FCOS详解S:FullyConvolutionalOne-StageObjectDetection
这玩意和基于anchor的有异曲同工之处,anchor-based是一个点对应n个anchor,而这玩意是每一个点对应一个box。
训练时:
基于anchor的方法是在featuremap的每一个点上产生anchor,然后将anchor映射回原图求gt与anchor的iou,大于一定阈值就认为是正样本,进行gt与anchor的坐标偏移回归,并且进行分类的训练。而这玩意是对于featuremap上的每一个点,将其映射回原图,如果其在gt内,则是正样本,进行外接矩形的
回归,否则就是负样本,不进行坐标回归。对于每一个点还要进行分类的训练。
测试时:
基于anchor的方法是进行前向传播,对于featuremap上的每一个点,其都有五个预测值,四个是anchor的偏移值,一个是类别值,将其对应的anchor映射回原图,根据偏移值求其anchor偏移后的box即为预测值,由类别值得到该box的类别。而这玩意也是先进行前向传播,对于featuremap上的每一个点,其都有五个预测值,四个是
一.概述
目标检测算法以前主要分为两个大的方向:单阶段检测器/双阶段检测器,其对应的代表性算法分别是Faster-rcnn和Yolo。而随着目标检测性能的大幅度提升,这个领域的门槛变得很高,仅有很少的大佬们仍然在探索着新的检测算法。其实对于目标检测而言,我们还可以按照其它的类别进行划分,即所谓的基于anchor和anchor-free的算法,而本文其实就属于单阶段的anchor-free目标检测算法。
先来聊一聊为什么要去掉anchor。众所周知,anhcor的引入对目标检测算法的效果提升帮助很大,这也是为什么最近几年流行的目标检测算法基本上都是基于anchor来预测目标框位置的。但是显然anchor的引入也带来一些问题,最主要的有2点:
- 超参数较多。这些超参数包括anchor的尺寸、数量、确定正负样本的IOU阈值等等,不同的超参数对检测结果都有一定影响,而调参显然是比较麻烦的工作。当然,关于超参数方面也诞生了一些有意思的作品,比如YOLO v2的anchor聚类、RefineDet的anchor refine等,都是为了提供更准确的anchor。
- 正负样本不均衡。因为一张图像中目标数量是有限的,为了达到足够的召回率,anchor数量一般要铺设比较多,这就导致负样本要远远多于正样本,虽然大部分目标检测算法有类似负样本欠采样等步骤做过滤,但都不能算是从根本上解决正负样本不均衡的问题。
- detection performance is sensitive to the sizes, aspect ratios and number of anchor boxes
- Even with careful design, because the scales and aspect ratios of anchor boxes are kept fixed,detectors encounter difficulties to deal with object can didateswithlargeshapevariations,particularly for small objects. The pre-defined anchor boxes also hamper the generalization ability of detectors, as they need to be re-designed on new detection tasks with different object sizes or aspect ratios.
- In order to achieve a high recall rate, an anchor-based detector is required to densely place anchor boxes on the input image (e.g., more than180K anchor boxes in feature pyramid networks(FPN) for an image with its shorter side being 800). Most of these anchor boxes are labelled as negative samples during training. The excessive number of negative samples aggravates the imbalance between positive and negative samples in training.
- Anchor boxes also involve complicated computation such as calculating the intersection-over-union (IoU) scores with ground-truth bounding boxes.
作者为什么要提出anchor-free算法FCOS呢,主要的原因如下所示:
- anchor会引入很多需要优化的超参数, 比如anchor number、anchor size、anchor ratio等;
- 为了保证算法效果,需要很多的anchors,存在正负样本类别不均衡问题;
- 在训练的时候,需要计算所有anchor box同ground truth boxes的IoU,计算量较大;
FCOS属于anchor-free类别的算法,且效果在anchor-free派系中算SOTA了。它的主要优点如下:
- 因为输出是pixel-based预测,所以可以复用semantic segmentation方向的相关tricks;
- 可以修改FCOS的输出分支,用于解决instance segmentation和keypoint detection任务;
先来聊一聊为什么要去掉anchor。众所周知,anhcor的引入对目标检测算法的效果提升帮助很大,这也是为什么最近几年流行的目标检测算法基本上都是基于anchor来预测目标框位置的。但是显然anchor的引入也带来一些问题,最主要的有2点:1、超参数较多。这些超参数包括anchor的尺寸、数量、确定正负样本的IOU阈值等等,不同的超参数对检测结果都有一定影响,而调参显然是比较麻烦的工作。当然,关于超参数方面也诞生了一些有意思的作品,比如YOLO v2的anchor聚类、RefineDet的anchor refine等,都是为了提供更准确的anchor。2、正负样本不均衡。因为一张图像中目标数量是有限的,为了达到足够的召回率,anchor数量一般要铺设比较多,这就导致负样本要远远多于正样本,虽然大部分目标检测算法有类似负样本欠采样等步骤做过滤,但都不能算是从根本上解决正负样本不均衡的问题。这或许就是研究anchor free的目标检测算法的原因,FOCS也是其中之一。
This new detection framework enjoys the following advantages
- Detection is now unified with many other FCNsolvable tasks such as semantic segmentation, making it easier to re-use ideas from those tasks.
- Detection becomes proposal free and anchor free, which significantly reduces the number of design parameters. The design parameters typically need heuristic tuning and many tricks are involved in order to achieve good performance. Therefore, our new detection framework makes the detector, particularly its training, considerably simpler.
- By eliminating the anchor boxes, our new detector completely avoids the complicated computation related to anchor boxes such as the IOU computation and matching between the anchor boxes and ground-truth boxes during training, resulting in faster training and testing as well as less training memory footprint than its anchor-based counterpart.
- Without bells and whistles, we achieve state-of-theart results among one-stage detectors. We also show that the proposed FCOS can be used as a Region Proposal Networks (RPNs) in two-stage detectors and can achieve significantly better performance than its anchor-basedRPN counterparts. Given the even better performance of the much simpler anchor-free detector, we encourage the community to rethink the necessity of anchor boxes in object detection, which are currently considered as the de facto standard for detection.
- The proposed detector can be immediately extended to solve other vision tasks with minimal modification, including instance segmentation and key-point detection. We believe that this new method can be the new baseline for many instance-wise prediction problems.
二.详解
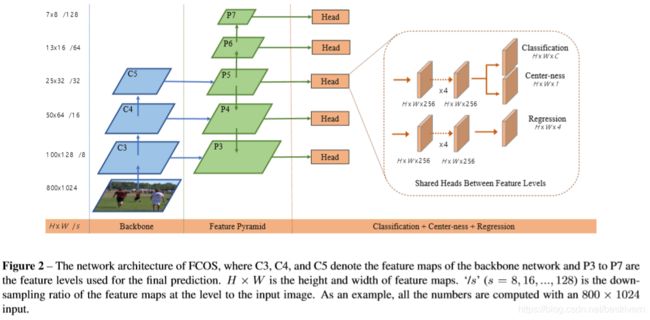
整体的思想如下就是使用per-pixel的方法去进行目标检测:
- 使用多种尺度的预测去提升recall和解决ambiguity resulted from overlapped bounding boxes.
- 使用center-ness分支去压缩低质量的检测框,极大的提升了整体表现。
1.全卷积one-stage目标检测器
:the feature maps at layer i of a backbone CNN
s:be the total stride until the layer.
输入图像的gt:![]()
对于 上的每一个点(x,y),其在输入图像上的点为
上的每一个点(x,y),其在输入图像上的点为![]() ,在(x,y)的感受野中心的附近。基于anchor的目标检测器回归的是该点中心所在的anchor,而FCOS回归的是该点的bbox。
,在(x,y)的感受野中心的附近。基于anchor的目标检测器回归的是该点中心所在的anchor,而FCOS回归的是该点的bbox。
点(x,y)在gt box里面,则其是一个正样本,c=ci。否则是一个负样本,c=0。每一个点的回归包含以下两部分:
1.类别标签
2.![]()
如果一个点同时落入多个gt当中,则其为一个ambiguous sample。选择area最小的区域作为回归的gt目标。
如果一个位置(x,y)与一个bbox相关,则其具体的回归过程如下:

FCOS可以利用尽可能多的正样本来训练回归。anchor-based的检测方法将与gt的iou超过一定阈值的作为正样本,存在很严重的正负样本不均衡的问题。
网络的输出
网络的输出是一个80维的类别输出和一个4维的坐标输出。我们训练了40个二分类器而不是一个80类别的分类器。在backbone之后增加了4个卷积层,用于构建分类和回归分支。因为![]() 这4个值都是正的,所以为了保证回归支路的输出结果都是正,回归支路的输出会通过exp()函数再输出,exp()函数输入是负无穷到正无穷,输出大于0。所以在进入到回归分支之前先用exp(x)将x映射到0-正无穷。
这4个值都是正的,所以为了保证回归支路的输出结果都是正,回归支路的输出会通过exp()函数再输出,exp()函数输入是负无穷到正无穷,输出大于0。所以在进入到回归分支之前先用exp(x)将x映射到0-正无穷。
loss函数

该loss函数如上图所示,同样包含两部分,Lcls表示分类loss,本文使用的是Focal_loss;Lreg表示回归loss,本文使用的是IOU loss。其实这两个loss应当是当前最好的配置啦。
inference过程
输入一张图像,经过网络前向传播,对于featuremap上的每一个点都获得一个分类的分数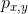 和回归的预测结果
和回归的预测结果 ,当>0.05时,就认为这个点是一个正样本,就将它映射回原图进行获得预测的bounding box。
,当>0.05时,就认为这个点是一个正样本,就将它映射回原图进行获得预测的bounding box。
2.多尺度的FPN for FCOS可以解决两个问题:
1.最后一个featuremap的stride较大会导致相对较低的BPR,对于基于anchor的方法来讲,降低正样本的iou阈值会提升BPR,对于FCOS来讲,如果stride较大,可能导致最后的featuremap上没有目标,这样肯定没办法召回该目标,使得BPR较低,但是多尺度训练可以解决该问题,并实现和anchor-based RetinaNet达到类似的BPR。
2.由于gt的overlapping导致的ambiguity问题,这是所有基于FCN的检测器都会遇到的问题,但是可以被很好的解决通过多尺度预测。如下图所示:

多尺度的预测是在p3,p4,p5,p6,p7这几个featuremap上完成的。p3,p4,p5是在backbone的conv层产生的,是通过c3,c4,c5这三层,在其上加上1×1卷积和top-down连接完成的。在p5上stride=2卷积产生p6,在p6上面stride=2卷积产生p7,所以p3,p4,p5,p6,p7的stride=8,16,32,64和128。
并不是每一个点的预测都是有效的:
对于每一个level的featuremap,m2,m3,m4,m5,m6,m7的值分别为0,64,128,256,512,正无穷。
当![]() 或者
或者![]() 时,将这个点视为一个负样本,不参与回归。然后对于重叠的预测box,选择area最小的那个预测结果。
时,将这个点视为一个负样本,不参与回归。然后对于重叠的预测box,选择area最小的那个预测结果。
我们这里共享所有的检测head,这种共享可以提升检测的表现,但是对于每一个尺度水平,我们希望他预测不同尺度的box,所以我们这里对于的结果用![]() 处理,这里的si是一个可以学习的参数,这样就可以共享一个检测head,但是也可以实现不同尺度的预测了,这样也可以显著提升检测结果。
处理,这里的si是一个可以学习的参数,这样就可以共享一个检测head,但是也可以实现不同尺度的预测了,这样也可以显著提升检测结果。
3.Center-ness for FCOS
在经过多尺度的预测之后,FCOS和基于anchor的方法的效果之间仍然存在一个gap,我们观察到这是由于那些离目标中心很远的点产生了很多低质量的box而导致的。这里用了一种高效的方法去压缩box,用了一个和分类层并行的single layer,这个层预测一个center-ness,这个center-ness反映了该点预测的box与目标之间的归一化距离。

这里用开方去减缓centerness的衰减,其值位于0-1之间,训练时采用交叉熵损失(BCE Loss)。
当检测的时候,score=centerness*classification_score,这个最终的score用来对于检测到的box进行排序,这个centerness可以降低远离目标中心的box的权重。经过这个centerness的down-weight作用,最后再经过NMS处理,可以显著提升最终的检测效果。
centerness的另外一种选择就是仅仅将gt的中心部分对应的featuremap上的那些点作为正样本。
center-ness其实是BB以一个点分开的四块,最小的面/最大的面积,再开方,如果该点越贴近BB的中心,那么值越趋向于1,换言之,离中心点越远,这个值越小,从而让cls的scores跟center-ness想乘得到最终的score,降低离中心点较远的那些点的得分,再进行NMS
三.实验结果
training details:
1.backbone时ResNet50,且参数和RetinaNet一样
2.SGD,90k iterations,initial learning_rate=0.01,batch_size=16
3.60K iteration时,learning_rate=0.001,80K iteration时,learning_rate=0.0001
4. Weight decay = 0.0001,momentum=0.9
5.the input images are resized to have their shorter side being 800 and their longer side less or equal to 1333.
Inference Details:
the same as RetinaNet
1.AblationStudy
Multi-levelPredictionwithFPN
基于FCN的目标检测器都存在一个问题就是由于ground truth的重叠会导致低的recall和难分样本。而这些问题可以由多尺度的预测解决。
Best Possible Recalls
Here BPR is defined as the ratio of the number of ground-truth boxes a detector can recall at the most divided by all ground-truth boxes。那具体计算的时候怎么做呢?A ground-truth box is considered being recalled if the box is assigned to at least one sample (i.e., a location in FCOS or an anchor box in anchor-based detectors) during training。
可以看到FCOS的BPR比RetinaNet低一些,但是作者说了:Due to the fact that the best recall of current detectors are much lower than 90%, the small BPR gap(lessthan1%)betweenFCOSandtheanchor-baseddetector will not actually affect the performance of detector 。其也可以由下表证明:


Ambiguous Samples
BPR表明多尺度的预测极大的降低了missed的目标数量,并且FCOS采用选择最小区域匹配的原则,所以理论上可能会导致丢失一些较大的目标,但是后续的实验表明这并不会使得我们的性能低于anchor-based的检测器。

With or Without Center-ness
center-ness可以压缩那些由目标边缘所产生的低质量的检测框,并且这个center-ness分支可以将AP从33.5提升到37.1,超过了RetinaNet的35.9。RetinaNet有两个阈值来控制正负样本,也有助于压缩低质量的检测结果。使用centerness可以消除这两个超参数,但是我们也发现同时使用centerness和这两个超参可以提升检测效果。
centerness也可以回归得到的向量来计算,而不用单独搞出来一个centerness分支,但是我们发现这样会检测效果变差。

2.Comparison with state-of-the-art detector

3.Extensions on Region Proposal Networks
