自然语言处理入门(何晗):第一章
第一章 新手上路
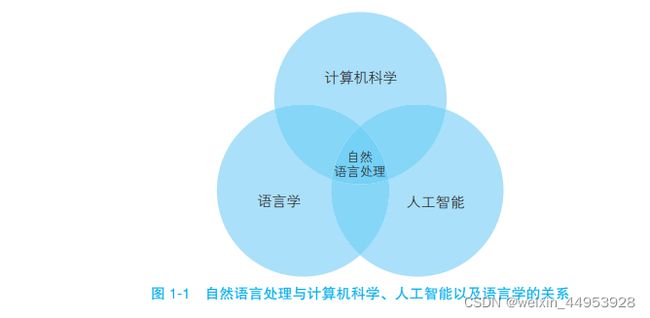
**自然语言处理(NLP)**是一门融合了计算机科学、人工智能以 及语言学的交叉学科,
这门学科研究的是如何通过机器学习等技术, 让计算机学会处理人类语言,乃至实现终极目标——理解人类语言或人工智能
1.1 自然语言与编程语言
1.1.1 词汇量
自然语言中的词汇比编程语言中的关键词丰富,我们还可以随时创造各种类型的新词
自然语言中的词汇比编程语言中的关键词丰富。
1.1.2 结构化
自然语言是非结构化的,而编程语言是结构化的
自然语言是非结构化的,而编程语言是结构化的。所谓结构化,指的是信息具有明确的结构关系,比如编程语言中的类与成员、数据库中的表与字段,都可以通过明确的机制来读写。
苹果 的 创始人 是 乔布斯 ,它 的logo是 苹果
1.1.3 歧义性
自然语言含有大量歧义,这些歧义根据语境的不同而表现为特定的义项。比如汉语中的多义词,只有在特定的上下文中才能确定其含义,甚至存在故意利用无法确定的歧义营造幽默效 果的用法。除了上文“苹果”的两种意思之外,“意思”这个词也有多种意义。
但在编程语言中,则不存在歧义性#。如果程序员无意中写了有歧义的代码,比如两个函数 的签名一样,则会触发编译错误
1.1.4 容错性
自然语言错误随处可见,而编程语言错误会导致编译不通过
1.1.5 易变性
自然语言变化相对迅速嘈杂一些,而编程语言的变化要缓慢得多
1.1.6 简略性
自然语言往往简洁、干练,而编程语言就要明确定义
由于说话速度和听话速度、书写速度和阅读速度的限制,人类语言往往简洁、干练。我们 经常省略大量背景知识或常识,比如我们会对朋友说“老地方见”,而不必指出“老地方”在哪 里。
1.2 自然语言处理的层次
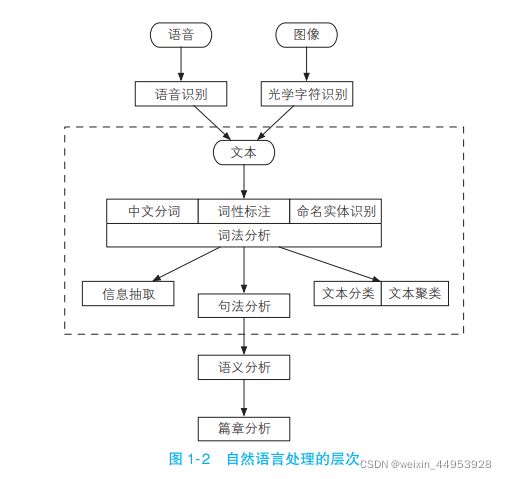
1.2.1 语音、图像和文本
自然语言处理系统的输入源一共有 3 个,即语音(语音识别)、图像(光学字符识别)与文本。
语音经过语音识别,图像经过光学字符识别,转换成文本。
1.2.2 中文分词、词性标注和命名实体识别
这 6 个任务都是围绕词语进行的分析,所以统称词法分析
- 中文分词:词法分析的主要任务是将文本 分隔为有意义的词语
- 词法标注:确定每个词语的类别和浅层的歧义消除
- 命名实体识别:识别出一些较长的专有名词
对中文而言,词法分析常常是后续高级任务的基础
1.2.3 信息抽取
高频词、关键词、公司名称、专业术语等等。
词法分析之后,文本已经呈现出部分结构化的趋势,根据分析出来的每个单词和附有自己词性及其他标签的数据,抽取出一部分有用的信息,关键词、专业术语等,也可以根据统计学信息抽取出更大颗粒度的文本。
1.2.4 文本分类与文本聚类
将文本拆分为一系列词语之后,我们还可以在文章级别做一系列分析
有时我们想知道一段话是褒义还是贬义的,判断一封邮件是否是垃圾邮件,想把许多文档 分门别类地整理一下,此时的 NLP的任务称作文本分类
另一些时候,我们只想把相似的文本归档到一起,或者排除重复的文档,而不关心具体类 别,此时进行的任务称作文本聚类
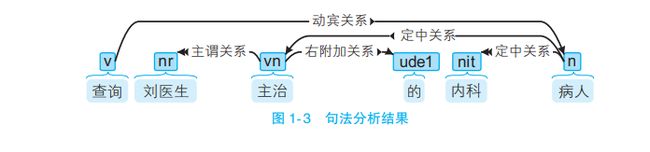
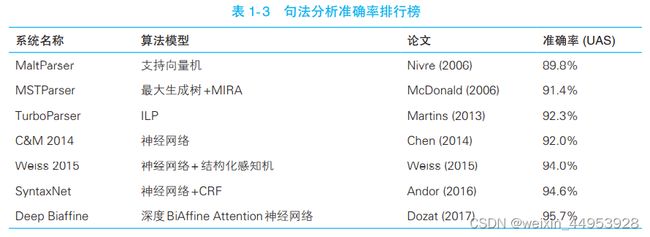
1.2.5 句法分析
词法分析只能得到零散的词汇信息,计算机不知道词语之间的关系。在一些问答系统中, 需要得到句子的主谓宾结构。
1.2.6 语义分析与篇章分析
相较于句法分析,语义分析侧重语义而非语法。
它包括词义消歧(确定一个词在语境中的 含义,而不是简单的词性)、语义角色标注(标注句子中的谓语与其他成分的关系)乃至语义分析(分析句子中词语之间的语义关系)。
1.2.7 其他高级任务
除了上述“工具类”的任务外,还有许多综合性的任务,与终端应用级产品联系更紧密。比如:
- 自动问答,根据知识库或文本中的信息直接回答一个问题,比如微软的 Cortana 和苹果的 Siri
- 自动摘要,为一篇长文档生成简短的摘要;
- 机器翻译,将一句话从一种语言翻译到另一种语言。
注意,一般认为信息检索(IR)是区别于自然语言处理的独立学科。虽然两者具有密切的联系,但 IR的目标是查询信息,而 NLP的目标是理解语言。此外,IR 检索的未必是语言,还可以是以图搜图、听曲搜曲、商品搜索乃至任何信息的搜索。现实中还存 在大量不需要理解语言即可完成检索任务的场景,比如SQL中的 LIKE
1.3 自然语言处理的流派
1.3.1 基于规则的专家系统(难扩展)
规则,指的是由专家手工制定的确定性流程。专家系统要求设计者对所处理的问题具备深入的理解,并且尽量以人力全面考虑所有可能的情况。它最大的弱点是难以拓展。当规则数量增加或者多个专家维护同一个系统时,就容易出现冲突。
1.3.2 基于统计的学习方法
人们使用统计方法让计算机自动学习语言。所谓“统计”,指的是在语料库上进行的统计。所谓“语料库”,指的是人工标注的结构化文本。
统计学习方法其实是机器学习的别称,而机器学习则是当代实现人工智能的主要途径。
1.3.3 历史

1.3.4 规则与统计
1.3.5 传统方法与深度学习
1.4 机器学习
1.4.1 什么是机器学习
人工智能领域的先驱在 1959年给出的机器学习定义是:不直接编程却能赋予计算机提高能力的方法。
机器学习指的是计算机通过某项任务的经验数据提高了在该项任务上的能力
简而言之,机器学习是让机器学会算法的算法。
机器学习算法则可以称作“元算法”,它指导机器自动学习出另一个算 法,这个算法被用来解决实际问题。为了避免混淆,人们通常称被学习的算法为模型
1.4.2 模型

1.4.3 特征
特征指的是事物的特点转化的数值,比如牛的特征是 34条腿、0双翅膀,而鸟的特征是 2条腿、1双翅膀。
- 特征指的是事物的特点转化的数值。
- 如何挑选特征,如何设计特征模板,这称作特征工程。特征越多,参数就越多;参数越多,模型就越复杂。
1.4.4 数据集


1.4.5 监督学习

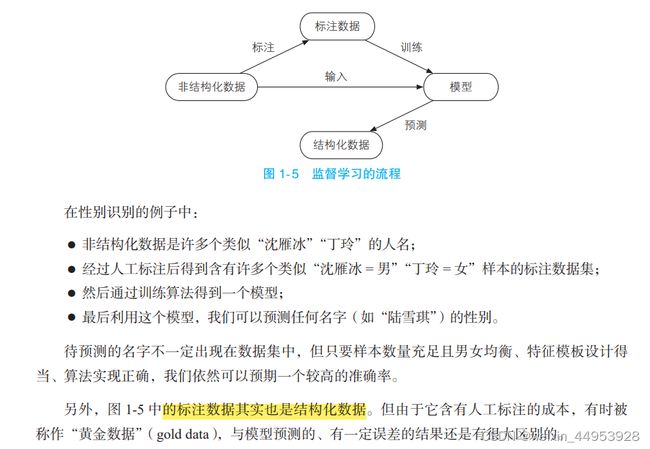
1.4.6 无监督学习
如果我们只给机器做题,却不告诉它参考答案,机器仍然可以学到知识吗?
可以,此时的学习称作无监督学习,而不含标准答案的习题集被称作无标注的数据集。
无监督学习一般用于聚类和降维,两者都不需要标注数据。
j降维指的是将样本点从高维空间变换到低维空间的过程。
1.4.7 其他类型的机器学习算法
如果我们训练多个模型,然后对同一个实例执行预测,会得到多个结果。如果这些结果 数一致,则可以将该实例和结果放到一起作为新的训练样本,用来扩充训练集。这样的算法被称为半监督学习。由于半监督学习可以综合利用标注数据和丰富的未标注数据,所以正在成为 热门的研究课题。
现实世界中的事物之间往往有很长的因果链:我们要正确地执行一系列彼此关联的决策, 才能得到最终的成果。这类问题往往需要一边预测,一边根据环境的反馈规划下次决策。这类算法被称为强化学习习。强化学习在一些涉及人机交互的问题上成果斐然,比如自动驾驶、电子 竞技和问答系统。
- 半监督学习:如果我们训练多个模型,然后对同一个实例执行预测,会得到多个结果。如果这些结果多数一致,则可以将该实例和结果放到一起作为新的训练样本,用力啊扩充训练集。这样的算法被称为半监督学习。
- 强化学习:现实世界中的事物之间往往有很长的因果链:我们要正确地执行一系列彼此关联的决策,才能得到最终的成果。这类问题往往需要一边预测,一边根据环境的反馈规划下次决策。这类算法被称为强化学习。
1.5 语料库
语料库作为自然语言处理领域中的数据集,是我们教机器理解语言不可或缺的习题集。在 这一节中,我们来了解一下中文处理中的常见语料库,以及语料库建设的话题
1.5.1 中文分词语料库
中文分词语料库指的是,由人工正确切分后的句子集合。
以著名的1998年《人民日报》语料库为例:
先 有 通货膨胀 干扰,后 有 通货 紧缩 叫板。
1.5.2 词性标注语料库
它指的是切分并为每个词语指定一个词性的语料
依然以《人民日报》语料库为例:
迈向/v 充满/v 希望/n 的/u 新/a 世纪/n --/w 一九九八年/t 新年/t 讲话/n
1.5.3 命名实体识别语料库
这种语料库人工标注了文本内部制作者关心的实体名词以及实体类别。比如《人民日报》语料库中-共含有人名、地名和机构名3种命名实体:
萨哈夫/nr 说/v ,/w 伊拉克/ns 将/d 同/p [联合国/nt 销毁/v 伊拉克/ns 大规模/b 杀伤性/n 武器/n 特别/a 委员会/n] /nt 继续/v 保持/v 合作/v 。/w
这个句子中的加粗词语分别是人名、地名和机构名。中括号括起来的是复合词,我们可以观察到:有时候机构名和地名复合起来会构成更长的机构名,这种构词法上的嵌套现象增加了命名实体识别的难度。
1.5.4 句法分析语料库
汉语中常用的句法分析语料库有CTB(Chinese Treebank,中文树库),其中一个句子可视化后如下图所示:
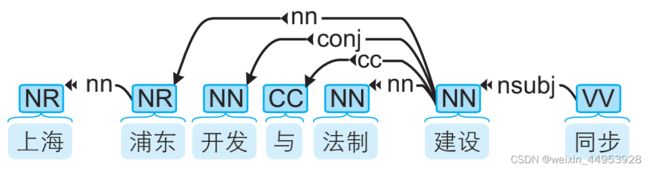
中文单词上面的英文标签标示词性,而箭头表示有语法联系的两个单词,具体是何种联系由箭头上的标签标示。
1.5.5 文本分类语料库
它指的是人工标注了所属分类的文章构成的语料库。
1.5.6 语料库建设
语料库建设指的是构建一份语料库的过程,分为规范制定、人员培训与人工标注这 3个阶段。
针对不同类型的任务,人们开发出许多标注软件,其中比较成熟的一款是brat,它支持词性标注、命名实体识别和句法分析等任务。
1.6 开源工具
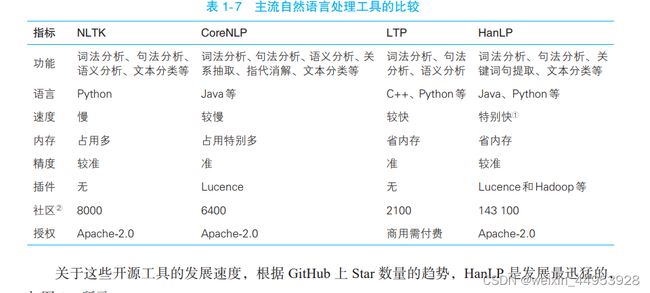
目前开源界贡献了许多优秀的 NLP 工具,它们为我们提供了多种选择,比如教学常用的NLTK ( Natural Language Toolkit )、斯坦福大学开发的CoreNLP,以及国内哈工大开发的 LTP ( Language Technology Platform )、我开发的HanLP ( Han Language Processing )。
1.6.1 主流 NLP 工具比较
选择一个工具包,我们需要考虑的问题有:功能、精度、运行效率、内存效率、可拓展性、商业授权和社区活跃程度。
1.6.2 Python 接口
得益于Python简洁的设计,使用这门动态语言调用HanLP会省下不少时间。无论用户是否常用Python,都推荐一试。
HanLP的 Python接口由 pyhanlp包提供,其安装只需一句命令:
pip install pyhanlp
1.7 总结
本章给出了人工智能、机器学习与自然语言处理的宏观缩略图与发展时间线。机器学习是人工智能的子集,而自然语言处理则是人工智能与语言学、计算机科学的交集。这个交集虽然小,它的难度却很大。为了实现理解自然语言这个宏伟目标,人们尝试了规则系统,并最终发展到基于大规模语料库的统计学习系统。
在接下来的章节中,就让我们按照这种由易到难的发展规律去解决第一个NLP问题一中文分词。我们将先从规则系统人手,介绍一些快而不准的算法,然后逐步进化到更加准确的统计模型。
1.8 GitHub项目
HanLP何晗–《自然语言处理入门》笔记:
https://github.com/NLP-LOVE/Introduction-NLP