微服务架构,springcloud核心组件和实战,docker容器
文章目录
- 前言
- 一、微服务开发基础
-
- 1、微服务架构开发
-
- 1.1单体架构的应用的困境
- 1.2 微服务架构
-
- 1.2.1 理解微服务架构
- 1.2.1 微服务的优缺点
- 1.3 微服务架构设计
-
- 1.3.1 微服务粒度——粗粒度划分较好
- 1.3.2 微服务拆分原则——从面向对象理论中借鉴
- 1.3.3 微服务自治原则——由一个服务提供数据操作
- 1.3.4 微服务交互原则——协议交互
- 1.3.5 微服务架构迁移——单体架构应用迁移到微服务架构
- 1.4 不使用微服务架构的情形
- 2、微服务基础-SpringBoot
-
- 2.1 Spring与SpringBoot
- 2.2 快速启动SpringBoot
- 2.3 使用Spring Boot构建示例项目
-
- 2.3.1 经典三层应用架构
- 2.3.2 设计领域对象
- 2.3.3 实现数据管理
- 2.3.4 编写业务逻辑层
- 2.3.5 编写RESTful API
- 2.3.6 数据库初始化
- 2.3.7 启动测试
- 2.4 Spring Boot特性
-
- 2.4.1 Spring Boot自动配置机制
- 2.4.2 Spring Boot扩展属性配置
- 2.4.3 Spring Boot日志配置
- 2.5 关于敏捷开发
- 2.6 关于RESTful设计
- 二、SpringCloud组件实战
-
- 3、SpringCloud简介
-
- 3.1 微服务架构的核心关键点---各个环节组件介绍
- 3.2 SpringCloud技术概览
-
- 3.2.1 SpringCloud子项目
- 3.2.2 为何选择Spring Cloud
- 3.3 SpringCloud版Hello World
- 4、服务治理与负载均衡
-
- 4.1 什么是服务治理
- 4.2 构建服务治理--eureka
-
- 4.2.1 搭建微服务Parent工程
- 4.2.2 搭建服务治理服务器——Eureka服务器
- 4.2.3 搭建服务提供者——注册服务
- 4.2.4 搭建服务消费者——获取服务
- 4.2.5 服务调用(自己加上的一个)
- 4.3 使用客户端负载均衡——Ribbon
-
- 4.3.1 什么是客户端负载均衡
- 4.3.2 启用Ribbon
- 4.3.3 负载均衡测试
- 4.4 使用epenFeign简化微服务调用(原文是使用feign)
- 4.5 深入Eureka
-
- 4.5.1 服务注册及相关原理
- 4.5.2 Eureka自我保护模式
- 4.5.3 注册一个服务实例需要的时间
- 4.5.4 Eureka高可用集群及示例
- 4.5.5 多网卡及IP指定
- 4.5.6 Eureka服务访问安全
- 4.6 深入Ribbon
-
- 4.6.1 Ribbon客户端负载均衡原理
- 4.6.2 Ribbon负载均衡策略及配置
- 4.6.3 直接使用Ribbon API
- 4.7 深入openFeign
-
- 4.7.1 Feign的参数绑定
- 4.7.2 Feign中的继承
- 4.7.3 Feign与Swagger的冲突
- 4.8 微服务健康监控
- 4.9 异构服务解决方案——Sidecar
- 5、微服务容错保护——Hystrix
-
- 5.1 什么是微服务容错保护
- 5.2 启动Hystrixfds
- 5.3 Hystrix容错机制分析
-
- 5.3.1 Hystrix整体处理流程
- 5.3.2 HystrixCommand与HystrixObservableCommand
- 5.3.3 断路器原理分析
- 5.4 服务隔离
- 5.5 服务降级模式
- 5.6 请求缓存
- 5.7 请求合并
- 5.8 Hystrix监控
- 6、API服务网关——Zuul
-
- 6.1 API服务网关(路由和过滤器)
- 6.2 Spring Cloud与Netflix Zuul
- 6.3 启用Zuul路由服务
- 6.4 路由规则
- 6.5 Zuul路由其他设置
- 6.6 Zuul容错与回退
- 6.7 Zuul过滤器
- 6.8 @EnableZuulServer与@EnableZuulProxy比较
- 7、统一配置中心——Config
-
- 7.1 Spirng Cloud Config简介
- 7.2 快速启动
- 7.4 配置的加密与解密
- 7.5 配置服务器访问安全
- 7.6 配置服务器的高可用
- 8、分布式服务跟踪——sleuth
-
- 8.1 Spring Cloud Sleuth简介
-
- 8.1.1 快速启用Sleuth
- 8.1.2 Sleuth与日志框架
- 8.2 Sleuth与ELK整合
- 8.3 整合Zipkin服务
-
- 8.3.1 构建Zipkin服务器
- 8.3.2 整合微服务
- 8.3.3 Zipkin分析
- 8.3.4 输出TraceId
- 8.4 Sleuth抽样采集与采样率
- 9、消息驱动——Stream
-
- 9.1 什么是消息驱动开发
- 9.2 Spring Cloud Stream简介
- 9.3 Kafka使用指南
- 9.4 使用消息对应用重构
- 9.5 Spring Cloud Stream高级主题
- 9.6 消息总线——Spring Cloud Bus
-
- 9.6.1 完成配置自动刷新配置
- 9.6.2 发布自定义事件
- 10、微服务应用安全——Security
-
- 10.1 Spring Boot的应用安全
- 10.2 微服务安全
- 10.3 基于OAuth 2.0的认证
- 10.4 基于JWT的认证
- 三、微服务与docker
-
- 11、微服务与Docker
-
- 11.1 Docker简介
- 11.2 Docker的使用
-
- 11.2.1 安装
- 11.2.2 镜像
- 11.2.3 容器
- 11.3 Docker与Spring Cloud微服务
-
- 11.3.1 部署Eureka服务
- 11.3.2 部署应用微服务
- 11.4 微服务与Jenkins
- 11.5 微服务编排
前言
本篇内容参考自《SpringCloud微服务架构开发实战》-董超、胡炽维,书中源码
一、微服务开发基础
1、微服务架构开发
1.1单体架构的应用的困境

①后期功能扩展不易:在传统的单体架构项目中,所有的东西都集中在一个项目,开发,部署,运维会随着业务的扩张而变得非常的麻烦,牵一发而动全身
②团队协作开发保持一致:而且对于一个团队开发来说,如果修改了数据库,那么其他所有人都应该知晓,而且技术栈也要一致,对于一个项目来说,很难使用和切换不同的框架,语言,新的开发者往往需要了解到整个项目的架构才能加入开发,并且多人使用git开发修改统一文件还会导致文件冲突,解决冲突也是一件很麻烦的事情
③项目部署难以水平扩展:因为每一个应用实例对服务器来说都需要相同的硬件配置,这让服务器无法充分发挥其能力,造成浪费,并且部署的服务速度会随着代码积累逐渐变慢,性能降低。
1.2 微服务架构
1.2.1 理解微服务架构
①核心原理:分而治之,就是将我们的应用分解成多个功能独立的模块/服务,服务之间的交互通过某种协议(REST,RPC-dubbo)进而完成一系列复杂的业务功能,每个服务都是一个能够独立提供范围有限的一个小型的完整功能,所以是能够单独部署在服务器上的,而且还能够水平复制,通过负载均衡算法确定调用的微服务,对外隐藏了具体的业务逻辑代码的细节,只提供外部访问的接口,
②可扩展模型:AFK可扩展立方体
X轴:服务可部署到多个服务器,然后再做一个集群负载均衡即可
Y轴:可运行多个实例,每个实例用来处理部分数据,在之前没有负载均衡, 而是一个路由,将请求转发到不同的实例中
Y轴:应用分解,高可扩展/font>
1.2.1 微服务的优缺点
优点:
①松耦合:应用拆解成多个服务,提供接口调用②抽象:调用特定的服务才能修改数据③独立:服务之前相互独立,独立部署④高可用
缺点:
感觉和优点有点悖论
①可用性降低:当一个服务崩溃之后,可能会产生级联反应,造成应用雪崩
②处理分布式事务:当用户操作涉及到多个服务时,如何保证数据的一致性,
③学习难度大:学习一系列的组件才能搭建应用系统
④全能对象:服务拆分时,可能遇到多个服务使用同一对象
⑤组织架构变更:涉及服务编排和服务治理等一系列处理
1.3 微服务架构设计
设计可分为三个步骤:
①根据应用的需求定义
②识别应用中所包含的所有服务
③将关键需求用来描述服务之间如何协作
识别服务:通过业务逻辑识别核心微服务,然后将核心服务相关的服务都定义出来,不可以一开始从技术的角度去拆分
服务的协作:根据业务分析,有的场景可能只需要某个服务,或者两个甚至多个服务才可以实现,有些协作是需要同步的,甚至是异步的,此外还需要考虑用户最初发起请求是由哪个服务承担
1.3.1 微服务粒度——粗粒度划分较好
如果我们将每一个部分都当做一个服务,那么粒度就太细了,每个服务都只实现了数据处理,而业务的处理需要粘合过多的代码才能够让这些微服务整合来完成一个具体的业务处理,
最好的方式是先专注于各个服务之间的交互,先分成粗颗粒度的服务,随着系统的升级和功能的提升再去细化这些服务
1.3.2 微服务拆分原则——从面向对象理论中借鉴
从面向对象的开发理论中进行借鉴:
①单一职责原则(SRP):一个类应该有且只有一个变化的原因
一个类承担多个职责后,往往这些职责就会耦合在一起,某一职责的改变可能会影响到其他的职责。这样的类设计是非常脆弱的,从而会导致应用的稳定性。因此,我们在进行类设计时要遵守单一职责原则
②共同封闭原则(CCP):包中的所有的类对于同一种性质的变化应该是共同封闭的。一个变化若对一个封闭的包产生影响,则将对该包中的所有类产生影响,而对其他包则不造成任何影响
开闭原则(OCP)中的关闭概念,说当需要修改某项业务时,我们需要将修改的范围限制在同一个包内,而不是遍布在很多包中
1.3.3 微服务自治原则——由一个服务提供数据操作
需要更改某一业务数据库表时往往会涉及多个模块,甚至有时候根本不清楚修改这张数据库表到底会影响到多少业务代码,从而不敢动数据库表的定义,只好退而求其次,通过增加表来处理,进而加剧了系统架构的恶化。
将业务数据管理进行私有化之后就进一步降低了业务之间的耦合度
微服务数据自治是指将对数据的操作封装到一个服务中,其他服务只能通过这个服务调用实现功能,而不能直接操作数据库
1.3.4 微服务交互原则——协议交互
①使用REST协议:REST可以说在微服务互相调用之间起着非常重要的角色,强烈建议大家使用HTTP作为服务的调用协议,并在服务处理上使用HTTP标准动词(GET、PUT、POST和DELETE)。
②使用URI表达:服务端点的URI应该能够清晰表达出我们所要解决的问题、提供的方法、相应资源信息及资源之间的关联关系。
③使用JSON数据格式:JSON作为轻量级数据格式协议,及自带的序列化和反序列化机制,几乎已经成为通信中的数据标准协议,并且对于前端开发来说非常容易使用与整合。
④使用HTTP标准状态码:HTTP协议本身具有非常丰富的状态码,那么使用这些状态码来作为服务调用结果的状态是非常合适的。
1.3.5 微服务架构迁移——单体架构应用迁移到微服务架构
使用Martin Fowler提出绞杀(Strangler)模式。该策略名字来源于雨林中的绞杀藤,绞杀藤为了能够爬到森林顶端都要缠绕着某棵大树生长,最终使被缠绕的大树死掉,只留下树形一样的绞杀藤。通过这种策略,我们在迁移时应首先围绕着传统应用开发出新的微服务应用,并逐渐替代传统应用中的部分业务功能。通过这种方式逐步构建微服务应用,并替代、兼容整合旧的传统应用,直到微服务承担全部应用功能
1.4 不使用微服务架构的情形
①构建分布式架构非常吃力时;
②服务器蔓延时;
③采用小型应用、快速产品原型时;
④对数据事务的一致性有一定要求时。
2、微服务基础-SpringBoot
2.1 Spring与SpringBoot
浅谈:
①Spring核心和IOC(控制反转)和AOP(面向切面编程),属性Spring家族核心产品,
②在原始SSM项目中我们可能要写很多配置文件,每一种框架都需要写,而利用SpringBoot构建的项目采用的结构是starter启动器,每一个功能及时一个启动器,比如说整合mysql,连接redis或者是使用AOP,你只需要导入相应的依赖即可,每一个starter都会有一个配置类,所有的配置类属性通过application配置文件修改配置类默认值,极大的简化了开发,而且还有统一的日志管理,缓存,语言切换等其他功能,灰常方便
2.2 快速启动SpringBoot
使用IDEA工具快速创建一个SpringBootDemo,再使用maven导入依赖,编写pom.xml文件
在创建的包下面的运行类启动即可
@SpringBootApplication注解告诉Spring容器:使用该类作为所有Bean源,通过该起始点构建应用的上下文,@SpringBootApplication注解继承自应该是注解套娃,该注解上的存在着两个注解@EnableAutoConfiguration和@ComponentScan,通过该注解使得项目在启动时Spring就会对该类所属目录下的所有子包进行扫描并根据Spring Boot的自动配置机制进行配置。

如果在应用启动时需要进行某些初始化处理,那么最好都在该类中完成。
2.3 使用Spring Boot构建示例项目
2.3.1 经典三层应用架构
针对系统:MVC:model、view、controller
针对后端:controller,service,dao
2.3.2 设计领域对象
,最难也是最先需要解决的就是业务领域对象(Domain)。只有清晰地识别出这些业务领域对象,以及它们之间如何交互及关联关系之后,才能进行下一步的开发
使用commons-lang包的ToStringBuilder.reflectionToString(Object)可以快速返回实体类的toString方法,特别是实体类有几十个属性的时候,
2.3.3 实现数据管理
①数据持久化:将数据存储到关系型数据库中,ORM(Object Relation Mapping)通过实体类和数据库中表的字段的映射操作数据,这只是一种想法和JDBC一样,具体的jar包才是实现,对ORM的实现有hiberate和mybatis,
②关于JPA和ORM
JPA的实现思想即是ORM。
JPA并不是一种框架,而是一类框架的总称,基于ORM思想实现的框架都称为JPA框架。
③spirngdatajpa
spring生态圈对jpa的整合,默认是使用hibernate框架实现的
2.3.4 编写业务逻辑层
处理一个业务的实际代码,将结果存储到数据库并且返回,
2.3.5 编写RESTful API
Restfult是一种编程艺术/风格/规范,你也可以不遵守,没得任何问题,就和驼峰命名法一样,但是这么多人写的代码,每个人的习惯都不一样,没有规范的话,看别人代码很头疼,而且有了规范还会提升开发效率,
Restful是指使用http请求的请求方式来判定对资源操作的增删改查,而不是通过方法名来确定,
swagger是一个用于测试api的工具类,而且还提供了测试的友好界面
2.3.6 数据库初始化
数据库设置初始值便于测试
2.3.7 启动测试
启动主启动类,访问swagger-ui.html主页或者postman均可测试接口
Enable
2.4 Spring Boot特性
2.4.1 Spring Boot自动配置机制
EnableAutoConfiguration,开启自动配置,找到starter的系统配置类,创建对象,
EnableConfigurationProperties指定属性配置类
condition设定条件决定是否启用这个配置
2.4.2 Spring Boot扩展属性配置
通过修改application系统配置文件,修改配置类的一些默认配置属性 ,
此外还有配置文件的优先级,profile文件,jar包外部配置文件配置,命令行启动配置,高优先级会覆盖低优先级,
还可以给自己写的配置类属性赋值,
application:ConfigurationProperties指定前缀
专注属性配置文件properties:还需要一个注解,忘记了,注解名有限制,具体也忘记了,好像是不能有大写字符和中文
也可以用通过Spirng的value("${配置文件中得变量名}")注解赋值
2.4.3 Spring Boot日志配置
springboot依赖自定集成了spring-boot-starter-logging,使用slf4j作为统一的抽象接口,默认是logback日志实现,也可以自己替换
2.5 关于敏捷开发
开发者每次的改进(添加、优化、修改Bug)都不能太大,如果需要增加/改动的较大,那么这个时候或许就不能严格遵守敏捷开发的原则,需要在进行代码重构的同时添加一些必要的改进
2.6 关于RESTful设计
①以资源为中心进行URL设计;
/user/{id}
②正确使用HTTP方法及状态码;
get获取资源,post创建或者修改资源,put修改资源, delete删除资源
③查询及分页处理原则;
/userPage/?page=1&size=1&sort=username,desc
④其他指导原则
使用JSON作为同一个返回的数据格式,返回统一JSON数据信息,方便统一处理
二、SpringCloud组件实战
3、SpringCloud简介
2014年3月,Martin Fowler在其博客上发表了Microservices一文,对过去几年逐渐开始流行的微服务架构开发模式给出了正式的定义。同年,Netflix将自己多年实际开发所使用的微服务基础组件通过Netflix OSS(Open Source Software)进行开源,加速了微服务架构模式的推广和普及。随之,Pivotal在Netflix OSS的基础上进行了封装和集成,推出了SpringCloud。如今,随着微服务架构的普及,使微服务在技术生态上得到了不断的完善和更新,不论是容器、应用框架、发布管理及监控等都有了长足的进步。
3.1 微服务架构的核心关键点—各个环节组件介绍

1)服务治理
消费者如何访问并调用服务提供者所提供的的服务,服务提供者如何能让消费者知道并且消费。服务可以部署在多台服务器上,而我不可能利用服务IP去访问服务,因为我们不知道那个服务是否可用或者是否存在,也就是如何暴露服务
解决:服务治理(consul,eureka)
服务提供者在上线时将所提供的服务信息注册到服务治理服务器中,服务下线时,将信息从服务治理服务器中注销
服务消费者根据服务名称从服务治理服务器中获取服务并且调用
2)负载均衡
传统应用会在用户请求的入口通过负载均衡设备(如F5)或通过Ngnix反向代理方式实现负载均衡,
但在微服务架构下,负载均衡不仅仅是用户请求入口,还包含了服务之间的调用。
解决:客户端负载均衡(软负载均衡)
消费者(也叫客户端)保存有一份从服务治理服务中获取的服务者列表,客户端通过负载均衡策略来决定每次服务调用时所使用的具体服务实例,从而实现负载均衡
3)微服务统一入口
如何对众多微服务的入口统一到一个入口进行管理
解决:API服务网关
为微服务提供了统一的入口, 并能附加一些路由规则,使得不同的微服务通过路由规则提供一致的访问入口
4)微服务的容错
各个微服务的调用都是通过网络来完成的,而用户的一个请求往往需要涉及多个服务,如何防止服务调用失败不影响其他服务和调用者以及引起雪崩呢?
解决:Hystrix(断路器,服务降级)
防止服务调用失败引起的连锁反应
5)微服务的统一配置
/font>如何对众多的微服务进行统一的配置
6)微服务的监控
单体应用很容易通过系统的日志文件进行监控,而微服务架构的项目被拆分成了N多个服务,一个请求会设计到多个服务的调用,而日志由自己的服务实例管理,如何将分散在多个日志之间的调用串联起来,形成一个完整的请求链
解决:日志聚合,日志可视化分析,调用链跟踪
7)服务的部署
几十上百个的微服务的上线,下线,需要耗费很大的人力,
解决:自动化部署
Docker工具快速部署,K8s来构建自动化部署编排
3.2 SpringCloud技术概览
Spring Cloud并不是一个传统意义上的项目,而是众多子项目的一个大集成,在版本号中Spring Cloud也没有采用传统的方式,而是通过一个“发布列车”的概念来定义版本
核心功能包:
①基于Netflix实现服务治理、客户端负载均衡和声明式调用;
②服务网关;
③微服务容错管理;
④整合消息中间件提供消息驱动式开发;
⑤基于Spring Security提供微服务安全、单点登录功能;
⑥分布式、版本化的统一配置管理;
⑦微服务调用链及追踪管理
3.2.1 SpringCloud子项目
1)服务治理
eureka原本是Netflix下的开源产品,但是springcloud对其进行了二次封装,成了SpringCloudNetflix,
eureka提供了服务注册,服务发现,以及UI界面,在集群部署中即使只剩一个节点存活,也可以正常治理服务
2)负载均衡
ribbon实现,默认与eureka进行了无缝整合,当消费者去调用服务时,ribbon就会根据负载均衡策略选择一个合适的服务提供者实例并进行访问
服务调用方式:
①RestTemplate对象调用
②feign(自动集成了ribbon)接口调用,声明式服务调用
3)服务容错和降级
Hystrix提供容错,降级,回退,默认集成到了feign子项目中
其中可视化工具仪表盘可以监控服务调用所消耗的时间,请求数,成功率
4)服务网关
zuul实现,提供请求的路由和过滤
路由:将外部请求转发到具体的服务实例上,
过滤:对请求的处理过程进行干预
通过zuul可以将细粒度的服务组合起来提供一个组粒度的服务,所有请求都导入一个统一的入口,对外整个服务只需要暴露一个API接口,屏蔽了服务的实现细节,
5)消息中间件
SpirngCloud提供了Stream子项目,提供了建立消息应用抽象层,构建了消息收发、分组消费和消息分片等功能处理,将业务应用中的消息收发与具体消息中间件进行解耦.。和springboot日志的抽象类似
6)分布式配置中心
SpringCloud提供了Config子项目,将微服务分为两种角色,配置服务器,和配置客户端。
使用配置服务器集中地管理所有配置属性文件,配置服务中心可以将配置属性文件存储到Git、SVN等具有版本管理仓库中,也可以存放在文件系统中
7)微服务链路追踪
SpringCloud子项目sleuth提供了微服务之间调用的链路追踪,
leuth核心思想就是通过一个全局的ID将分布在各微服务服务节点上的请求处理串联起来,还原了调用关系,并借助数据埋点,实现对微服务调用链路上的性能数据的采集,可以很清楚地了解到一个用户请求经过了哪些服务、每个服务处理花费了多长时间
8)微服务安全
Spring CloudSecurity为我们提供了一个认证和鉴权的安全框架,实现了资源授权、令牌管理等功能,同时结合Zuul可以将认证信息在微服务调用过程中直接传递,简化了我们进行安全管控的开发
3.2.2 为何选择Spring Cloud
1)Spring Cloud作为Spring Boot的传承,遵循约定优于配置的原则,在使用时不需要复杂的配置就可以运行起来,学习曲线低。
2)Spring Cloud中的大部分子项目开箱即用,采用自动化配置机制,可说使用门槛非常低。
3)…
4)…
3.3 SpringCloud版Hello World
三个服务:服务提供者,服务消费者,服务治理服务器
消费者通过feign调用提供者注册在服务治理服务器中得服务,
代码暂时没有,书中代码版本较为破旧
4、服务治理与负载均衡
4.1 什么是服务治理
对于微服务架构来说,各个服务的快速上线和下线,从而可以快速进行水平扩展,并且保证服务的可用性,服务治理正好可以解决这一问题
服务治理:通过抽象将服务消费者和提供者进行隔离
消费者不知道真实的服务提供者的真实物理地址,也无须知道具体有多少个服务可以用;
提供者只需要将自己的服务注册到服务治理服务器中即可,也不需要知道具体是哪个消费者来调用的。而且一旦某个服务出现了,那么服务治理服务器可以发现这个有问题的服务,并且绕过有问题的服务实例
实现框架:eureka,是netflix开源框架中一系列项目中的一个,
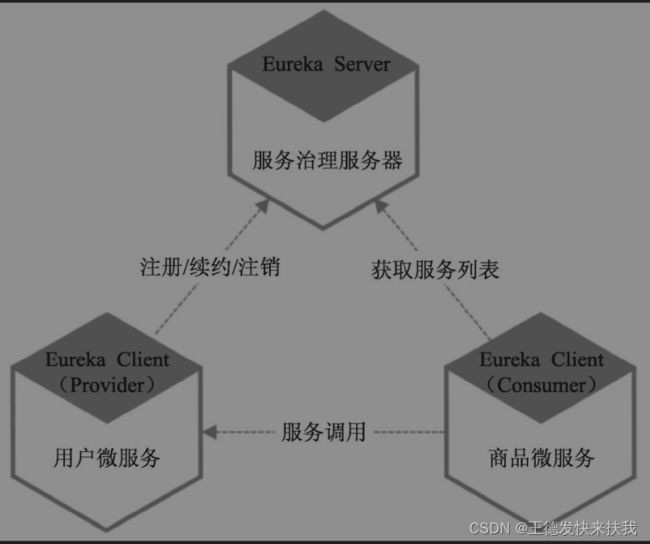
服务治理框架–eureka解决方案
①eureka服务器(注册中心):负责服务的注册,维护和查询功能
②服务提供者:将服务实例将自己配置信息通过服务名的形式注册到注册中心中
③服务消费者:通过所需要的服务名从注册中心获取服务并且调用
4.2 构建服务治理–eureka
4.2.1 搭建微服务Parent工程
搭建当前项目所需的pom依赖的父工程maven,对依赖版本进行统一的管理,其他项目都继承这个maven即可
4.2.2 搭建服务治理服务器——Eureka服务器
继承父工程依赖,导入eureka依赖,
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-serverartifactId>
<version>${euraka.server.version}version>//2.1.5.RELEASE
dependency>
配置文件
server:
port: 7002 #端口号
eureka:
instance:
hostname: cloud-payment-service
client:
register-with-eureka: false #false表示不向注册中心注册自己。
fetch-registry: false #false表示自己端就是注册中心,我的职责就是维护服务实例,并不需要去检索服务
service-url:
#集群指向其它eureka
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
eureka.client.register-with-eureka属性是用来控制当Spring Boot启动服务完成后是否将该服务注册到服务治理服务器上。这里因为服务本身就是服务治理服务器,而且尚未构建任何服务治理集群,因此将其设置为false,表示不注册。
eureka.client.fetch-registry属性也设置为false,表示应用启动后不需要从服务治理服务器中同步已注册的服务注册列表数据到本地。
其他配置:启动类加上@EnableDiscoveryServer
4.2.3 搭建服务提供者——注册服务
创建新模块继承父工程的POM,
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-clientartifactId>
<version>${euraka.server.version}version>//2.1.5.RELEASE
dependency>
eureka:
client:
register-with-eureka: true #是否注册到注册中心
fetch-registry: true #false表示自己端就是注册中心,我的职责就是维护服务实例,并不需要去检索服务
service-url:
#集群指向其它eurekaServer
defaultZone: http://localhost:7001/eureka/
其他配置:启动类加上@EnableDiscoveryClient
Eureka要求服务提供者必须发送3次心跳(默认每次心跳间隔为10秒)后才认为该服务实例已经准备好
4.2.4 搭建服务消费者——获取服务
创建的模块依赖和提供者一样,配置略有不同,eureka-client-fetch-registry改为true即可,因为服务消费者需要调用服务,所以需要从服务中心获取已注册的信息到本地
eureka:
client:
register-with-eureka: false #是否注册到注册中心
fetch-registry: true #false表示自己端就是注册中心,我的职责就是维护服务实例,并不需要去检索服务
service-url:
#集群指向其它eurekaServer
defaultZone: http://localhost:7001/eureka/
应用第一次与服务治理服务器同步注册服务列表数据后,默认以每30秒的频率与治理服务器进行同步
4.2.5 服务调用(自己加上的一个)
RestTemplate
① 提供了多种便捷访问远程Http服务的方法,是一种简单便捷的访问restful服务模板类,是spring提供的 用于访问Rest服务的客户端模板工具集,
②发出的http请求的请求方式必须和生产者对应接口所能处理的请求方式一致
DiscoveryClient
①通过resource注解注入
②
List<String> list = discoveryClient.getServices();//获取所有的实例名称
List<ServiceInstance> instanceList = discoveryClient.getInstances("cloud-payment-service");//指定服务名称获取服务实例
openFeign
接口式调用
4.3 使用客户端负载均衡——Ribbon
在微服务出现之前,消费者和提供者有一个独立的集中式负载均衡系统,该系统通常由专门的硬件(如F5)或者基于软件(Visual Studio、HAproxy等)来承担。
当服务消费者调用某个目标服务时,先向负载均衡系统发起请求,由负载均衡系统以某种策略(如Round-Robin)做负载均衡后再将请求转发给目标服务
缺点
①单点失败:一旦负载均衡宕机,那么整个应用无法访问
②难扩展:扩展时非常困难,
③复杂:有些负载均衡本身还对请求处理一些处理,这样导致在使用时还要去学习一下它的技术
4.3.1 什么是客户端负载均衡
在微服务中,负载发生在某个服务消费者调用上面
微服务架构负载均衡解决方案
①集中式负载均衡
独立的一个负载均衡系统,和之前传统的单体架构负载均衡原理一致
②进程内负载均衡(客户端负载均衡)
以库的形式整合到消费者服务中,当消费者调用某些服务时,内置的负载均衡会以某种负载均衡策略选择一个目标服务实例,然后查询真实服务地址,并且调用
③主机独立负载均衡进程方案
将负载均衡从消费者中抽移出来,变成同一主机上的一个独立进程,为该主机上的一个或多个服务消费者提供负载均衡处理。
ribbon就是第二种方案的实现
4.3.2 启用Ribbon
ribbon中自动整合了eureka,默认负载均衡算法是轮询,
使用
①在RestTemplate中加上增加一个@LoadBalanced注解,这时ResTemplate就具有了负载均衡的功能
@LoadBalanced
@Bean(value="restTemplate")
RestTemplate restTemplate(){return new RestTemplate();}
4.3.3 负载均衡测试
需要搭建两个消费者服务,本机上设置两个服务端口不一样即可,也就是jar包启动设置不同端口就可以了。
4.4 使用epenFeign简化微服务调用(原文是使用feign)
有必要说一下,feign已经停更,新版本openFeign功能更加强大,但是主要功能差别不大
openFeign整合了Hystrix和ribbon,接口式调用服务,在当前接口上添加注解,标明HTTP请求的参数,格式,地址等信息。
ribbon简单使用
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-openfeignartifactId>
<version>${openfeign.version}version>//2.2.1.RELEASE
dependency>
主启动类:@EnableFeignClients
接口调用:FeignClient(“服务名”),方法和服务端controller一致,并且注解也需要
@FeignClient(value = "cloud-payment-service")
public interface PaymentHystrixService {
@RequestMapping("/payment/hystrix/ok/{id}")
public String paymentInfo_OK(@PathVariable("id") Integer id);
@RequestMapping("/payment/hystrix/timeout/{id}")
public String paymentInfo_Timeout(@PathVariable("id") Integer id);
}
4.5 深入Eureka
4.5.1 服务注册及相关原理
1)CAP理论
在分布式系统领域有个CAP定理(CAP theorem),又被称为布鲁尔定理(Brewer’s theorem),它指出对于一个分布式计算系统来说,不可能同时满足以下3点。
①一致性(Consistency):同一个数据在所有集群的节点中,同一时刻是否有事同样的值
②可用性(availiability):集群中一部分节点故障,集群整体是否还能处理客户端的请求
③分区容忍性(Partition tolerance):是否允许数据的分区,数据分区的意思是指是否允许集群中的节点之间无法通信。
任何一个服务都无法同时满足以上条件:Zookeeper采用的设计原则就是CP原则,Netflix在设计Eureka时遵守的也就是AP原则。
2)eureka服务注册
由eureka服务器维护和存储服务列表,使用嵌套的HashMap保存信息
①第一层hashmap为应用名称和对应的服务实例
②第二层hashmap为服务实例及其对应的注册信息,包括宿主机服务IP地址,服务端口,运行状况指示符,URL等数据
当服务实例状态发生变化时,就会向eureka服务器更新自己的服务状态。
3)服务续约
当服务成功注册eureka服务器时,eureka客户端默认以每隔30秒的频率向eureka发送心跳,也就是续约,避免自己的注册信息被eureka剔除掉
对于eureka服务器来说,默认90秒内,也就是连续3次没有收到心跳,那么就会从维护的服务列表中剔除掉当前服务,如果设置了自我保护模式,那么不会清楚服务实例信息
4)服务下线与剔除
当服务关闭时,会自动向eureka服务器发起下线请求,直接从服务器中剔除
5)获取服务
eureka客户端启动的时候,会从服务器中获取服务列表的信息,并且缓存到本地,默认30秒从eureka服务器进行同步
6)Region、zone
这是由于Region和Zone (或者Availability Zone)均是AWS(Amazon Web Services)的概念。在非AWS环境下,可以暂时将Region简单地理解为大区域或地域,比如当我们租用阿里云服务器的时候需要选择华南、华北、华东等,Zone可理解成机房
4.5.2 Eureka自我保护模式
当Eureka服务器每分钟收到心跳续租的数量低于一个阈值,就会触发自我保护模式。当它收到的心跳数重新恢复到阈值以上时,该Eureka服务器节点才会自动退出自我保护模式
服务实例总数量×(60/每个实例心跳间隔秒数)×自我保护系数(0.85)
4.5.3 注册一个服务实例需要的时间
1)客户端/服务端本地缓存需要时间,默认30秒同步
2)ribbon负载均衡缓存,默认30秒同步
3)服务实例不是启动时注册实例,而是在启动之后的一个延时时间(默认40秒)再注册
4.5.4 Eureka高可用集群及示例
eureka服务器的互相复制,同步注册信息,让整个eureka集群中的每个服务都拥有注册服务的信息列表。
4.5.5 多网卡及IP指定
当一个服务注册到Eureka服务器后,其他的服务消费者会通过该服务所部署的主机名称进行通信,可能会出错,在开发环境中并没有DNS支持,所以当采用主机名称进行通信的时候就会产生无法找到服务器的错误,
所以推荐使用IP地址访问
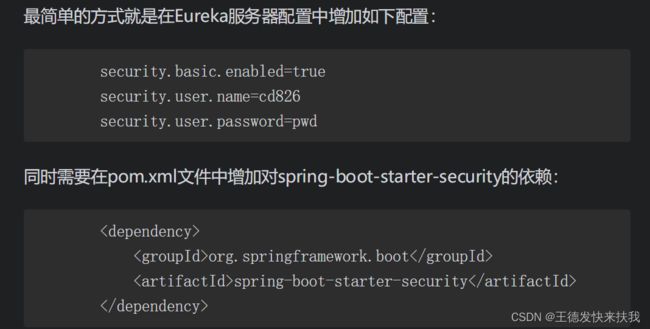
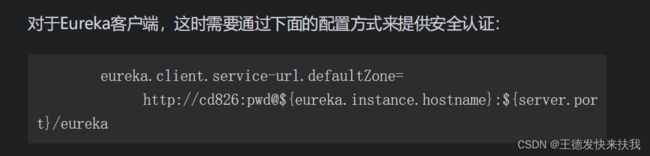
4.5.6 Eureka服务访问安全
eureka服务器(注册中心)直接通过IP和端口访问不太安全,可以加上验证
4.6 深入Ribbon
4.6.1 Ribbon客户端负载均衡原理
1)服务器列表(ServerList)
①静态服务列表:可以通过Ribbon中的BaseLoadBalancer所提供的setServersList()方法直接进行设置。
②基于配置的服务列表:配置文件中指定服务
 ③基于服务发现的服务列表:在应用启动的是ribbon默认就会从eureka服务器上获取所有注册服务的列表数据
③基于服务发现的服务列表:在应用启动的是ribbon默认就会从eureka服务器上获取所有注册服务的列表数据
2)服务器列表过滤(ServerListFilter)
在使用动态服务器列表时,会对原始服务器列表使用一定策略进行过滤,返回有效的服务器列表给客户端负载均衡使用。过滤器有以下几种
①ZoneAffinityServerListFilter:该过滤器基于区域感知的方式,实现对服务实例过滤,仅返回与本身所处区域一致的服务提供者实例列表。
②ServerListSubsetFilter:该过滤器继承自ZoneAffinityServerListFilter,在进行区域感知过滤后,仅返回一个固定大小的服务列表,也就是说不会返回全部符合条件的服务实例列表。这种过滤器非常适用于拥有大规模服务器集群的系统。默认将返回20个服务实例,但可以通过ribbon.ServerListSubsetFilter.size属性设置具体返回的服务实例个数
③ZonePreferenceServerListFilter:是Spring Cloud整合Netflix时新增的一个过滤器。当开发者使用Spring Cloud整合Eureka和Ribbon时就会默认使用该过滤器。其主要是实现通过配置或者Eureka所属区域来过滤出同区域的服务实例列表。
3)服务实例存活探测(IPing)
判断服务实例是否可用,实现方式如下
①PingUrl:通过定期访问指定的URL,来判断服务器是否可用。
②PingConstant:不做任何处理,只是返回一个固定值,用来表示该服务器是否可用,默认值为true,即可用。
③PingConstant:不做任何处理,只是返回一个固定值,用来表示该服务器是否可用,默认值为true,即可用
④·PingConstant:不做任何处理,只是返回一个固定值,用来表示该服务器是否可用,默认值为true,即可用。
⑤NIWSDiscoveryPing:根据DiscoveryEnabledServer中InstanceInfo的InstanceStatus属性判断,如果该属性的值为InstanceStatus.UP,则表示服务器可用,否则为不可用
4)负载均衡策略(IRule)
默认策略是轮询,也可以自定义策略。
常见策略如下:

自定义配置策略
@Configuration
public class MySelfRule {
@Bean
public IRule iRule(){
return new RandomRule();//定义为随机
}
}
//主启动类上
@SpringBootApplication
@EnableEurekaClient//消费者也要注册到注册中心
@RibbonClient(name = "CLOUD-PAYMENT-SERVICE",configuration = MySelfRule.class)//开启ribbon
public class OrderMain80 {
public static void main(String[] args) {
SpringApplication.run(OrderMain80.class,args);
}
}
5)负载均衡器(ILoadBalancer)
Ribbon负载均衡的具体实现主要是通过LoadBalancerClient类来实现的,而LoadBalanCer又将具体处理委托给ILoadBalancer来处理。对于ILoadBalancer,可以理解为客户端负载均衡“大总管”,其通过配置IRule、IPing等信息,并通过ServerList获取服务器注册列表的信息,默认以每10秒的频率向服务列表中的每一个服务实例发送ping请求,检测服务实例是否仍存活,最后使用负载均衡策略对ServerListFilter过滤得到最终可用的服务实例列表进行处理,并获取到最终要调用的服务实例,然后就可以交给服务调用器进行调用。ILoadBalancer也是一个接口,在具体实现上Ribbon提供了3个具体实现,分别是Dynamic ServerListLoadBalancer、ZoneAwareLoadBalancer和NoOpLoadBalancer。DynamicServer ListLoadBalancer继承自①ILoadBalancer基础实现BaseLoadBalancer,在基础的负载均衡功能上增加了运行期间对服务实例动态更新和过滤的功能。
②ZoneAwareLoad Balancer则是继承DynamicServerListLoadBalancer,并在此基础上增加防止跨区域访问的问题。当我们使用Spring Cloud整合Eureka和Ribbon时,默认就会使用该实现。
6)服务调用器(RestClient)
对于Ribbon所提供的6大组件及相应功能我们已经了解了一些,那么为何当我们在RestTemplate增加@LoadBalance注解后就可以为服务调用开启负载均衡处理呢?这就是LoadBalancerInterceptor的功劳了。当给RestTemplate增加了@LoadBalance注解后,Load BalancerAutoConfiguration就会对该RestTemplate进行处理,在RestTemplate的拦截器列表中添加一个LoadBalancerInterceptor拦截器,当通过RestTemplate进行服务请求时,LoadBalancerInterceptor中的拦截方法就会启动,通过LoadBalancerClient使请求具有负载均衡功能,具体拦截所执行的代码如下。

4.6.2 Ribbon负载均衡策略及配置
在前面我们已近提到了有哪些策略以及如何现在我们讲讲每一种策略的实现。
1)RoundRobinRule(轮询,默认轮询)
轮询策略,Ribbon以轮询的方式选择服务实例,即每次调度执行i = (count + 1) mod n,并选出第i台服务实例。其中count为执行请求的计数次数, n为当前可用的服务器总个数。这个是默认值,所以示例中所启动的两个用户服务会 被商品服务交替访问到。
2)RandomRule(随机)
3)BestAvailableRule(最大可用)
先过滤出故障服务实例后,选择一个当前并发请求数最小的
4)WeightedResponseTimeRule(带权轮询策略)
各个服务实例响应时间进行加权处理,然后再采用轮询的方式获取相应的服务实例
5)AvailabilityFilteringRule(可用过滤)
先过滤出有故障的或并发请求大于阈值的一部分服务实例,然后再以线性轮询的方式从过滤后的实例清单中选出一个实例
6)ZoneAvoidanceRule(区域感知)
先使用主过滤条件(区域负载器,选择最优区域)对所有实例过滤并返回过滤后的实例清单,依次使用次过滤条件列表中的过滤条件对主过滤条件的结果进行过滤,判断最小过滤数(默认1)和最小过滤百分比(默认0),最后对满足条件的服务实例则使用RoundRobinRule(轮询方式)方式选择一个
这个策略可以降低服务之间的调用延迟,提升系统效率
4.6.3 直接使用Ribbon API
@GetMapping("/discovery")
public Object discovery(){
List<String> list = discoveryClient.getServices();//获取所有的实例名称
for (String service : list) {
System.out.println(service);
}
List<ServiceInstance> instanceList = discoveryClient.getInstances("cloud-payment-service");
for (ServiceInstance instance : instanceList) {
//uri=http://host:port/
System.out.println("http://"+instance.getHost()+":"+instance.getPort()+"/"+instance.getUri());
}
return discoveryClient;
}
4.7 深入openFeign
以接口形式调用服务器,接口中的方式,都是使用的SpirngMvc的注解,
4.7.1 Feign的参数绑定
1)SpringMvc参数常用注解
@RequestParam:绑定单个请求参数值。
@PathVariable:绑定URI模板变量值。
@RequestHeader:绑定请求头数据。
@RequestBody:绑定请求的内容区数据并能进行自动类型转换等。
2)使用示例
@FeignClient(value = "cloud-payment-service")
public interface PaymentHystrixService {
@RequestMapping("/payment/hystrix/ok/{id}")
public String paymentInfo_OK(@PathVariable("id") Integer id);
@RequestMapping("/payment/hystrix/timeout/{id}")
public String paymentInfo_Timeout(@PathVariable("id") Integer id);
}
3)其他配置
主启动类上还需要加上@EnableFeignClients,接口的方法和服务controller一致
4.7.2 Feign中的继承
将消费者和提供者中相同代码片段提取出来,形成一个新的模块,然后在两个服务中分别引入。
4.7.3 Feign与Swagger的冲突
如果项目中使用了swagger,那么可能会导致无法启动,需要升级swagger到2.6.1版本以上就可以了
4.8 微服务健康监控
当开发者使用Spring Boot来构建微服务时,Spring已经提供了一个SpringActuator子项目,该子项目开箱即用。Actuator提供的对应用系统自身和监控的集成功能,包含了对应用系统进行配置查看、运行状态监控及相关功能统计等功能。通过rest风格接口访问并且可以看到返回的数据

应用启动后通过http://localhost:port/health端点可以获取到应用的健康状态
通过http://localhost:port/metrics端点可以访问应用一些度量指标数据
4.9 异构服务解决方案——Sidecar
通过Sidecar,可以将异构的服务加入Spring Cloud所构建的服务架构体系中
5、微服务容错保护——Hystrix
果单个服务出现问题,则调用该服务时会出现延迟甚至调用失败的情况;若调用失败,用户则会重新刷新页面并尝试再次调用,再加上其他服务的调用,从而增加了服务器的负载,导致某个服务瘫痪,甚至整个服务崩溃。
当服务调用失败时,应该采取应急措施,让系统进行自我保护和调节,如果不能有效的隔离这个有问题的服务,其他服务很可能因为这个单点故障而阻塞,从而产生雪崩效应,导致整个服务不能对外提供服务
5.1 什么是微服务容错保护
Hystrix是根据“断路器”模式而创建的。“断路器”本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控(类似熔断保险丝机制),向调用方返回一个符合预期的服务降级处理(fallback),而不是长时间地等待或者抛出调用方无法处理的异常,这样就保证了服务调用方的线程不会被长时间不必要地占用,从而避免了故障在分布式系统中的蔓延乃至崩溃
Hystrix原理结构图

在请求失败频率较低的情况下,Hystrix还会直接把故障返回给客户端(还是会继续调用服务)。只有当失败次数达到阈值(默认在20秒内失败5次)时,断路器才会被打开并且不再进行后续通信(直接返回错误信息),从而直接进行服务降级(fallback)处理。
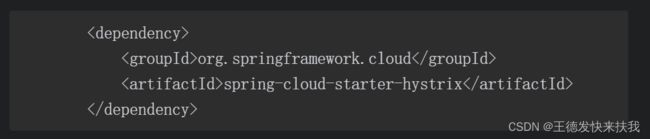
5.2 启动Hystrixfds
1)引入依赖
2)开启Hystrix支持
主启动类上添加@EnableCircuitBreake注解。
3)修改UserService实现(@HystrixCommand,使用在service接口实现类上)
①示例
@HystrixCommand(fallbackMethod = "paymentInfo_TimeoutHandler",commandProperties = {
@HystrixProperty(name="execution.isolation.thread.timeoutInMilliseconds",value="3000")//如果超过了3s那么就会发生服务降级
})
public String paymentInfo_Timeout(Integer id){
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "线程池:"+Thread.currentThread().getName()+" paymentInfo_Timeout::"+"\t"+"哈哈";
}
public String paymentInfo_TimeoutHandler(Integer id){
return "服务繁忙,请稍后重试!";
}
②HystrixCommand
fallback:发生错误时回调的方法名,方法就定义在当前类中,服务降级的处理方法
commandProperties:一个数组,用来指定出现哪些错误进行服务降级
4)Hystrix服务降级实现方式(服务端)
①注解,和上面我们给出的例子一样,但@HystrixCommand注解还有一些其他的属性
groupKey:设定HystrixCommand分组的名称。
commandKey:设定HystrixCommand的名称。
threadPoolKey:设定HystrixCommand执行线程池的名称。f fallbackMethod:设定HystrixCommand服务降级所使用的方法名称,注意该方法需要与主方法定义在同一个类中,并且方法签名也要一致。commandProperties:设定HystrixCommand属性,比如,断路器失败百分比、断路器时间窗口大小等,具体属性可以参考后面的讲解。threadPoolProperties:设定HystrixCommand所执行线程池的属性,比如,线程池的大小、线程池等待队列长度等。
ignoreExceptions:设定HystrixCommand执行服务降级处理时需要忽略的异常,也就是当出现这些异常时不会执行服务降级处理。
②继承HystrixCommand完成服务降级实现
Hystrix还提供了两个对象来支持服务降级实现的处理,即HystrixCommand和HystrixObservableCommand
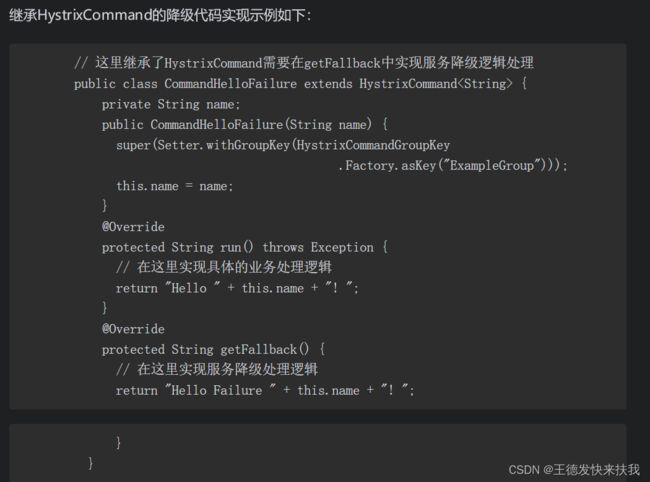

5)在openFeign中使用Hystrix回退(客户端)
和上面的配置是类似,只不过实在客户端也同样设置Hystrix服务降级即可
yml:设置feign.hystrix.enabled: true
主启动类:加上@EnableHystrix,服务端是@EnableCircuitBreaker
控制层:加上@HystrixCommand注解,和之前一样,只是位置不一样,(指定处理方法,和指定处理哪些异常)
处理方法:参数和服务调用方法一致。
5.3 Hystrix容错机制分析
①Hystix通过HystrixCommand或HystrixObservableCommand对所有第三方②依赖/服务调用进行封装,整个封装对象是运行在一个单独线程之中。
③可配置依赖调用超时时间,超时时间一般设为比99.5%平均时间略高即可。当调用超时时,直接返回或进行服务降级处理。
④为每个依赖关系/服务调用维护一个小的线程池(或信号量),如果已满,那么依赖服务调用将立即被拒绝,而不是排队等待。
⑤对服务调用的执行状态:成功、失败(客户端抛出异常)、超时及线程拒绝等进行统计;
⑥如果某服务调用的错误百分比高于阈值,则可以通过手动或自动的方式打开断路器,这样在一段时间内停止对该服务调用的所有请求。
⑦当服务请求被拒绝、连接超时或者断路器打开时,可以直接执行服务降级处理(fallback);
⑧Hystrix提供几乎实时的指标监控和配置变化。
5.3.1 Hystrix整体处理流程

以下是对流程的分析
1.命令封装与执行
对于这两个命令的封装和执行,在前面的示例中也说过,Hystrix主要是通过使用命令模式,将用户对业务服务调用请求的操作进行封装,通过该封装实现了调用者与实现者的解耦。同时更重要的是:Hystrix通过该模式来完成对整个请求的改造处理,从而实现了在不侵入微服务业务逻辑的情况下,为微服务增加了一层服务容错处理功能,使开发者在进行微服务编写时可以专注于业务逻辑的实现。
2.结果缓存是否可用
当我们为Hystrix开启了缓存功能时,Hystrix在执行命令时首先会检查是否缓存命中,如果是则立即将缓存的结果以Observale对象的形式返回,并不再继续执行该命令。
3.断路器是否已打开
当结果没有缓存命中时,Hystrix将继续执行该命令,但在执行前将先判断断路器的状态。如果断路器已打开,则说明相应的服务已不可用,那么这时Hystrix将会转入服务降级处理,否则将继续执行。
4.是否有资源执行
接下来,Hystrix将判断与该命令相关的线程池和队列是否已满(如果使用的是信号量隔离,则判断信号量是否已满),如果已满,那么Hystrix将不执行该命令,而是转入到服务降级处理。
5.执行业务逻辑
如果前面命令执行的条件都满足了,这时Hystrix将会调用HystrixCommand的run()方法或者HystrixObservableCommand的construct()方法来执行具体的业务逻辑处理, Hystrix使用run()还是construct()方法,是由前面所编写的方法来决定的,简单说明如下。
①run():该方法将返回一个单一的结果,或者抛出一个异常。
②construct():该方法将返回一个Observable对象,通过该对象发送一个或多个返回数据,或者发送一个OnError错误通知。
在命令执行过程中如果执行时间超时,那么执行线程(如果该命令没有在其自身线程中执行,则会使用一个单独线程)将会抛出一个TimeoutException异常,这时Hystrix将会转入到fallback处理。同时,如果线程没有被取消或者中断,那么run()或者construct()返回的结果将会被抛弃,该超时时间可以通过execution.isolation.thread.timeoutInMilliseconds设置,默认值为1000ms。另外需要注意的是,没有很好的办法强制将线程停止,Hystrix能做到的最好处理方法就是在JVM上抛出一个InterruptedException,如果业务方法没有正确地响应该异常,那么线程将会继续执行,即使客户端已经收到了TimeoutException,这会对Hystrix的线程池造成影响。此外,大部分Httpclient库尚不能正确处理InterruptedException,所以我们需要正确地配置Http client的读写超时时间。如果命令执行成功,那么Hystrix在返回结果之前,会记录一些日志和监控信息数据,以便后续对断路器健康状态进行评估。
6.更新断路器健康数据
在上面的过程中,Hystrix将会把采集到的“成功”、“失败”、“拒绝”和“超时”等数据提交给断路器,断路器则会把这些统计数据更新到一系列的计数器中,然后根据这些统计数据计算断路器是否需要打开;一旦断路器打开,在恢复期结束之前Hystrix都会对该服务进行熔断处理,在恢复期之后会根据采集到的数据再次进行判断,如果仍未达到健康状态,则将继续对该服务实施熔断处理的操作,直至符合健康状态为止。
7.服务降级处理
从图中可以看到以下几种情况都会进入服务降级处理:
①断路器已打开;
②无资源执行命令(线程池、队列或信号量已满);
③执行命令失败;
④执行命令超时。
当使用HystrixCommand时降级处理逻辑将通过getFallback()来实现,如果使用的是HystrixObservableCommand,降级逻辑则是通过resumeWithFallback()实现。在实现服务降级处理时,最好能够提供一个默认的处理结果,该结果最好是从内存缓存中或者一个静态逻辑处理中计算得到,不要再有任何网络调用的依赖。这是因为,一旦降级处理中包含网络处理,那么势必需要再次对该响应进行HystrixCommand/HystrixObservableCommand封装处理,从而造成级联处理,增大了系统的不稳定性,并且,降级处理终究还是要回归到一个能够稳定返回的实现上。
8.返回结果
一旦Hystrix命令执行成功(不论是缓存中的返回、所依赖服务处理的返回还是业务降级的返回,Hystrix都认为是已执行成功),将根据我们调用的不同返回直接处理结果或者Observable。
5.3.2 HystrixCommand与HystrixObservableCommand
1)HystrixCommand和HystrixObservableCommand两个类
①从命令模式上来说,HystrixCommand是一个阻塞型命令,当执行命令时可以直接获取到执行结果。而HystrixObservableCommand是一个非阻塞型命令,该命令的调用者通过订阅其返回对象来获取执行的结果。不过,HystrixCommand命令也提供了observe()方法,可以返回一个非阻塞型对象,但返回的Observable对象只能向调用者发送一次数据。
②从代码编写上来说,HystrixCommand命令的业务逻辑写在run()方法中,服务降级逻辑写在getFallback()方法中;而HystrixObservableCommand的业务逻辑写在construct()方法中,服务降级逻辑写在resumeWithFallback()方法中。
③从执行上来说,HystrixCommand的run()是由新创建的线程执行;而HystrixObservableCommand的construct()则是由调用程序线程执行。
④从执行返回的结果来说,HystrixCommand只能返回一个执行结果;而HystrixObservableCommand则可以按顺序向调用者发送多条执行结果。
2)execute()、queue()、observe()和toObservable()4种命令执行方式
①execute():该方法将以同步堵塞方式执行run()。也就是说当调用execute()后,Hystrix将会首先创建一个新线程来运行run(),同时调用者程序会在execute()调用处一直处于堵塞状态,直到run()运行完成。
②queue():该方法将以异步非堵塞方式执行run()。也就是说当调用queue()后,调用者线程就直接返回一个Future对象,同时Hystrix创建一个新线程运行run(),调用者通过Future.get()拿到run()的返回结果,而Future.get()则是堵塞执行的。
③observe():执行该方法时,Hystrix会首先触发执行HystrixCommand的run()方法,或执行HystrixObservableCommand的construct()方法。对于HystrixCommand,将创建一个新线程以非堵塞方式执行run();如果是HystrixObservableCommand,将在调用程序线程堵塞执行construct()。然后再调用subscribe()完成事件注册,如果run()或construct()执行成功则触发onNext()和onCompleted()方法,如果执行异常则触发onError()。④toObservable():与observe()不同的是,toObservable()方法是先注册,注册完成后自动触发并执行run()或construct()方法。
5.3.3 断路器原理分析
执行命令之前先判断断路器是否已打开,如果已打开则相应的服务就不可用,那么Hystrix将会转入服务降级处理,否则将继续执行。另外,当命令执行后,不论是否执行成功,Hystrix都会将收集到的数据提交给断路器以更新断路器的状态
1)断路器如何打卡
也就是在默认情况下错误率超过50%且10秒内超过20个命令请求进行中断拦截,这时候断路器将会被打开,Hystrix将会对所有命令执行请求进行服务降级处理。
2)断路器如何关闭
当断路器打开一段时间后(该值通过sleepWindowInMilliseconds设置), Hystrix就会进入半开(Half-Open State)状态,当一个命令请求通过这个断路器时,断路器则尝试不阻断这个命令请求,而是直接将这个命令请求通过,如果这个命令请求仍然执行失败,那么断路器会直接回到打开状态。如果这个命令请求执行成功,那么断路器就会关闭,并且开始进行下一次统计。
5.4 服务隔离
1)Hystrix实现服务隔离的思路
①使用命令模式(HystrixCommand/HystrixObservableCommand)对服务调用进行封装,使每个命令在单独线程中/信号授权下执行。
阿为每一个命令的执行提供一个小的线程池/信号量,当线程池/信号已满时,立即拒绝执行该命令,直接转入服务降级处理。
③为每一个命令的执行提供超时处理,当调用超时时,直接转入服务降级处理。
④提供断路器组件,通过设置相关配置及实时的命令执行数据统计,完成服务健康数据分析,使得在命令执行过程中可以快速判断是否可以执行,还是执行服务降级处理。
2)线程池隔离与信号量隔离
①线程池隔离:不同服务的执行使用不同的线程池,同时将用户请求的线程(如Tomcat)与具体业务执行的线程分开,业务执行的线程池可以控制在指定的大小范围内,从而使业务之间不受影响,达到隔离的效果。
②信号量隔离:用户请求线程和业务执行线程是同一线程,通过设置信号量的大小****限制用户请求对业务的并发访问量,从而达到限流的保
护效果。
3) 服务隔离的颗粒度
服务隔离颗粒度控制策略:
①服务分组+线程池:实现服务隔离的粗粒度控制,一个服务分组/系统配置一个隔离线程池即可。也可以不配置线程池名称或者配置为相同的线程池名称。
②服务分组+服务+线程池:实现服务隔离的细粒度控制,一个服务分组中的每一个服务配置一个隔离线程池,为不同的命令实现配置不同的线程池名称即可。
③混合实现:一个服务分组配置一个隔离线程池,然后对重要服务单独设置隔离线程池。
4) 服务隔离配置
①execution.isolation.strategy:设定服务隔离策略。THREAD为线程池隔离,SEMAPHORE为信号量隔离。默认值为THREAD。②execution.isolation.thread.timeoutInMilliseconds:用来设置线程池隔离和信号量隔离两种隔离策略的超时时间,单位为毫秒,默认值是1000ms。该值根据相应的业务和服务器所能承受的负载来设置,一般设置为比业务平均响应时间大20%~100%即可。如果这个值设置太大,则会导致线程不够用从而使太多请求被服务降级处理。如果值设置得太小,一些特殊的慢业务失败率会提升,甚至会造成业务一直无法成功执行,在重试机制存在的情况下,反而会加重后端服务压力。③execution.isolation.semaphore.maxConcurrentRequests:该值设置使用信号量隔离时最大的信号量大小。当请求达到或超过该设置值后,其余就会被降级处理,默认值是10。·execution.timeout.enabled:是否开启业务服务超时处理,默认值是true。
④execution.isolation.thread.interruptOnTimeout:当业务服务超时时是否中断线程,默认值是true。
⑤execution.isolation.thread.interruptOnCancel:取消时是否中断业务服务的执行,默认值是false。
5)小结
线程池隔离把执行业务服务线程与用户请求线程分离,请求线程可以自由控制离开的时间(异步过程)。通过线程池大小可以控制并发量,当线程池饱和时可以提前拒绝服务,防止依赖问题扩散。建议线程池不要设置过大,否则大量堵塞线程有可能会拖慢服务器。因此,当请求的服务网络开销比较大的时候,或者请求比较耗时的时候,最好使用线程隔离策略。这样,可以保证用户请求(如Tomcat)线程可用,不会由于业务服务原因,使用户请求一直处于阻塞或等待状态,而是快速失败返回。
信号量隔离方式是限制总的用户请求并发数,每次请求过来时**,请求线程和调用业务服务的线程是同一个线程**,更为轻量,开销更小。当我们请求缓存服务或者不涉及远程RPC调用(没有网络开销)服务的时候,应优先使用信号量隔离策略,因为这类服务通常会快速返回,不会占用容器线程太长时间,同时也减少了线程切换的一些开销,提高了服务效率。
另外,尽管线程池提供了线程隔离,我们的客户端底层代码也必须要有超时设置,不能无限制地阻塞,否则会造成线程池一直处于饱和状态。
5.5 服务降级模式
1)快速失败
在服务降级中不做任何处理,直接返回异常
2)静默失败
静默失败即当进行服务降级处理时返回空的结果,针对返回值类型,返回的可能是null、空List或者空Map等。
3)返回默认值
返回一个静态的值,这样速度更快
4)返回组装的值
通过服务请求中的值及一些默认值来组装这个返回结果
5)返回远程缓存
服务处理失败的情况下再发起一次远程请求,不过这次请求的是一个缓存.
要注意,执行fallback的线程一定要与主线程区分开,否则可能会造成主线程休眠,线程池被耗光,也就是说在执行fallback的命令时需要重新命名ThreadPoolKey
6 主/从降级模式
开发者当开发一个系统时可能会为系统设置双通道架构——主/从模式或者主模式和故障转移。有时候从模式或故障转移只是用来做失败处理,和前面的“返回远程缓存”模式一致。有时候开发者在部署新功能时,为了防止发生错误,可以将原来的旧代码作为从模式,当新功能出现错误时就降级使用原功能。
5.6 请求缓存
缓存处理是在construct()或run()方法调用之前,这样可以有效地减少业务服务请求数,降低了服务的并发

5.7 请求合并
Hystrix支持将多个请求自动合并为一个请求,通过合并可以减少HystrixCommand并发执行所需的线程和网络连接数量,极大地节省了开销,提高了系统效率
比如:查询一个用户和批量查询用户,
处理时需要注意
①对于请求合并的处理,需要实现上继承HystrixCollapser基类;
②还需要实现一个批量请求的BatchCommand,该Command负责调用用户服务的批量查询方法;
③然后再实现mapResponseToRequests()方法,将批量返回的结果映射到每个请求中。
5.8 Hystrix监控
实时查看服务服务提供者的状态信息
1)单机
①
添加依赖spring-boot-starter-actuator依赖
浏览器中输入:http://localhost:port/hystrix.stream即可查看数据,
②
添加依赖spirng-boot-starter-hystrix-dashboadr
主启动类中增加@EnableHystrixDashboard注解,开启Hystrix仪表盘服务
可以通过仪表盘可视化工具查看服务的健康状态
在浏览器中输入http://localhost:port/hystrix,可以进入到主界面。然后在界面中输入之前的地址http://localhost:port/hystrix.stream,单击Monitor Stream按钮,就可以看到统计报表页面。
2)集群部署
搭建Turbine服务器
6、API服务网关——Zuul
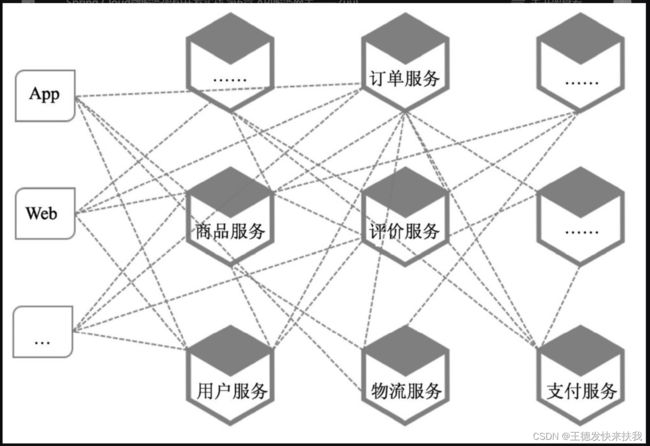
对于一个项目可能会有几十个,甚至几百个微服务,那个时候,如果客户端都直接去调用微服务,那么就加重了客户端的负担,而且对于权限认证,流量与并发控制等一些集中式的功能,也应该是统一处理,而不需要每一个微服务都需要去实现一遍,那么麻烦了。
没有服务网关的情况下,客户端和服务端的交互。
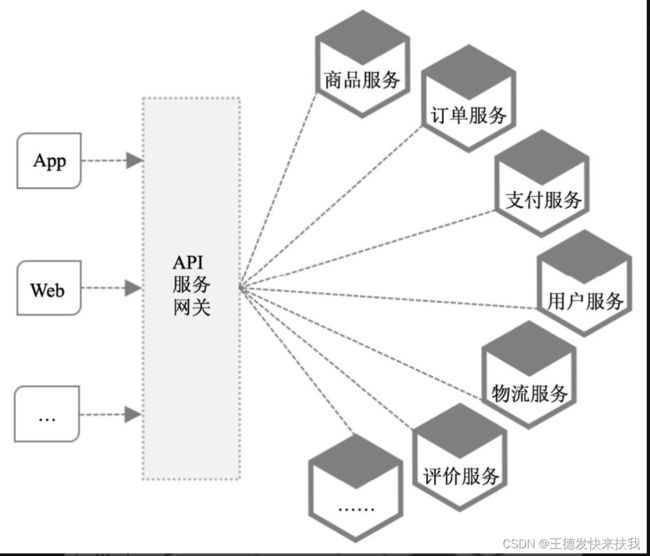
6.1 API服务网关(路由和过滤器)
网关的核心是:为所有客户端请求或其他消费者统一的网关通过该网关接入不同的微服务,并隐藏架构实现的细节,以及对客户端请求的过滤。这样也可以实现对系统内部架构的封装,将于业务无关的逻辑抽到到API服务网关中实现。
6.2 Spring Cloud与Netflix Zuul
Zuul。Netflix所提供的Zuul是一个基于JVM路由和服务端的负载均衡器,其参考GOF设计模式中的外观(Facade)模式,将细粒度的服务组合起来提供了一个粗粒度的服务,以便所有请求都导入一个统一的入口,整个服务只需要暴露一个API,对外屏蔽了服务端的实现细节。这就是之前提到的API服务网关功能
通过zuul组件,可实现以下功能
1)动态路由
zuul默认与eureka整合(其实我有一个问题,如果eureka是集群如何去配置,包括在使用ribbon的时候,也是默认使用的eureka注册中心,那么如何去手动指定呢?),可以对动态注册到eureka服务器中的服务进行路由映射(通过服务名+服务接口)
2)身份认证与安全
对客户端的请求做统一的处理,
3)压力测试(限流)
通过Zuul所提供的过滤器功能可以逐渐增加对某一服务集群的流量,以了解服务性能,从而及早对服务运维架构做出调优。
6.3 启用Zuul路由服务
1)构建zuul服务器
①pom依赖
②启动类加上@EnableZuulProxy注解
③配置文件

2)路由测试
通过zuul服务器去访问微服务,
http://localhost:port/服务名映射的路由(默认服务名的小写)/接口名/参数信息/…,
3)负载均衡测试
zuul默认集成了负载均衡的功能(如何实现?,那还要ribbon负载均衡干嘛?)
4)Hystrix容错和监控
zuul默认集成了hystrix和ribbon,所以也有容错和负载均衡的功能。
当使用path与url的映射关系来配置路由规则时,对于路由转发的请求则不会采用Hystrix Command来包装,所以这类路由请求就没有线程隔离和服务容错保护功能,并且也不会有负载均衡的能力,所以对路由的配置应该使用path和serviceId的组合

6.4 路由规则
①与Eureka服务器整合自动根据微服务的ID进行映射,这个是默认机制,也是之前示例中所使用的机制。
②结合微服务ID通过自定义方式进行路由映射。
③直接使用静态URL路径的方式对微服务进行路由映射。
④添加全局路由映射。
⑤通过自定义路由转换器,实现更灵活的路由映射。
1)默认规则

2) 自定义微服务访问路径
可以在Zuul路由服务器配置文件中通过增加格式为“zuul.routes.微服务Id=指定路径”的属性配置方式进行配置,对访问路径进行控制,例如:

3)忽略指定微服务
参数的值可以设置多个服务的ID,如果需要忽略多个服务,那么服务ID之间需使用逗号隔开即可

4)设置路由前缀

通过http://localhost:zuul服务ip/routes可以查看eureka下所有服务的请求地址和服务的映射关系
5) 通过静态URL路径配置路由映射
对于没有注册到eureka中的其他服务,但是这样就不会得到ribbon的负载均衡功能,因为默认是与eureka集成的,可以采取手动的方式配置

6)自定义路由规则
如果路由规则比较复杂,那么我们也可以定义一个转换器,让serviceId和路由之间使用自定义的规则进行转换。比如,在下面的代码中通过一个正则表达式来自动匹配,将形如servicename-vx的服务名称映射为/vx/servicename的访问路径。代码如下:
6.5 Zuul路由其他设置
1)Header设置
①敏感Header设置
当zuul服务器将请求转发给下游服务时,会将请求头的信息也转发过去,如果是第三方服务,不想header携带敏感信息转发给服务,那么就需要设置忽略Header的清单
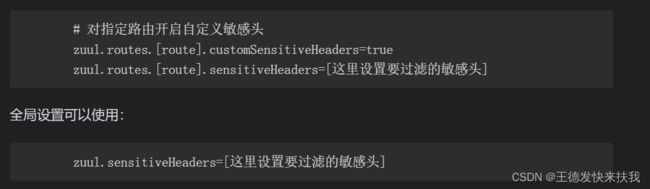
②忽略Header

2)路由配置的动态加载
通过SpringCloudConfig进行统一配置,后面章节会提到
6.6 Zuul容错与回退
访问zuul服务的hystrix的dashboadr,监控的不再是具体的某一个方法,而是一个完整的服务,假设其中某一个服务关掉了,那么zuul在调用服务时,肯定会等待超时。最后报错,
1)实现zuul回退
Zuul提供了一个ZuulFallbackProvider接口,通过实现该接口就可以为Zuul实现回退功能


2)服务超时
注意到超时的时候,ribbon和hystrix回退的超时时间设置要合理
6.7 Zuul过滤器
过滤器的功能则是负责对请求的处理过程进行干预,是实现请求校验
1)过滤器特性
①过滤器源码:
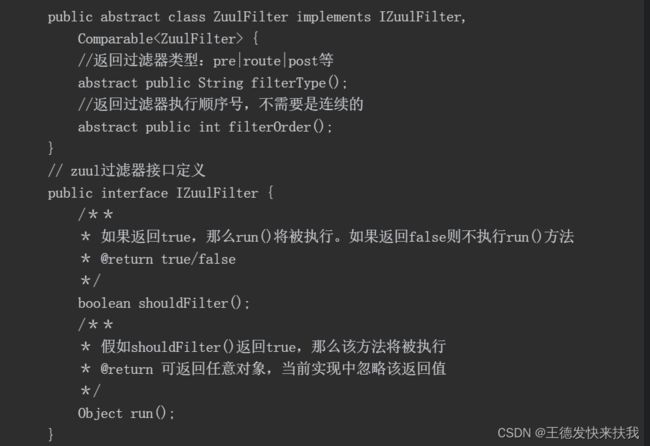
②核心特性
Type:定义在请求执行过程中何时被执行;
Execution Order:当存在多个过滤器时,用来指示执行的顺序,值越小就越早执行;Criteria:执行的条件,即该过滤器何时被触发;
Action:该过滤器具体要执行的动作。
③对应上面的Zuul过滤器特性和源码,在实现一个自定义过滤器时需要实现的方法有以下几点:
filterType()方法返回过滤器的类型;
filterOrder()方法返回过滤器的执行顺序;
shouldFilter()方法判断是否需要执行该过滤器;
run()方法是该过滤器所要执行的具体过滤动作。
2)过滤器类型及生命周期
①过滤器类型(每种过滤器类型都有很多实现,根据开启的注解不同,加载的实现类也不一样)
PRE过滤器:在请求被路由之前调用,可用来实现身份验证、在集群中选择请求的微服务、记录调试信息等。
ROUTING过滤器:在调用目标服务之前被调用,通常可以用来处理一些动态路由。比如,A/B测试,在这里可以随机让部分用户访问指定版本的服务,然后通过用户体验数据的采集和分析来决定哪个版本更好。另外,还可以结合PRE过滤器实现不同版本服务之间的处理。
POST过滤器:在目标微服务执行以后,所返回的结果在送回给客户端时被调用,我们可以利用该过滤器实现为响应添加标准的HTTP Header、数据采集、统计信息和指标、审计日志处理等。
ERROR过滤器:该过滤器在处理请求过程中发生错误时被调用,可以使用该过滤器实现对异常、错误的统一处理,从而为客户端调用显示更加友好的界面。
②各个过滤器的执行流程

3)禁用过滤器

6.8 @EnableZuulServer与@EnableZuulProxy比较
ZuulProxy注解包含了ZuulSever而且,开启了hystrix和ribbon的功能,但是二者在加载过滤器功能时有所不同
①EnbableZuulProxy
②EnableZuulServer
7、统一配置中心——Config
服务可能会有很多个,每一个服务都有配置文件,对配置文件的修改集成在了项目中,对于开发和后期维护都有很大的困难,我们可以将配置作为一个独立的服务来管理项目其他的服务的配置文件,这样就可以把配置文件独立出放到具有版本控制的git或者svn上,
7.1 Spirng Cloud Config简介
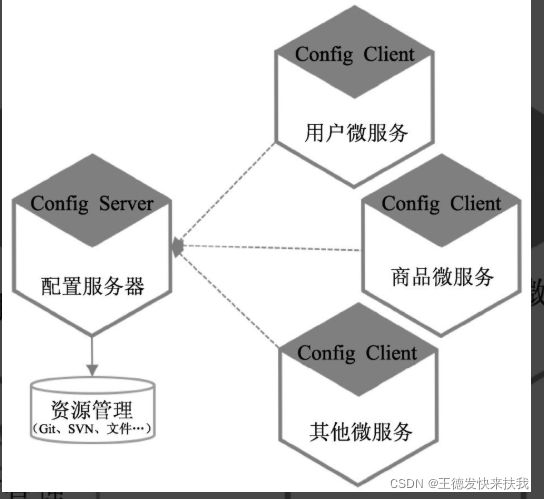
1)提供的功能(优势)
①提供配置服务器(Config Server)和配置客户端(Config Client)两种角色,便于部署和使用,使开发者可以集中式管理分布式环境下的应用配置。
②配置服务器集中对配置资源进行管理,并支持多种配置资源存储方式,如Git、SVN及文件系统。
③通过对Git、SVN库的支持,便于对配置文件进行版本管理,后续可以对配置文件的变更做审查。
④基于Spring环境,与Spring Boot深度整合,在应用中通过几个简单的注解就可以实现配置的统一管理,而不需要过多的投入。
⑤Spring Cloud Config提供与Spring Boot配置类似的机制,可以非常容易地实现对应用开发环境、测试环境、仿真环境和生产环境的配置、切换和迁移等处理。
⑥配置服务器可以方便地与Eureka和Consul等进行整合,快速构建一个高可用的配置服务。
⑦配置服务器也可用于其他语言开发的服务中。
2)系统架构
7.2 快速启动
1)构建配置服务器
①新建项目修改pom.xml依赖

②主启动类上开启注解@EnableConfigServer
③配置文件

config默认集成的是git,需要写git仓库的真实地址以及用户名和密码
2)在仓库中添加配置文件

http://localhost:config服务端口/productservice/default,可以查看服务配置文件里的内容
3)升级微服务配置
①在原来服务项目中添加pom依赖

②编写bootstrap.properties配置文件,
这个配置文件负责从外部加载配置属性并且进行解析,配置文件优先级高于本地配置,

3)@Value注解
使用远程配置文件的情况下也是支持注解注入属性的。
4)Spring配置加载顺序
JVM参数>jar包同级目录配置文件>内部配置文件(细分还有几个目录)>yml>yaml>proeprties
7.4 配置的加密与解密
7.5 配置服务器访问安全
防止通过服务器地址直接访问到服务的配置信息,使用SpringSecurity框架,
1)添加依赖和配置

在bootstrap.properties中添加用户名和密码,如果不设置,那么会默认生成一个密码
在此访问config服务的时候,就需要进行用户认证了
同时配置的服务端也需要加上访问用户名和密码,同样在bootstrap.properteis中
7.6 配置服务器的高可用
将配置服务器也做为一个服务注册到eureka中,
1)整合eureka
①添加eureka依赖和指定eureka服务器,并且开启注解
②其他服务bootstrap.properties中指定的配置服务器的uri可以直接指定eureka的服务名

2)快速启动
我们希望在配置服务器启动的时候就去加载配置,如果加载失败就快速返回失败

3)动态刷新配置

8、分布式服务跟踪——sleuth
对于一个用户请求,往往需要多个微服务协同才能处理并形成结果返回给用户,在这个过程中,用户请求所经过的每一个微服务都会形成一个复杂的、分布式的服务调用链路,链路中的任何一环出现问题或者网络超时,都会导致用户请求的失败。虽然可以使用Hystrix对用户请求进行保护,但是当出现这种情况时如何对整个请求处理链进行分析,在运维过程中是非常重要的一环。
8.1 Spring Cloud Sleuth简介
SpringCloudSleuth为微服务之间提供了一套完整的服务链路跟踪方案。
1)通过Spring Cloud Sleuth可以帮助开发者做以下几件事。
①耗时分析:通过Sleuth可以很方便地了解到每个采样请求的耗时,从而分析出哪些微服务调用比较耗时。
②可视化错误:对于程序未捕捉的异常,可以在集成Zipkin服务界面上看到。
③链路优化:通过Sleuth可以轻松识别出调用比较频繁的微服务,开发者可以针对这些微服务实施相应的优化措施。
2)Sleuth的实现原理
①服务追踪:对于同一个用户请求,认为是同一条链路,并赋值一个相同的TraceID,在后续中通过该标识就可以在多个微服务之间找到完整的处理链路。
②服务监控:对于链路上的每一个微服务处理,Sleuth会再生成一个独立的SpanID,同时记录请求到达时间和离开时间等信息,以作为用户请求追踪的依据,从而判断每一个微服务的处理效率。
3)执行流程
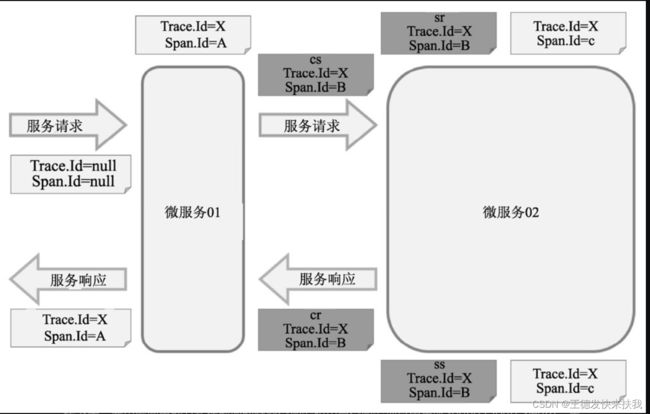
①Span:是Sleuth中最基本的工作单元。微服务发起一次请求就是一个新Span。Span使用唯一的、长度为64位的ID作为标识。在Span中可以带有其他数据,如描述、时间戳、键值对、起始Span的ID等数据。Span有起始和结束,可以用于跟踪服务处理时间信息。Span一般都是成对出现,因为有始必有终,所以一旦创建了一个Span,就必须在未来某个时间点结束它。
②Trace:一次用户请求所涉及的所有Span的集合,采用树形结构进行管理。③Annotation:用于记录时间信息,包含了以下几项。
✧ cs:客户端发送(Client Sent),表示一个Span的起始点。
✧ sr:服务端接收(Server Received),表示服务端接收到请求并开始处理。如果减去cs的时间戳,则可以计算出网络传输耗时。
✧ ss:服务端完成请求处理,应答信息被发回客户端(Server Sent)。通过减去sr的时间戳,可以计算出服务端处理请求的耗时。
✧ cr:客户端接收(Client Received),标志着一个Span生命周期的结束,客户端成功地接收到服务端的应答信息。如果减去cs的时间戳,则可以计算出整
8.1.1 快速启用Sleuth
在原来微服务基础上添加新的功能。
1)修改配置文件BootStrap.proiperties

2)添加依赖

3)启动测试
依次启动eureka,微服模块,这是访问接口就会在控制台打印整个接口的调用链路,
数据格式:
[ApplicationName, TraceId, SpanId, Exportable],该数据包含了下面4种信息。
①ApplicationName:这里的值为productservice,是Sleuth当前所追踪服务的服务名称,也就是前面在bootstrap.properties文件的配置。需要注意,该值必须在bootstrap.properties文件中进行配置,这是由于日志框架启动时间较早造成的。如果是在application.properties文件中进行配置,则会因为该配置数据尚未加载而导致日志框架无法获取到该值。
②TraceId:这里的值为826bfe5c0116e8f3,对应于客户端的每次请求,也就是一次请求处理的链路。通过该标识符就可以找到一次客户端请求完整的处理链路。
③SpanId:这里的值为826bfe5c0116e8f3,对应于每次请求中每一个处理部分,也就是该请求链路中的每一环,是Sleuth追踪的最基础工作单元。一次链路请求最起始的Span通常被称为根Span(Root Span),它的ID通常也被作为Trace的ID,因此**在这里TraceId和SpanId的值是一样(起始服务和第一个服务是一样的)**的。
④Exportable:是否将追踪到的信息输出到Zipkin服务器等日志采集服务器上。关于Zipkin服务器,将在后面章节中进行介绍。
8.1.2 Sleuth与日志框架
默认情况,Sleuth会默认与Slf4j MDC(Mapped Diagnostic Context,映射调试上下文)进行整合,当在项目中没有对日志配置进行覆写的话,启动Sleuth后上述追踪数据时就会立即在日志中显示
8.2 Sleuth与ELK整合
将服务调用链路的信息存储到日志处理整合在ELK框架上
ELK:指得是ElasticSearch(分布式的大数据处理的全文检索引擎),LogStash(日志采集框架,可以对采集到日志过滤和输出到ES中),kiabana(针对于ES的可视化工具),是当前非常热门的一项技术,
1)日志输出到logstash
SpringBoot项目默认采用LogBack,而LogStash本身也对Logback有相应的支持工具,可以直接在LogBack中增加Appender,就可以将日志转化成JSON格式的字符串并输出到LogStash上
①添加依赖
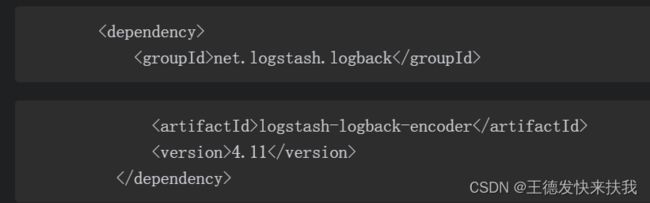
日志配置文件修改,对于LogStash的配置可以查阅相关资料

2)8.2.2 Logstash与Log4j的集成
如果使用的是Log4j,那么日志配置文件修改为

8.3 整合Zipkin服务
Zipkin致力于收集分布式系统中的时间数据,并进行跟踪。通过Zipkin可以为开发者采集一个外部请求所跨多个微服务之间的服务跟踪数据,同时以可视化的方式为开发者展现服务请求所跨越多个微服务中耗费的总时间及各个微服务所耗费的时间。可以说Zipkin是微服务架构下一个用来监控微服务效能的非常强大的工具。
ZipKin并不是Spring Cloud下的一个子项目,而是一个开源项目,可以从GitHub中获取,地址为https://github.com/openzipkin/zipkin。
1)主要组件
①collector:数据采集组件,用来收集Sleuth所生成的跟踪数据。
②storage:数据存储组件,将采集的数据进行存储以便后续进行分析。
③search:数据查询组件,对采集到的数据处理后,就可以通过查询组件进行过滤、分析等处理。
④UI:数据展示组件。
2)storage数据存储方案
①In-Memory:将采集到的数据保存在内存中。如果是测试环境中推荐这种方式,使用和配置都比较简单,但是在生产环境中最好还是不要使用该方式,因为一旦服务关闭,所有数据都会丢失。
②MySQL:将采集到数据保存到MySQL数据库中。
③Cassandra:是一个使用非常广泛的关系型开源数据库。
④Elasticsearch:前面在做ELK整合时已经介绍过,在生产环境中个人推荐使用该存储,这样就能和之前的日志聚合进行统一。
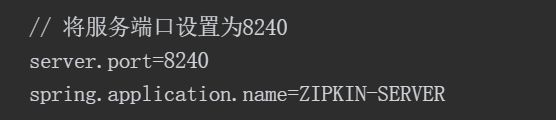
8.3.1 构建Zipkin服务器
单独构建一个独立的Zipkin服务
1)依赖和配置
①依赖

②配置:
启动类上加入注解@EnableZipkinServer
服务器配置
8.3.2 整合微服务

8.3.3 Zipkin分析
通过zipkin可视化面板,可以查看每个用户请求的调用链路,以及每个Span的响应时间。
8.3.4 输出TraceId
如果请求过多,那么查看某一个请求就会很难,但是可以通过TraceIId获取,因为他标识的是一个请求的唯一性,但是如何知道Id,而且这个ID是随机的,很难记忆。
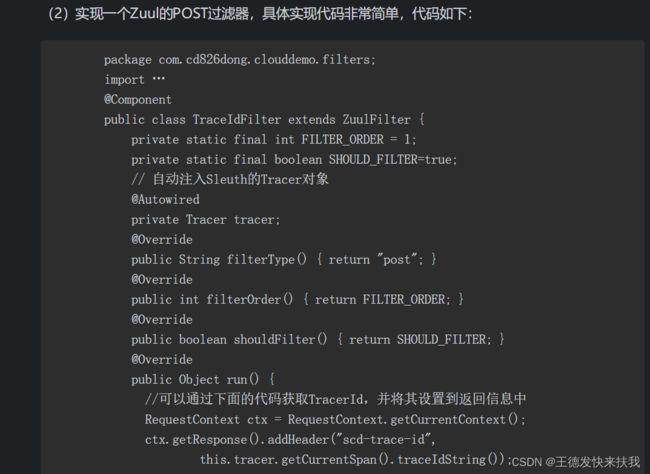
实现:通过Zuul服务网关在请求完成后输出TraceId
1)zull服务依赖和配置
①依赖
 ②配置
②配置
8.4 Sleuth抽样采集与采样率
在真实线上环境中,如果采集所有的用户请求,那么请求量肯定是巨大的,如果全部采集,一是对业务有影响,二是对存储压力有影响,所以采样就很重要了
Sleuth提供了Simpler策略,默认采用水塘抽样算法,也就是,采样比默认是0.1,也可以通过@Bean选择其他抽样方式

9、消息驱动——Stream
通过消息中间件所提供的松散耦合的方式——存储和转发微服务之间的异步数据,使得微服务之间彼此不需要直接通信,而是与作为中介的消息中间件进行通信,从而将微服务应用集成在一起。微服务开发人员可以在无须过多了解底层调用和网络与通信协议细节的情况下,通过发送和接收消息,可以方便、可靠地实现微服务之间的消息传递。因此,消息中间件几乎成了微服务架构体系下的标配中间件。
9.1 什么是消息驱动开发
1)消息驱动开发间接
微服务A与微服务B通过消息中间件进行消息的传递。当微服务A发送消息给微服务B时,将由消息中间件负责处理网络通信。如果网络连接不可用或者微服务B不在线,则消息中间件会存储消息,直到连接变得可用或微服务B恢复时,再将消息转发给微服务B。这样保障了消息传递的可靠性

2)同步和异步模式
在分布式环境下,消息中间件支持同步方式和异步方式的消息传递。异步方式的消息传递比同步方式具有更强的容错性,能够保障在系统故障时消息正常可靠地传输。异步消息中间件的消息传递模式又可以分为两种:点对点模式和“发布-订阅”模式。
①点对点模式:该模式常用于消息生产者和消息消费者之间点到点的通信;
②**“发布-订阅”模式**:该模式使用主题(Topic)代替点对点中的目的消费者。此时消息生产者只需要将消息发布到主题中即可,而不需要关心是谁消费该消息;而消费者如果需要消费消息,只需要订阅相应的主题,当有消息时消息中间件就会推送该消息。
2)基于消息中间件开发的优点
①降低耦合度:大大减少微服务之间的依赖和调用
②改善应用性能:在异步模式,即使某个服务不可用,也不会影响其他服务
③提高了应用的可扩展性:符合面向对象的开闭原则
④提供了系统的可用性
⑤更灵活的系统集成
3)基于消息中间件的缺点
①更复杂的应用架构
②更具挑战的开发模式
③更陡峭的学习曲线
9.2 Spring Cloud Stream简介
Spring Cloud Stream是创建消息驱动微服务应用的框架,其基于Spring Boot,可以用来构建单独的或者工业级Spring应用,支持与多种消息中间件整合,如Kafka、RabbitMQ等,使用SpringIntegration提供与消息代理之间的连接,为应用程序的消息发布和消费提供了一个平台中立的接口,将实现的细节独立于应用代码之外,从而有效简化了上层研发人员对各消息中间件使用上的复杂度,让开发者更加专注于核心业务的处理。
1)应用模型

①消息发送通道接口Source
消息发送通道接口用于Spring Cloud Stream与外界通道的绑定,我们可以在该接口中通过注解的方式定义消息通道的名称。当使用该通道接口发送一个消息时,Spring Cloud Stream会将所要发送的消息进行序列化,然后通过该接口所提供的MessageChannel将所要发送的消息发送到相应的消息中间件中。
②消息通道Channel
消息通道是对消息队列的一种抽象,用来存放消息发布者发布的消息或者消费者所要消费的消息。在向消息中间件发送消息时,需要指定所要发送的消息队列或主题的名称,而在这里Spring CloudStream进行了抽象,开发者只需要定义好消息通道,消息通道具体发送到哪个消息队列则在项目配置文件中进行配置,这样一方面可以将具体的消息队列名称与业务代码进行解耦,另外一方面也可以让开发者方便地根据项目环境切换不同的消息队列。
③消息绑定器Binder
**Spring Cloud Stream通过定义绑定器作为中间层,实现了应用程序与具体消息中间件细节之间的隔离,向应用程序暴露统一的消息通道,使应用程序不需要考虑与各种不同的消息中间件的对接。**当需要升级或者更改不同的消息中间件时,应用程序只需要更换对应的绑定器即可,而不需要修改任何应用逻辑。Spring Cloud Stream默认提供了对RabbitMQ和Apache Kafka的绑定器,在应用中开发者只需要引入相应的绑定器就可以实现与RabbitMQ或者Kafka的对接,从而进行消息的发送与监听。SpringCloud Stream会根据类路径自动侦测开发者使用何种绑定器,当然,开发者也可以在项目中同时使用不同的绑定器,只要把相关的依赖代码包含进来即可,甚至可以让项目在运行时动态地将不同的消息通道绑定到不同的绑定器上。
④消息监听通道接口Sink
与消息发送通道接口(Source)相似,消息监听通道接口则是Spring Cloud Stream提供应用程序监听通道消息的抽象处理接口。当从消息中间件中接收到一个待处理消息时,该接口将负责把消息数据反序列化为Java对象,然后交由业务所定义的具体业务处理方法进行处理。
2)编程模型
Spring CloudStream还提供很多开箱即用的接口声明及注解,来声明约束消息发送和监听通道
①声明和绑定消息通道
@EnableBinding注解是告诉应用需要触发消息通道的绑定,将我们的应用变成一个Spring CloudStream应用。@EnableBinding可以应用到Spring的任意一个配置类中,因为注解本身就包含@Configuration注解,所以一旦增加该注解,就会触发Spring Cloud Stream进行基本配置,将应用升级为一个Spring Cloud Stream应用。此外,@EnableBinding注解中可以声明一个或多个消息发送通道接口或消息监听通道接口参数。
@Input注解是用在消息监听通道接口的方法定义上,用来绑定一个具体的消息通道。例如前面所说的消息监听通道接口Sink,该接口就是Spring Cloud Stream提供的一个开箱即用的消息监听通道接口定义
@Output注解是用在消息发送通道接口的方法定义上,用来绑定消息发送的通道。而Source接口就是Spring Cloud Stream提供的开箱即用的消息发送通道接口定义
②访问消息通道
首先是声明和绑定消息通道,然后就可以访问Spring Cloud Stream所绑定的消息通道了。对于使用@EnableBinding绑定的每一个接口,Spring Cloud Stream都会自动构建一个Bean,并实现该接口。当我们通过该Bean调用哪些注解了@Input或@Output的方法时,就会返回相应的消息发送或订阅通道。
③发布或监听消息
在消息监听处理时可以使用Spring Integration的注解或者Spring Cloud Stream的@StreamListener注解来实现。Spring Cloud Stream所提供的@StreamListener注解模仿Spring的其他消息注解(如@MessageMapping、@JmsListener和@RabbitListener等)。同时@StreamListener注解还提供了一种更简单的模型来处理输入消息,尤其当所要处理的消息包含了强类型信息时
3)使用“发布-订阅”模式
示例图
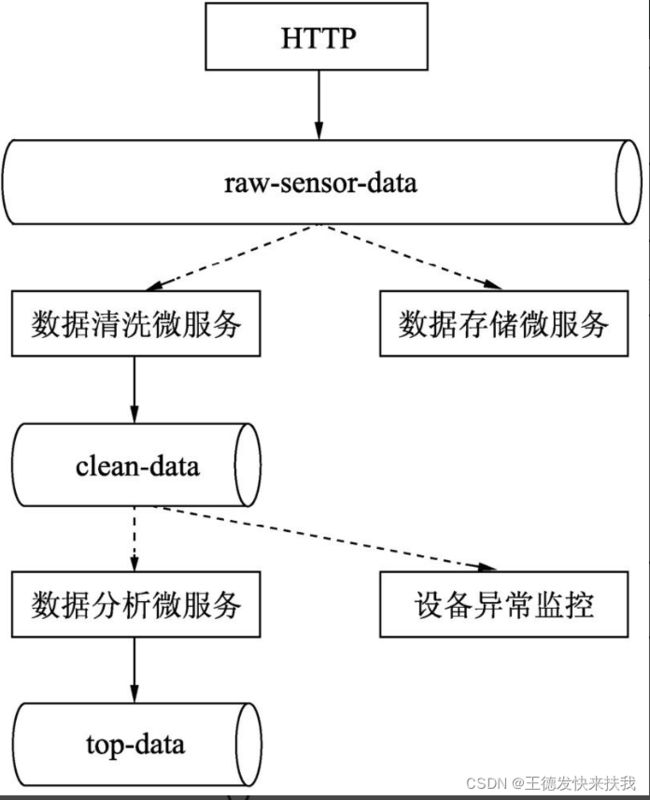
发布-订阅模式可以将两个或多个互相依赖的应用进行解耦,使它们可以各自独立地改变和复用,这样就会给系统维护、扩展和重用带来便利。Spring Cloud Stream进行了一些扩展将发布-订阅模式作为应用的一种可选,并且通过原生中间件的支持,简化了在不同平台使用发布-订阅模式的复杂性。
传感器所采集的数据通过一个HTTP端点发布到raw-sensor-data主题上。另外有两个独立的微服务,一个用来计算传感数据的平均值,另一个是将这些原始数据存放到HDFS中,这两个微服务都分别订阅了raw-sensor-data主题上的消息。可见,通过使用发布-订阅模式消息的生产者和消费者都大大减少了复杂性,而且当添加一个新的应用时,也不需要对现有的业务流程做修改。例如,对于传感数据需要计算一个最大值,用来进行显示和监控,还需要对计算的平均数据进行故障和异常数据检测,这些新的应用都可以很轻松地进行扩展,而不需要破坏现有的应用。
9.3 Kafka使用指南
Apache Kafka源于LinkedIn,是一个分布式的发布-订阅消息系统
1)Kafaka基本知识
①主题Topic
在Kafka中将每一个不同类别的消息称为一个主题Topic。在物理上,不同主题(Topic)的消息是分开存储的。在逻辑上,同一个主题(Topic)的消息可能保存在一个或多个代理(Broker)中,但对于生产者或消费者来说,只需指定消息的主题(Topic)就可生产或消费数据,而不用关心消息数据到底存于何处。
②生产者Producer
生产者也就是消息的发布者。负责将消息发布到Kafka中的某个主题(Topic)中,消息代理(Broker)在接收到生产者所发送的消息后,将该消息追加到当前分区中。生产者在发布消息的时候也可以选择将消息发布到主题上的哪一个分区上。
③消费者Consumer
消费者从消息代理(Broker)中读取消息数据并进行处理。一个消费者可以同时消费多个主题(Topic)中的消息。此外,Kafka还提供了消费者组(Consumer Group)的概念,发布在主题上消息的可以分发给此消费者组中的任何一个消费者进行消费。
④消息代理Broker
生产者所发布的消息将保存在一组Kafka服务器中,称之为Kafka集群。而集群中的每一个Kafka服务器节点就是一个消息代理Broker。消费者通过消息代理从中获取所订阅的消息并进行消费。
⑤消息分区Partition
主题所发布的消息数据将会被分割为一个或多个分区(Partition),每一个分区的数据又可以使用多个Segment文件进行存储。在一个分区中的消息数据是有序的,而多个分区之间则没有消息数据顺序。如果一个主题的数据需要严格保证消息的消费顺序,那么需要将分区数目设为1。
2)搭建Kafka环境
因为书中的较为老旧,可以自行去查看资料下载安装
9.4 使用消息对应用重构
1)应用问题
我们看到商品微服务中的评价管理,在每次加载数据时都需要通过用户微服务获取评论者的用户信息。这种做法有两个缺陷:一是每次都进行请求会造成服务效率低下;二是一旦用户微服务不可用,势必对评价功能造成影响(不论是否使用降级处理)
2)利用缓存解决
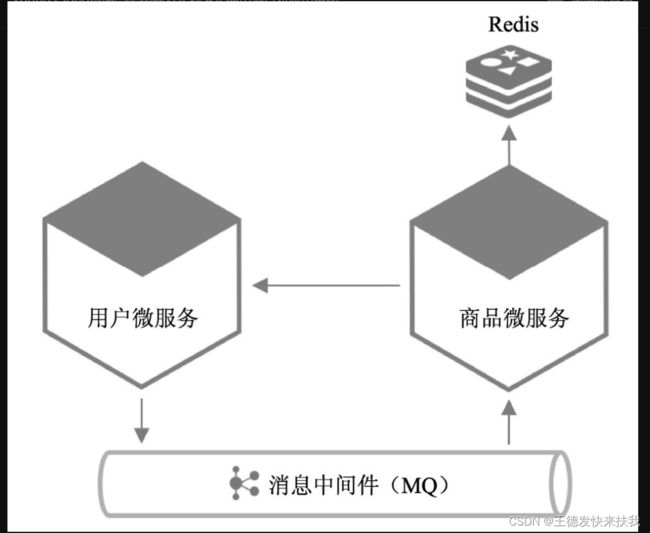
这里redis配置和操作,后面再补充,当缓存的数据跟新之后,同步跟新缓存里的数据
3)用户服务和商品服务都集成stream-kafka
用户服务更新用户信息之后,通知商品服务更新用户信息
用户服务修改后,发送消息Source.output().send(MessageBuilder.withPayload(对象).build()),
商品服务添加消息监听功能,自定义一个类添加@EnableBinding(Sink.clas),在类中的方法上添加@StreamListener(Sink.INPUT),在方法中对对用户的改变而去跟新商品信息。
9.5 Spring Cloud Stream高级主题
1)单元测试
单元测试是开发过程中必不可少的一环。在面向消息驱动的开发中,Spring Cloud Stream为开发者提供了一个TestSupportBinder来支持单元测试,可以让开发者在没有连接到消息中间件的情况下完成测试。通过TestSupportBinder可以模拟访问消息通道,并进行消息的发送与监听。
对于消息发送,TestSupportBinder会注册一个类型为MessageCollector的Bean,通过该Bean可以获取到所发送的消息,这样就可以判断消息是否发送成功。对于消息监听测试,则可以通过直接向入站通道发送消息进行模拟。下面来看一个单元测试示例。
2)错处处理
Spring Cloud Stream提供了一个全局错误消息处理通道,当出现异常时,Spring Cloud Stream就会将该异常包装成ErrorMessage,然后发送到该消息通道中。默认该消息通道的名称为errorChannel,可以通过项目配置文件中的spring.cloud.stream.bindings.error.destination属性来指定通道的名称,比如下面的配置,会将错误消息通道的名称设置为myGlobal ErrorChannel。

3)消息处理分发
Spring Cloud Stream从1.2版本开始,支持将同一个消息通道中的消息,根据条件分发给不同的方法进行处理。相应的方法除了需要@StreamListener注解外,还需要满足以下条件:
①该方法没有返回值。
②该方法只能处理独立的消息,不能是响应式消息处理器。消息分发的条件可以通过@StreamListener注解中的condition属性设定,条件可以使用SpEL表达式(关于SpEL表达式,可以参考:https://docs.spring.io/spring/docs/current/spring-framework-reference/core.html#expressions)。
在进行消息分发处理时,Spring Cloud Stream会对每一个条件进行求值,所有符合条件的方法都会在同一个线程中执行,但并不保证执行的顺序
4)消费者组与消息分区
发布-订阅模式通过共享主题使应用之间的连接更加容易,但是应用的水平扩展也是非常重要的。通常,对于一个消息只需要一个实例进行处理即可,所以当一个应用存在多个实例时,这些实例之间便会成为同一个消息相互竞争的消费者。Spring Cloud Stream通过消费者组的概念给这种情况进行建模。既然是一个组,那么组内必然可以有多个消费者或消费者实例(也就是微服务实例),它们之间共享一个相同的ID,即消费者组ID。消费者组内的成员统一在一起消费所订阅消息中的所有消息,而消息中的每个分区只能由同一个消费者组内其中的一个消费者(应用)来消费。默认情况下,如果没有为应用指定消费者组,Spring Cloud Stream会为该应用创建一个匿名组,并且该组中只有其一个应用。开发者也可以在应用的配置文件中设置spring.cloud.stream.bindings.input.group属性来指定所属消费者组的ID。一般来说,在创建应用时,最好为其指定一个消费者组,这样可以防止当启动多个应用实例时收到重复的消息(除非你的应用需要处理每个应用实例)。
5)消息绑定器
前面说过Spring Cloud Stream通过提供了一个抽象的绑定器作为中间层,实现了与具体消息中间件(RabbitMQ、Kakfa等)连接,应用程序通过Spring Cloud Stream所暴露的统一的消息通道进行消息的发送与监听。通过这种方式一方面大大减少了使用消息中间件的难度,另一方面使应用代码与具体的消息中间件可以解耦,在生产中可以根据需要对接不同的消息中间件。下面让我们深入了解一下绑定器的运作原理。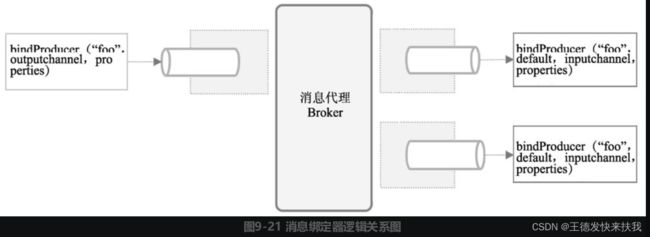
9.6 消息总线——Spring Cloud Bus
Spring Cloud Bus建构在Spring Cloud Stream之上,是一个轻量级的通信组件,可以将分布式系统中的节点与轻量级消息代理连接,从而实现状态更改(如上面说的配置信息更改)广播或其他事件的广播。
9.6.1 完成配置自动刷新配置

1)依赖和配置


2)修改微服务
①商品服务
②用户微服务,只需要引入Spring Cloud Bus依赖即可。
9.6.2 发布自定义事件
通过Spring Cloud Bus也可以发布自定义事件,所发布的事件需要继承自RemoteApplicationEvent。在发布事件时默认会将事件转换为JSON格式,在反序列化时也需要使用到该事件的类型。因此,事件发布者和监听者都需要访问这个事件类,或者保持这两个类一致。也可以用@JsonTypeName注解来自定义序列化中的类名,但在接收端也要有同样的定义。
10、微服务应用安全——Security
1)只有认证的用户才能访问应用,也就是用户认证
2)用户要有相关的权限才能访问某个资源
10.1 Spring Boot的应用安全
Spring Security是基于Spirng AOP和Servlet的过滤,充分利用了Sping的IOC和AOP功能。
1)实现用户认证
①依赖和配置
添加依赖:

如果没有指定用户的话默认有一个user用户,密码会在项目启动的时候打印在控制台,这是访问接口就需要携带上用户信息,在Http请求头中的Authorization中添加用户和密码
自定义类继承WebSecurityConfigurerAdapter,重写认证方法,可以从数据库中获取用户信息认证,
2)实现用户授权
根据用户的权限限制资源访问,

10.2 微服务安全
由于服务很多,一个用户请求可能需要设计到多个服务,不可能在每个服务中都去判断用户权限,
David Borsos提出的四个解决方案
①单点登录:每个服务都需要与认证服务交互,会造成重复认证,而且增大服务器的压力
②分布式会话:将会话信息存储在Nosql,如redis,服务共享会话数据,高可用和扩展,不能直接采用session,分布式中多个微服务session不共享。
③客户端令牌Token:令牌由客户端保存,服务端进行认证,令牌中包含用户的信息,但是如何及时注销用户认证是个问题。
④客户端令牌和服务网关结合:服务网关对外提供了统一的访问接口,这样有利于对用户的请求做统一处理。相对于分布式session,安全性更高一些。
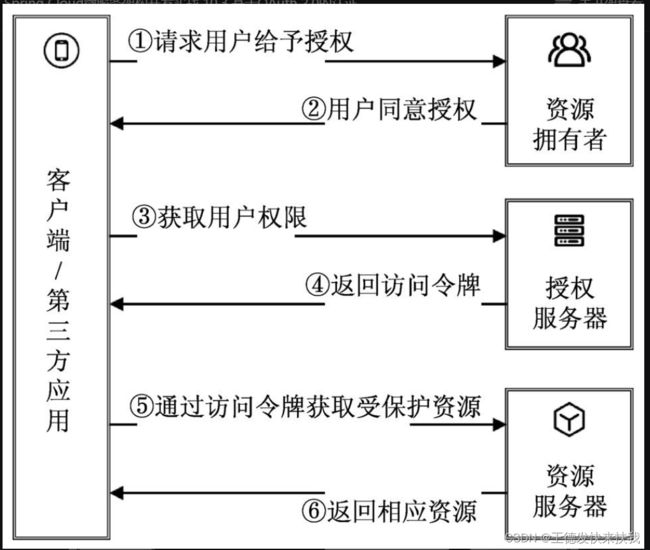
10.3 基于OAuth 2.0的认证
OAuth是一个开放的、安全的用户认证协议,允许用户让第三方应用访问该用户在某一网站上存储的私密的资源,而无须将用户名和登录口令提供给第三方应用
1)OAuth2.0授权流程
2)客户端授权模式
①授权码模式(Authorization Code)
 (1)用户访问客户端,客户端将用户引导到授权服务器上。
(1)用户访问客户端,客户端将用户引导到授权服务器上。
(2)用户选择是否同意给客户端授权。
(3)如用户同意授权,授权服务器将重定向到客户端事先指定的地址,同时附加上一个授权码(Token)。
(4)客户端收到授权码后,同时附加上需要重定向的页面(如果有的话),经由客户端后台向授权服务器申请令牌。
(5)授权服务器校验授权码后,向客户端发送访问令牌(Access Token)和更新令牌(RefreshToken)并重新定向到上一步指定的页面。
②简化模式(Implicit)
简化模式是指不通过客户端的后台服务器来获取访问令牌,这里的客户端通常是浏览器,客户端直接通过脚本语言(一般是JavaScript)来完成向授权服务器申请访问令牌的操作。具体流程如下:
(1)用户访问客户端,客户端将用户引导到授权服务器上,并附加认证成功或失败时需要重定向的URI。
(2)用户选择是否同意给客户端授权。
(3)如用户同意授权,那么授权服务器根据user-agent中的数据进行验证,验证通过后将用户重定向到之前所指定的地址,同时在所重定向的地址中附加一个相应访问令牌的值;
(4)浏览器将返回的信息保存在本地,然后向资源服务器发出请求,但不包括访问令牌。
(5)资源服务器返回一个网页,通常在该网页中会包含一段代码,该代码可以获取之前返回的访问令牌。
(6)浏览器执行上一步中获得的脚本,并获取到访问令牌。
(7)浏览器将解析到的访问令牌发送给客户端。
③密码模式(Resource Owner Password Credentials)
密码模式是指客户端通过用户提供的用户名和密码信息,直接通过授权服务器来获取授权。在这种模式下,用户需要把自己的用户名和密码提供给客户端,但是客户端不得储存这些信息。该模式只有在用户对客户端高度信任的情况下或者同一个产品系列中,在实际生产中应避免使用这种授权模式。该模式的授权流程如下:
(1)用户向客户端提供相应的用户名和密码。
(2)客户端通过用户提供的用户名和密码向授权服务器请求访问令牌。
(3)授权服务器确认后,返回访问令牌给客户端。
④密码模式(Resource Owner Password Credentials)
密码模式是指客户端通过用户提供的用户名和密码信息,直接通过授权服务器来获取授权。在这种模式下,用户需要把自己的用户名和密码提供给客户端,但是客户端不得储存这些信息。该模式只有在用户对客户端高度信任的情况下或者同一个产品系列中,在实际生产中应避免使用这种授权模式。该模式的授权流程如下:
(1)用户向客户端提供相应的用户名和密码。
(2)客户端通过用户提供的用户名和密码向授权服务器请求访问令牌。
(3)授权服务器确认后,返回访问令牌给客户端。
3)实现用户认证和授权
搭建OAuth2.0认证服务器
①依赖和配置
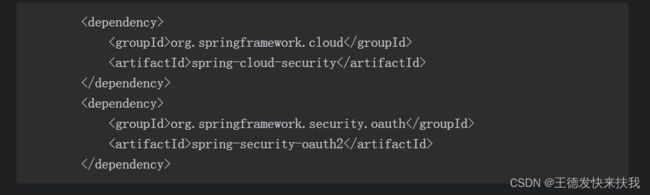
在主启动类上添加@EnableAuthorizationServer注解
②继承AuthorizationServerConfigurerAdapter
发过与OAuth集成应用的读者都知道,当需要和第三方认证集成时通常要提供一个ClientID(或AppID)和ClientSecret(或AppSecret)用来进行认证。对于我们所要搭建的OAuth认证服务器也一样,只有认证后的应用才可以使用所提供的用户认证服务
需要扩展Spring的AuthorizationServerConfigurerAdapter,并覆写其中的configure()方法
③继承WebSecurityConfigurerAdapter,重写认证和授权方法
4)整合API服务网关
zuul服务网关会过滤掉敏感Header(Cookie,set-cookie,Authorization)
从新设置敏感header

10.4 基于JWT的认证
1)JWT简介
①JWT加密后的字符串由三段信息组成
头部(Header):JWT的基本信息,如类型、签名等
载荷(payload):存储令牌的有效信息
签名(signature):将头部和载荷进行Base64编码后,使用加密方法进行签名,签名后的结果就放在这部分内容中
②认证流程

2)使用JWT改造服务
①依赖和配置

添加JWT配置类

3)zuul中对JWT进行解析
①依赖和配置

在zuul的过滤器中对token信息进行解密
4)改造商品服务
zuul对JWT解析之后传给下游的服务,这是在服务的过滤器中获取解密之后的用户认证信息进行过滤即可。
三、微服务与docker
微服务项目有多个,不可能自己一个一个手动的上线和下线。
11、微服务与Docker
11.1 Docker简介
Docker已经发展成为世界领先的软件容器虚拟化平台
虚拟机简单说就是指在一个操作系统里运行另外一个操作系统,如在Windows系统上运行Linux系统
虚拟机对于宿主系统来说就是一个普通的文件,完全可以做到迁移到另外一个新的虚拟机上,这就达到了完成一次环境配置后复制到其他计算机上使用的目的
11.2 Docker的使用
在软件真正发布到生产环境之前,可能不知道要重复经历多少遍的交付、部署、测试这样的流程。
Docker的出现可以说将DevOps(开发运维一体化)过程变得更加自动化、便捷,加速了软件和服务的交付。通过自动化持续构建工具,开发人员提交代码后,就会检测代码的变动,然后自动将新的代码构建成Docker镜像并进行部署,部署成功后直接通知测试人员进行测试
11.2.1 安装
由于版本不同于书中的原因,安装可以参考其他博客
11.2.2 镜像
在Docker中有3个重要的概念:仓库、镜像和容器。
Docker将应用程序及其依赖的库等打包到同一个文件里从而形成镜像,镜像可以包含完整的操作系统,也可以仅包含Tomcat或JDK运行环境,
容器是基于镜像运行的虚拟实例
11.2.3 容器
Docker容器都是基于镜像来创建运行的。基于某个镜像,可以创建多个容器,而且容器之间是相互隔离互不影响的,它们各自拥有唯一的ID和名字,这样能够更有效地保护各个容器能够正常运行而不受其他容器的影响。
我们可以将应用程序复制到容器内运行,也可以通过挂载宿主机上的应用程序文件来运行。
11.3 Docker与Spring Cloud微服务
在生产环境中使用Docker时,强烈建议使用Linux操作系统,除了足够安全之外,Docker在Linux操作系统上也是最成熟、稳定的,基本不会出现什么问题
11.3.1 部署Eureka服务
如何将应用发布到Docker中运行。首先,在项目目录内创建shells目录,并在该目录下创建下面两个文件。
release-docker.sh:发布脚本,运行Docker应用,需要上传到服务器。
build.sh:用于应用的编译打包,上传到服务器,最后执行发布脚本。
①elease-docker.sh发布脚本是要上传到服务器上执行的,主要用来运行Docker容器。如果需要备份,则在该脚本中直接编写相关命令即可。运行的容器是基于前面所构建的基础镜像microserv/openjdk:1.0.0,在这个镜像的Dockerfile文件中定义了默认运行文件/jar/app.jar。因此
②在build.sh脚本中先定义了编译发布所需要的相关变量值,如SSH配置,然后通过Maven命令对微服务应用进行编译打包。
由于书中版本较老,配置和其他都有些修改,这里建议参考其他文章,只叙述大致的思路
11.3.2 部署应用微服务
首先把service-discovery项目中的shells目录分别复制到user-service和product-service目录下,然后分别将build.sh和release-docker.sh脚本中的容器名称和端口号修改如下。
user-service:将dockerName修改为userservice,将dockerPort修改为2100。
product-service:将dockerName修改为productservice,将dockerPort修改为2200。
修改完毕后,分别执行微服务的build.sh脚本,如无意外,用户微服务和商品微服务都可以部署成功,启动后则会注册到Eureka服务器中
11.4 微服务与Jenkins
在之前说虽然不熟服务不需要再去配置IP和端口,JDK环境了,但是过多的微服务部署起来,肯定还是有些麻烦,这里可以采用shell脚本一键部署,,最好的是检测到服务源码的变化,自动部署。
Jenkins是一个用Java编写的开源的持续集成工具,它提供了软件开发的持续集成服务,可用于自动执行、构建、测试、交付或部署相关任务。Jenkins可以执行基于Apache Ant和Apache Maven所构建的项目,以及任意的Shell脚本和Windows批处理命令。同时, Jenkins也是一个高度可扩展的产品,提供了强大的插件生态环境,通过安装插件几乎能够满足任何你想要的构建任务。
关于Jenkins的安装和配置不再赘述,书中版本过于老旧,可以参考网上其他资料学习
11.5 微服务编排
在实际的生产环境中,所需要部署的微服务不仅仅是一个,而是多个,而这必然会暴露出服务器硬件设施、服务之间的联调、保证服务访问健壮性等一系列的问题。硬件设施问题一般较容易解决,但如何才能够保证微服务架构的健壮性呢?因此微服务的集群部署始终会成为其中最先考虑的方案之一。
集群部署方案其实就是将同一个微服务部署到不同的机器上,通过负载均衡方式来调度,不同用户请求可能会分发到不同的目标服务中,如果某个服务宕机,那就略过此服务而转发请求到其他正常的服务中,这就是传统集群部署,若在Docker微服务架构上使用集群部署,那么要考虑的不但是负载均衡,还需要包含以下几个问题:
①容器编排;
②服务调度;
③容器集群管理;
④容器健康检查。
单独使用Docker进行微服务的集群部署是无法做到的,必须与其他工具一起配合才能够打造出高可用的集群服务
1)Docker Compose工具
Docker Compose是Docker官方的开源项目,负责实现对Docker容器集群的快速编排,允许用户通过一个单独的docker-compose.yml文件将一组相关联的应用容器定义为一个项目
2)Docker Swarm工具
Docker Swarm和Docker Compose同样都是Docker官方的开源项目,是一套较为简单的工具。Docker Swarm负责提供Docker容器集群服务,是官方提供给云生态支持的核心方案。通过DockerSwarm项目可以将一群Docker宿主机变成一个单一的虚拟主机,从而让使用者感觉是一台容器。
3)Kubernetes(K8s)工具
最后介绍的一个工具就是大名鼎鼎的Kubernetes,简称K8s。Kubernetes是Google十多年大规模容器管理技术Borg的开源版本,用于容器集群管理,可以实现容器集群的自动化部署、扩容、缩容、维护等处理。其所提供的功能基本涵盖了Docker Compose和Docker Swarm的大部分功能,牛就完事了
可以实现
①自动化容器的部署和复制;
②随时扩展或收缩容器规模;
③将容器组织成组,并且提供容器间的负载均衡;
④很容易地升级应用程序容器的新版本;
⑤提供容器弹性,如果容器失效就替换它。
但是Kubernetes入门门槛稍高,首先需要理解它的一些概念,如Pod、Label、Service和Node等,然后需要学习其所提供的一套指令和配置文件