Transformer(三)--论文实现:transformer pytorch 代码实现
转载请注明出处:https://blog.csdn.net/nocml/article/details/124489562
传送门:
Transformer(一)–论文翻译:Attention Is All You Need 中文版
Transformer(二)–论文理解:transformer 结构详解
Transformer(三)–论文实现:transformer pytorch 代码实现
文章目录
- 1. 文章说明
- 2. 代码实现
-
- 2.2 Transformer 实现
-
- 2.2.1 transformer 基础代码实现
-
- 2.2.1.1 模块1:Positional Embedding
- 2.2.1.2 模块2:Multi-Head Attention
- 2.2.1.3 模块4:Layer Normalization
- 2.2.1.4 模块5:Feed Forward Network
- 2.2.2 transformer 代码封装
-
- 2.2.2.1 Block 1
- 2.2.2.2 Block 2
- 2.2.2.3 Encoder Layer
- 2.2.2.4 Decoder Layer
- 2.3 机器翻译框架实现
-
- 2.4.1 Encoder Stack
- 2.4.2 Decoder Stack
- 2.4.3 Linear + SoftMax
- 2.4.4 机器翻译模型
- 3. 跑通一个测试用例
-
- 3.1 数据准备
-
- 3.1.1 生成训练数据
- 3.2 辅助类代码及工具准备
-
- 3.1.1 生成掩码的代码
- 3.1.2 Tokenizer 工具类
- 3.1.3 词表构建方法
- 3.1.3 数据集迭代器
- 3.2 训练模型
-
- 3.2.1 训练主函数
- 3.2.2 训练模型
- 3.2.3 解码方法
- 3.2.4 加载已训练模型进行测试
1. 文章说明
此篇文章承接上篇文章,按照上篇文章的结构来实现transformer, 并在机器翻译任务上应用。
文章整体结构分为两部分,第一部分(2.代码实现)实现transfomer及 机器翻译框架,实现的主要架构及思路参考同系列中的上一篇文章,在本文中不在做过多的讲解。第二部分(3. 跑通一个测试用例)使用实现的模型跑通一个例子,让大家更好的理解。
2. 代码实现
原始论文中,transformer是在机器翻译任务中提出的。整个机器翻译模型可以分为两大块,一部分是核心特征提取器,即transformer模块,另一部分是整体encoder-decoder框架的实现。我们按照论文中的顺序,先实现transformer核心模块,再实现encoder-decoder框架。
2.2 Transformer 实现
2.2.1 transformer 基础代码实现
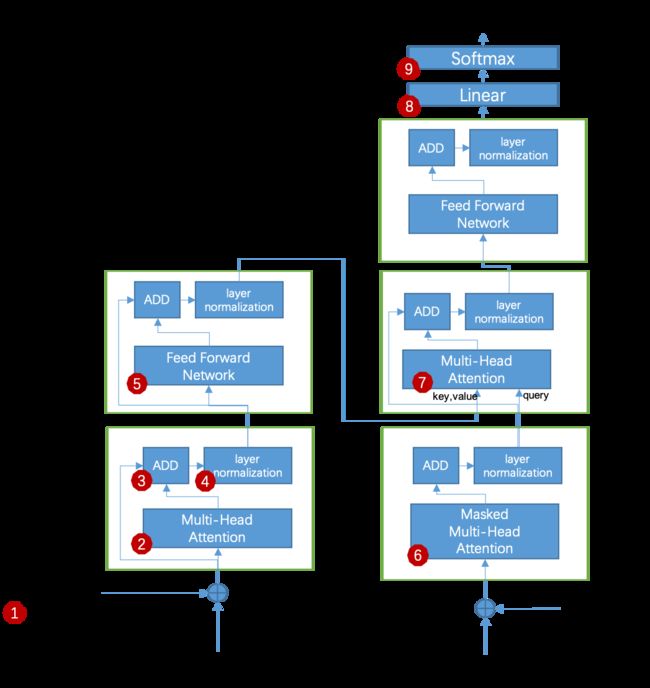
transformer的结构如 图2.1 所示,共有9个主要模块,我们先分别实现这9个模块。在实现过程中,模块6和模块2的区别是一个做mask操作,一个不做mask操作,因些,我们可以使用一个类来实现,当传入掩码时,我们做mask操作,不传入掩码时我们就不做mask操作。这样的话,图2.1中❷、❻、❼ 只实现一个就可以。❸ 是基础的向量相加操作,这里不再实现。❽、❾我们放在机器翻译框架代码中实现(理由:❽、❾ 可以理解为特定任务的Head)。
综上所述,我们只需要实现❶、❷、❹、❺ 4个模块。
导入依赖–下文使用的所有依赖均在此处导入。
import copy
import math
import torch
import logging
import numpy as np
import sentencepiece as spm
import torch.optim as optim
from tqdm import tqdm
from dataclasses import dataclass
from typing import List, Union, Optional, Dict
from torch import nn
from torch.autograd import Variable
from torch.nn import functional as F
from torch.utils.data import Dataset, DataLoader
from transformers.utils import PaddingStrategy
2.2.1.1 模块1:Positional Embedding
class PositionalEncoding(nn.Module):
"""
module 1: 位置编码
"""
def __init__(self, d_model:int, dropout:float, max_len:int=5000):
"""
:param d_model: 模型词微量维度
:param dropout: drop out 比例
:param max_len: 最大支持长度
"""
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x:torch.Tensor):
"""
:param x: 待加入位置信息的输入向量(展开d_model所属维度)
:return:
"""
x = x + Variable(self.pe[:, :x.size(1)],
requires_grad=False)
return self.dropout(x)
2.2.1.2 模块2:Multi-Head Attention
class MultiHeadAttention(nn.Module):
"""
module 2: 多头注意力
"""
def __init__(self, h: int, d_model: int , dropout: float=0.1):
"""
:param h: 多头个数
:param d_model: 词向量维度
:param dropout: drop out 比例
"""
super(MultiHeadAttention, self).__init__()
assert d_model % h == 0
self.d_k = d_model // h
self.h = h
self.linears = nn.ModuleList([copy.deepcopy(nn.Linear(d_model, d_model)) for _ in range(4)])
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def attention(self, query: torch.Tensor, key:torch.Tensor, value:torch.Tensor, mask: torch.Tensor=None, dropout: torch.nn.Module=None):
"""
:param query: 查询query [batch size, head num, sentence length, d_model/h]
:param key: 待查询key [batch size, head num, sentence length, d_model/h]
:param value: 待查询value [batch size, head num, sentence length, d_model/h]
:param mask: 计算相似度得分时的掩码(设置哪些输入不计算到score中)[batch size, 1, 1, sentence length]
:param dropout: drop out 比例
:return:
"""
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
try:
scores = scores.masked_fill(mask == 0, -1e9)
except Exception as e:
logger.error(e.__str__())
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
def forward(self, query: torch.Tensor, key: torch.Tensor, value: torch.Tensor, mask: torch.Tensor=None):
"""
:param query: 查询query [batch size, sentence length, d_model]
:param key: 待查询key [batch size, sentence length, d_model]
:param value: 待查询value [batch size, sentence length, d_model]
:param mask: 计算相似度得分时的掩码(设置哪些输入不计算到score中)[batch size, 1, sentence length]
:return:
"""
if mask is not None:
# 1) Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
if mask is not None:
logger.debug('mask shape:%s' % str(mask.shape))
query, key, value = [l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2) for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = self.attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
2.2.1.3 模块4:Layer Normalization
class LayerNormalization(nn.Module):
"""
module 4:基于层的标准化
"""
def __init__(self, features, eps=1e-6):
super(LayerNormalization, self).__init__()
# a 系数的默认值为1
self.a = nn.Parameter(torch.ones(features))
# b 系统的初始值为0
self.b = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a * (x - mean) / (std + self.eps) + self.b
2.2.1.4 模块5:Feed Forward Network
class FFN(nn.Module):
"""
module 5: 前馈神经网络
"""
def __init__(self, d_model, d_ff, dropout=0.1):
super(FFN, self).__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.linear2(self.dropout(F.relu(self.linear1(x))))
2.2.2 transformer 代码封装
在上一节中我们使用一个通过方法实现了❷、❻、❼模块,那么,如图2.2,三个红色方框内的代码结构与功能完全相同,我们可以把MHA-ADD-LN三个算法模块封装成一个代码块,我们且命名为Block1。同理,图2.2中黄色方框中的代码也封装成一个代码块,命名为Block2。这样的话,图2.2转化为图2.3。图2.3中的两个蓝色方框中的部分在原始论文中各使用了6次,因此我们把蓝色方框中的block再封装一层。如图2.4,把图2.3中左则蓝框中的Block1、Block2封装成Encoder Layer,把图2.3中右则蓝框中的Block1、Block、Block2封装成Decoder Layer。
综上所述,在这部分,我们需要做4部分封装,如下:
- Block1 的封装
- Block2 的封装
- EncoderLayer 的封装
- DecoderLayer 的封装

2.2.2.1 Block 1
class BlockOne(nn.Module):
def __init__(self, head_num, d_model,dropout):
super(BlockOne, self).__init__()
self.mha = MultiHeadAttention(head_num, d_model)
self.ln = LayerNormalization(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, query, key, value, mask=None):
"""
:param query:
:param key:
:param value:
:param mask:
:return:
"""
x_mha = self.mha(query, key, value, mask)
query = query + self.dropout(x_mha)
query = self.ln(query)
return query
2.2.2.2 Block 2
class BlockTwo(nn.Module):
def __init__(self, d_model, d_ff, dropout):
super(BlockTwo, self).__init__()
self.ffn = FFN(d_model, d_ff, dropout)
self.ln = LayerNormalization(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
"""
:param x:
:return:
"""
x_ffn = self.ffn(x)
x = x + self.dropout(x_ffn)
x = self.ln(x)
return x
2.2.2.3 Encoder Layer
class EncoderLayer(nn.Module):
def __init__(self, head_num, d_model, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.bk1 = BlockOne(head_num=head_num, d_model=d_model,dropout=dropout)
self.bk2 = BlockTwo(d_model=d_model, d_ff=d_ff, dropout=dropout)
self.d_model = d_model
def forward(self, x, mask=None):
x = self.bk1(x, x, x, mask)
x = self.bk2(x)
return x
2.2.2.4 Decoder Layer
class DecoderLayer(nn.Module):
def __init__(self, head_num, d_model, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.bk1 = BlockOne(head_num=head_num, d_model=d_model,dropout=dropout)
self.bk2 = BlockOne(head_num=head_num, d_model=d_model,dropout=dropout)
self.bk3 = BlockTwo(d_model=d_model, d_ff=d_ff, dropout=dropout)
self.d_model = d_model
def forward(self, query, memory, src_mask=None, tgt_mask=None):
out = self.bk1.forward(query=query, key=query, value=query, mask=tgt_mask)
out = self.bk2.forward(query=out, key=memory, value=memory, mask=src_mask)
out = self.bk3.forward(out)
return out
2.3 机器翻译框架实现
模型总体构架采用encoder-decoder结构,这里的encoder中是下图中的encoder-stack,decoder指的是decoder-stack(为了和transformer中的encoder,decoder区分,下文提及的encoder-stack及decoder-stack均为整体架构中的encoder和decoder,而encoder和decoder均指transformer中的结构)

2.4.1 Encoder Stack
class EncoderStack(nn.Module):
"""
编码器栈
"""
def __init__(self, layer, layer_num):
super(EncoderStack, self).__init__()
self.layers = nn.ModuleList([copy.deepcopy(layer) for _ in range(layer_num)])
self.norm = LayerNormalization(layer.d_model)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
2.4.2 Decoder Stack
class DecoderStack(nn.Module):
"""
解码器栈
"""
def __init__(self, layer, layer_num):
super(DecoderStack, self).__init__()
self.layers = nn.ModuleList([copy.deepcopy(layer) for _ in range(layer_num)])
self.norm = LayerNormalization(layer.d_model)
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections."
for ndx, layer in enumerate(self.layers):
logger.debug('layer : %d start '% ndx)
x = layer(x, memory, src_mask, tgt_mask)
logger.debug('layer : %d end ' % ndx)
return self.norm(x)
2.4.3 Linear + SoftMax
class Generator(nn.Module):
"""
decoder_stack stack 后的 linear + softmax
"""
def __init__(self, d_model:int, vocab:int):
"""
:param d_model: 模型词向量维度
:param vocab: 目标语言词表大小
"""
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1)
2.4.4 机器翻译模型
class Translate(nn.Module):
"""
机器翻译模型整体框架
"""
def __init__(self, src_vocab_size:int, tgt_vocab_size:int, head_num:int=8, layer_num:int=6, d_model:int=512, d_ff:int=2048, dropout:float=0.1):
"""
:param src_vocab_size: 源语言词表大小
:param tgt_vocab_size: 目标语言词表大小
:param head_num: 多头个数
:param layer_num: encoder_stack stack中encoder的个数(decoder_stack stack 中 decoder的个数)
:param d_model: 模型词向量维度
:param d_ff: FFN 模块的中间层大小
:param dropout: drop out 比例
"""
super(Translate, self).__init__()
encoder_layer = EncoderLayer(head_num=head_num, d_model=d_model, d_ff=d_ff, dropout=dropout)
decoder_layer = DecoderLayer(head_num=head_num, d_model=d_model, d_ff=d_ff, dropout=dropout)
# 上图的encoder stack
self.encoder_stack = EncoderStack(layer=encoder_layer, layer_num=layer_num)
# 上图的decoder stack
self.decoder_stack = DecoderStack(layer=decoder_layer, layer_num=layer_num)
self.layer_num = layer_num
self.pe_encode = PositionalEncoding(d_model=d_model, dropout=dropout)
self.pe_decode = PositionalEncoding(d_model=d_model, dropout=dropout)
self.src_embedd = nn.Embedding(src_vocab_size, d_model)
self.tgt_embedd = nn.Embedding(tgt_vocab_size, d_model)
self.generator = Generator(d_model=d_model, vocab=tgt_vocab_size)
def forward(self, src:torch.Tensor, tgt:torch.Tensor, src_mask:torch.Tensor, tgt_mask:torch.Tensor):
"""
:param src: 源语言输入 [batch_size , source sentence length]
:param tgt: 目标语言输入 [batch_size , target sentence length]
:param src_mask: 源语言掩码 [batch_size, 1, source sentence length]
:param tgt_mask: 目标语言掩码 [batch_size, target sentence length, target sentence length]
:return:
"""
src_embedding = self.pe_encode(self.src_embedd(src))
tgt_embedding = self.pe_encode(self.tgt_embedd(tgt))
encoder_ouput = self.encoder_stack(x=src_embedding, mask=src_mask)
decoder_output = self.decoder_stack(memory=encoder_ouput, x=tgt_embedding, src_mask=src_mask, tgt_mask=tgt_mask)
softmax_out = self.generator(decoder_output)
return decoder_output, softmax_out
3. 跑通一个测试用例
3.1 数据准备
3.1.1 生成训练数据
!mkdir temp_checkpoints
!mkdir temp_data
mkdir: temp_checkpoints: File exists
mkdir: temp_data: File exists
source_content = """
返回大于或等于0且小于1的平均分布随机数(依重新计算而变)
返回一个大于0且小于1的随机数。
返回日期时间格式的当前日期和时间。
返回日期时间格式的当前日期和时间。请在“帮助”中查看有关输入序列数的信息
返回日期格式的的当前日期。请在“帮助”中查看有关输入序列数的信息
"""
target_content = """
returns a random number greater than or equal to 0 and less than 1 , evenly distributed ( changes on recalculation )
returns an evenly distributed random number greater than or equal to 0 and less than 1 .
returns the current date and time formatted as a date and time .
returns the current date and time formatted as a date and time. see help for information on entering serial numbers
returns the current date formatted as a date. see help for information on entering serial numbers
"""
fw_source = open('./temp_data/source.txt','w+')
fw_target = open('./temp_data/target.txt','w+')
for line in [l for l in source_content.split('\n') if len(l) > 0]:
fw_source.write(line.strip() + '\n')
for line in [l for l in target_content.split('\n') if len(l) > 0]:
fw_target.write(line.strip() + '\n')
fw_source.flush()
fw_target.flush()
fw_source.close()
fw_target.close()
3.2 辅助类代码及工具准备
3.1.1 生成掩码的代码
def get_decoder_mask(data, pad=0):
tgt_mask = (data != pad).unsqueeze(-2)
tgt_mask = tgt_mask.long()
tgt_mask = tgt_mask & Variable(subsequent_mask(data.size(-1)).type_as(tgt_mask.data))
return tgt_mask
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return torch.from_numpy(subsequent_mask) == 0
def get_encoder_mask(data):
lt = data.view(-1).detach().numpy().tolist()
new_lt = [1 if n > 0 else 0 for n in lt]
mask_tensor = torch.from_numpy(np.array(new_lt))
mask_tensor = mask_tensor.view(data.size())
return mask_tensor.unsqueeze(-2)
3.1.2 Tokenizer 工具类
class TokenizerSpm(object):
def __init__(self, model_path):
self.sp = spm.SentencePieceProcessor(model_file=str(model_path))
def encode(self, texts: List[str], add_bos=False, add_eos=False, return_tensor=False) -> List[int]:
val = self.sp.Encode(input=texts,
out_type=int,
add_bos=add_bos,
add_eos=add_eos,
)
if return_tensor:
torch.LongTensor(val)
return val
def decode(self,text):
return self.sp.Decode(text)
def get_vocab_size(self):
return self.sp.vocab_size()
3.1.3 词表构建方法
def build_vocab(source_file, target_file, vocab_size,temp_dir="./temp_data/"):
merged_file = temp_dir + 'data.tmp'
fzh = open(source_file, 'r')
fen = open(target_file, 'r')
fmerge = open(merged_file,'w')
for line in fzh:
fmerge.write(line)
for line in fen:
fmerge.write(line)
fzh.close()
fen.close()
fmerge.flush()
fmerge.close()
spm.SentencePieceTrainer.Train(input=merged_file,
model_prefix= temp_dir + 'm',
vocab_size=vocab_size,
model_type = 'bpe',
pad_id=0,
bos_id=1,
eos_id=2,
unk_id=3
)
3.1.3 数据集迭代器
# 加载使用sentencepiece训练好的模型
def padding(data_list:List[List[int]],max_length = 128,pad_id = 0,return_tensors='pt')->List[List[int]]:
max_len = -1
for token_id_list in data_list:
if max_len < len(token_id_list):
max_len = len(token_id_list)
max_len = max_length if max_len > max_length else max_len
for ndx, token_id_list in enumerate(data_list):
if len(token_id_list) < max_len:
data_list[ndx].extend([pad_id] * (max_len - len(token_id_list)))
elif len(token_id_list) > max_len:
data_list[ndx] = data_list[ndx][0:max_len]
if return_tensors == 'pt':
return torch.Tensor(data_list).long()
return data_list
@dataclass
class DataCollator:
"""padding补全等"""
tokenizer: TokenizerSpm
padding: Union[bool, str, PaddingStrategy] = True
max_length: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
def __call__(self, features: List[Dict[str, List[int]]]) -> Dict[str, torch.Tensor]:
batch_size = len(features)
if batch_size == 0:
return
features_in_bucket = {}
for item in features:
for key, value in item.items():
temp = features_in_bucket.get(key, [])
temp.append(value)
features_in_bucket[key] = temp
batch = {}
for key, value_list in features_in_bucket.items():
batch[key] = padding(data_list=value_list, pad_id=self.padding, max_length=self.max_length, return_tensors="pt")
return batch
class TranslateDataset(Dataset):
def __init__(self, source: List[str], target:List[str], max_length,tokenizer):
self.items = []
for i in tqdm(range(len(source))):
text1 = source[i].replace(' ','').strip()
text2 = target[i].strip()
input_ids = tokenizer.encode(text1)
labels = tokenizer.encode(text2, add_bos=True, add_eos=True)
item = {}
item['input_ids'] = input_ids
item['labels'] = labels
# item = {key: torch.LongTensor(val) for key, val in item.items()}
self.items.append(item)
def __len__(self):
return len(self.items)
def __getitem__(self, idx):
return self.items[idx]
def build_dataset(source: str, target: str,tokenizer) -> Dataset:
source_lines = open(source, 'r').readlines()
target_lines = open(target, 'r').readlines()
assert len(source_lines) == len(target_lines)
dataset = TranslateDataset(source_lines, target_lines,128,tokenizer)
return dataset
def build_dataloader(source: str, target: str, batch_size, tokenizer):
dataset = build_dataset(source, target,tokenizer=tokenizer)
return DataLoader(dataset, batch_size=batch_size, shuffle=True, collate_fn=DataCollator(tokenizer=tokenizer,padding=0,max_length=128), drop_last=True)
3.2 训练模型
3.2.1 训练主函数
def run(model_dir, train_path,
batch_size, epochs, learning_rate,
save_interval, checkpoint_model, vocab_size, tokenizer):
train_data_loader = build_dataloader(train_path + 'source.txt', train_path + 'target.txt', batch_size=batch_size,tokenizer=tokenizer)
model: Translate = Translate(src_vocab_size=vocab_size, tgt_vocab_size=vocab_size)
if checkpoint_model is not None and len(checkpoint_model) > 5:
model: Translate = Translate(src_vocab_size=vocab_size, tgt_vocab_size=vocab_size)
ck = torch.load(checkpoint_model)
model.load_state_dict(ck['model'])
loss_fn = nn.CrossEntropyLoss()
opt = optim.Adam(model.parameters(), lr=learning_rate)
if torch.cuda.device_count() >= 1:
logger.info("Let's use %d GPUs!" % (torch.cuda.device_count()))
gpu_num = torch.cuda.device_count()
model = DataParallel(model, device_ids=[int(i) for i in range(gpu_num)])
model.cuda()
for epoch in range(0,epochs + 1):
for ndx, batch in enumerate(train_data_loader):
model.train()
opt.zero_grad()
# data loader 中的每一条数据是一个batch,因此
try:
src = batch["input_ids"]
src_mask = get_encoder_mask(src)
# label 右移一位
tgt = batch["labels"][:, :-1]
# 去头:删除第一个字符
tgt_y = batch["labels"][:, 1:]
tgt_mask = get_decoder_mask(tgt)
decoder_output, softmax_output = model.forward(src=src,
tgt=tgt,
src_mask=src_mask,
tgt_mask=tgt_mask)
flattened_predictions = softmax_output.view(-1, vocab_size)
flattened_target = tgt_y.contiguous().view(-1)
ntokens = (tgt_y != 0).data.sum()
if torch.cuda.is_available():
loss = loss_fn(flattened_predictions, flattened_target.cuda()) / ntokens
else:
loss = loss_fn(flattened_predictions, flattened_target) / ntokens
loss.mean().backward()
opt.step()
loss = loss.cpu().mean().item()
total_interatoin_step = ndx + epoch * (len(train_data_loader.dataset))
logger.info('Epoch [%d/%d]: [%d/%d] train loss = %f'%(epoch,epochs,ndx,len(train_data_loader.dataset),loss))
if total_interatoin_step % save_interval == 0:
torch.save(model.state_dict(), "%s/Transformer_checkpoint_%s.pt"%(model_dir,total_interatoin_step))
except Exception as e:
logger.error(e)
3.2.2 训练模型
logging.basicConfig(level=logging.INFO,
format= '[%(asctime)s]-[%(threadName)s]-[%(filename)s:%(funcName)s:%(lineno)s]-%(levelname)s: %(message)s'
)
logger = logging.getLogger(__name__)
logger.info("build vocabulary...")
build_vocab('./temp_data/source.txt','./temp_data/target.txt',vocab_size=450)
logger.info("load vocabulary...")
tokenizer = TokenizerSpm('./temp_data/m.model')
logger.info("start training...")
run(model_dir="./temp_checkpoints/",
train_path="./temp_data/",
batch_size=2,
epochs=20,
learning_rate=0.0001,
save_interval=20,
checkpoint_model="",
vocab_size=tokenizer.get_vocab_size(),
tokenizer=tokenizer)
[2022-05-18 15:01:02,665]-[MainThread]-[2435230881.py::6]-INFO: build vocabulary...
sentencepiece_trainer.cc(77) LOG(INFO) Starts training with :
trainer_spec {
input: ./temp_data/data.tmp
input_format:
model_prefix: ./temp_data/m
model_type: BPE
vocab_size: 450
self_test_sample_size: 0
character_coverage: 0.9995
input_sentence_size: 0
shuffle_input_sentence: 1
seed_sentencepiece_size: 1000000
shrinking_factor: 0.75
max_sentence_length: 4192
num_threads: 16
num_sub_iterations: 2
max_sentencepiece_length: 16
split_by_unicode_script: 1
split_by_number: 1
split_by_whitespace: 1
split_digits: 0
treat_whitespace_as_suffix: 0
required_chars:
byte_fallback: 0
vocabulary_output_piece_score: 1
train_extremely_large_corpus: 0
hard_vocab_limit: 1
use_all_vocab: 0
unk_id: 3
bos_id: 1
eos_id: 2
pad_id: 0
unk_piece:
bos_piece:
eos_piece:
pad_piece:
unk_surface: ⁇
}
normalizer_spec {
name: nmt_nfkc
add_dummy_prefix: 1
remove_extra_whitespaces: 1
escape_whitespaces: 1
normaliza[2022-05-18 15:01:02,686]-[MainThread]-[2435230881.py::9]-INFO: load vocabulary...
tion_rule_tsv:
}
denormalizer_spec {}
trainer_interface.cc(319) LOG(INFO) SentenceIterator is not specified. Using MultiFileSentenceIterator.
trainer_interface.cc(174) LOG(INFO) Loading corpus: ./temp_data/data.tmp
trainer_interface.cc(375) LOG(INFO) Loaded all 10 sentences
trainer_interface.cc(390) LOG(INFO) Adding meta_piece:
trainer_interface.cc(390) LOG(INFO) Adding meta_piece:
trainer_interface.cc(390) LOG(INFO) Adding meta_piece:
trainer_interface.cc(390) LOG(INFO) Adding meta_piece:
trainer_interface.cc(395) LOG(INFO) Normalizing sentences...
trainer_interface.cc(456) LOG(INFO) all chars count=620
trainer_interface.cc(477) LOG(INFO) Alphabet size=80
trainer_interface.cc(478) LOG(INFO) Final character coverage=1
trainer_interface.cc(510) LOG(INFO) Done! preprocessed 10 sentences.
trainer_interface.cc(516) LOG(INFO) Tokenizing input sentences with whitespace: 10
trainer_interface.cc(526) LOG(INFO) Done! 43
bpe_model_trainer.cc(167) LOG(INFO) Updating active symbols. max_freq=15 min_freq=1
bpe_model_trainer.cc(258) LOG(INFO) Added: freq=6 size=20 all=273 active=193 piece=▁date
bpe_model_trainer.cc(258) LOG(INFO) Added: freq=4 size=40 all=290 active=210 piece=mber
bpe_model_trainer.cc(258) LOG(INFO) Added: freq=2 size=60 all=297 active=217 piece=bu
bpe_model_trainer.cc(258) LOG(INFO) Added: freq=2 size=80 all=301 active=221 piece=关输
bpe_model_trainer.cc(258) LOG(INFO) Added: freq=2 size=100 all=306 active=226 piece=随机数
bpe_model_trainer.cc(167) LOG(INFO) Updating active symbols. max_freq=2 min_freq=0
bpe_model_trainer.cc(258) LOG(INFO) Added: freq=2 size=120 all=308 active=228 piece=ributed
bpe_model_trainer.cc(258) LOG(INFO) Added: freq=1 size=140 all=297 active=217 piece=分布
bpe_model_trainer.cc(258) LOG(INFO) Added: freq=1 size=160 all=304 active=224 piece=分布随机数
bpe_model_trainer.cc(258) LOG(INFO) Added: freq=0 size=180 all=289 active=209 piece=ed
bpe_model_trainer.cc(258) LOG(INFO) Added: freq=0 size=200 all=269 [2022-05-18 15:01:02,688]-[MainThread]-[2435230881.py:| :12]-INFO: start training...
active=189 piece=ng
bpe_model_trainer.cc(167) LOG(INFO) Updating active symbols. max_freq=0 min_freq=0
bpe_model_trainer.cc(258) LOG(INFO) Added: freq=0 size=220 all=249 active=169 piece=ve
bpe_model_trainer.cc(258) LOG(INFO) Added: freq=0 size=240 all=229 active=149 piece=期格
bpe_model_trainer.cc(258) LOG(INFO) Added: freq=0 size=260 all=209 active=129 piece=enl
bpe_model_trainer.cc(258) LOG(INFO) Added: freq=0 size=280 all=189 active=109 piece=tri
bpe_model_trainer.cc(258) LOG(INFO) Added: freq=0 size=300 all=169 active=89 piece=大于或
bpe_model_trainer.cc(167) LOG(INFO) Updating active symbols. max_freq=0 min_freq=0
bpe_model_trainer.cc(258) LOG(INFO) Added: freq=0 size=320 all=149 active=69 piece=numb
bpe_model_trainer.cc(258) LOG(INFO) Added: freq=0 size=340 all=129 active=49 piece=式的当前
bpe_model_trainer.cc(258) LOG(INFO) Added: freq=0 size=360 all=109 active=29 piece=当前日期和
trainer_interface.cc(604) LOG(INFO) Saving model: ./temp_data/m.model
trainer_interface.cc(615) LOG(INFO) Saving vocabs: ./temp_data/m.vocab
100%|████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 6337.72it/s]
[2022-05-18 15:01:03,372]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [0/20]: [0/5] train loss = 0.154542
[2022-05-18 15:01:03,988]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [0/20]: [1/5] train loss = 0.160107
[2022-05-18 15:01:04,379]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [1/20]: [0/5] train loss = 0.115343
[2022-05-18 15:01:04,774]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [1/20]: [1/5] train loss = 0.120547
[2022-05-18 15:01:05,168]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [2/20]: [0/5] train loss = 0.103386
[2022-05-18 15:01:05,559]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [2/20]: [1/5] train loss = 0.122731
[2022-05-18 15:01:05,955]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [3/20]: [0/5] train loss = 0.112539
[2022-05-18 15:01:06,345]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [3/20]: [1/5] train loss = 0.097869
[2022-05-18 15:01:06,758]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [4/20]: [0/5] train loss = 0.089460
[2022-05-18 15:01:07,534]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [4/20]: [1/5] train loss = 0.107935
[2022-05-18 15:01:07,920]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [5/20]: [0/5] train loss = 0.101126
[2022-05-18 15:01:08,307]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [5/20]: [1/5] train loss = 0.075773
[2022-05-18 15:01:08,695]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [6/20]: [0/5] train loss = 0.088569
[2022-05-18 15:01:09,087]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [6/20]: [1/5] train loss = 0.081271
[2022-05-18 15:01:09,475]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [7/20]: [0/5] train loss = 0.076573
[2022-05-18 15:01:09,866]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [7/20]: [1/5] train loss = 0.070809
[2022-05-18 15:01:10,255]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [8/20]: [0/5] train loss = 0.053256
[2022-05-18 15:01:10,977]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [8/20]: [1/5] train loss = 0.059203
[2022-05-18 15:01:11,363]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [9/20]: [0/5] train loss = 0.050286
[2022-05-18 15:01:11,748]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [9/20]: [1/5] train loss = 0.058902
[2022-05-18 15:01:12,139]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [10/20]: [0/5] train loss = 0.052746
[2022-05-18 15:01:12,525]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [10/20]: [1/5] train loss = 0.041707
[2022-05-18 15:01:12,911]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [11/20]: [0/5] train loss = 0.037112
[2022-05-18 15:01:13,297]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [11/20]: [1/5] train loss = 0.031008
[2022-05-18 15:01:13,684]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [12/20]: [0/5] train loss = 0.042449
[2022-05-18 15:01:14,689]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [12/20]: [1/5] train loss = 0.025332
[2022-05-18 15:01:15,077]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [13/20]: [0/5] train loss = 0.038972
[2022-05-18 15:01:15,464]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [13/20]: [1/5] train loss = 0.023630
[2022-05-18 15:01:15,852]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [14/20]: [0/5] train loss = 0.017667
[2022-05-18 15:01:16,239]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [14/20]: [1/5] train loss = 0.019002
[2022-05-18 15:01:16,624]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [15/20]: [0/5] train loss = 0.034253
[2022-05-18 15:01:17,012]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [15/20]: [1/5] train loss = 0.009599
[2022-05-18 15:01:17,398]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [16/20]: [0/5] train loss = 0.023280
[2022-05-18 15:01:18,199]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [16/20]: [1/5] train loss = 0.009765
[2022-05-18 15:01:18,583]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [17/20]: [0/5] train loss = 0.018155
[2022-05-18 15:01:18,966]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [17/20]: [1/5] train loss = 0.013349
[2022-05-18 15:01:19,350]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [18/20]: [0/5] train loss = 0.011095
[2022-05-18 15:01:19,739]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [18/20]: [1/5] train loss = 0.007021
[2022-05-18 15:01:20,124]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [19/20]: [0/5] train loss = 0.005878
[2022-05-18 15:01:20,509]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [19/20]: [1/5] train loss = 0.008361
[2022-05-18 15:01:20,890]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [20/20]: [0/5] train loss = 0.012428
[2022-05-18 15:01:21,690]-[MainThread]-[2670694996.py:run:52]-INFO: Epoch [20/20]: [1/5] train loss = 0.006123
| | | 3.2.3 解码方法
def greedy_decode(model, src, max_len = 10, start_symbol =1):
src_embed = model.pe_encode(model.src_embedd(src))
src_mask = get_encoder_mask(src)
memory = model.encoder_stack(src_embed, src_mask)
ys = torch.ones(1, 1).fill_(start_symbol).long()
for i in range(max_len - 1):
ys_embed = model.pe_encode(model.tgt_embedd(ys.long()))
tgt_mask = get_decoder_mask(ys)
out = model.decoder_stack(memory=memory, src_mask=src_mask, x=Variable(ys_embed), tgt_mask=tgt_mask)
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim=1)
next_word = next_word.data[0]
ys = torch.cat([ys, torch.ones(1, 1).fill_(int(next_word))], dim=1)
return ys
3.2.4 加载已训练模型进行测试
vocab_size = tokenizer.get_vocab_size()
ck = torch.load('./temp_checkpoints/Transformer_checkpoint_100.pt')
model = Translate(vocab_size, vocab_size)
model.load_state_dict(ck)
input_str = "返回日期时间格式的当前日期和时间。"
input = tokenizer.encode([str(input_str)])
input = Variable(torch.LongTensor(input))
ys = greedy_decode(model=model, src=input,max_len=25)
target_decode = tokenizer.decode((ys.long()).tolist()[0])
print('decode result : ', target_decode)
decode result : returns the current date and time formatted as a date and time .
注:这个blog本是用jupyter notebook写的,在notebook上看整体结构更清晰。但奈何CSDN不支持notebook与pdf格式文件的导入,所以我是把格式转换成md后再上传上来。有需要pdf文件的同学,留个邮箱,有时间我会发给你。