python爬虫从基础到实战一站式服务
一,第一站(基础)
1,http&https
http协议:就是服务器和客户端进行数据交互的一种形式。
常用的请求头信息:
- -User-Agent:请求载体的身份标识
- Connection:请求完毕后,是断开连接还是保持连接
常用的响应头信息:
- -Content-Type:服务器返回客户端的数据类型
https:安全的超文本传输协议
2,requests第一血
requests模块就是python中的一款基于网络请求的模块,功能很强大,简单快捷, 效率高。
作用:模拟浏览器发请求
如何使用:
(1)指定url
(2)发起请求
(3)获取响应数据
(4)持久化存储
环境安装
pip install requests
# 需求,爬取csdn首页的全部html代码
import requests
if __name__=="__main__":
# 指定url
url = "https://www.csdn.net/"
# 发起请求
response = requests.get(url=url)
# 获取响应数据(字符串格式)
result_text=response.text
# 持久化存储
print(result_text)
3,爬取百度指定词条对应的搜索结果页面(简易网页采集器)
下面有一个知识点是UA伪装,就是让爬虫对应的请求载体身份标识伪装成某一款浏览器,可以F12得到请求后的请求头信息,把User-Agent的内容复制过来即可。
# 需求,爬取csdn首页的全部html代码
import requests
#UA伪装:让爬虫对应的请求载体身份标识伪装成某一款浏览器
if __name__=="__main__":
# 指定url
url = "https://www.baidu.com/s?ie=UTF-8"
# UA伪装
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
}
# 动态输入搜索内容
kw = input("请输入搜索关键字:")
params={
"wd":kw
}
# 发起请求
response = requests.get(url=url,params=params,headers=headers)
# 获取响应数据(字符串格式)
result_text=response.text
# 持久化存储
print(result_text)
4,破解百度翻译

在左边输入文字,网站会发送ajax请求,然后返回翻译后的结果。
那么这里用requests来直接发送翻译请求,首先F12获取ajax的请求信息。
# 需求,爬取csdn首页的全部html代码
import requests
#UA伪装:让爬虫对应的请求载体身份标识伪装成某一款浏览器
if __name__=="__main__":
# 指定url
url = "https://fanyi.baidu.com/sug"
# UA伪装
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
}
# 动态输入搜索内容
kw = input("请输入要翻译的内容:")
data={
"kw":kw
}
# 发起请求
response = requests.post(url=url,params=data,headers=headers)
# 获取响应数据(如果确认返回格式是json类型的,那么可以调用json方法拿到json对象)
result=response.json()
# result结果
#{'errno': 0, 'data': [{'k': '测试', 'v': 'test; testing; measurement ; checkout'}, {'k': '测试仪', 'v': 'tester'}, {'k': '测试区', 'v': 'test section'}, {'k': '测试员', 'v': 'test controler'}, {'k': '测试头', 'v': 'measuring head'}]}
# 持久化存储
print(result["data"][0]["v"])

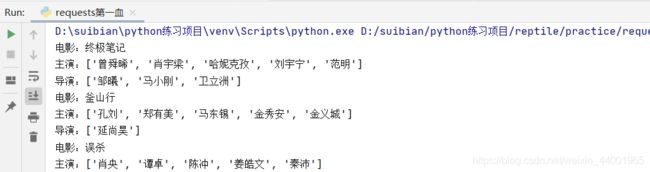
5,爬取豆瓣电影分类排行榜
F12发现,其实也是ajax请求,复制请求地址,模拟参数,相同的操作再来一波
# 需求,爬取csdn首页的全部html代码
import requests
#UA伪装:让爬虫对应的请求载体身份标识伪装成某一款浏览器
if __name__=="__main__":
# 指定url
url = "https://movie.douban.com/j/new_search_subjects"
# UA伪装
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
}
data={
"sort":"U",
"range":"0,10",
"start":"20"
}
# 发起请求
response = requests.get(url=url,params=data,headers=headers)
# 获取响应数据(如果确认返回格式是json类型的,那么可以调用json方法拿到json对象)
result=response.json()
# 持久化存储
datalist = result["data"]
for obj in datalist:
print("电影:" + obj.get("title"))
print("主演:" + str(obj.get("casts")))
print("导演:" + str(obj.get("directors")))
二,数据解析
聚焦爬虫:爬取页面中指定的页面内容
数据解析分类:
- 正则
- bs4
- xpath(重点)
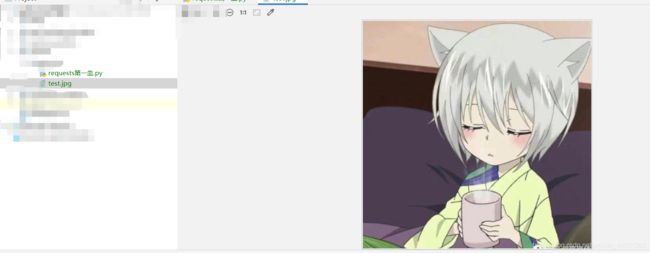
这里先爬取指定一个在线地址的图片,得到二进制形式的响应数据,并存储
# 需求,爬取csdn首页的全部html代码
import requests
#UA伪装:让爬虫对应的请求载体身份标识伪装成某一款浏览器
if __name__=="__main__":
# 指定url
url = "https://img-blog.csdnimg.cn/20201216201054832.jpg"
# # UA伪装
# headers={
# "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
# }
#
# data={
# "sort":"U",
# "range":"0,10",
# "start":"20"
# }
# 发起请求
response = requests.get(url=url)
# 获取响应数据
# content 返回的是二进制形式的图片数据
# text 字符串格式
# json() json对象格式
result=response.content
# 二进制图片持久化存储 wb:写入二进制数据
with open('./test.jpg','wb') as fp:
fp.write(result)
1,正则解析-爬取糗事百科中糗图板块下所有的图片
.*? 表示匹配任意字符到下一个符合条件的字符
import requests
import re
if __name__=="__main__":
# 指定url
url = "https://www.qiushibaike.com"
# # UA伪装
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
}
# 发起请求
response = requests.get(url=url,headers=headers)
result=response.text
# 使用正则找到图片在线地址 .*?
ex = '.*?) image_url_list = re.findall(ex,result,re.S)
# 遍历
for src in image_url_list:
print(src)
# 拿到在线地址之后再发get请求拿到二进制数据,并持久化即可
image_url_list = re.findall(ex,result,re.S)
# 遍历
for src in image_url_list:
print(src)
# 拿到在线地址之后再发get请求拿到二进制数据,并持久化即可
2,bs4解析-解析糗事百科的所有图片的alt属性值
环境安装
pip install bs4
pip install lxml
如何实例化BeautifulSoup对象?
对象的实例化
1,将本地的html文档中的数据加载到该对象中
fp=open('./test.html','r',encoding='utf-8')
soup = BeautifulSoup(fp,'lxml')
2,将互联网上获取到的页面源码加载到该对象中
page_text = response.text
soup = BeautifulSoup(page_text,'lxml')
提供的用于数据解析的方法和属性
-
soup.tagName:返回的是html文档中第一次出现tagName对应的标签
-
soup.find():
- soup.find(“tagName”):等同于soup.div
- 属性定位:soup.find(“div”,class_ / id / attr = “song”)
-
select()
- select(‘某种选择器’),返回的是一个列表
- 层级选择器
- soup.select(".tang > ul > li > a"):>表示一个层级
- soup.select(".tang > ul > li a"):空格表示多个层级
-
获取标签之间的文本数据
- soup.a.text / get_text():可以获取某一个标签中所有的文本内容
- soup.a.string:只可以获取该标签下面直系的文本内容
-
获取标签中的属性值
- soup.a[‘text’]
import requests
from bs4 import BeautifulSoup
if __name__=="__main__":
# 指定url
url = "https://www.qiushibaike.com"
# # UA伪装
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
}
# 发起请求
response = requests.get(url=url,headers=headers)
result=response.text
soup = BeautifulSoup(result,'lxml')
div_list = soup.select('.recommend-article > ul > li > a > img')
for div in div_list:
print(div['alt'])
3,xpath解析-爬取博客网站的所有博客信息
原理:实例化一个etree对象,需要将被解析的页面源码数据加载到该对象中。
调用etree的xpath方法结合着xpath表达式实现标签的定位和内容的捕获。
环境安装
pip install lxml
如何实例化一个etree对象?
from lxml import etree
使用方式
将本地的html文档中的源码数据加载到etree对象中
etree.parse(filePath)
可以从互联网上获取的源码数据加载到该对象中
etree.HTML(‘page_text’)
xpath表达式
-
/ 斜杠表示的是从根节点开始定位,表示的是一个层级
-
//双斜杠表示是多个层级,可以表示从任意位置开始定位
-
定位属性://div[@class=‘song’] tag[@attrName=‘attrValue’]
-
索引定位://div[@class=‘song’]/p[3] 索引是从1开始的
-
取文本:
- /text() :获取的是标签中直系的文本内容
- //text():标签中非直系的文本内容(所有的文本内容)
-
取属性:/@attrName ==>img/@src
下面列出了最有用的路径表达式:
nodename
选取此节点的所有子节点。
/
从根节点选取。
//
从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
.
选取当前节点。
…
选取当前节点的父节点。
@
选取属性。
开始爬取博客网站
# 需求,爬取csdn首页的全部html代码
import requests
from lxml import etree
def test():
# 指定url
url = "https://blogs.qianlongyun.cn/page/"
# UA伪装
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
}
# 发起请求
for i in range(12):
print("========== 当前爬取页面:第"+str(i)+"页 ==============")
newUrl = url+str(i+1)+"/"
response = requests.get(url=newUrl, headers=headers)
# 得到etree对象
etreeObj = etree.HTML(response.text)
# 得到所有文章的div
articles = etreeObj.xpath("//div[@class='content']/article")
for article in articles:
print("========================")
# 拿到文章标题
content = article.xpath(".//h2/a/text()")[0]
print("博客标题:"+content)
imgUrl = article.xpath(".//img/@src")[0]
print("博客配图在线链接:" + imgUrl)
author = article.xpath("./p[1]/span[1]/text()")[0]
print("作者:" + author)
if __name__=="__main__":
test()
4,验证码识别
识别验证码图片中的数据,用于模拟登录操作。
- 人眼识别(不推荐)
- 第三方接口识别(推荐,但是由于收费,此处跳过)
如何读取验证码?
先使用xpath解析到验证码图片的在线地址,并转为二进制持久化存储(下载到本地),然后使用第三方接口进行识别即可
5,模拟登录以及模拟登录cookie存储
点击登录按钮会发出一个post请求,post请求中会携带登录之前录入的登录信息(账号,密码,验证码)
涉及到一个问题?登录成功之后会返回cookie并存储到浏览器,爬虫如何设置cookie?
session会话对象
作用:1,可以进行请求的发送 2,如果请求过程中产生了cookie,则该cookie会被自动存储/携带在该session对象中
- 创建一个session对象,requests.Session()
- 使用session对象进行模拟登录post请求的发送(cookie就会被存储到session中)
- session对象对登录成功之后的所有页面进行get请求(携带了cookie)
6,模拟登录古诗文网并爬取个人主页详细信息
import requests
from lxml import etree
def test():
# 指定url古诗文网登录页
url = "https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx"
# UA伪装
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
}
login_html=requests.get(url=url,headers=headers).text
etreeObj = etree.HTML(login_html)
# 找到验证码的标签,并复制xpath值
yzm_src = "https://so.gushiwen.cn"+etreeObj.xpath('//*[@id="imgCode"]/@src')[0]
# 请求验证码在线地址,得到二进制数据,并持久化到本地
yzm_data = requests.get(url=yzm_src,headers=headers).content
with open("yzm.jpg","wb") as tp:
tp.write(yzm_data)
yzm_value = input("验证码图片已下载,请输入验证码:")
data={
"__VIEWSTATE": "q5220JT0+dsek1Iq8Fjx0xFeucO6gCylR4IaiN5dDnXvRTA4UDtUG4oJlRrRML4jIcJ7LBp+bQgN/glEST9wTy81hdDS3DOcSZ5tYzDTwPn2Fa6Jqit2/GdazXs=",
"__VIEWSTATEGENERATOR": "C93BE1AE",
"from": "http://so.gushiwen.cn/user/collect.aspx",
"email": "18838030468",
"pwd": "aini12345",
"code": yzm_value,
"denglu": "登录"
}
# 创建session
session = requests.session()
# 登录url
loginUrl = "https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx"
print("正在模拟登录中。。。")
response = session.post(url=loginUrl,data=data, headers=headers)
if response.status_code==200:
print("登录成功!开始爬取信息!")
# 持久化登录成功后的html到本地
with open('test.html','w',encoding='utf-8') as fp:
fp.write(response.text)
# 详情页的url
xqUrl = "https://so.gushiwen.cn/user/collectbei.aspx?sort=t"
# 然后就可以继续爬取详情页了(使用session发请求)
else:
print("模拟登录失败,请重试!")
if __name__=="__main__":
test()
三,代理
破解封ip这种反爬机制!
代理的作用:
- 突破自身ip访问的控制
- 隐藏自身真实ip
1,代理在爬虫中的应用
在百度中搜索ip,可以得到当前请求百度时本机的ip地址

这里使用代理来请求百度
这里提供一个全国代理网站:http://www.goubanjia.com/,这里提供很多免费的代理!
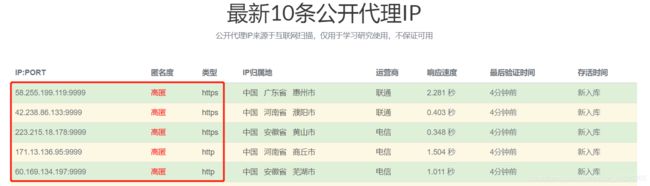
代理ip的类型:
- http:应用到http协议的url中
- https:应用到https协议的url中
代理ip的匿名度:
- 透明:服务器知道此次请求使用了代理,也知道请求对应真实的ip(代理ip)
- 匿名:知道使用了代理,不知道真实ip
- 高匿:不知道使用了代理,更不知道真实ip
url = "https://www.baidu.com/s?wd=ip"
# UA伪装
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
}
response = requests.get(url=url,headers=headers,proxies={"https":"222.110.147.50:3128"})
with open("test.html","w",encoding="utf-8") as fp:
fp.write(response.text)
四,高性能异步爬虫
1,单线程串行爬虫示例
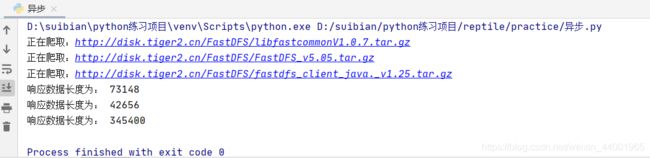
示例:爬取三个压缩包
import requests
urls = [
"http://disk.tiger2.cn/FastDFS/libfastcommonV1.0.7.tar.gz",
"http://disk.tiger2.cn/FastDFS/FastDFS_v5.05.tar.gz",
"http://disk.tiger2.cn/FastDFS/fastdfs_client_java._v1.25.tar.gz"
]
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
}
def getContent(url):
print("正在爬取:"+url)
response = requests.get(url=url,headers=headers)
if response.status_code == 200:
return response.content
def parseContent(content):
print("响应数据长度为:",len(content))
for url in urls:
content = getContent(url)
parseContent(content)
执行结果:

很明显,三个是同步的执行的,requests的get方法是一个阻塞的方法,效率会比较低。
2,异步爬虫之多进程and多线程
多线程,多进程(不建议)
线程池,进程池(建议)线程数量有限
import requests
# 导入线程池模块所需要的类
from multiprocessing.dummy import Pool
urls = [
"http://disk.tiger2.cn/FastDFS/libfastcommonV1.0.7.tar.gz",
"http://disk.tiger2.cn/FastDFS/FastDFS_v5.05.tar.gz",
"http://disk.tiger2.cn/FastDFS/fastdfs_client_java._v1.25.tar.gz"
]
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
}
def getContent(url):
print("正在爬取:"+url)
response = requests.get(url=url,headers=headers)
if response.status_code == 200:
print("响应数据长度为:",len(response.content))
# 实例化一个线程池对象
pool = Pool(4)
# 将列表中每一个列表元素传递给getContent方法进行处理(异步)
pool.map(getContent,urls)
原则:线程池处理的是阻塞且耗时的操作!并不是什么都可以执行!
3,异步爬虫之线程池案例应用
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
}
url = "https://www.pearvideo.com/category_5"
response = requests.get(url=url,headers=headers)
if response.status_code==200:
etreeObj = etree.HTML(response.text)
# 得到视频列表的li
li_list = etreeObj.xpath('//*[@id="listvideoListUl"]/li')
# 存放视频真实地址
urls=[ ]
for li in li_list:
detail_url = "https://www.pearvideo.com/"+li.xpath('.//a/@href')[0]
# 这只是一个视频详情页的链接,并不是视频链接,要靠F12大胆的去发现,这里发现请求详情页后,又发了一个请求
# https://www.pearvideo.com/videoStatus.jsp?contId=1718464&mrd=0.7595792109906241
# 其中的contId就是detail_url参数的最后面的数字
print(detail_url)
name = li.xpath('.//div[@class="vervideo-title"]/text()')[0]+".mp4"
print(name)
# 截取字符串
contId = detail_url[32:]
# 请求视频详情页
response = requests.get("https://www.pearvideo.com/videoStatus.jsp?contId="+contId+"&mrd=0.7595792109906241")
if response.status_code==200:
# 得到视频真实地址
jsons=response.json()
react_url = jsons["videoInfo"]["videos"]["srcUrl"]
print("视频真实地址:",react_url)
# 下面的操作就不写了,就是把url放到urls里,然后和上面的示例操作一样
4,多任务异步协程实现
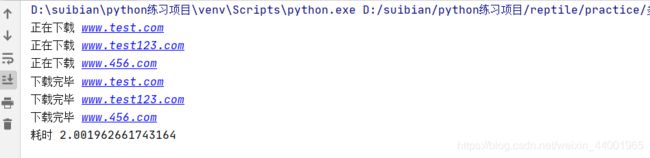
下面请求三个url,使用多任务异步协程,每个url请求模拟等待2秒,那么三个如果是同步的话应该耗时六秒,如果异步那么应该是两秒。
import asyncio
import time
async def request(url):
print("正在下载",url)
# 在异步协程中如果出现了同步模块相关的代码,那么就无法实现异步
# time.sleep(2)
# 当在asyncio中遇到阻塞操作必须进行手动挂起
await asyncio.sleep(2)
print("下载完毕",url)
start = time.time()
urls=[
"www.test.com",
"www.test123.com",
"www.456.com"
]
# 任务列表:存放多个任务对象
stasks = []
for url in urls:
c = request(url)
task = asyncio.ensure_future(c)
stasks.append(task)
loop = asyncio.get_event_loop()
# 需要将任务列表封装到wait中
loop.run_until_complete(asyncio.wait(stasks))
print("耗时",time.time()-start)
5,aiohttp多任务异步协程实现异步爬虫
首先安装aiohttp
pip install aiohttp
然后使用如下
import asyncio
import time
import aiohttp
async def request(url):
async with aiohttp.ClientSession() as session:
# get() post()都可以
async with await session.get(url) as response:
# text()返回字符串形式的响应数据
# read()返回二进制形式的响应数据
# json()返回的就是json对象
# 注意:获取响应数据操作之前一定要使用await进行手动挂起
page_text = await response.text()
start = time.time()
urls=[
"www.test.com",
"www.test123.com",
"www.456.com"
]
# 任务列表:存放多个任务对象
stasks = []
for url in urls:
c = request(url)
task = asyncio.ensure_future(c)
stasks.append(task)
loop = asyncio.get_event_loop()
# 需要将任务列表封装到wait中
loop.run_until_complete(asyncio.wait(stasks))
print("耗时",time.time()-start)
结果同上,耗时两秒。
五,selenium简介
1,selenium模块的基本使用
问题:什么是selenium?selinium和爬虫之间具有怎样的关联?
便捷的获取网站中动态加载的数据
便捷实现模拟登录
基于浏览器自动化的一个模块(可以直接操作浏览器,类似无人驾驶去自动驾驶的效果)
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器
2,selenium初试-爬取药监局的企业信息
药监局网站的企业信息是ajax动态加载的,可以由selenium来模拟浏览器来完成信息的获取!
1,环境安装
pip install selenium
-
下载安装selenium:pip install selenium
-
下载浏览器驱动程序:
- http://chromedriver.storage.googleapis.com/index.html
-
查看驱动和浏览器版本的映射关系:
- http://blog.csdn.net/huilan_same/article/details/51896672
-
实例化一个浏览器对象
-
编写基于浏览器自动化的操作代码
进行操作之前要把浏览器对应的驱动程序解压并放置到一个位置
from selenium import webdriver
from lxml import etree
# 实例化一个浏览器对象(传入浏览器的驱动程序chromedriver.exe)
bro = webdriver.Chrome(executable_path='./chromedriver.exe')
# 让浏览器发起一个指定url对应请求
bro.get('http://scxk.nmpa.gov.cn:81/xk/')
# page_source获取浏览器当前页面的页面源码数据
page_text = bro.page_source
# 解析企业名称
tree = etree.HTML(page_text)
li_list = tree.xpath('//*[@id="gzlist"]/li')
for li in li_list:
company_name = li.xpath('.//a/text()')[0]
print('公司名称:',company_name)
bro.quit()
3,selenium其他自动化操作
from selenium import webdriver
from lxml import etree
import time
# 实例化一个浏览器对象(传入浏览器的驱动程序chromedriver.exe)
bro = webdriver.Chrome(executable_path='./chromedriver.exe')
# 让浏览器发起一个指定url对应请求
bro.get('https://www.taobao.com/')
# 标签定位
search_input = bro.find_element_by_id('q')
# 标签交互(向输入框输入内容)
search_input.send_keys('IPhone')
# 执行一组js程序(向下滚动一个屏幕的距离)
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
# 点击按钮
btn = bro.find_element_by_css_selector('.btn-search')
btn.click()
# 回退
bro.back()
# 前进
bro.forward()
time.sleep(5)
bro.quit()
4,iframe处理+动作链
像上面直接通过id或者class获取标签的话,如果这些标签在iframe里就会报错!
这里使用selenium来实现拖动滑块
from selenium import webdriver
#导入动作链对应的类
from selenium.webdriver import ActionChains
# 实例化一个浏览器对象(传入浏览器的驱动程序chromedriver.exe)
bro = webdriver.Chrome(executable_path='./chromedriver.exe')
# 让浏览器发起一个指定url对应请求
bro.get('https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
# 如果定位的标签是存在与iframe中则必须通过如下操作再进行标签定位
bro.switch_to.frame('iframeResult')# 切换浏览器标签定位的作用域
# 获取拖动小滑块的div元素
div = bro.find_element_by_id('draggable')
# 动作链
action = ActionChains(bro)
# 点击长按指定的标签(滑块)
action.click_and_hold(div)
for i in range(5):
# perform立即执行动作链操作
# move_by_offset(x,y):x:水平方向 y:竖直方向
action.move_by_offset(17,0).perform()
# 释放动作链
action.release()
bro.quit()
5,selenium实现模拟登陆
通过上面的基础操作,那么用selenium来实现模拟登录是在是太简单方便了!
当然一切操作都离不开F12啦!
这里写一个例子,来模拟登录qq空间吧!
from selenium import webdriver
import time
# 实例化一个浏览器对象(传入浏览器的驱动程序chromedriver.exe)
bro = webdriver.Chrome(executable_path='./chromedriver.exe')
# 让浏览器发起一个指定url对应请求
bro.get('https://qzone.qq.com/')
bro.switch_to.frame('login_frame')# 值是iframe的id值
# 获取登录链接标签
loginButton = bro.find_element_by_id('switcher_plogin')
# 点击
loginButton.click()
# 账号输入框
account_input = bro.find_element_by_id('u')
# 密码输入框
pwd_input = bro.find_element_by_id('p')
# 输入账号和密码
account_input.send_keys('675361896')
pwd_input.send_keys('*******')
# 点击登录
login = bro.find_element_by_id('login_button')
login.click()
time.sleep(5)
bro.quit()
6,无头浏览器+规避检测
上面的效果是自动弹出来浏览器并自动进行操作的(可视化)
无头浏览器:只默默的执行,并不会弹出浏览器
推荐大家可以使用谷歌的无头浏览器,是一款无界面的谷歌浏览器
如何实现?
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
# 创建一个参数对象,用来控制chrome以无界面模式打开
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 驱动路径
path = r'C:\Users\ZBLi\Desktop\1801\day05\ziliao\chromedriver.exe'
# 创建浏览器对象
browser = webdriver.Chrome(executable_path=path, chrome_options=chrome_options)
# 上网
url = 'http://www.baidu.com/'
browser.get(url)
time.sleep(3)
browser.save_screenshot('baidu.png')
browser.quit()
selenium规避被检测识别
现在不少大网站有对selenium采取了监测机制。比如正常情况下我们用浏览器访问淘宝等网站的 window.navigator.webdriver的值为
undefined。而使用selenium访问则该值为true。那么如何解决这个问题呢?
只需要设置Chromedriver的启动参数即可解决问题。在启动Chromedriver之前,为Chrome开启实验性功能参数excludeSwitches,它的值为[‘enable-automation’],完整代码如下:
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = Chrome(options=option)
完整示例如下
from selenium import webdriver
import time
####################################################################
# 无可视化界面
from selenium.webdriver.chrome.options import Options
# 实现规避检测
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
# 创建一个参数对象,用来控制chrome以无界面模式打开
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 实例化一个浏览器对象(传入浏览器的驱动程序chromedriver.exe)
bro = webdriver.Chrome(executable_path='./chromedriver.exe',chrome_options=chrome_options,options=option)
####################################################################
# 让浏览器发起一个指定url对应请求
bro.get('https://qzone.qq.com/')
bro.switch_to.frame('login_frame')# 值是iframe的id值
# 获取登录链接标签
loginButton = bro.find_element_by_id('switcher_plogin')
# 点击
loginButton.click()
# 账号输入框
account_input = bro.find_element_by_id('u')
# 密码输入框
pwd_input = bro.find_element_by_id('p')
# 输入账号和密码
account_input.send_keys('675361896')
pwd_input.send_keys('*******')
# 点击登录
login = bro.find_element_by_id('login_button')
login.click()
time.sleep(5)
bro.quit()
7,selenium实现12306模拟登录
这是12306官网的登录页面
模拟登录的思路如下:
- selenium输入账号和密码
- selenium截屏
- selenium截图验证码的div
- 使用超级鹰在线接口实现此类验证码的识别(传入验证码图片,返回对应的图的坐标,实现模拟点击即可)
- 然后模拟点击,进行登录
from selenium import webdriver
import time
# 用于裁剪
from PIL import Image
bro = webdriver.Chrome(executable_path='./chromedriver.exe')
# 浏览器全屏放大
bro.maximize_window()
# 让浏览器发起一个指定url对应请求
bro.get('https://kyfw.12306.cn/otn/resources/login.html')
time.sleep(1)
zhdl = bro.find_element_by_xpath('/html/body/div[2]/div[2]/ul/li[2]/a')
zhdl.click()
time.sleep(2)
# save_screenshot就是将当前页面进行截图并保存
bro.save_screenshot('aa.png')
# 确定验证码图片对应的左上角和右下角的坐标(确定裁剪的区域) 这个xpath可以在F12中找到验证码div元素右键copy->xpath
code_img_ele = bro.find_element_by_id('J-loginImg')
# 验证码div元素左上角的坐标
location = code_img_ele.location
print(location)
# 验证码div元素对应长和高
size = code_img_ele.size
print(size)
# 左上角和右下角坐标
# 因为我个人电脑的原因,屏幕缩放比例是125%,所以都乘以1.25
range = (
int(location['x']*1.25),int(location['y']*1.25),int((location['x']+size['width'])*1.25),int((location['y']+size['height'])*1.25)
)
# 至此,验证码图片区域进行图片裁剪
i = Image.open('./aa.png')
# crop根据指定区域进行图片裁剪
frame = i.crop(range)
# 保存截图到当前目录
frame.save('./code.png')
bro.quit()
最后得到的code.png就是验证码图片,如下图

然后把这个图片根据超级鹰在线接口得到返回的坐标进行模拟点击。
# 比如通过超级鹰在线接口返回了坐标信息,我们对坐标信息进行数据处理,处理成了[[253,23],[267,25]] (两个坐标)
list = [[253,23],[267,25]]
# 遍历列表,使用动作链对每一个列表元素对应的x,y指定的位置进行模拟点击
for l in list:
x = l[0]
y = l[1]
# 这个x,y坐标只是相对于code.png这张图片来说的,但是模拟点击要得到这个验证码图片要点击的内容的坐标是相对于浏览器的,所以用动作链来切换为浏览器的坐标并进行模拟点击
ActionChains(bro).move_to_element_with_offset(code_img_ele,x,y).click().perform()
time.sleep(1)
#录入用户名和密码,并点击登录确认按钮
bro.find_element_by_id('username').send_keys('xxx')
bro.find_element_by_id('password').send_keys('xxx')
bro.find_element_by_id('login').click()
print('模拟登录成功')
bro.quit()
六,scrapy框架
什么是scrapy框架?
爬虫中封装好的一个明星框架,功能:高性能的持久化存储,异步的数据下载,高性能的异步解析,分布式。
1,scrapy环境安装
- 环境安装:
- linux和mac操作系统:
- pip install scrapy
- windows系统:
- pip install wheel
- 下载twisted,下载地址为http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted,要下载对应安装的python版本喝操作系统位数
- 安装twisted:pip install Twisted‑17.1.0‑cp36‑cp36m‑win_amd64.whl
- pip install pywin32
- pip install scrapy
测试:在终端里录入scrapy指令,没有报错即表示安装成功!
- scrapy使用流程:
- 创建工程:
- scrapy startproject ProName
- 进入工程目录:
- cd ProName
- 创建爬虫文件:
- scrapy genspider spiderName www.xxx.com
- 编写相关操作代码
- 执行工程:
- scrapy crawl spiderName
2,scrapy基本使用
- scrapy使用流程:
- 创建工程:
- scrapy startproject ProName
- 进入工程目录:
- cd ProName
- 创建爬虫文件:
- scrapy genspider spiderName www.xxx.com
- 编写相关操作代码
- 执行工程:
- scrapy crawl spiderName
- scrapy crawl spiderName --nolog (这是忽略详情信息,建议)
创建好scrapy框架之后,开始编写爬虫代码,这里还以爬取糗事百科网站的标题为示例!
上面是以命令启动的scrapy爬虫,不能进行debug调试,下面的方式启动可以debug调试!
创建start.py文件,内容如下
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'spiderName', '--nolog']) # 相当于在终端输入命令
在上面创建的爬虫文件spiderName.py中进行编写
import scrapy
class SpidernameSpider(scrapy.Spider):
name = 'spiderName'
# 允许爬取的域名(如果遇到非该域名的url则爬取不到数据)
allowed_domains = ['https://www.qiushibaike.com']
# 起始爬取的url
start_urls = ['https://www.qiushibaike.com/']
# 访问起始URL并获取结果后的回调函数,该函数的response参数就是向起始的url发送请求后,获取的响应对象.该函数返回值必须为可迭代对象或者NUll
def parse(self, response):
# xpath为response中的方法,可以将xpath表达式直接作用于该函数中
odiv = response.xpath('//*[@id="content"]/div/div[2]/div/ul/li')
content_list = [] # 用于存储解析到的数据
for div in odiv:
# xpath函数返回的为列表,列表中存放的数据为Selector类型的数据。我们解析到的内容被封装在了Selector对象中,需要调用extract()函数将解析的内容从Selecor中取出。
author = div.xpath('.//a[@class="recmd-content"]/text()')[0].extract()
# 打印展示爬取到的数据
print(author)
3,scrapy的数据持久化存储
scrapy的高性能持久化存储操作
- 基于终端指令的持久化存储
- 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化操作。
import scrapy
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
allowed_domains = ['https://www.qiushibaike.com/']
start_urls = ['https://www.qiushibaike.com/']
def parse(self, response):
#xpath为response中的方法,可以将xpath表达式直接作用于该函数中
odiv = response.xpath('//div[@id="content-left"]/div')
content_list = [] #用于存储解析到的数据
for div in odiv:
#xpath函数返回的为列表,列表中存放的数据为Selector类型的数据。我们解析到的内容被封装在了Selector对象中,需要调用extract()函数将解析的内容从Selecor中取出。
author = div.xpath('.//div[@class="author clearfix"]/a/h2/text()')[0].extract()
content=div.xpath('.//div[@class="content"]/span/text()')[0].extract()
#将解析到的内容封装到字典中
dic={
'作者':author,
'内容':content
}
#将数据存储到content_list这个列表中
content_list.append(dic)
return content_list
- 执行指令:
- 执行输出指定格式进行存储:将爬取到的数据写入不同格式的文件中进行存储
scrapy crawl 爬虫名称 -o xxx.json
scrapy crawl 爬虫名称 -o xxx.xml
scrapy crawl 爬虫名称 -o xxx.csv
- 基于管道的持久化存储操作
- scrapy框架中已经为我们专门集成好了高效、便捷的持久化操作功能,我们直接使用即可。要想使用scrapy的持久化操作功能,我们首先来认识如下两个文件:
- items.py:数据结构模板文件。定义数据属性。
- pipelines.py:管道文件。接收数据(items),进行持久化操作。
- 持久化流程:
- 1.爬虫文件爬取到数据后,需要将数据封装到items对象中。
- 2.使用yield关键字将items对象提交给pipelines管道进行持久化操作。
- 3.在管道文件中的process_item方法中接收爬虫文件提交过来的item对象,然后编写持久化存储的代码将item对象中存储的数据进行持久化存储
- 4.settings.py配置文件中开启管道
- 小试牛刀:将糗事百科首页中的段子和作者数据爬取下来,然后进行持久化存储
- 爬虫文件:qiubaiDemo.py
import scrapy
from secondblood.items import SecondbloodItem
class QiubaidemoSpider(scrapy.Spider):
name = 'qiubaiDemo'
allowed_domains = ['www.qiushibaike.com']
start_urls = ['http://www.qiushibaike.com/']
def parse(self, response):
odiv = response.xpath('//div[@id="content-left"]/div')
for div in odiv:
# xpath函数返回的为列表,列表中存放的数据为Selector类型的数据。我们解析到的内容被封装在了Selector对象中,需要调用extract()函数将解析的内容从Selecor中取出。
author = div.xpath('.//div[@class="author clearfix"]//h2/text()').extract_first()
author = author.strip('\n')#过滤空行
content = div.xpath('.//div[@class="content"]/span/text()').extract_first()
content = content.strip('\n')#过滤空行
#将解析到的数据封装至items对象中
item = SecondbloodItem()
item['author'] = author
item['content'] = content
yield item#提交item到管道文件(pipelines.py)
items文件:items.py
import scrapy
class SecondbloodItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
author = scrapy.Field() #存储作者
content = scrapy.Field() #存储段子内容
管道文件:pipelines.py
class SecondbloodPipeline(object):
#构造方法
def __init__(self):
self.fp = None #定义一个文件描述符属性
#下列都是在重写父类的方法:
#开始爬虫时,执行一次
def open_spider(self,spider):
print('爬虫开始')
self.fp = open('./data.txt', 'w')
#因为该方法会被执行调用多次,所以文件的开启和关闭操作写在了另外两个只会各自执行一次的方法中。
def process_item(self, item, spider):
#将爬虫程序提交的item进行持久化存储
self.fp.write(item['author'] + ':' + item['content'] + '\n')
return item
#结束爬虫时,执行一次
def close_spider(self,spider):
self.fp.close()
print('爬虫结束')
配置文件
#开启管道
ITEM_PIPELINES = {
'secondblood.pipelines.SecondbloodPipeline': 300, #300表示为优先级,值越小优先级越高
}
- 面试题:如果最终需要将爬取到的数据值一份存储到磁盘文件,一份存储到数据库中,则应该如何操作scrapy?
- 答:管道文件中的代码为
#该类为管道类,该类中的process_item方法是用来实现持久化存储操作的。
class DoublekillPipeline(object):
def process_item(self, item, spider):
#持久化操作代码 (方式1:写入磁盘文件)
return item
#如果想实现另一种形式的持久化操作,则可以再定制一个管道类:
class DoublekillPipeline_db(object):
def process_item(self, item, spider):
#持久化操作代码 (方式1:写入数据库)
return item
在settings.py开启管道操作代码为:
#下列结构为字典,字典中的键值表示的是即将被启用执行的管道文件和其执行的优先级。
ITEM_PIPELINES = {
'doublekill.pipelines.DoublekillPipeline': 300,
'doublekill.pipelines.DoublekillPipeline_db': 200,
}
#上述代码中,字典中的两组键值分别表示会执行管道文件中对应的两个管道类中的process_item方法,实现两种不同形式的持久化操作。
4,scrapy基于Spider类的全站数据爬取
- 大部分的网站展示的数据都进行了分页操作,那么将所有页码对应的页面数据进行爬取就是爬虫中的全站数据爬取。
- 基于scrapy如何进行全站数据爬取呢?
- 将每一个页码对应的url存放到爬虫文件的起始url列表(start_urls)中。(不推荐)
- 使用Request方法手动发起请求。(推荐)
- 需求:将糗事百科所有页码的作者和段子内容数据进行爬取切持久化存储
import scrapy
from qiushibaike.items import QiushibaikeItem
# scrapy.http import Request
class QiushiSpider(scrapy.Spider):
name = 'qiushi'
allowed_domains = ['www.qiushibaike.com']
start_urls = ['https://www.qiushibaike.com/text/']
#爬取多页
pageNum = 1 #起始页码
url = 'https://www.qiushibaike.com/text/page/%s/' #每页的url
def parse(self, response):
div_list=response.xpath('//*[@id="content-left"]/div')
for div in div_list:
#//*[@id="qiushi_tag_120996995"]/div[1]/a[2]/h2
author=div.xpath('.//div[@class="author clearfix"]//h2/text()').extract_first()
author=author.strip('\n')
content=div.xpath('.//div[@class="content"]/span/text()').extract_first()
content=content.strip('\n')
item=QiushibaikeItem()
item['author']=author
item['content']=content
yield item #提交item到管道进行持久化
#爬取所有页码数据
if self.pageNum <= 13: #一共爬取13页(共13页)
self.pageNum += 1
url = format(self.url % self.pageNum)
#递归爬取数据:callback参数的值为回调函数(将url请求后,得到的相应数据继续进行parse解析),递归调用parse函数
yield scrapy.Request(url=url,callback=self.parse)