R实验(二)-关联规则-apriori函数的基本使用
动动大家的小手,一键三连一下,这对我有很大的帮助~
实验1:关联规则R基本实现验证—apriori函数的简易使用
mydata<-read.transactions(file="D:\\表6.1.csv")
问题1.1:请描述上述命令的运行结果
答:从D盘中读取表6.1.csv中的数据
问题1.2:结合运行结果,请描述inspect 函数功能
答:查看数据集的记录(如图1所示)

图1
问题1.3:结合运行结果,请写出:生成的规则总数,最大的支持度、置信度和提升度
答:成的规则总数为10条,最大支持度:0.2222、最大置信度:1、最大提升度:1.500(如图2所示)

图2
问题1.4:结合运行结果,请描述inspect函数功能(其中,lhs和rhs是前件和后件)
答:显示myrules中的所有规则(如图3所示)

图3
问题1.5:依据运行结果,请描述所有规则的后件(即rhs)所含项的数量
答:所有规则的后件所含项的数量均为1(如图3所示)
问题1.6:依据表6.1的实际数据,请写出规则1、5和9的支持度、置信度和提升度计算过程
| 规则 |
支持度计算过程 |
置信度计算过程 |
提升度计算过程 |
| 1 |
2/9=0.222222 |
2/2=1 |
2/9/(2/9*7/9)=1.285714 |
| 5 |
1/9=0.111111 |
1/1=1 |
1/9/(1/9*6/9)=1.500000 |
| 9 |
1/9=0.111111 |
1/1=1 |
1/9/(1/9*7/9)=1.285714 |
实验2:关联规则R基本实现验证—apriori函数的其他使用
问题2.1:结合图2.1,请详细描述“①~④”部分的结果含义【其中,density表示数据的稀疏程度】
答:1、事务总共有9个项集,5个item,在稀疏矩阵中,1占的比例为0.5111111;
2、将1项集按其频繁程度排序,频繁的1项集{I2}出现了7次,{I1}出现6次,{I3}出现6次,{I4}出现2次,{I5}出现2次;
3、将事务数据集中,每一个事务包含的元素个数进行计数并分类,例如第一列含义为:包含两个元素的事务数为5个;
4、计算事务中元素总数的最小值,最大值和四分位数。
问题2.2:依据运行结果,请描述上述sort函数的具体功能
答:对于myrules,按其support值进行排序,默认为降序(如图4所示)
问题2.3:依据sort(x=myrules, by="support", decreasing=TRUE),请描述该sort函数具体功能,并运行该函数,观察结果
答:对于myrules,按其support值进行排序,decreasing=true为按降序排序。

图4
问题2.4:依据运行结果,请描述所有规则的后件(即rhs)所含项的数量
答:所有规则的后件所含项的数量均为1(如图5所示)

图5
问题2.5:依据运行结果,请描述所有规则的后件(即rhs)所含项的数量;体会R语言的apriori生成规则的后件项数特点!
答:所有规则的后件所含项的数量均为1(如图6所示)

图6
问题2.6:依据上述两个apriori函数的运行结果,请描述minlen的功能
答:LHS+RHS并集的元素的最小个数,图7为最小个数为2时的数据,图8为最小个数为3时的数据

图7

图8
实验3:关联规则R基本实现验证—其他函数的使用
问题3.1:依据运行结果,请描述参数[,1:3]的功能
答:查看前三个item的支持度(如图9所示)。

图9
itemFrequencyPlot(mydata, support=0.2)
itemFrequencyPlot(mydata, support=0.3)
问题3.2:依据运行结果图,请描述上述两个命令的结果之间差异;并运行结果图,截取、存入word。
答:第一条命令:显示支持度大于0.2的项集的支持度图(如图10所示)
第二条命令:显示支持度大于0.3的项集的支持度图(如图11所示)

图10

图11
问题3.3:请描述下述函数的完整功能
答:
itemFrequencyPlot(mydata, horiz=T) :显示关于mydata数据的图表条形水平展示图(如图12所示);
itemFrequencyPlot(mydata, topN=3, horiz=T):显示关于mydata中前三个item的图表条形水平展示图(如图13所示);
itemFrequencyPlot(mydata, support=0.2, topN=3, horiz=T):显示关于mydata中前三个item中支持度大于0.2的图表条形水平展示图(如图14所示);

图12

图13

图14
问题3.4:依据上述排序sort函数格式,请写出“依据支持度”排序的sort函数格式
答:sorted <- sort(x=myrules, by="support")

图15
问题3.5:请描述函数“subset(myrules, lift>1.3&support>0.2)”的功能
答:提取符合提升度lift>1.3并且支持度support>0.2的规则(如图16所示)。

图16
问题3.6:若提取后件含“I1”项的规则,则请写出subset函数形式
答: subset(myrules,subset=lhs%in%"I2") (如图17所示)

图17
问题3.7:依据下述subset运行结果,请描述subset(myrules, items %pin% c("I1")) 的功能
subrules=subset(myrules, items %pin% c("I1"))
答:提取myrules中包含I1的规则(如图18所示)

图18
问题3.8:依据下述subset运行结果,请描述subset(myrules, items%in% c("I5")&lift>=1.5) 的功能
subrules=subset(myrules, items%in% c("I5")&lift>=1.5)
inspect(subrules)
答:提取myrules中包含I5的规则并且提升度lift>=1.5的规则(如图19所示)。

图19
问题3.9:若需要显示subrules的前三项,则请写出inspect函数的具体形式
答:inspect(subrules[1:3]) (如图20所示)
 图20
图20
实验4:基于数据集Groceries 的关联规则挖掘
问题4.1:Groceries数据集,有多少行(即事务),有多少商品项?
答:有9835行,169个商品项(如图21所示)
问题4.2:在稀疏矩阵中,1占的比例是多少?
答:比例为0.02609146(如图21所示)

图21
问题4.3:若生成最小支持度0.001、最小置信度0.5的规则(假设规则存入myrules),则写出apriori函数样式,并发现了多少规则?长度为4的规则,有多少?
答:apriori(Groceries,parameter=list(support=0.001,confidence=0.5))共5668条规则(如图22所示);长度为4的规则,有3211条(如图23所示)。

图22
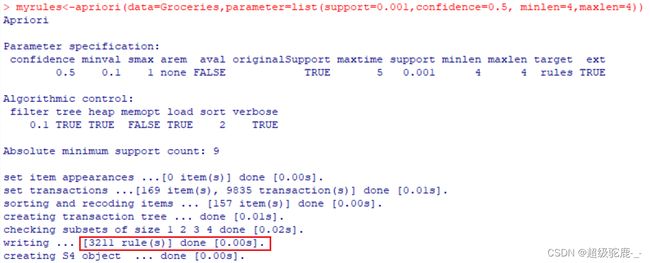
图23
问题4.4:在实现问题3的条件基础上,支持度、置信度和提升度最大值,分别是多少?
答:支持度最大值:0.007829、置信度最大值:1.0000、提升度最大值:11.279(如图24所示)。

图24
问题4.5:在实现问题3的条件基础上,若显示前5个规则,则写出itemFrequencyPlot函数样式,并将截取、存入支持度图。
答:itemFrequencyPlot(Groceries,topN=5, horiz=T) (如图25所示)

图25
问题4.6:在实现问题3的条件基础上,若生成support大于0.1的支持度图,则写出itemFrequencyPlot函数样式,并将截取、存入支持度图。
答:itemFrequencyPlot(Groceries,support=0.1) (如图26所示)

图26
问题4.7:运行下述三条命令,请给出运行结果,并分析下述三条命令的功能。
inspect(sort(rules,by="support")[1:5])
将myrules中的数据按支持度排序,并显示前五条规则
subset(rules,subset=rhs%in%"whole milk"&lift>=1.2)
提取myrules中右件为whole milk,且提升度>=1.2的规则数
inspect(subset(rules,subset=rhs%in%"whole milk"&lift>=1.2)[1:5])
显示myrules中右件为whole milk,且提升度>=1.2的前五条规则
如图27所示

图27
动动大家的小手,一键三连一下,这对我有很大的帮助~,如果有不正确的地方,还请大家指正!