决策树--CART算法
文章目录
-
-
-
- 1.Crat算法(分类树)
-
- 1.1基尼系数
- 1.2连续型特征处理
- 1.3CART算法
- 1.5 举例说明
- 1.5 代码
- 2.回归树
-
-
1.Crat算法(分类树)
1.1基尼系数
CART是基于基尼(Gini)系数最小化准则来进行特征选择,生成二叉树。
基尼系数代表了模型得不纯度,基尼系数越小,则不纯度越低,特征越好。这点和信息增益是相反的。
在分类问题中,假设有K各类别,第k个类别概率为 p k p_{k} pk,则基尼系数的表达式为:
G i n i ( D ) = 1 − ∑ k = 1 K p k 2 Gini(D)=1-\sum_{k=1}^{K}p_{k}^{2} Gini(D)=1−k=1∑Kpk2
若给定样本D,如果根据特征A的某个值a,把D分为D1和D2两个部分,则在特征条件A下,D的基尼系数表达式为:
G i n i A ( D ) = D 1 D G i n i ( D 1 ) + D 2 D G i n i ( D 2 ) Gini_{A}{(D)}=\frac{D_{1}}{D}Gini(D_{1})+\frac{D_{2}}{D}{Gini(D_2)} GiniA(D)=DD1Gini(D1)+DD2Gini(D2)
1.2连续型特征处理
CART处理连续值问题与C4.5一样,都是将连续的特征离散化,唯一区别在于,C4.5采用信息增益率而CART算法采取的是基尼系数。
具体思路如下:有m个样本的连续的特征A有m个,从小到大排序。取相邻两个样本值的平均数,则会得到m-1个二分类点。分别计算这m-1
个点分别作为二分类点时的基尼系数。选择基尼系数最小的点作为该连续型特征的二元分类点。与ID3和C4.5不同的是如果当前节点为连续属性,则该属性在后面还可以参与子节点的产生选择过程。
在ID3和C4.5中,特征A被选取建立决策树结点,如果他有A1,A2和A3三种类别,我们会在决策树上建立一个三叉节点,从而创建一颗多叉树。但CART分类树则不一样,它采用不停的二分,CART分类树会考虑把A分成{A1}和{A2,A3},{A2}和{A1,A3},{A3}和{A1,A2}三种情况,找到基尼系数最小的组合,如{A2}和{A1,A3},然后建立二叉树节点,一个节点是A2对应的样本,另一个节点是{A1,A3}对应的节点。同时,由于这次没有把特征A的取值完全划分开,后面还有机会在子节点中继续在特征A中划分A1和A3.
1.3CART算法


来自李航《统计学原理》一书。
1.5 举例说明
如下图所示的一组数据,其中样本特征有三个分别为是否有房,婚姻状况和年收入,其中有房情况和婚姻状况是离散型的取值,而年收入是连续型取值。是否拖欠贷款属于分类的结果。
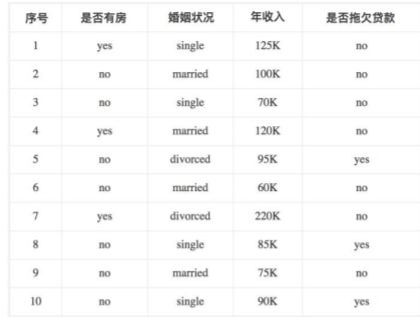
对于是否有房这个特征,他是一个二分类离散数据,其基尼系数为:
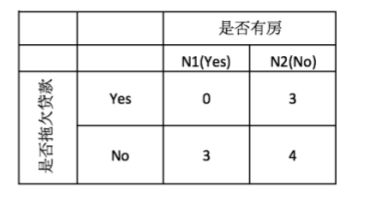
G i n i = 3 10 G i n i ( 有 房 ) + 7 10 G i n i ( 无 房 ) Gini=\frac{3}{10}Gini(有房)+\frac{7}{10}Gini(无房) Gini=103Gini(有房)+107Gini(无房)
= 3 10 ( 1 − ( ( 3 3 ) 2 + ( 0 3 ) 2 ) + 7 10 ( 1 − ( ( 4 7 ) 2 + ( 3 7 ) 2 ) =\frac{3}{10}(1-((\frac{3}{3})^{2}+(\frac{0}{3})^{2})+\frac{7}{10}(1-((\frac{4}{7})^{2}+(\frac{3}{7})^{2}) =103(1−((33)2+(30)2)+107(1−((74)2+(73)2)=0.343
对于婚姻状况这个有三个取值的离散型特征,他有三种分类情况,要计算出每一种对于的基尼指数:
| 单身或已婚 | 离婚 | ||
|---|---|---|---|
| 是否拖欠贷款 | 否 | 6 | 1 |
| 是 | 2 | 1 |
G i n i = 2 10 G i n i ( 离 婚 ) + 8 10 G i n i ( 单 身 或 已 婚 ) Gini=\frac{2}{10}Gini(离婚)+\frac{8}{10}Gini(单身或已婚) Gini=102Gini(离婚)+108Gini(单身或已婚)
= 2 10 ( 1 − ( ( 1 2 ) 2 + ( 1 2 ) 2 ) + 8 10 ( 1 − ( ( 6 8 ) 2 + ( 2 8 ) 2 ) =\frac{2}{10}(1-((\frac{1}{2})^{2}+(\frac{1}{2})^{2})+\frac{8}{10}(1-((\frac{6}{8})^{2}+(\frac{2}{8})^{2}) =102(1−((21)2+(21)2)+108(1−((86)2+(82)2)=0.4
| 单身或离婚 | 已婚 | ||
|---|---|---|---|
| 是否拖欠贷款 | 否 | 3 | 4 |
| 是 | 3 | 0 |
G i n i = 4 10 G i n i ( 已 婚 ) + 6 10 G i n i ( 单 身 或 离 婚 ) Gini=\frac{4}{10}Gini(已婚)+\frac{6}{10}Gini(单身或离婚) Gini=104Gini(已婚)+106Gini(单身或离婚)
= 4 10 ( 1 − ( ( 4 4 ) 2 + ( 0 4 ) 2 ) + 6 10 ( 1 − ( ( 3 6 ) 2 + ( 3 6 ) 2 ) =\frac{4}{10}(1-((\frac{4}{4})^{2}+(\frac{0}{4})^{2})+\frac{6}{10}(1-((\frac{3}{6})^{2}+(\frac{3}{6})^{2}) =104(1−((44)2+(40)2)+106(1−((63)2+(63)2)=0.3
| 已婚或离婚 | 单身 | ||
|---|---|---|---|
| 是否拖欠贷款 | 否 | 5 | 2 |
| 是 | 1 | 2 |
G i n i = 4 10 G i n i ( 单 身 ) + 6 10 G i n i ( 已 婚 或 离 婚 ) Gini=\frac{4}{10}Gini(单身)+\frac{6}{10}Gini(已婚或离婚) Gini=104Gini(单身)+106Gini(已婚或离婚)
= 4 10 ( 1 − ( ( 2 4 ) 2 + ( 2 4 ) 2 ) + 6 10 ( 1 − ( ( 5 6 ) 2 + ( 1 6 ) 2 ) =\frac{4}{10}(1-((\frac{2}{4})^{2}+(\frac{2}{4})^{2})+\frac{6}{10}(1-((\frac{5}{6})^{2}+(\frac{1}{6})^{2}) =104(1−((42)2+(42)2)+106(1−((65)2+(61)2)=0.3667
对于收入这个连续型数据,要先转换为离散型才可以计算,
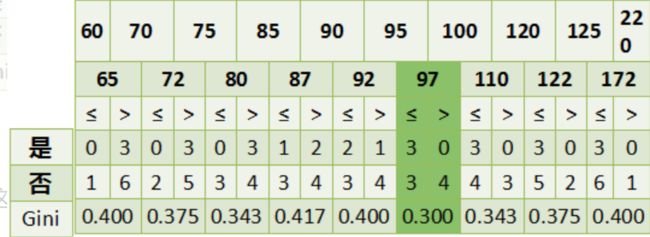
通过计算我们得出了当以97作为分类点时其基尼系数最小,所以选择97作为此时该特征得二元分类点。
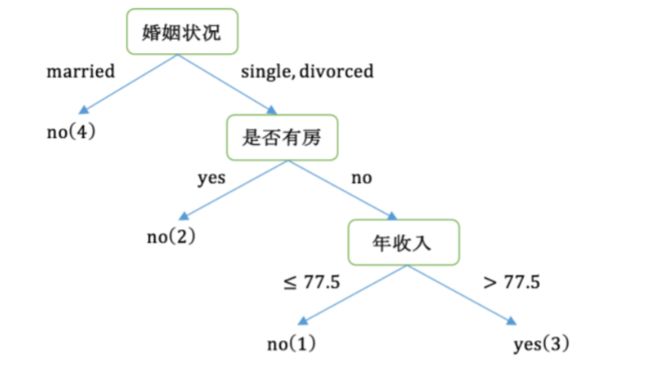
此时我们通过比较,发现 离婚作为婚姻状况得分类点和97作为收入得分类点得基尼系数一样,所以我们可以随意选择他们两个其中任意一个作为最有特征得最优特征值。选择得点不一样,构造出来的决策树也会不一样。在选择一个点后,将数据分为了D1和D2两个部分,对这两个部分用上边方法计算其基尼系数。
选择婚姻状况为最优特征得到的一个决策树:
1.5 代码
from sklearn import tree
import numpy as np
数据集已经做过处理:
RID,house_yes,house_no,single,married,divorced,income,label
1,1,0,1,0,0,125,0
2,0,1,0,1,0,100,0
3,0,1,1,0,0,70,0
4,1,0,0,1,0,120,0
5,0,1,0,0,1,95,1
6,0,1,0,1,0,60,0
7,1,0,0,0,1,220,0
8,0,1,1,0,0,85,1
9,0,1,0,1,0,75,0
10,0,1,1,0,0,90,1
data=np.genfromtxt('/root/jupyter_projects/data/cart.csv',delimiter=',')
x_data=data[1:,1:-1]
y_data=data[1:,-1]
print(x_data.shape)
print(y_data.shape)
(10, 6)
(10,)
model=tree.DecisionTreeClassifier(criterion='gini')#已基尼系数为判定标准
model.fit(x_data,y_data)
DecisionTreeClassifier()
import graphviz
dot_data=tree.export_graphviz(model,
out_file=None,
feature_names=['house_yes','house_no','signal','married','divorce','icome'],
class_names=['yes','no'],
filled=True,
rounded=True,
special_characters=True)
grahp=graphviz.Source(dot_data)
grahp.render('cart.pdf')
'cart.pdf.pdf'
grahp#因为每次选择得最优特征和最优特征值不一样,所以每次产生的决策树也不一样,下面是两个不同得决策树
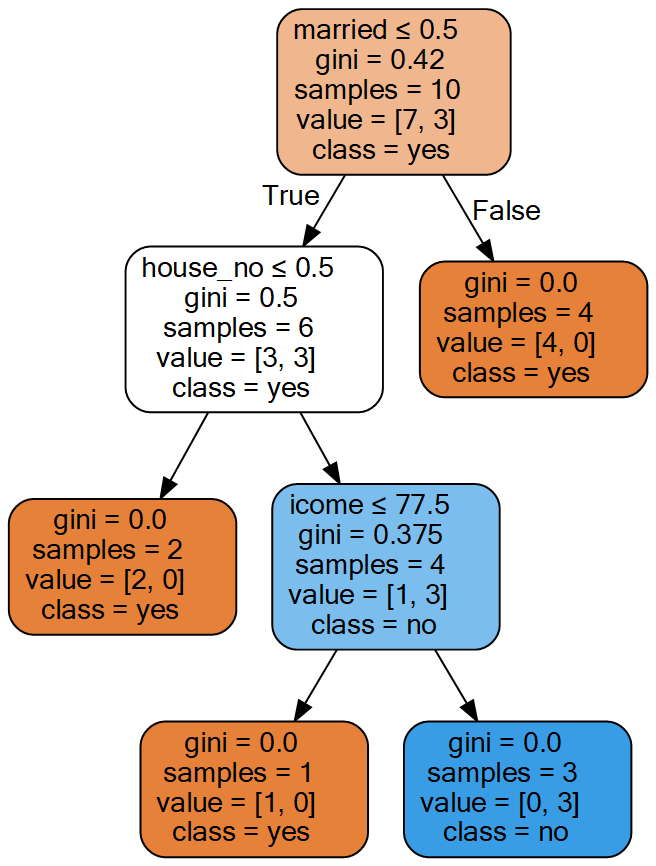
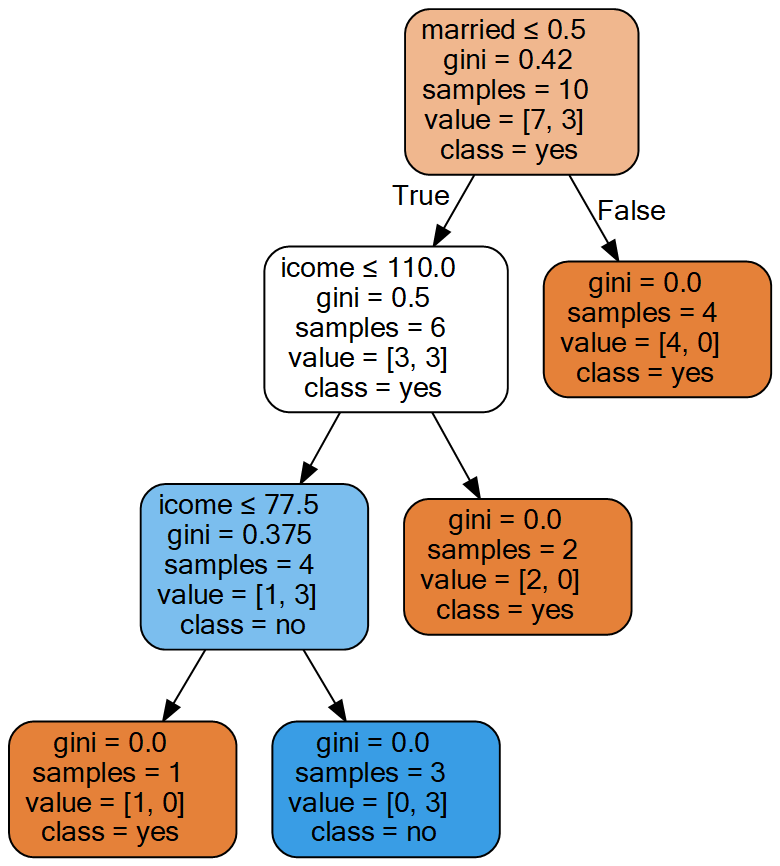
2.回归树
CART回归树和分类树得建立大致相似,两者得区别在于样本输出,如果输出得是离散值,那么这是一颗分类树,如果样本输出是连续值,那么这是一个回归树。
回归树对于连续型数据得处理使用了和方差来度量。CART回归树是对于任意划分特征A,对于任意划分点s两边划分成得数据集D1和D2,求出使D1和D2各自集合得均方差最小,同时D1和D2得均方差之和最小所对应得特征和特征划分点。
对于决策树建立后做预测得方式,分类树采用叶子节点里概率最大得类别作为当前节点得预测类别,而回归树采用得是最终叶子得均值或中位数来预测结果。
参考:决策树算法原理(下)