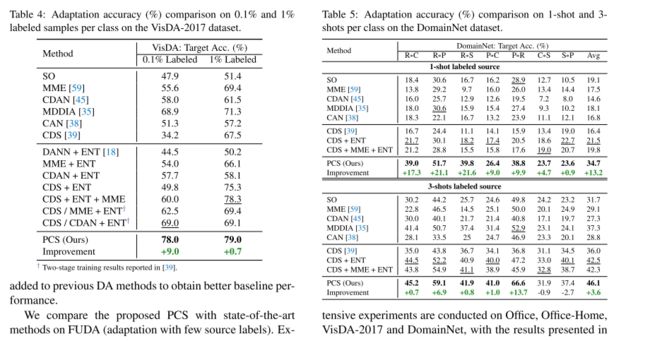
数据集。 我们在四个公共数据集上评估了我们的方法,并在之前的工作[39]的基础上选择了源域中的标记图像。Office[58]是一个用于领域自适应任务的真实数据集。它包含3个域(亚马逊,DSLR,网络摄像头),有31个类。实验在该数据集中,每个类使用1次和3次的源标签进行。Office-Home[69]是一个比Office更困难的数据集,它由65个类中的4个领域(艺术、剪纸艺术、产品、真实)组成。在[39]之后,我们查看每个类有3%和6%标记源图像的设置,这意味着每个类平均有2到4个标记图像。VisDA-2017[55]是一个具有挑战性的模拟到真实的数据集,包含跨12个类的超过280K张图像。根据[39]的建议,我们对每个类使用0.1%和1%标记源图像的源图像设置验证了我们的模型。域网[54]是一个大规模的领域自适应基准。由于一些域和类是有噪声的,我们遵循[59],并使用一个包含四个域(剪纸艺术、真实、绘画、素描)的子集和126个类。我们在这个数据集上显示了使用1次和3次源标签设置的结果。


实现细节。 我们使用在ResNegeNet上预训练的(用于域网)的ResNet-101和ResNet-50(用于其他数据集)作为我们的骨干。为了与[39]进行公平的比较,我们将最后一个FC层替换为一个512-D随机初始化的线性层。对输出特征进行L2归一化处理。我们在快速[37]中使用k-means GPU实现来实现有效的聚类。我们使用SGD,动量为0.9,学习率为0.01,批处理大小为64。更多的实施细节可以在补充材料中找到。


5. Conclusion
在本文中,我们研究了源域只有少数标记样本,目标域没有标记样本的小样本无监督域适应。我们提出了一种新的原型跨域自监督学习(PCS)框架,该框架可以同时执行域内和跨域原型自监督学习,以及自适应原型分类器学习。我们在多个基准数据集上进行了大量的实验,证明了PCS优于以往的最佳方法。PCS为小样本无监督领域自适应设定了一种新的技术状态。