Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
论文基本信息
- 标题:Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
- 作者:Peize Sun, Rufeng Zhang, Yi Jiang, Tao Kong, Chenfeng Xu, Wei Zhan, Masayoshi Tomizuka, Lei Li, Zehuan Yuan, Changhu Wang, Ping Luo
- 机构:The University of Hong Kong, Tongji University, ByteDance AI Lab, University of California, Berkeley
- 来源:CVPR2021
- 时间:2021/04/26
- 链接:https://arxiv.org/abs/2011.12450
- 代码:
https://github.com/PeizeSun/SparseR-CNN(official code)
https://paperswithcode.com/paper/sparse-r-cnn-end-to-end-object-detection-with
文章概要
背景
Dense-prior detector

Dense:密集,指需要用很多的参数和anchor等
Sparse:稀疏,指不需要用很多的参数和anchor等
two-stage算法可以看成是one-stage算法的扩展:区别仅在于RPN输出的是二分类,而后者是多分类。
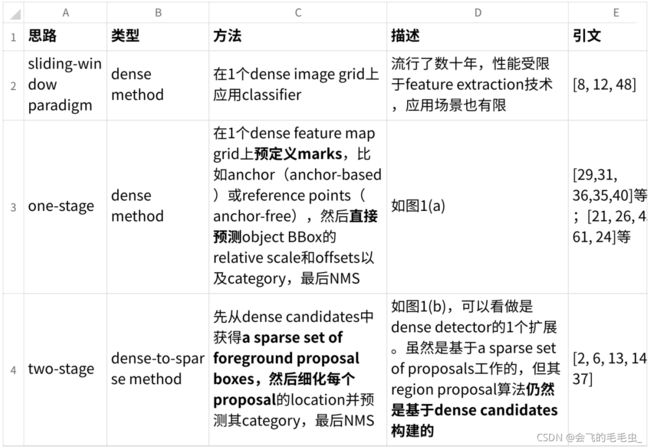
当前的OD⽅法严重依赖于dense object candidates。★dense-prior detector存在⼀些limitation:
- 通常产⽣redundant且near-duplicate的prediction,因此必须通过NMS进⾏后处理
- 训练中的many-to-one label assignment(这是个pre-defined principle,在训练时会根据
anchor与GT BBox的IoU或reference point是否位于GT BBox内,所有的candidate都会被分配给某个GT BBox)问题使得network对heuristic assign rules⽐较sensitive - 性能会受到anchor(size, aspect ratio, number)、reference point(density)、region
proposal算法的影响
DETR:
- 思路:将OD重构为a direct and sparse set prediction problem(⽆需后处理直接输出最终的prediction set),其输⼊仅为100个learned object query
- dense-to-sparse:这些object query与global(dense) image feature进⾏interaction,因此可以将DETR看做另1种dense-to-sparse formulation
- 优点:a simple and fantastic framework
- 缺点(sparse程度还不够):需要每个object query和global image context进⾏interaction,这种dense property不仅减慢了其训练收敛,也阻⽌其成为1个thoroughly sparse pipeline
sparse detector:
-
sparse detector可能免去使⽤dense candidates,但通常准确度⽐dense-prior detector低
-
G-CNN:
意义:sparse detector的precursor
思路:从image上的multi-scale regular grid开始,迭代更新box以对object进⾏cover(检测)和classification
缺点:这种hand-designed regular prior显然是次优的,⽆法达到最佳性能 -
Deformable-DETR:限制每个object query关注reference points周围的⼀⼩组key sampling points,⽽不是特征图中的所有point
-
相⽐于DETR,Sparse RCNN提出sparse property应该包括2个⽅⾯:
sparse boxes:少量的starting boxes就⾜以预测1张图⽚⾥的所有object
sparse features:每个box的feature不需要和整个image中的所有其它feature进⾏
interaction
方法/研究内容
- 不完全的sparse:和DETR⼀样,Sparse RCNN将OD直接定义为1个set prediction problem,但DETR中每个object query与global(dense) image feature进⾏interaction(这并不够sparse),这减慢了其训练收敛,也阻⽌其成为1个thoroughly sparse pipeline
- 完全的sparse:Sparse RCNN中,输⼊为N个proposal box和N个proposal feature,模型中有N个dynamic instance interactive head,三者⼀⼀对应。因此每个box的feature不需要和整个image中的所有其它feature进⾏interaction,实现了真正的sparse
创新点/优点
- 完全的sparse:
sparse boxes:没有在image grid上枚举的object candidate
sparse features:object query不⽤和整张image中的feature进⾏interaction - 本文创新:sparse features,即本⽂中的dynamic head的设计
- paradigm:整个过程都是sparse-in sparse-out paradigm
- 没有使⽤object candidates design、many-to-one label assignment和NMS
- 有多么sparse:对于COCO仅需100个box和400个参数,⽽RPN需要数⼗万个candidate
- proposal boxes和proposal features都是随机初始化,并和⽹络参数⼀起优化
性能/效果
在COCO上,性能(准确度、run-time和training convergence)与当前的well-established detector相当。
- 准确度:standard 3× training schedule,AP达45.0%
- 速度:ResNet-50 FPN达22fps
算法描述
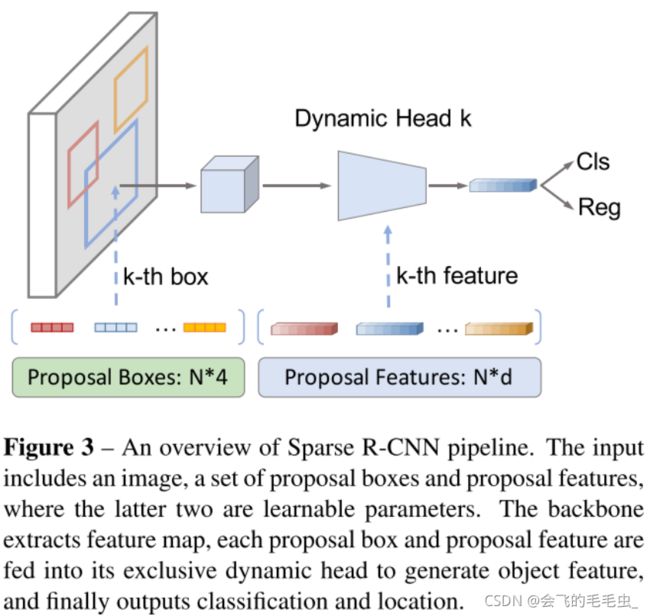
N个proposal box、N个proposal feature和N个dynamic instance interactive head,三者⼀⼀对应:
- 输⼊:
1张图⽚
N个proposal box(learnable)
N个proposal feature(learnable) - 模型结构:
a. backbone
b. RoIAlign:基于backbone输出的image feature和模型输⼊proposal box,提取出box feature
c. N个dynamic instance interactive head:
i. 在proposal feature上应⽤self-attention,以推理object之间的relation
ii. 对proposal feature和box feature进⾏interaction,得到最终的object feature
d. 回归层和分类层:基于object feature预测位置并分类
Backbone
- ResNet+FPN
pyramid levels: P2 到 P5 ,其中 Pl 指该level的resolution⽐input低 2的l次方
通道数:均为256个channel
详⻅FPN原⽂ - more:可以使⽤Deformable-DETR中的stacked encoder layer(源⾃DETR)和deformable
convolution network来提⾼performance
Learnable proposal box
- Learnable proposal box:
定义:将⼀组learnable proposal box(N×4)作为region proposal
representation:⽤4个参数表⽰1个BBox,取值范围0到1,表⽰normalized的中⼼坐标、⾼
度和宽度
learnable:随机初始化(实验证明影响很⼩),在训练过程中可以和⽹络中其它parameter⼀
起优化 - 关于region proposal
RPN:RPN⽣成的proposal与当前input密切相关,提供了object的粗略位置
rethinking:因为later stage中会对box的location进⾏refine,那first-stage中的locating就是
luxurious(奢侈的),⽽1个reasonable statistic已经可以是合格的候选⼈
Sparse RCNN:proposal box是training set中潜在的object的位置的statistics,因此可以⽆视
input,作为最有可能包含object的区域的initial guess
Learnable proposal feature
- proposal box的缺点:只提供了object的coarse localization,并且丢失了许多informative detail
(例如object pose和shape) - proposal feature:N×d,N个d维(⽐如256)的latent vector,作⽤是对instance的丰富特征进
⾏编码,⽤法是生成interaction操作的参数,可以看作是1个与location⽆关的feature filter
Dynamic instance interactive head

- 预处理
proposal feature:在interaction之前,将self-attention应⽤于proposal feature集合,以推理
object之间的relation
proposal box:基于backbone输出的image feature和proposal box,使⽤RoIAlign提取出box
feature - interaction
结构:2个连续1×1卷积(带有ReLU),这2个卷积的参数由proposal feature得到
输⼊:1个box feature fi(S × S, C) 及其对应的1个proposal feature pi©
输出:object feature ©
作⽤:通过proposal feature(作为1个feature filter)将⽆效的bin过滤,并输出最终的object
feature©
注:interaction的实现细节并不重要,只要⽀持并⾏计算以提⾼效率
相关算法:Conditional convolutions for instance segmentation和Dynamic filter networks
也使⽤了相似的dynamic机制
分类和回归
regression:1个3层的perception,得到object box
classification:1个linear projection层
iteration structure
- iteration structure:本次迭代新⽣成的object box和object feature作为下次迭代时的proposal
box和proposal feature(TODO:类似于cascade) - 性能:由于sparse property和light dynamic head,这只引⼊了marginal computation
overhead
Set prediction loss
使⽤set prediction loss,在size固定的predction set和GT set之间产⽣optimal bipartite matching
(最佳⼆分匹配)
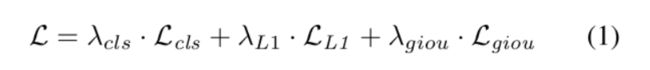
- matching cost
λ :各loss对应的coefficient
L :predicted classification和GT category label之间的Focal Loss cls
LL ,L :predicted box和GT BBox之间的L1 loss和generalized IoU loss 1 giou - training loss
和matching cost相同,但仅在matched pairs上执⾏;
final loss为所有pair的loss之和(需要通过training batch中object的数量进⾏normalization)
性能实验
实现细节
- 数据集
训练:train2007
验证:val2017 - Training details
backbone:默认ResNet50
优化器:AdamW,weight decay 0.0001
mini-batch:batch size 16,8GPU
epoch:36个epoch
学习率:初始为2.5×10e-5,epoch27和33分别除以10
模型参数初始化:backbone⽤ImageNet预训练权重初始化,其它层⽤Xavier初始化
数据增强:random horizontal、随机resize图像(最短边⾄少为480、最多800,最⻓边最多
1333)
λcls = 2, λL1 = 5, λgiou = 2
proposal box、proposal feature、iteration的数量:100,100,6
为了稳定训练,在iterative architecture的每个stage,阻塞proposal box的梯度(除了初始的
proposal box) - Inference details
直接预测100个BBox及它们的score(包含object的概率,应该是class吧)
evaluation时不⽤post-processing,直接使⽤100个BBox
AP on COCO 2017 val set
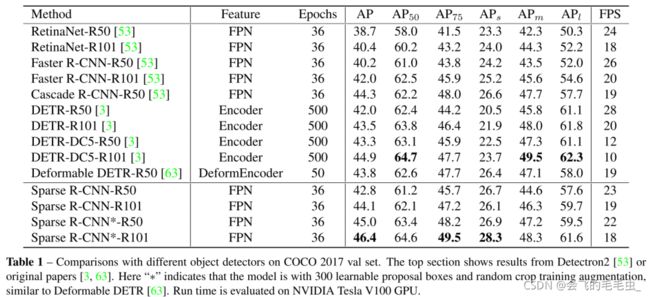
- Sparse RCNN模型:
不带:100 learnable proposal boxes,random crop,和RetinaNet、Faster RCNN等主流
detector进⾏对⽐
带:300 learnable proposal boxes,random crop,和DETR系列进⾏对⽐
从100(23 FPS)到300(22 FPS),FPS下降很⼩,这是因为dynamic instance interactive
head的轻量化设计 - 主流detector:
AP:Sparse RCNN⼤幅超过RetinaNet、Faster RCNN等主流detector;Sparse RCNN
(ResNet50,AP 42.8%)超过Faster RCNN(ResNet101,AP 42.0%)
速度:相当 - DETR系列
-特征提取:DETR和Deformable DETR通常使⽤更强的特征提取⽅法,Sparse RCNN仅使⽤简
单的FPN就获得了更⾼的AP,并且Sparse RCNN在small object上的效果⽐DETR好很多(26.7
AP vs. 22.5 AP)
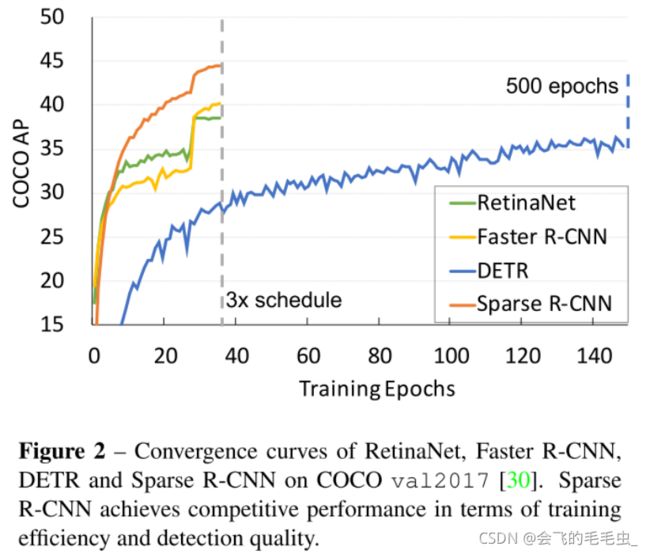
-Sparse RCNN的训练收敛⽐DETR快10倍,如图2所⽰。为解决DETR训练收敛慢的问题,才提
出了Deformable DETR
-Sparse RCNN与Deformable DETR相⽐,AP更⾼(45.0 AP vs. 43.8 AP),速度更快(22 FPS
vs. 19 FPS),训练时间更短(36 epochs vs. 50 epochs)

- ResNeXt-101作为backbone时,AP达46.9%;DCN作为backbone时,AP达48.9%
- 使⽤额外的test-time augmentation时,AP达51.5%,和SOTA相当